一、论文理论

论文地址:Separable Self-attention for Mobile Vision Transformers
1.理论思想
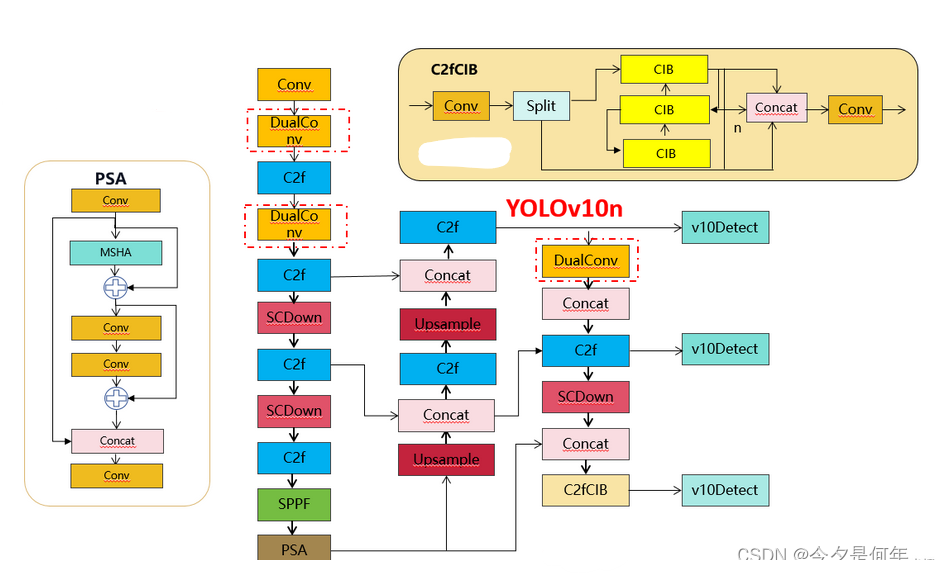
将 MobileViTv1 中的Transformer块中的 MHA 替换为提出的可分离自注意力方法。我们将生成的架构称为 MobileViTv2。我们也没有在 MobileViT 块中使用skip-connection连接和融合块([4] 中的图 1b),因为它略微提高了性能([4] 中的图 12)。此外,为了创建不同复杂度的 MobileViTv2 模型,我们使用宽度乘数 α ∈ {0.5, 2.0} 统一缩放 MobileViTv2 网络的宽度。这与为移动设备训练三种特定架构(XXS、XS 和 S)的 MobileViTv1 形成对比
2.创新点
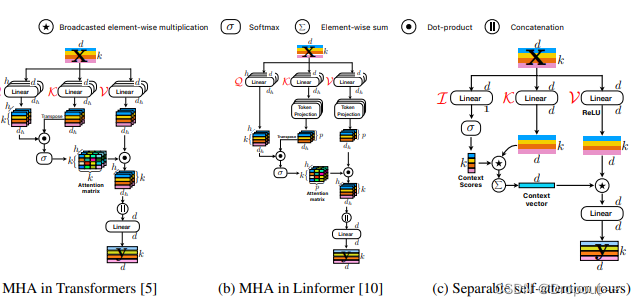
操作过程:
(1)将特征图通过一个卷积核大小为nxn(代码中是3x3)的卷积层进行局部的特征建模,然后通过一个卷积核大小为1x1的卷积层调整通道数<



![【<span style='color:red;'>YOLOv</span>8<span style='color:red;'>改进</span>[Backbone]】使用MobileNetV3<span style='color:red;'>助力</span><span style='color:red;'>YOLOv</span>8网络结构<span style='color:red;'>轻</span><span style='color:red;'>量化</span>并<span style='color:red;'>助力</span><span style='color:red;'>涨</span><span style='color:red;'>点</span>](https://img-blog.csdnimg.cn/direct/9904d67767ff4a36ba29bdf79f4a084a.png)