小说下载脚本使用模块:
- requests:用于数据请求。
- parsel:用于数据解析。
- prettytable:用于制表模块。
- tqdm:用于显示进度条。
实现功能:
- 采集单章小说内容。
- 采集完整小说正本内容。
- 实现搜索下载功能 / 打包成exe软件。
实现基本流程:
- 明确需求
- 抓包分析
- 发送请求
- 获取数据
- 解析数据
- 存储数据
主要函数与功能:
- GetResponse(url):发送请求函数,模拟浏览器发送请求。
- GetContent(link):获取单章小说内容,包括标题和章节内容。
- Save(name, title, content):保存小说内容到文件的函数。
- GetInfo():获取小说名字和章节链接函数。
- main 函数:整体流程,获取小说信息,遍历获取章节内容并保存到本地文件。
抓包分析
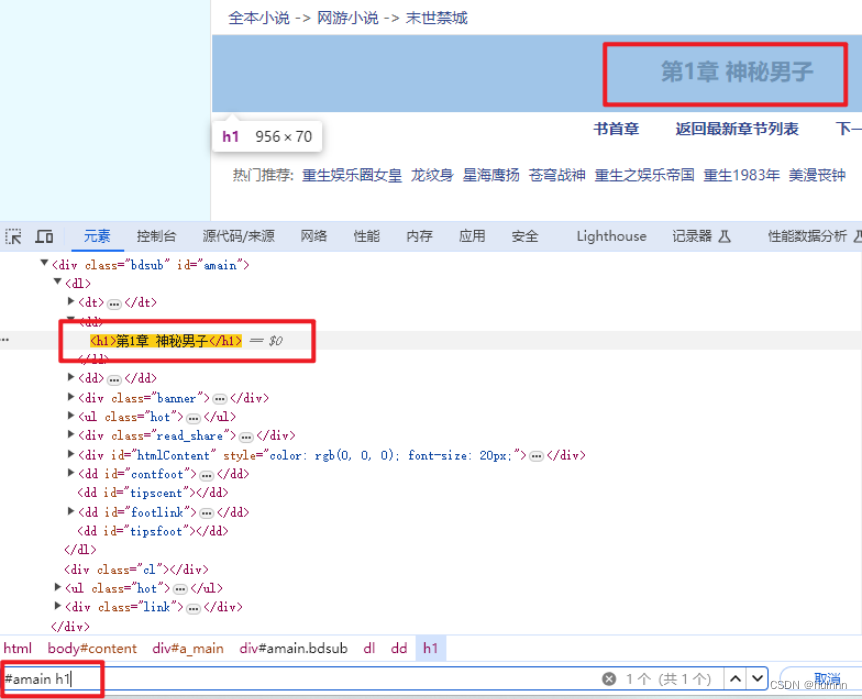
提取章节标题

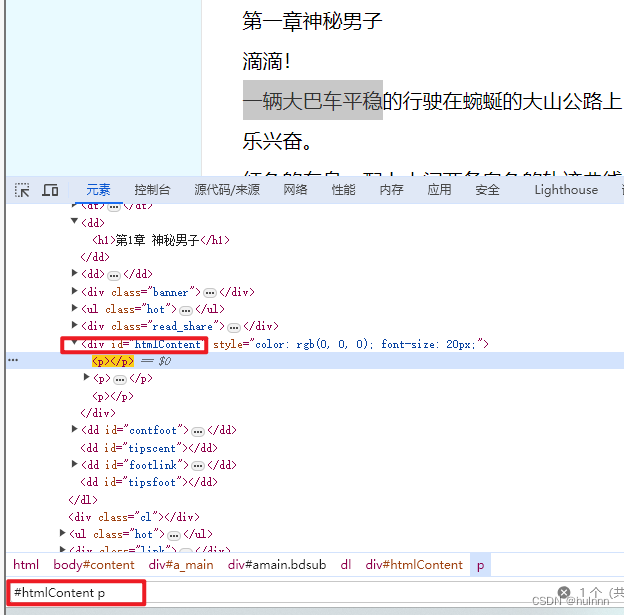
提取内容
代码部分
# 导入数据请求模块
import requests
# 导入数据解析模块
import parsel
# 导入进度条模块
from tqdm import tqdm
def GetResponse(url):
# 模拟浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}
# 发送请求
response = requests.get(url=url, headers=headers)
# 返回内容
return response
def GetContent(link):
"""获取小说内容单章"""
# 小说章节链接地址
# link = 'https://www.heenee.com/quanben/27/27066/16579246.html'
# 调用发送请求
response = GetResponse(url=link)
# 获取数据内容
html = response.text
# 把获取到的html字符串数据 转成可解析对象
selector = parsel.Selector(html)
# 提取章节标题
title = selector.css('#amain h1::text').get() # 根据标签属性提取数据内容
# 提取章节内容
content_list = selector.css('#htmlContent p::text').getall()
# 把列表合并成字符串
content = '\n\n'.join(content_list)
# 返回标题 和 内容
#print(title)
#print(content)
return title, content
# 保存函数
def Save(name,title, content):
with open(name + '.txt', mode='a', encoding='utf-8') as f:
f.write(str(title))
f.write('\n\n')
f.write(content)
f.write('\n\n')
def GetInfo():
# 获取小说名字,章节链接
novel_url= 'https://www.heenee.com/quanben/27/27066/'
# 发送请求
novel_html=GetResponse(url=novel_url).text
# 把获取到的html字符串数据 转成可解析对象
selector = parsel.Selector(novel_html)
# 提取小说名字
name=selector.css('.bdsub h1::text').get().split(' ')[0]
# 提取小说章节链接
href = selector.css('.L a::attr(href)').getall()
chapter_url_list=['https://www.heenee.com/'+i for i in href]
#print(name)
#print(href)
#print(chapter_url_list)
return name,chapter_url_list
if __name__ == '__main__':
# 获取小说名字,章节链接
name,chapter_url_list=GetInfo()
print(f'正在采集{name},请等待。')
for chapter_url in tqdm(chapter_url_list):
# 调用获取章节标题/内容函数
title, content = GetContent(link=chapter_url)
# 保存数据
Save(name,title,content)



























![[BUUCTF]ciscn_2019_c_1](https://img-blog.csdnimg.cn/direct/7c3e8fdff31648b0b7a4fcb7d96a8924.png)