语义向量模型是什么?
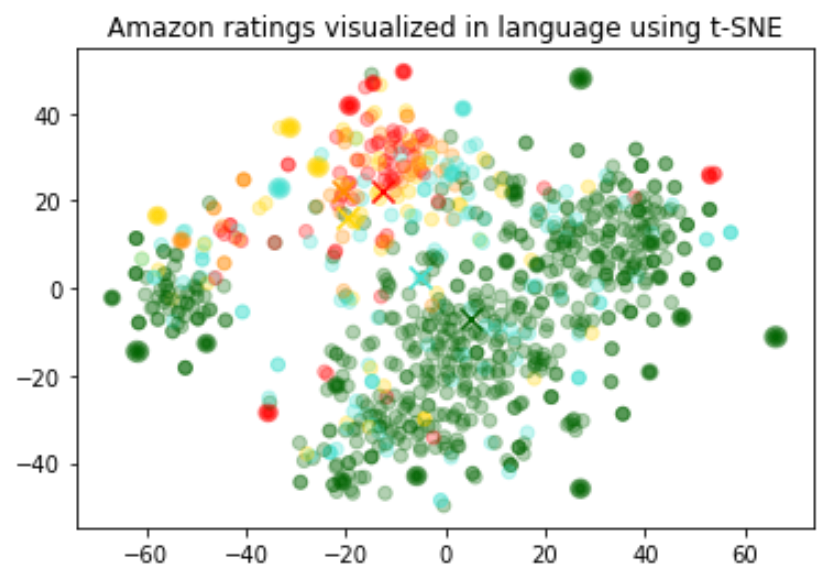
语义向量模型(Embedding Model)被广泛应用于搜索、推荐、数据挖掘等重要领域,将自然形式的数据样本(如语言、代码、图片、音视频)转化为向量(即连续的数字序列),并用向量间的“距离”衡量数据样本之间的“相关性” 。
常见的Embedding模型
- BCEmbedding
BCEmbedding (Bilingual and Crosslingual Embedding for RAG) 是由网易有道开发的双语和跨语种语义表征算法模型库,其中包含EmbeddingModel和RerankerModel两类基础模型。 - BGEEmbedding
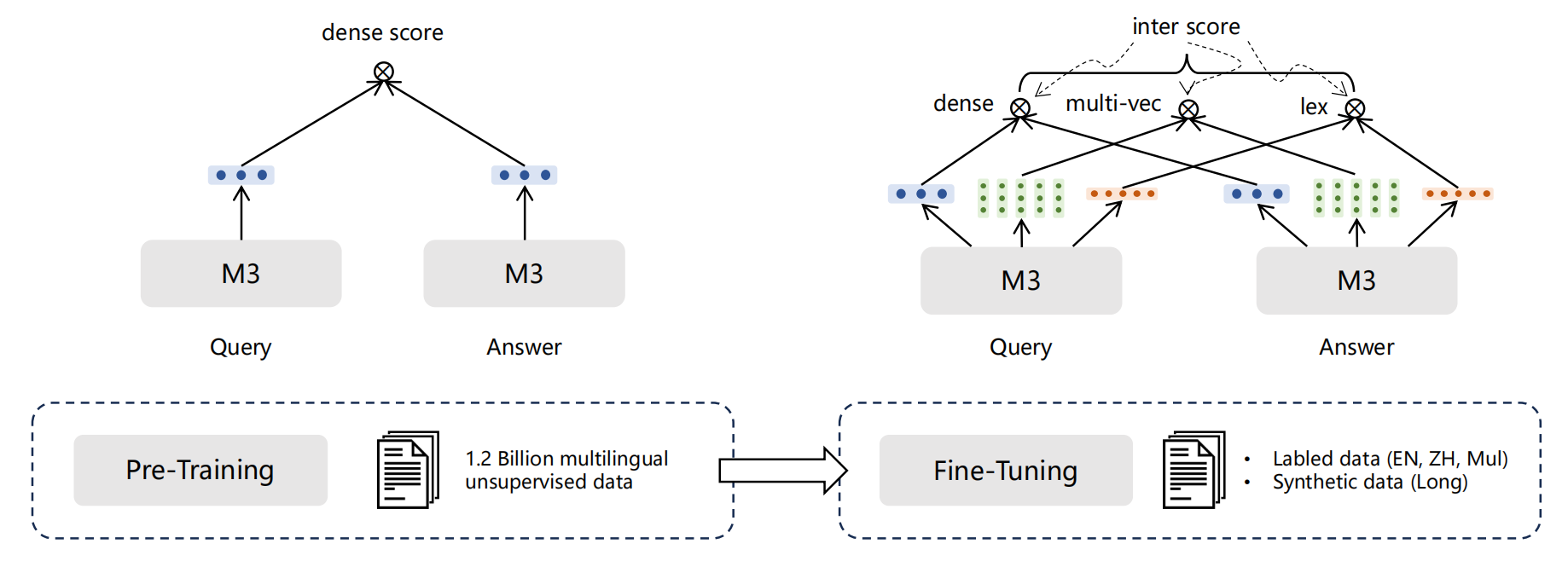
BGEEmbedding是一个通用向量模型由智源研究院开发,基于retroma 对模型进行预训练,再用对比学习在大规模成对数据上训练模型。 - M3E
M3E(Moka Massive Mixed Embedding)使用场景主要是中文,少量英文的情况,建议使用 m3e 系列的模型。 - 针对场景微调embedding模型:
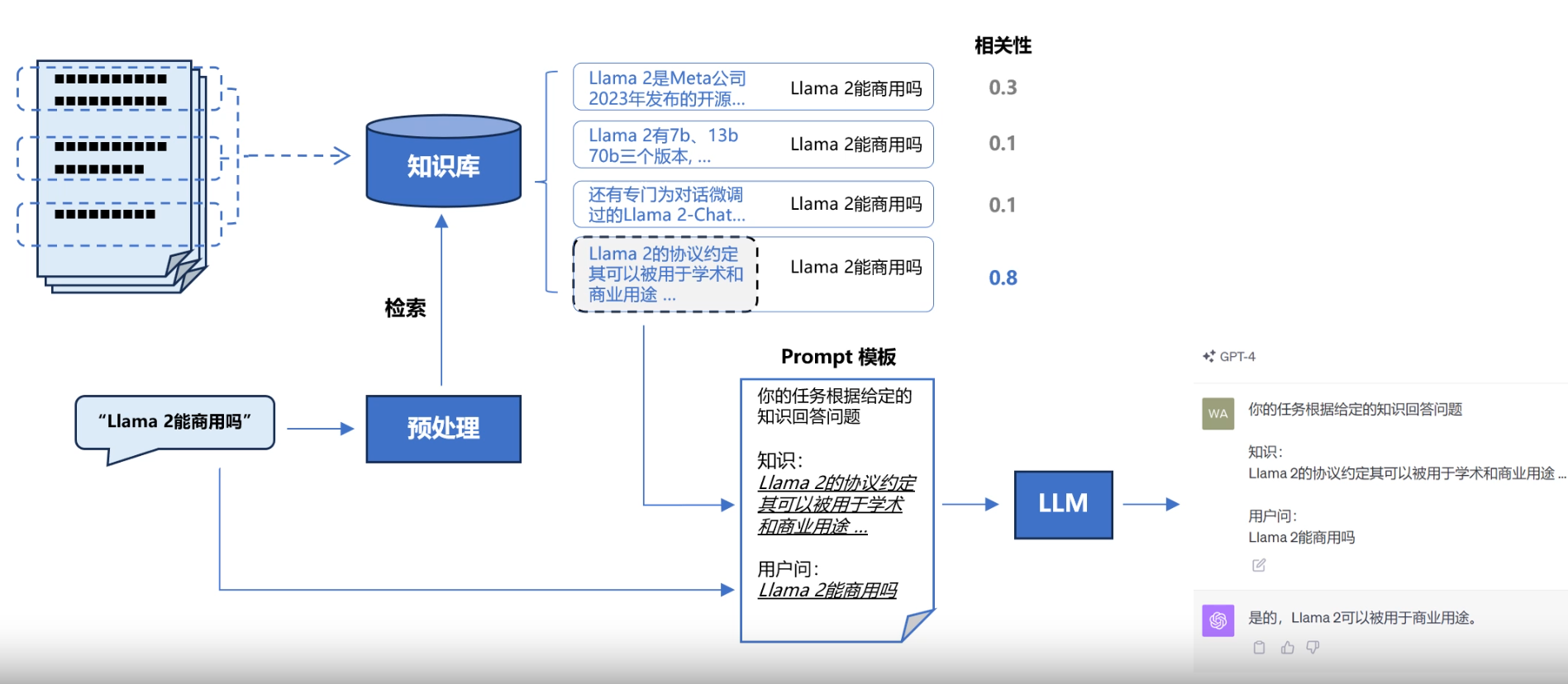
在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回答效果,因此,在许多场景下,我们都需要微调embedding模型来提高我们的召回效果。
如何选取合适的Embedding模型
创建一个小型的内存向量数据库DocArrayInMemorySearch并在其中插入一些文本,这些文本包括:中文句子,英文句子,数字符号等,这里我们为了在后面检验大模型给出的答案是否是由于"幻觉"而产生的。所以会往向量数据库中插入一些违背常识的文本。
from langchain.embeddings import HuggingFaceBgeEmbeddings
bge_embeddings = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-large-zh-v1.5")
vectordb = DocArrayInMemorySearch.from_texts(
["青蛙是食草动物",
"人是由恐龙进化而来的。",
"熊猫喜欢吃天鹅肉。",
"1+1=5",
"2+2=8",
"3+3=9",
"Gemini Pro is a Large Language Model was made by GoogleDeepMind",
"A Language model is trained by predicting the next token"
],
embedding=bge_embeddings
)
# #创建检索器
bge_retriever = vectordb.as_retriever(search_kwargs={"k": 1})
这里我们创建了一个内存向量数据库vectordb,并在里面创建了3句中文,3句数字符号,2句英文的文本。然后我们又创建了一个检索器bge_retriever,它可以根据问题从向量数据库中检索出与问题最相关的文档,这里我们设置了bge_retriever的参数search_kwargs={“k”: 1},这表示beg_retriever每次只检索1条最相关的文档给用户。
实验过程中不断更换embedding模型,对比不同模型的检索效果,选取最合适的模型。
RAG之大模型常用向量数据库对比
https://zhuanlan.zhihu.com/p/364923722
1. Faiss库
- 关键词:高效性、灵活性、Facebook支持
- 功能特性:轻松将向量检索功能嵌入到深度学习,适合需要高效相似度搜索和丰富社区支持的大型应用。支持多种向量检索方式,包括内积、欧氏距离等,同时支持精确检索与模糊搜索。
2.Milvus
- 关键词:大规模数据、云原生、高可用性
- 功能特性:大规模内容检索、图像和视频搜索,适合需要处理超大规模数据的云端应用
- 专为处理超大规模向量数据而设计
- 提供云原生的分布式架构和存储方案
- 支持多种索引类型和查询优化策略
- 适用于大规模内容检索、图像和视频搜索等场景
3.Chroma
- 关键词: 轻量级、易用性、开源
- 功能特性:快速搭建小型语义搜索,适合初学者和小型项目
- 提供高效的近似最近邻搜索(ANN)
- 支持多种向量数据类型和索引方法
- 易于集成到现有的应用程序中
- 适用于小型到中型数据集