paper:Momentum Contrast for Unsupervised Visual Representation Learning
official implementation:https://github.com/facebookresearch/moco
背景
最近的一些研究提出使用对比损失相关的方法进行无监督视觉表征学习并取得了不错的结果。尽管是受到不同motivation的启发,这些方法都可以看做是在构建一个动态字典。字典中的"keys"(tokens)从数据(图片或图片的patch)中采样并用一个编码器encoder网络来表示。无监督学习训练encoder来执行字典查找:一个encoded "query"应该与它匹配的key相似,而与其它的key不同。学习过程表述为最小化对比损失的过程。
存在的问题
从构建动态字典的角度来看,作者假设构建的字典应该具备两个特点:
- large即字典要足够大
- 在训练期间字典要保持一致性
从直觉上来说,一个更大的字典可以更好地对连续的、高维的视觉空间进行采样。而字典中的键应该由相同或相似的编码器表示,以便它们与query的比较是一致的。然而,一些使用对比损失的现有方法受限于这两个方面中的一个(具体将在后续的方法介绍中讨论)。
本文的创新点
本文提出了动量对比(Momentum Contrast,MoCo)作为一种构建大型和一致的字典的方法,用于对比损失的无监督学习,如图1所示。
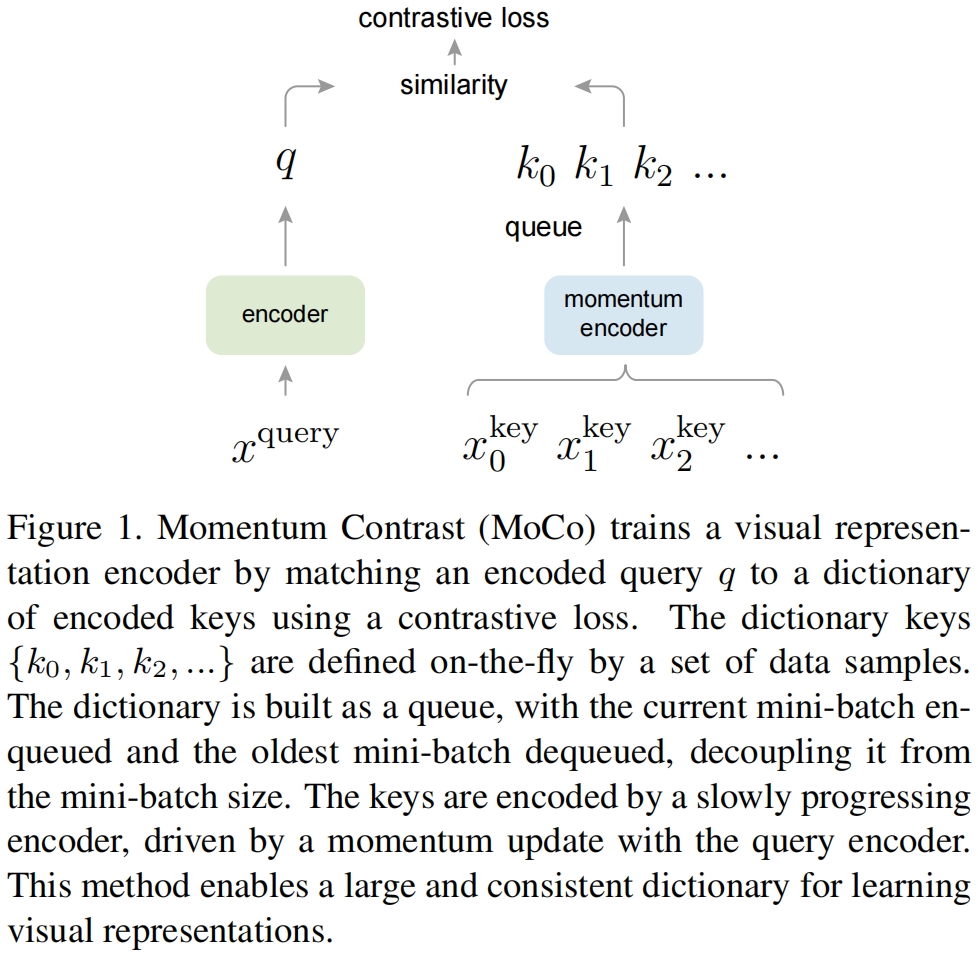
作者维护了一个数据样本的队列作为字典,当前mini-batch的encoded representation进队,队列中最老的表示出队。队列将字典大小和batch size进行解耦从而使得字典可以非常大。此外由于字典的key来源于之前若干个mini-batch,作者提出了一个缓慢变化的key encoder,具体实现为query encoder的基于动量的移动平均值,从而保持一致性。
无监督学习的一个主要目的是得到一个预训练表示,通过微调可以tranfer到下游任务中。作者通过实验表明,在7个与检测和分割相关的下游任务中,MoCo无监督预训练可以超过ImageNet有监督预训练。
方法介绍
Contrastive Learning as Dictionary Look-up
对比学习可以用来为字典查找任务训练一个编码器。对于一个encoded query \(q\) 和一组encoded样本 \(\{k_0,k_1,k_2,...\}\),后者是字典的keys。假设字典中有一个单独的key(表示为 \(k_+\))与 \(q\) 匹配,对比损失作为一个函数,当 \(q\) 和的positive key \(k_+\) 相似并与所有其它的key(被认为是 \(q\) 的negative keys)不相似时对比损失的值很小。用点积来表示相似性,本文采用了对比损失的一种形式,InfoNCE,如下

其中 \(\tau\) 是是温度超参,结果对一个正样本和 \(K\) 个负样本求和。从直觉上来说,这个损失是一个 \((K+1)\) 类基于softmax分类器的log损失,这个分类器试图将 \(q\) 分为 \(k_+\) 类。对比损失还有其它形式,比如margin-based loss和NCE loss的一些变种。
对比损失作为无监督的目标函数用来训练encoder network来表示queries和keys。一般来说,query representation是 \(q=f_q(x_q)\) 其中 \(f_q\) 是encoder网络,\(x_q\) 是一个query样本(同样,\(k=f_k(x_k)\))。初始化取决于具体的代理任务,输入 \(x_q\) 和 \(x_k\) 可以是图像、patches、或包含一组patches的context。网络 \(f_q\) 和 \(f_k\) 可以是相同的、部分共享的、或不同的。
Momentum Contrast
Dictionary as a queue
本文方法的核心是维护一个数据样本的队列作为字典,这使得我们可以重用前面mini-batch中的encoded keys,队列的引入将字典大小与batch大小进行了解耦,我们的字典可以比普通的batch size大得多,并且可以灵活独立的作为一个超参来设置。
字典中的样本被逐步替换掉,当前mini-batch进入队列,而队列中最老的mini-batch被删除。字典总是表示所有数据的一个采样子集,而维护字典的额外计算是可控的。此外删除最早的mini-batch也是有好处的,因为它的encoded keys是最老的,与最新的编码最不一致。
Momentum update
使用队列可以使字典更大,但也使得通过反向传播更新key encoder变得困难(梯度应该传播到队列中的所有样本)。一个天真的解决方法是忽略key encoder \(f_k\) 的梯度直接拷贝query encoder \(f_q\),但这种解决方案在实验中得到的结果很差,作者推测这是由于快速变化的encoder减少了key representation的一致性导致的。因此提出了动量更新来解决这个问题。
我们将 \(f_k\) 的参数表示为 \(\theta_k\),\(f_q\) 的参数表示为 \(\theta_q\),然后通过下式更新 \(\theta_k\)
![]()
其中 \(m\in[0,1)\) 是动量系数,只有参数 \(\theta_q\) 通过反向传播更新,式(2)中的动量更新使得 \(\theta_k\) 比 \(\theta_q\) 的更新更平滑。因此,尽管队列中的keys是通过不同的encoder编码的(不同的mini-batch),这些encoder之间的差异非常小。后续实验表明,一个更大的动量(例如 \(m=0.999\))比更小的动量(例如 \(m=0.9\))表现得更好,表明一个缓慢更新的key encoder是使用队列的核心。
Relations to previous mechanisms
MoCo是使用对比损失的一种机制,作者将其与其它两种机制进行了对比,如图2所示,它们在字典大小和一致性上表现出不同的属性。

图2(a)是通过反向传播进行end-to-end更新的一种机制,它使用当前mini-batch中的样本作为字典,因此key的编码是一致的(通过相同的一组encoder参数)。但是字典的大小和mini-batch的大小耦合,受限于GPU的内存。同时也受到大mini-batch优化问题的挑战。
另外一种机制是采用memory bank,如图2(b)所示。memory back包含了数据集中所有样本的representation,每个mini-batch的字典是从memory bank中随机采样得到的,且没有反向传播,因此字典的size可以很大。但是,memory bank中一个样本的表示在它最后一次被看到时就更新了,因此采样的keys是过去一个epoch中不同step的encoder得到的,从而缺乏了一致性。
Pretext Task
对比学习可以使用不同的代理任务,由于本文的重点不是设计一个新的代理任务,本文遵循instance discrimination任务使用了一个简单的代理任务。如果一个query和一个key来源于同一张图像,则将它们视为positive pair,否则视为negative pair。我们对同一张图像进行两次随机数据增强得到一个postive pair,queries和keys分别由各自的encoder \(f_q\) 和 \(f_k\) 进行编码,encoder可以是任何的卷积网络。
MoCo的伪代码如下所示,对当前的mini-batch,我们对postive pair分别进行编码得到queries和对应的keys,负样本来源于队列。

Shuffling BN
编码器 \(f_q\) 和 \(f_k\) 中都使用了BN,作者在实验中发现使用BN会阻止模型学习好的表示,模型似乎“欺骗”了代理任务并很容易地找到了一种low-loss的解决方法。这可能是样本之间的batch内的通信(BN引起的)泄露了信息。
作者通过shuffle BN来解决这个问题。具体训练是在多个GPU上进行的,每个GPU独立的对样本执行BN。对于key encoder \(f_k\),在将当前mini-batch分配到不同GPU之前打乱样本顺序(并在编码之后还原顺序),query encoder \(f_q\) 不进行打乱顺序。这保证了用于计算query和对应的positve key的统计信息来自于不同的子集,有效解决了欺骗问题。
代码解析
下面是官方实现,基本上和文章中的伪代码一致,没有什么难以理解的地方。其中encoder_k的参数更新顺序和伪代码不一样,伪代码是f_q和f_k分别forward,然后f_q的loss反向传播,更新f_q的参数,最后f_k进行动量更新。而代码中是f_q先forward,然后f_k更新参数,接着f_k进行forward,最后再根据反向传播更新f_q。
另外,这里包含了MoCo v2的代码,主要的区别就是v2借鉴SimCLR的做法,在encoder的avg pooling层后多加了一层projection layer,即一个MLP。
# Copyright (c) Meta Platforms, Inc. and affiliates.
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
class MoCo(nn.Module):
"""
Build a MoCo model with: a query encoder, a key encoder, and a queue
https://arxiv.org/abs/1911.05722
"""
def __init__(self, base_encoder, dim=128, K=65536, m=0.999, T=0.07, mlp=False):
"""
dim: feature dimension (default: 128)
K: queue size; number of negative keys (default: 65536)
m: moco momentum of updating key encoder (default: 0.999)
T: softmax temperature (default: 0.07)
"""
super(MoCo, self).__init__()
self.K = K
self.m = m
self.T = T
# create the encoders
# num_classes is the output fc dimension
self.encoder_q = base_encoder(num_classes=dim)
self.encoder_k = base_encoder(num_classes=dim)
if mlp: # hack: brute-force replacement
dim_mlp = self.encoder_q.fc.weight.shape[1] # 2048
self.encoder_q.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_q.fc
)
self.encoder_k.fc = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp), nn.ReLU(), self.encoder_k.fc
)
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data.copy_(param_q.data) # initialize
param_k.requires_grad = False # not update by gradient
# create the queue
self.register_buffer("queue", torch.randn(dim, K))
# 将张量或缓冲区注册为 nn.Module 的一部分,但不会被视为模型的可学习参数。
# 通常情况下,这用于存储模型中的固定参数或状态,例如均值、方差等,这些参数在训练过程中不会被更新。
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
@torch.no_grad()
def _momentum_update_key_encoder(self):
"""
Momentum update of the key encoder
"""
for param_q, param_k in zip(
self.encoder_q.parameters(), self.encoder_k.parameters()
):
param_k.data = param_k.data * self.m + param_q.data * (1.0 - self.m)
@torch.no_grad()
def _dequeue_and_enqueue(self, keys):
# gather keys before updating queue
keys = concat_all_gather(keys)
batch_size = keys.shape[0]
ptr = int(self.queue_ptr)
assert self.K % batch_size == 0 # for simplicity
# replace the keys at ptr (dequeue and enqueue)
self.queue[:, ptr: ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.K # move pointer
self.queue_ptr[0] = ptr
@torch.no_grad()
def _batch_shuffle_ddp(self, x):
"""
Batch shuffle, for making use of BatchNorm.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# random shuffle index
idx_shuffle = torch.randperm(batch_size_all).cuda()
# 打乱索引顺序,比如batch_size_all=8, idx_shuffle=[1,3,5,2,0,4,7,6]
# broadcast to all gpus
torch.distributed.broadcast(idx_shuffle, src=0)
# 将生成的随机索引序列从GPU 0(src=0)广播到所有其他的GPU设备上,以便在分布式训练时,每个GPU都能够获得相同的随机索引序列,以保持数据的同步性。
# index for restoring
idx_unshuffle = torch.argsort(idx_shuffle) # tensor([4, 0, 3, 1, 5, 2, 7, 6])
# shuffled index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_shuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this], idx_unshuffle
@torch.no_grad()
def _batch_unshuffle_ddp(self, x, idx_unshuffle):
"""
Undo batch shuffle.
*** Only support DistributedDataParallel (DDP) model. ***
"""
# gather from all gpus
batch_size_this = x.shape[0]
x_gather = concat_all_gather(x)
batch_size_all = x_gather.shape[0]
num_gpus = batch_size_all // batch_size_this
# restored index for this gpu
gpu_idx = torch.distributed.get_rank()
idx_this = idx_unshuffle.view(num_gpus, -1)[gpu_idx]
return x_gather[idx_this]
def forward(self, im_q, im_k):
"""
Input:
im_q: a batch of query images
im_k: a batch of key images
Output:
logits, targets
"""
# compute query features
q = self.encoder_q(im_q) # queries: NxC
q = nn.functional.normalize(q, dim=1)
# compute key features
with torch.no_grad(): # no gradient to keys
self._momentum_update_key_encoder() # update the key encoder
# 和论文中伪代码的顺序不一样,论文中encoder_k是先forward后更新参数,这里是先更新参数后forward
# shuffle for making use of BN
im_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)
k = self.encoder_k(im_k) # keys: NxC
k = nn.functional.normalize(k, dim=1)
# undo shuffle
k = self._batch_unshuffle_ddp(k, idx_unshuffle)
# compute logits
# Einstein sum is more intuitive
# positive logits: Nx1
l_pos = torch.einsum("nc,nc->n", [q, k]).unsqueeze(-1)
# negative logits: NxK
l_neg = torch.einsum("nc,ck->nk", [q, self.queue.clone().detach()])
# logits: Nx(1+K)
logits = torch.cat([l_pos, l_neg], dim=1)
# apply temperature
logits /= self.T
# labels: positive key indicators
labels = torch.zeros(logits.shape[0], dtype=torch.long).cuda()
# dequeue and enqueue
self._dequeue_and_enqueue(k)
return logits, labels
# utils
@torch.no_grad()
def concat_all_gather(tensor):
"""
Performs all_gather operation on the provided tensors.
*** Warning ***: torch.distributed.all_gather has no gradient.
"""
tensors_gather = [
torch.ones_like(tensor) for _ in range(torch.distributed.get_world_size())
]
torch.distributed.all_gather(tensors_gather, tensor, async_op=False)
output = torch.cat(tensors_gather, dim=0)
return output
实验结果
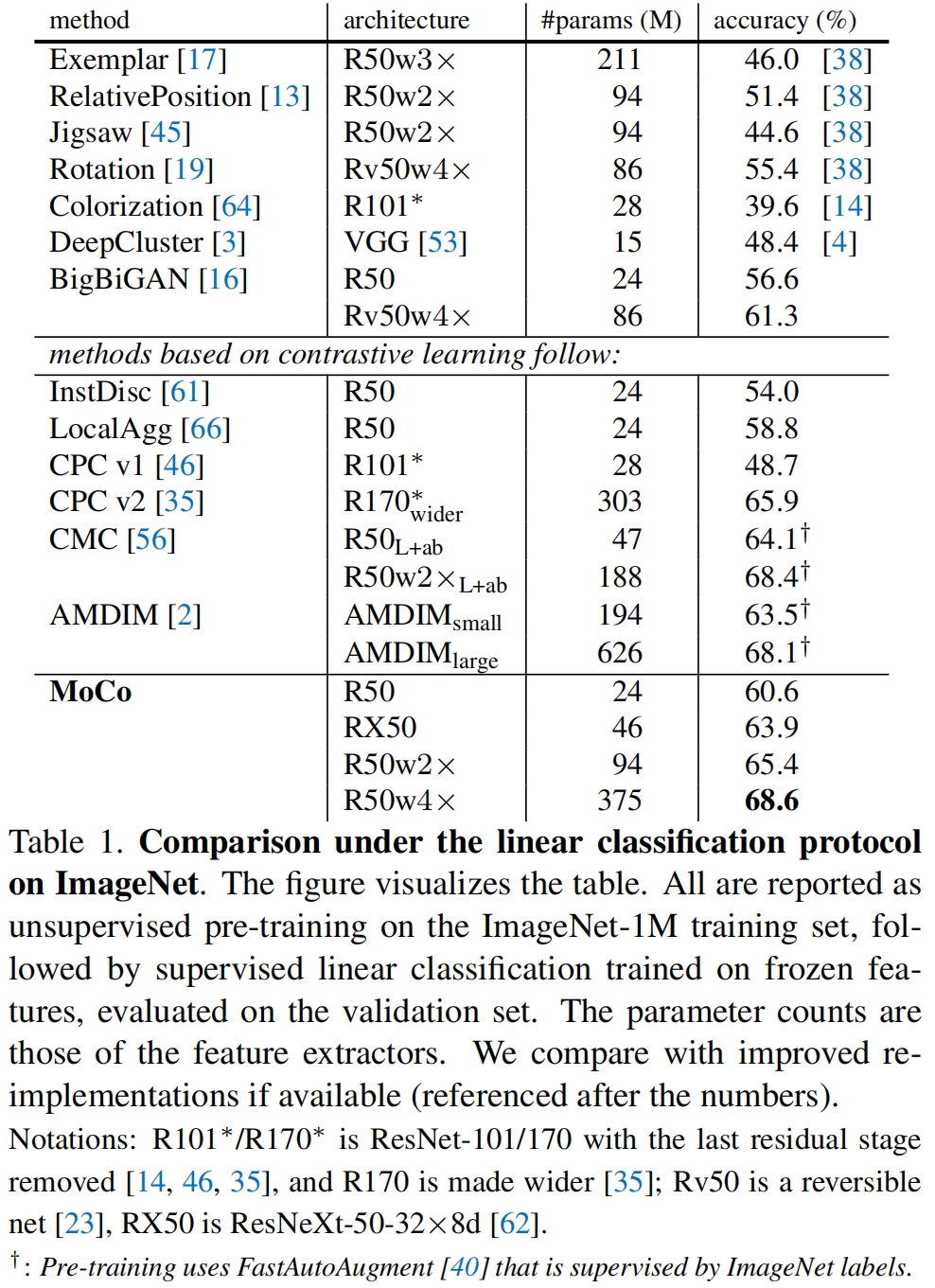
无监督模型的常见评估方法是将训练好的encoder的权重freeze,后面接一层全连接层和softmax,然后在目标数据上只训练全连接层,最后在测试集上评估得到的模型效果。下面是MoCo和之前的无监督模型的结果对比,可以看到MoCo取得了最优的结果。
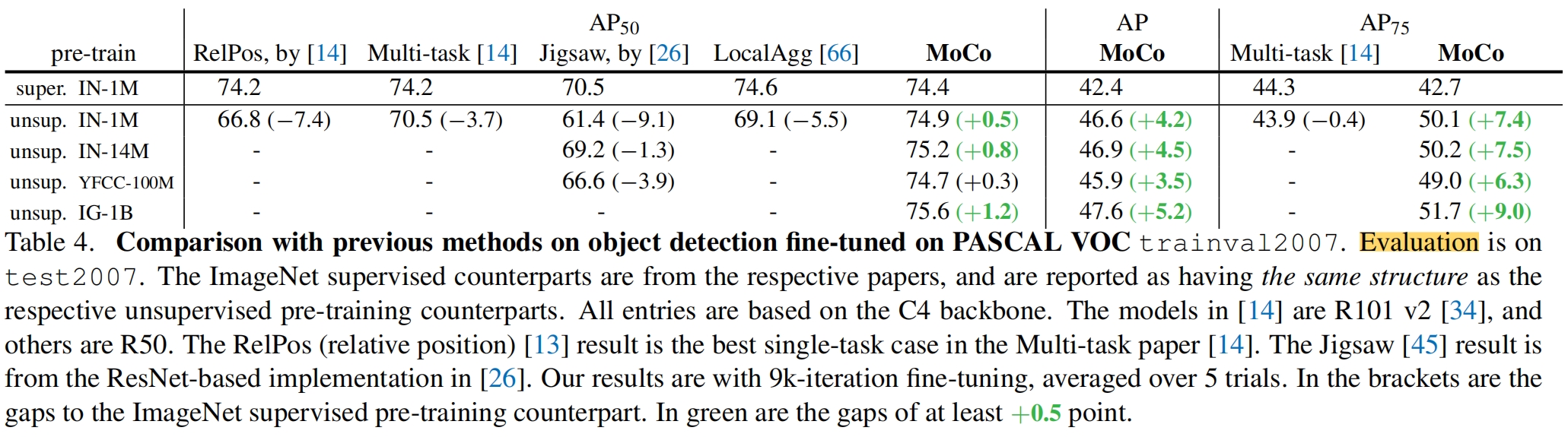
无监督模型的另一个作用是当做下游任务的预训练权重。在VOC目标检测任务上和监督预训练的对比如下,可以看到MoCo比监督预训练权重的效果更好。
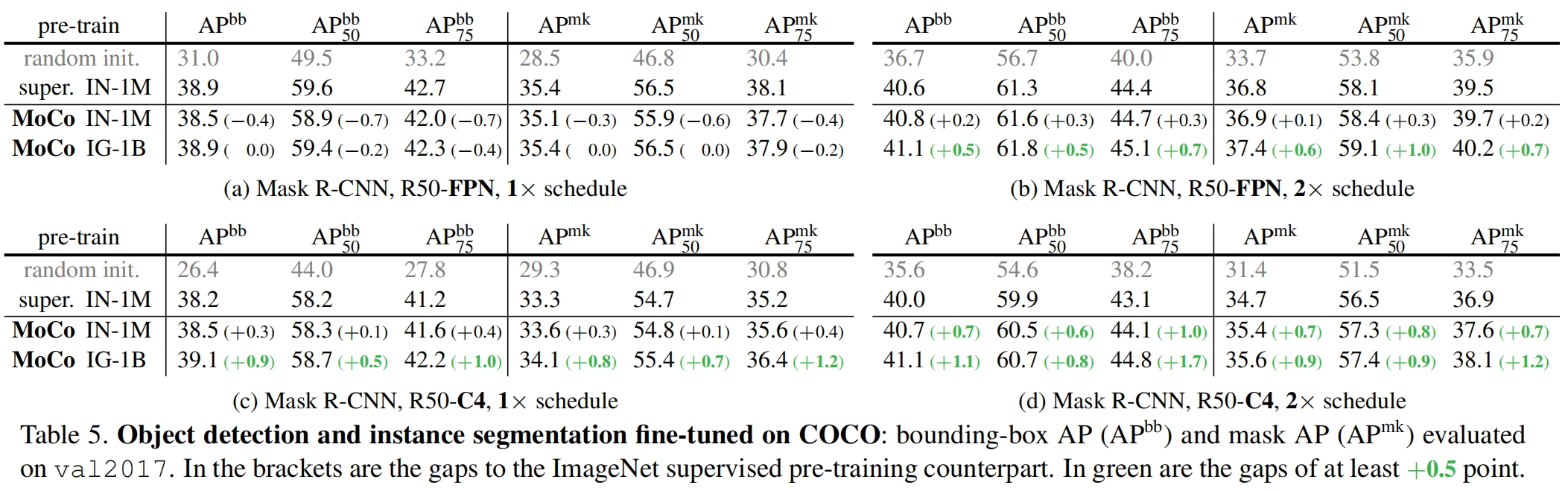
下面是在COCO数据的目标检测任务和实例分割任务上与随机初始化权重、监督预训练权重的结果对比