RAG
RAG是什么?
RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
重点是可以构建外部知识库来完成问答,方便快捷,不用深入内部对模型进行微调,降低使用成本。
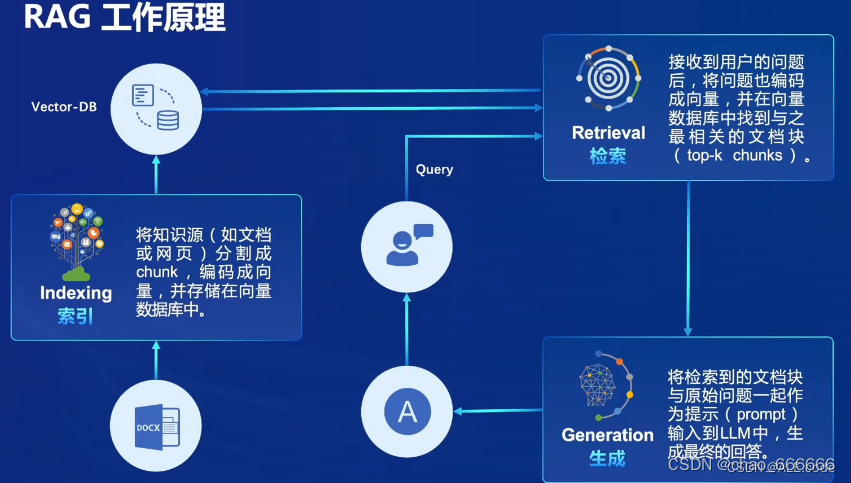
工作原理
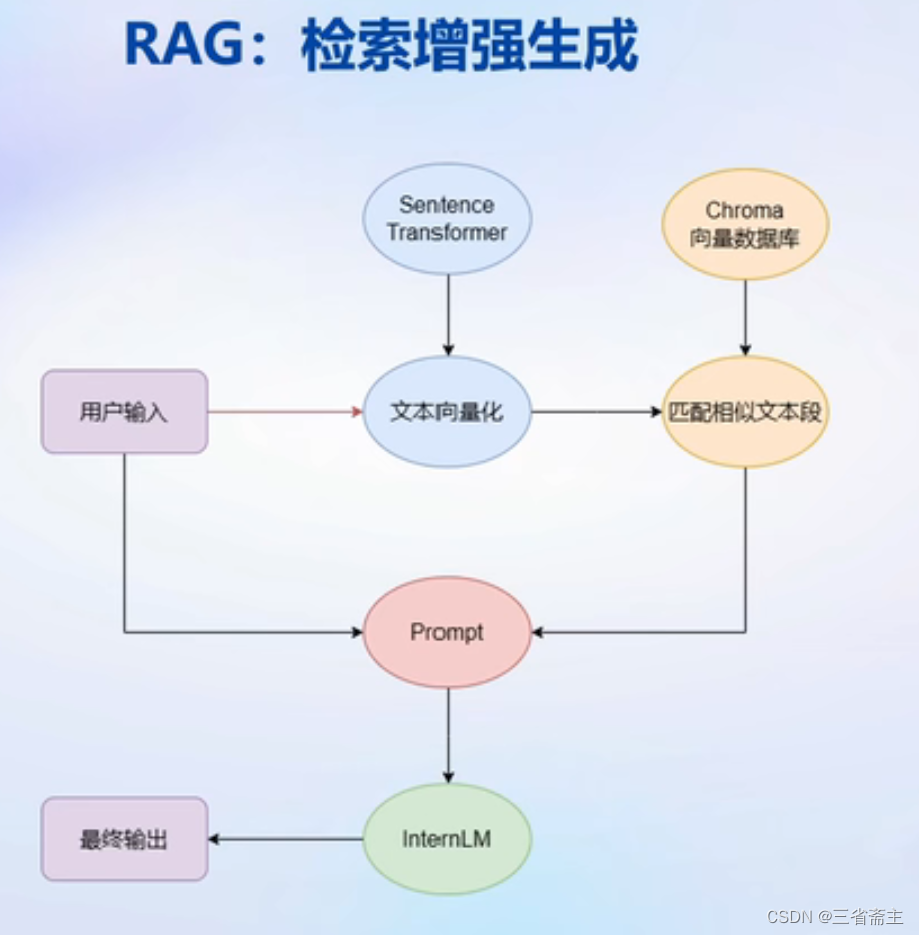
工作原理是在用户提问时,去知识库查找相关内容,再次将查找到的内容与问题一起作用prompt输给大模型,进行回答。
 数据库构建——向量知识库
数据库构建——向量知识库
将文本编码为向量,进行相似度查找,找到相关内容。

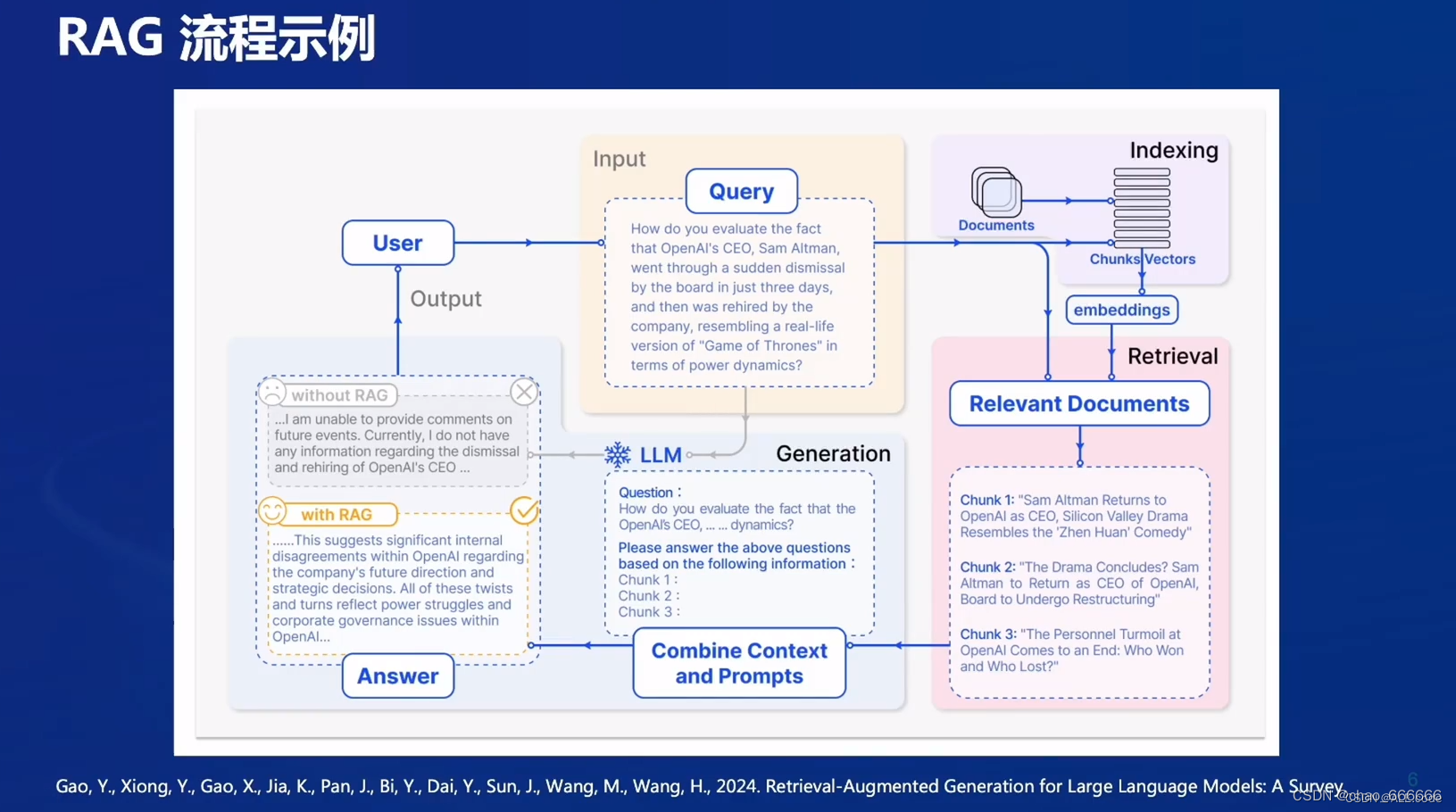
RAG工作流
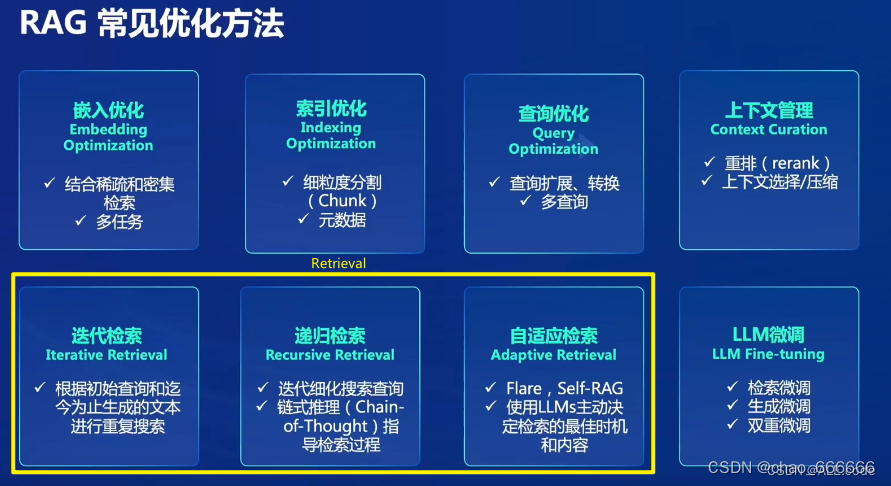
RAG优化方法
参考优秀笔记:【InternLM 实战营第二期笔记3】“茴香豆“:零代码搭建你的 RAG 智能助理-CSDN博客
应用RAG其他平台——coze
抖音旗下云雀大模型平台coze搭建了一套完整的流程,包括记忆库(数据库和知识库),
接着可以使用模块化工作流进行一个bot的搭建。


工作流实例
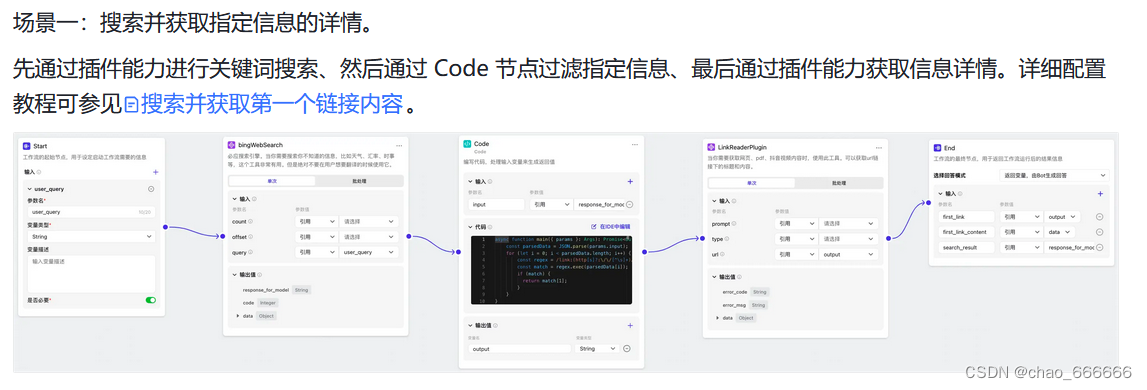
任务一:在茴香豆 Web 版中创建自己领域的知识问答助手
构建个人回答助手
进入web页面,传输属于自己的文件,此处进行输入大量投资领域资料,构建个人投资者问答助手
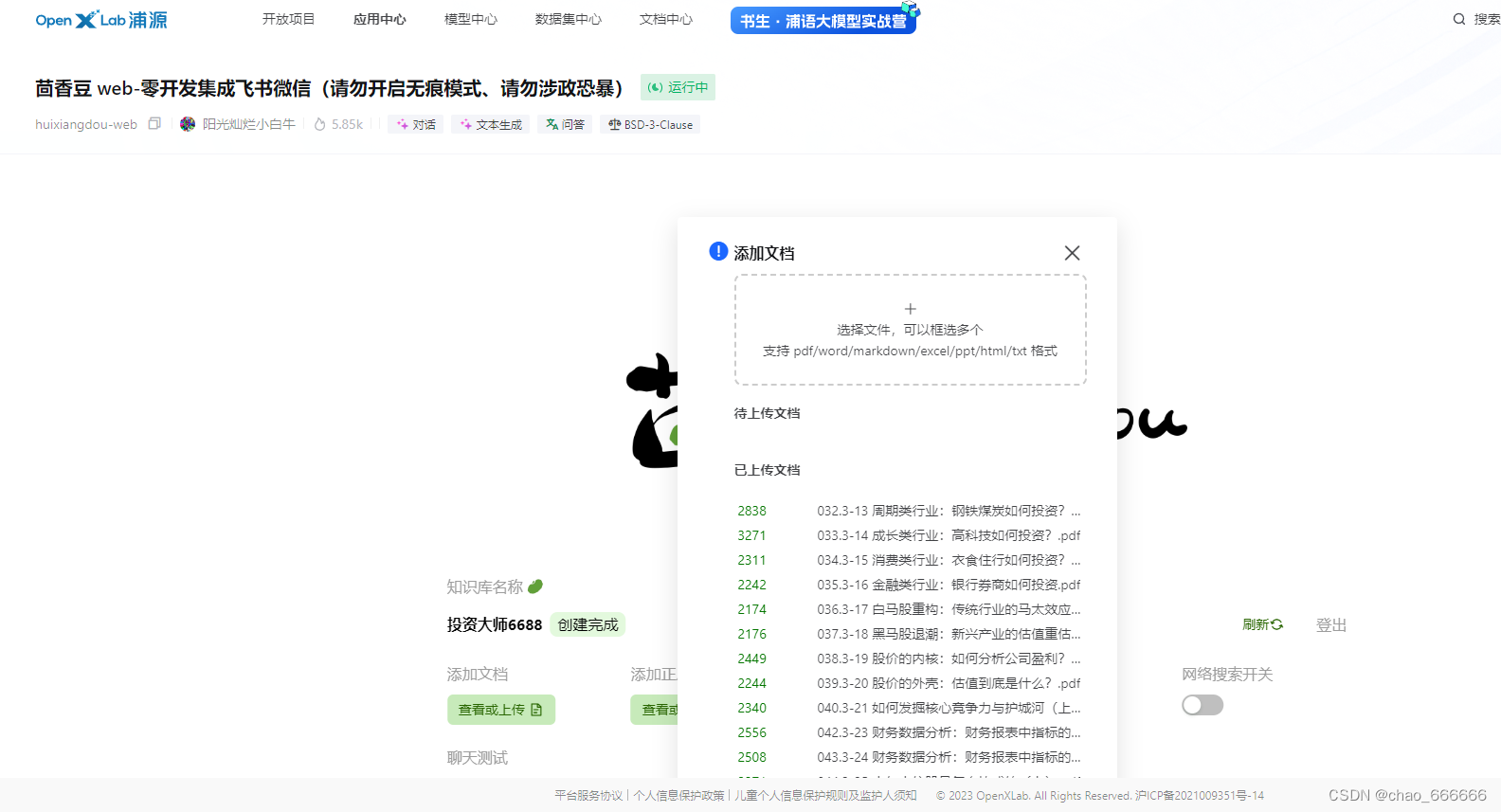
回答示例
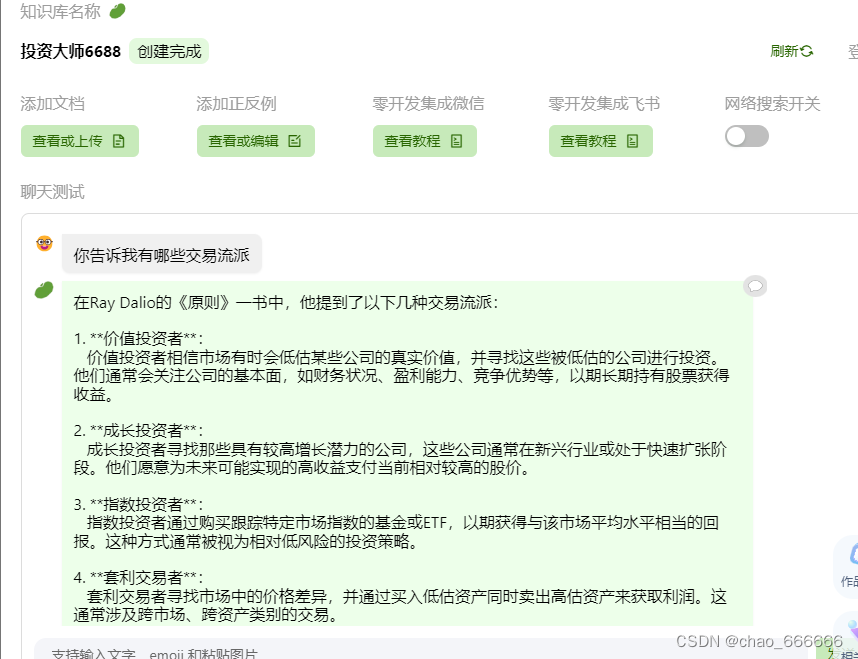
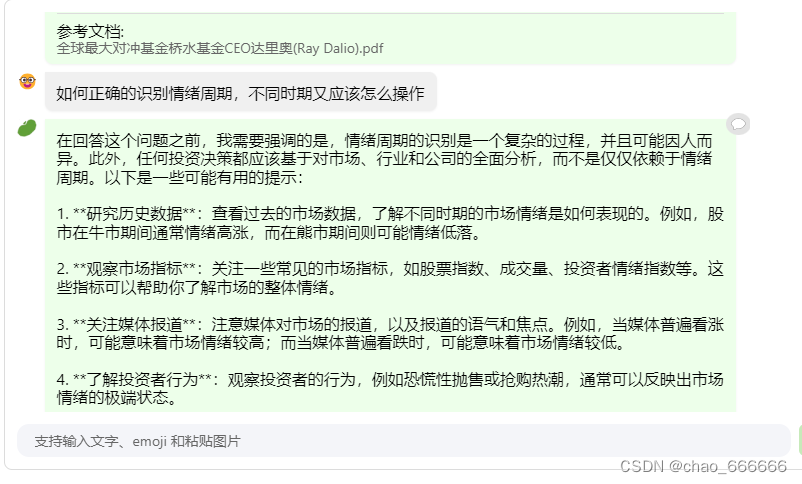
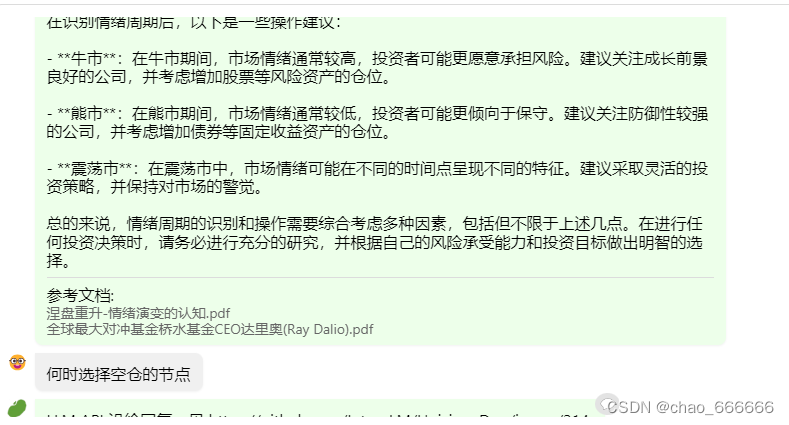

茴香豆缺陷
此处会发现茴香豆仍然存在一些缺点,会发现在多个回答中都参考了同一个文档并且没有进一步去查找知识库中的其他文档,导致最后生成的回答质量有一定缺陷,通过以下图可以发现,多次出现的文档《全球最大对冲基金桥水基金CEO达里奥》是在最先输入进入知识库的,可以推测知识库查找是按照顺序查找,找到符合的资料会导致后续文档的引用权重减少
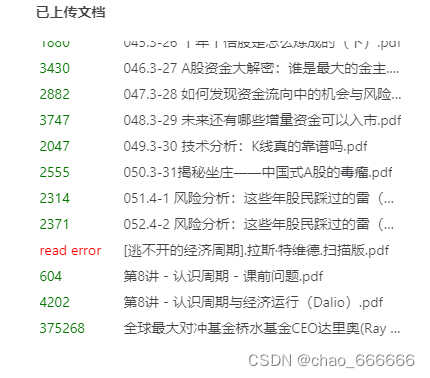
任务二:在 InternLM Studio 上部署茴香豆技术助手
Tutorial/huixiangdou at camp2 · InternLM/Tutorial · GitHub
茴香豆技术助手亮点
数据库向量化
数据库向量化的过程应用到了 LangChain 的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型,如果没有在 config.ini 文件中指定本地模型路径,茴香豆将自动从 HuggingFace 拉取默认模型。
建立接受和拒答两个向量数据库
- 接受问题列表,希望茴香豆助手回答的示例问题
- 存储在
huixiangdou/resource/good_questions.json中
- 存储在
- 拒绝问题列表,希望茴香豆助手拒答的示例问题
- 存储在
huixiangdou/resource/bad_questions.json中 - 其中多为技术无关的主题或闲聊
- 如:"nihui 是谁", "具体在哪些位置进行修改?", "你是谁?", "1+1"
- 存储在
通过接受和拒答数据库,可以在群聊中更有针对性的回答问题,较少资源消耗。
根据茴香豆官方文档进行模型的部署完成























![[通俗易懂]《动手学强化学习》学习笔记2-第2、3、4章](https://img-blog.csdnimg.cn/direct/467a2cc871084a53ad2b700c0fd320f0.png)