Sigma:用于多模态语义分割的暹罗曼巴网络
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
摘要
多模态语义分割显著提高了AI代理在不利条件下的感知和场景理解能力,尤其是在低光或过度曝光的环境中。利用热成像和深度等额外模态(X模态)与传统RGB数据相结合,提供了互补信息,使得分割更加健壮和可靠。
在这项工作中,作者介绍了Sigma,一个用于多模态语义分割的暹罗眼镜蛇网络,它采用了选择性结构化状态空间模型Mamba。与依赖于局部感受野有限的CNN或以二次复杂度为代价提供全局感受野的视觉 Transformer (ViTs)的常规方法不同,作者的模型以线性复杂度实现了全局感受野的覆盖。通过采用暹罗编码器并创新Mamba融合机制,作者有效地从不同模态中选择关键信息。然后开发了解码器以增强模型的通道建模能力。作者的方法Sigma在RGB-热成像和RGB-深度分割任务上进行了严格评估,展示了其优越性,并标志着状态空间模型(SSMs)在多模态感知任务中的首次成功应用。
Introduction
语义分割旨在为图像中的每个像素分配一个语义标签,这对于人工智能代理准确感知其环境越来越重要。然而,当前的视觉模型在低光或具有遮挡元素(如阳光反射和火焰)的挑战性条件下仍然存在困难。为了在这样具有挑战性的条件下增强分割效果,额外的模态如热成像和深度信息对于增强视觉系统的鲁棒性是有益的。借助这些补充信息,视觉处理 Pipeline 的鲁棒性和能力可以得到提升[30, 37, 73]。然而,利用多个模态带来了额外的挑战,即对通过这些额外通道提供的信息进行对齐和融合[12]。
在多模态语义分割的先前方法中,依赖于卷积神经网络(CNN)或视觉 Transformer (ViT)。尽管基于CNN的方法[13, 29]以其可扩展性和线性复杂性而闻名,但它们受到由核大小限制的小感受野的影响,导致局部还原性偏差。此外,CNN在整个输入的不同部分使用权重共享核,限制了其在适应未见或低质量图像时的灵活性。相比之下,基于ViT的方法[1, 30, 52]通过利用全局感受野和动态权重增强了视觉建模。然而,它们的自注意力机制在输入大小方面具有二次复杂性[16],引发了效率问题。尝试通过减少处理窗口的维度或步长来提高效率,这牺牲了感受野的范围[66]。
为了解决这些限制,选择性结构化状态空间模型——Mamba[16]——因其具有全局感受野覆盖和线性复杂性的动态权重而越来越受欢迎。Mamba在涉及长序列建模的任务中显示出卓越的有效性,特别是在自然语言处理中[16]。此外,更多的研究探索了其在视觉相关应用中的潜力,如图像分类[33]、医学图像分割和3D场景理解[28]。受到这些好处的启发,作者介绍了Sigma,一个用于多模态传感器融合的双胞胎Mamba网络,利用了Mamba的最新进展,并将其应用于具有挑战性的语义分割领域。
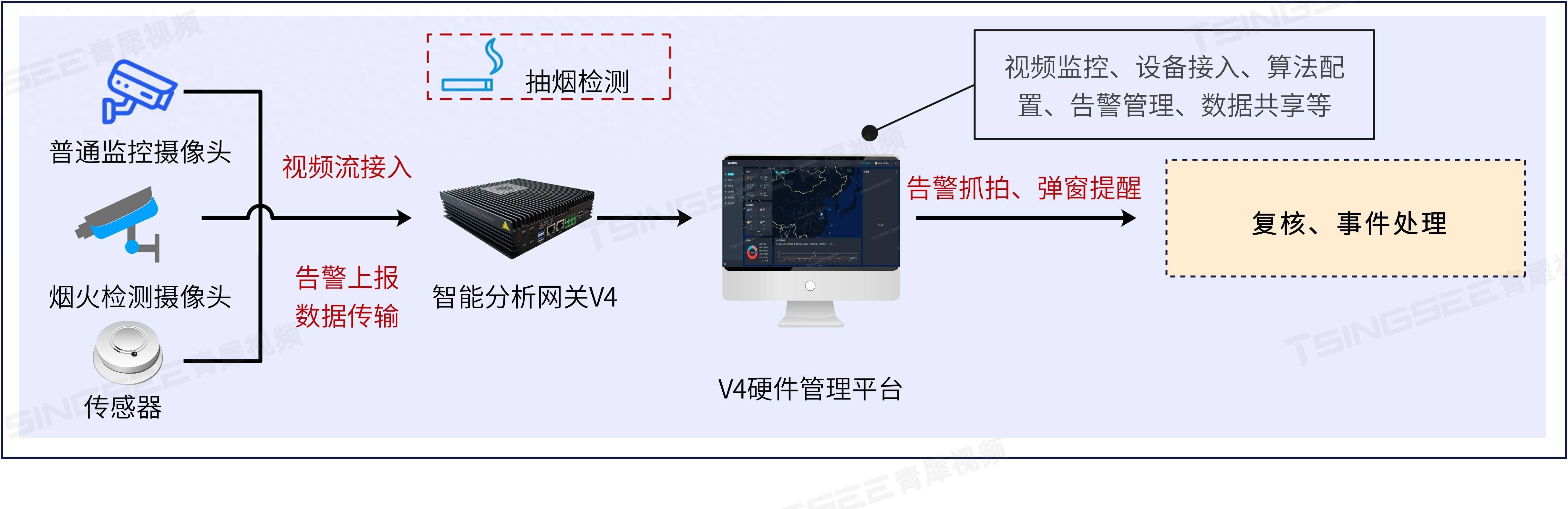
如图2所示,作者的Sigma集成了一个双胞胎编码器进行特征提取,融合模块以聚集来自不同模态的信息,以及一个解码器,该解码器适用于空间和通道特定的信息。编码器主干使用级联的_Visual State Space(VSS)块_与下采样来从各种模态提取多尺度全局信息。随后,提取的特征被引导到每个 Level 的融合模块,在那里多模态特征通过_Cross Mamba Block(CroMB)进行初步交互,以增强跨模态信息。在这之后,增强的特征被_Processed by a Concat Mamba Block(ConMB),该块采用一种注意力机制来选择每个模态的相关信息。
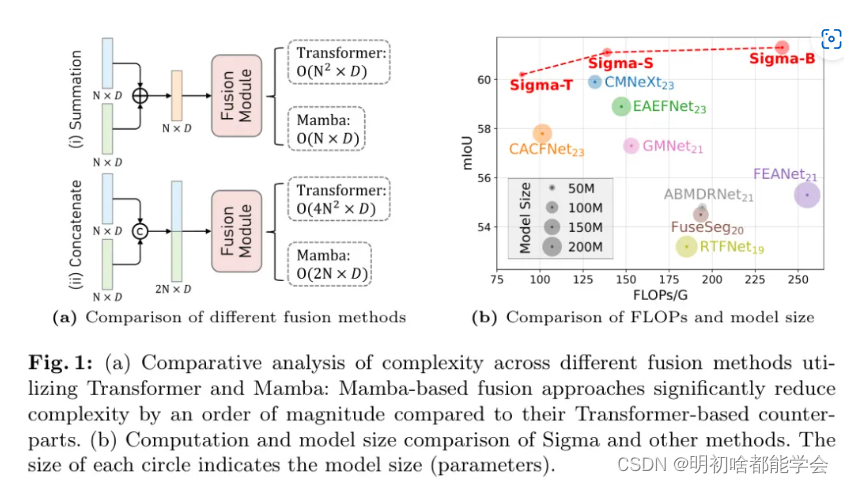
作者的融合机制利用了Mamba的线性缩放属性,显著降低了计算需求,如图1(a)所示。最后,融合后的特征被发送到多级的_Channel-Aware Visual State Space(CVSS)块_,以有效地捕捉多尺度长距离信息。
作者在RGB-热成像和RGB-深度数据集[46, 48]上进行了全面实验,证明Sigma在准确性和效率上都优于现有技术水平,如图1(b)所示。详细的消融研究进一步验证了Sigma中每个组件对整体模型有效性的贡献。
作者的贡献可以总结如下:
- 据作者所知,这是状态空间模型,特别是Mamba,在多模态语义分割中的首次成功应用。
- 作者引入了一种基于注意力的Mamba融合机制以及一个通道感知的Mamba解码器,以高效地从不同模态提取信息并将它们无缝集成。
- 在RGB-热成像和RGB-深度领域的全面评估展示了作者方法在准确性和效率方面的优势,为未来研究Mamba在多模态学习中的潜力奠定了新的基准。
Related Work
二维图像分割在计算机视觉领域有着悠久的历史,针对各种应用提出了众多算法。经典方法包括阈值化[1],边缘检测[2]和区域生长[3]。随着深度学习的发展,卷积神经网络(CNN)已成为图像分割的主流方法。FCN[4]首次提出了用于语义分割的全卷积网络,并在PASCAL VOC数据集上取得了具有竞争力的结果。随后,基于CNN的一系列方法被提出,如U-Net[5],SegNet[6]和DeepLab[7],这些方法进一步提高了语义分割的性能。
Multi-Modal Semantic Segmentation
多模态语义理解通常包括用于广泛应用的RGB模态,以及其他如热成像、深度、激光雷达等补充模态[12, 75]。这些辅助传感器为视觉系统在各种场景中提供了关键信息。例如,热传感器检测红外辐射,通过温度差异使得在黑暗和雾天条件下能够识别目标。这种能力对于监控、野火救援行动和野生动物监测等应用至关重要[14]。同时,深度传感器确定传感器与环境中物体之间的距离,提供了场景的三维表示。这项技术在自动驾驶车辆的障碍物检测和场景理解中得到了广泛利用[11]。为了优化这些附加模态的使用,开发有效的特征提取器和融合机制至关重要。
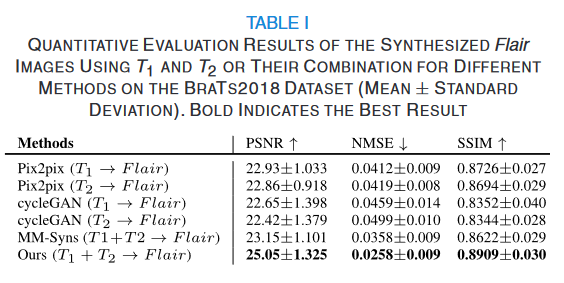
在RGB-热成像语义分割中,早期的尝试通常设计带有短路连接的编码器-解码器架构,密集连接,扩张卷积[62, 76],知识蒸馏[13]等。为了减轻CNN全局上下文理解能力的不足,许多方法在特征融合阶段应用了注意力机制。随着Transformers的日益普及,更多方法开始利用它们从RGB和热成像图像中提取长距离依赖关系。CMX[30]利用SegFormer[59]进行特征提取,并引入一个校正模块以及一个跨注意力模块进行特征融合。基于CMX[30],CMNeXt[73]提出一个自我 Query 中心,以从各种辅助模态中选择信息性特征。最近,SegMiF[32]采用级联结构与分层交互注意力机制相结合,确保两种模态之间关键信息的精确映射。
在RGB-深度语义分割领域,已在RGB-热成像分割中证明有效的方法也展示了令人印象深刻的性能,如CMX[30],CMNeXt[73]。同时,自监督预训练的最新发展为其在RGB-深度感知中的探索铺平了道路。例如,MultiMAE[1]采用带伪标签的Masked Autoencoder[23]方法,摄取来自各种模态的标记并重建被 Mask 的标记。DFormer[51]在预训练架构中整合了RGB和深度模态,以学习可迁移的多模态表示。
尽管上述基于Transformers的方法在RGB-X语义分割中由于其全局上下文建模能力而显示出有希望的结果,但Transformers中自注意力机制的二次方缩放特性限制了输入序列的长度。因此,大多数方法必须在融合之前将多模态标记(,)整合为单一标记()(图1a),这本质上导致了有价值信息的丢失,因为压缩了总序列长度。相比之下,作者提出的Sigma方法处理连接的序列,保留了所有有价值的信息,同时计算量显著减少。
State Space Models
状态空间模型(SSM),受到线性时不变(LTI)系统的启发,被认为是高效的序列到序列模型。最近,结构化状态空间序列模型(S4)[17]作为深度状态空间建模的开创性工作,特别是在捕捉长距离依赖方面。此外,通过将选择机制引入S4,Mamba[16]超越了Transformers和其他先进架构。由于SSM的卓越性能,研究行人将其扩展到计算机视觉领域。模型如ViS4mer[25],S4ND[39],TranS4mer[26]和选择性S4模型[53]展示了使用S4对图像序列的有效建模。最近,Vision Mamba[80]将SSM与双向扫描相结合,使得每个图像块与其他块相关联。
同时,V Mamba[33]将扫描扩展到四个方向,以充分捕捉图像块之间的相互关系。此外,状态空间模型已扩展到医学图像分割[38, 41, 56, 60],图像恢复[19]和点云分析[28],所有这些都在较低复杂度下展示了竞争性结果。然而,最近的工作直接将SSM作为一个即插即用的模块,没有针对特定任务的深入设计。此外,在多模态任务中SSM的探索也相对缺乏。因此,作者提出了基于注意力的Mamba融合机制和通道感知的Mamba解码器,旨在有效地增强来自各种模态的关键信息,并将它们无缝集成。通过利用针对多模态任务的专业SSM设计,作者的方法在保持低复杂度的同时获得了增强的准确性。
Sigma: Siamese Mamba Network
在本节中,作者详细介绍了作者提出的暹罗曼巴网络(Sigma)用于多模态语义分割。首先,作者提供了状态空间模型的基本信息。随后,作者概述了作者的Sigma架构,接着深入讨论了编码器、融合模块和解码器。
Preliminaries
初步研究部分的开头。
3.1.1 State Space Models.
状态空间模型(SSM)代表了一类序列到序列建模系统,其特点是在时间上具有恒定的动态特性,这种性质也称为线性时不变(LTI)。具有线性复杂度,SSM可以通过隐式映射到潜在状态有效地捕获系统的固有动态,可以定义为:

这段描述讨论了状态空间模型(SSM)中的离散化过程以及相关的方程。具体来说,状态空间模型描述了输入序列 c(t)、隐藏状态 h(t) 和输出 y(t) 之间的关系。在这个描述中,c(t) 是一个标量,h(t) 是大小为 N 的向量,表示隐藏状态,而 y(t) 是一个标量表示输出。A 是一个 N×N 的状态转移矩阵,B 是一个 N×1 的矩阵,C 是一个 1×N 的矩阵,D 是一个标量。这些矩阵被用来描述系统的动态。
为了将连续时间下的参数 A 和 B 映射到离散时间空间,SSMs 使用了零阶保持(ZOH)离散化方法。离散化过程通过以下方式描述:
- ( A = \exp(A \Delta) )
- ( B = (A \Delta)^{-1}(\exp(A) - I) \cdot AB )
- ( C = C )
- ( y_k = Ch_k + Dh_k )
在这里,所有的矩阵在迭代操作中保持相同的维度。需要注意的是,通常在方程中会丢弃 D,并且 B 可以通过一阶泰勒级数进行近似,如下所示:
- ( B = (\exp(A) - I)A^{-1}B = (A \Delta)^{-1}(\exp(A \Delta) - I) \cdot AB = AB )
这段描述讨论了状态空间模型中离散化过程的关键步骤和近似方法。
选择性扫描机制。虽然SSM对于建模离散序列是有效的,但由于其LTI属性,它们遇到了限制,因为无论输入的差异如何,参数都是不变的。为了解决这个限制,引入了选择性状态空间模型(S6,又名Mamba)[16],使状态空间模型成为输入依赖的。在Mamba中,矩阵 , , 和 来自输入数据 ,使模型能够对输入上下文有感知。借助这种选择机制,Mamba能够有效地建模长序列中存在的复杂交互。
Overall Architecture

如图2所示,作者提出的方法包括一个暹罗特征提取器(第3.3节)、一个特征融合模块(第3.4节)以及一个上采样解码器(第3.5节),形成一个完全由状态空间模型组成的架构。在编码阶段,四个具有下采样操作的视觉状态空间(VSS)块依次级联以提取多级图像特征。两个编码分支共享权重以减少计算复杂性。随后,来自每个 Level 的、两个不同分支的特征通过融合模块进行处理。在解码阶段,每个 Level 的融合特征通过一个具有上采样操作的空间感知视觉状态空间(CVSS)块进一步增强。最终,最后的特征被送入分类器以生成结果。
Siamese Mamba Encoder
VSS块是一种用于处理特征的操作,它能够保持特征维度不变。VSS块的具体细节如下:
首先,VSS块将输入特征通过一个1x1卷积层进行降维操作,将通道数减少到输入特征的四分之一。这样做的目的是减少计算量和参数数量,并为后续的处理提供更高效的特征表示。
接下来,经过一个3x3卷积层进行特征提取。这个3x3卷积层通过空间卷积操作可以捕捉到特征的空间相关性。
然后,VSS块通过一个1x1卷积层进行维度恢复操作,将通道数恢复到输入特征的原始维度。这个操作使得VSS块的输出特征与输入特征具有相同的维度。
最后,VSS块通过一个残差连接将输入特征与经过1x1卷积层处理后的特征相加,得到VSS块的输出。这个残差连接能够帮助保持特征的信息完整性,避免信息丢失。
通过多次堆叠VSS块,可以生成多尺度的深层特征,用于后续的任务处理。这些深层特征具有不同的空间分辨率和语义信息,能够提供更丰富的特征表示,提升模型的性能。
VSS块。遵循V Mamba [33]和MambaIR [19],作者使用选择性扫描2D(SS2D)模块实现VSS块。如图3的左部分所示,输入特征经过一系列线性投影(Linear)、深度卷积(DWConv)作为原始Mamba [16],然后使用SS2D模块来模拟特征中的长距离空间信息,并通过残差连接。
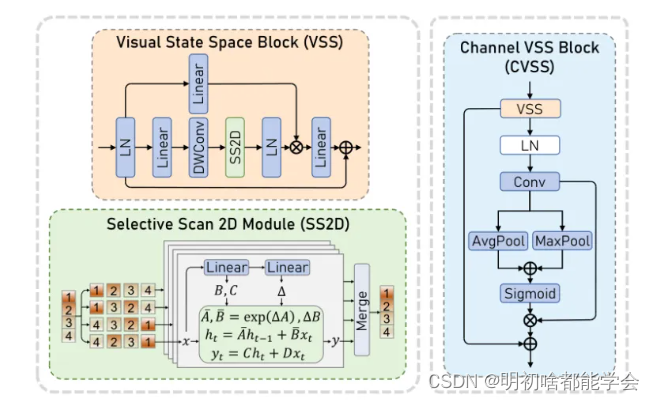
SS2D模块。在SS2D模块内,形状为 ( R \times H \times W \times C ) 的输入特征首先按照 [33] 中的 Proposal,从四个方向(从左上到右下,从右下到左上,从右上到左下,从左下到右上)展平为四个 ( R \times (H \times W) \times C ) 序列。然后使用四个独特的选择性扫描模块 [16] 提取多方向信息,其中每一个都使用方程3中的操作捕捉序列的长距离依赖性。最后,四个序列反转到同一方向并求和。