大家好,我是微学AI,今天给大家介绍一下大模型的实践应用20-一种内存高效微调技术LISA,效果比LoRA有显著提升。LISA是一种新型的微调技术,全称为Layerwise Importance Sampled AdamW,由UIUC联合LMFlow团队提出。这项技术主要针对大型语言模型(LLM)的微调问题,旨在实现内存高效的微调。LISA技术的核心在于对大型语言模型中的各个层次进行重要性采样,从而在保证模型性能的同时减少内存消耗。
一、LISA微调技术的背景
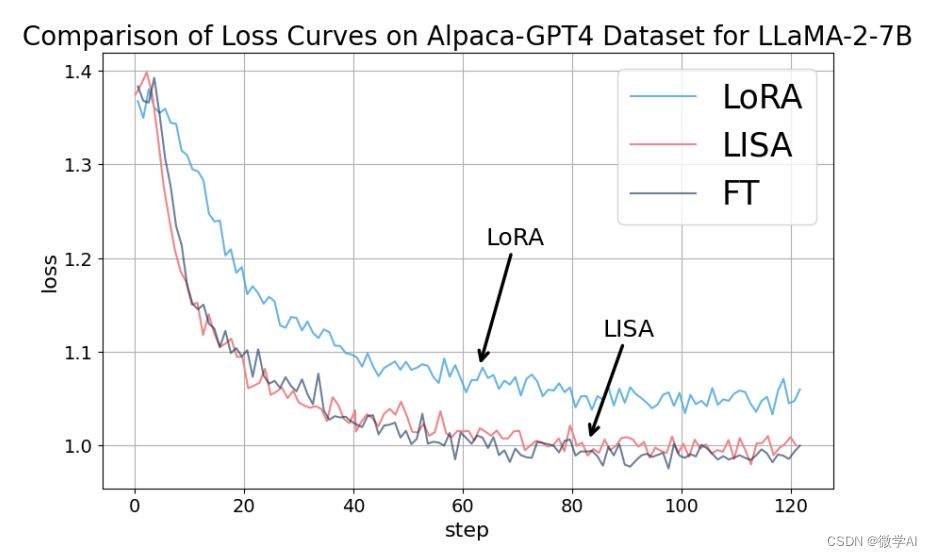
自从大型语言模型(LLMs)首次出现以来,机器学习社区见证了令人印象深刻的进步,然而它们巨大的内存消耗已成为大规模训练的一个主要障碍。为了缓解这个问题,提出了一些参数高效微调技术,如低秩适应(LoRA),但它们的性能仍然无法与大多数大规模微调设置中的全参数训练相匹敌。为了补充这一不足,我们研究了LoRA在微调任务中的逐层特性,并观察到了不同层之间权重范数的非寻常偏斜。利用这一关键观察,我们发现了出人意料地简单的训练策略,该策略在广泛的设置中优于LoRA和全参数训练,内存消耗与LoRA一样低。我们将其命名为逐层重要采样AdamW(LISA),这是LoRA的一个有前途的替代方案,它将重要性采样的想法应用于LLMs中的不同层,并在优化过程中随机冻结大多数中间层。实验结果表明,在相似的或更少的GPU内存消耗下,LISA在下游微调任务中超越了LoRA,甚至超过了全参数微调,其中LISA在MT-Bench得分上始终优于LoRA超过11%-37%。特别是在大型模型LLaMA-2-70B上,LISA在MT-Bench、GSM8K和PubMedQA上的性能与LoRA相当或更好,展示了其在不同领域的有效性。
二、原理说明
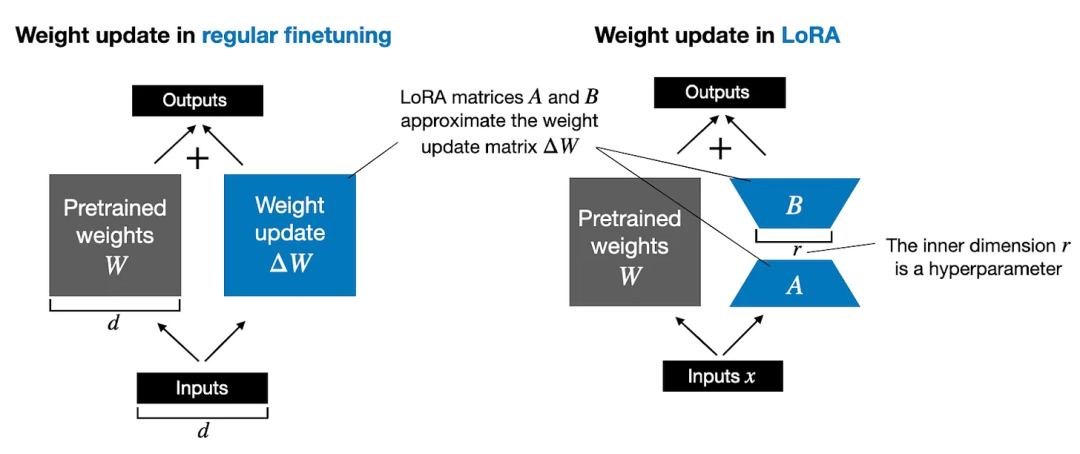
LISA算法的核心思想是:始终更新底层embedding和顶层linear head,同时随机更新少数中间的self-attention层,比如2-4层。这种做法可以让模型在指令微调任务上超过LoRA甚至全参数微调,同时还能降低空间消耗和LoRA相当甚至更低。LISA的收敛性质比LoRA有显著提升,达到了全参数调节的水平。此外,LISA由于不需要像LoRA那样引入额外的adapter结构,计算量小于LoRA,速度比LoRA快近50%。在理论性质上,LISA也更加容易分析,可以使用Gradient Sparsification、Importance Sampling、Randomized Block-Coordinate Descent等数学工具进行分析。

三、LISA与LoRA微调的对比
LISA与LoRA相比,具有以下几个方面的优势:
效率提升:LISA的速度比LoRA快约50%。
内存消耗:LISA的总空间消耗低于LoRA,70B的总空间消耗降低到了80G*4,而7B则直接降到了单卡24G以下。
模型性能:LISA在指令微调任务上超过了LoRA和全参数微调。
算法简化:LISA不需要像LoRA那样引入额外的结构,使得算法更为简洁。
适应性:LISA对更深网络和梯度检查点技术更加友好,能够带来更大的空间节省。
四、算法步骤说明
为了利用前述发现,我们希望模拟LoRA的更新模式,通过采样不同的层进行冻结。这样,我们可以避免LoRA固有的有限低秩表示能力的不足,并模仿其快速学习过程。直观地说,考虑到层间相同的全局学习率,LoRA中权重范数小的层在完全参数设置中解冻的概率也应该小,这样,各层在迭代过程中的预期学习率可以保持不变。这正是重要性采样的思想(Kloek和Van Dijk,1978;Zhao和Zhang,2015),我们在完全参数设置中不是应用层间的不同学习率 { η t ℓ } \{\eta_t^\ell\} {ηtℓ}来模仿LoRA的更新 { η ~ t ℓ } \{\tilde{\eta}_t^\ell\} {η~tℓ},而是应用采样
η t ℓ = η ~ t ℓ ⋅ w ~ ℓ w ℓ ⇒ η t ℓ = η ⋅ p ℓ , p ℓ = w ~ ℓ w ℓ \eta_t^\ell = \tilde{\eta}_t^\ell \cdot \frac{\tilde{w}^\ell}{w^\ell} \Rightarrow \eta_t^\ell = \eta \cdot p^\ell, \quad p^\ell = \frac{\tilde{w}^\ell}{w^\ell} ηtℓ=η~tℓ⋅wℓw~ℓ⇒ηtℓ=η⋅pℓ,pℓ=wℓw~ℓ
这产生了我们的逐层重要性采样AdamW方法,如算法1所示。在实践中,由于LoRA中除了最底层和最高层之外的层的权重范数都较小,我们实际上采用了 { p ℓ } ℓ = 1 N L = { 1.0 , γ / N L , γ / N L , … , γ / N L , 1.0 } \{p^\ell\}_{\ell=1}^{N_L} = \{1.0, \gamma/N_L, \gamma/N_L, \ldots, \gamma/N_L, 1.0\} {pℓ}ℓ=1NL={1.0,γ/NL,γ/NL,…,γ/NL,1.0},其中 γ \gamma γ控制了优化过程中解冻层的预期数量。直观上, γ \gamma γ作为一个补偿因子,弥合了LoRA和全参数调整之间的差异,让LISA模仿LoRA类似的层间更新模式。为了进一步控制在实际设置中的内存消耗,我们每次随机采样 γ \gamma γ层,以在训练过程中上限未冻结层的最大数量。
LISA算法的步骤主要包括以下几个环节:
初始化:首先,需要加载预训练的大型语言模型,并准备好待微调的任务数据。
层间重要性采样:LISA会根据预设的策略(例如,基于权重范数的策略)来选择哪些层需要更新。通常,只有少数几层会在每次迭代中被更新。
更新策略:对于选定的层,LISA会使用优化算法(如AdamW)来更新其权重。
梯度检查点:为了避免在反向传播过程中消耗过多的内存,LISA可以利用梯度检查点技术来节省内存。
重复采样:LISA会重复执行层间采样和更新步骤,直到达到一定的迭代次数或满足性能指标为止。

五、多尺度微调
为了进一步展示LISA在大规模LLMs上的可扩展性,我们在LLaMA-2-70B(Touvron等人,2023b)上进行了额外的实验。
我们引入了一套针对数学和医学QA基准的领域特定微调任务。GSM8K数据集(Cobbe等人,2021年),包含7473个训练实例和1319个测试实例,用于数学领域。对于医学领域,我们选择了PubMedQA数据集(Jin等人,2019年),它包括211.3K个人工生成的QA训练实例和1K个测试实例。这些数据集的统计信息总结在表2中。对PubMedQA数据集(Jin等人,2019年)的评估使用了5次提示设置,而GSM8K数据集(Cobbe等人,2021年)的评估是使用Chain of Thought (CoT)提示进行的,如近期的研究(Wei等人,2022年;Shum等人,2023年;Diao等人,2023b年)所建议。关于超参数,我们对LoRA采用秩256,对LISA采用E+H+4L,更多细节可以在附录A中找到。
结果 如表所示,与LoRA相比,LISA在性能上始终更优或与之相当。此外,在指令调整任务中,LISA再次超越了全参数训练,使其成为这一设置中的有竞争力方法。特别是,图5突出了模型在各种方面的表现,尤其是在写作、角色扮演和STEM方面,LISA优于所有方法。除此之外,LISA在所有子任务上的表现一致优于LoRA,突显了LISA在多样化任务中的有效性。图表还将黄色LoRA线与紫色Vanilla线进行了对比,揭示出在70B这样的大型模型中,LoRA的表现并不如预期,只在特定方面显示出边际改进。

六、应用场景
LISA技术的应用场景广泛,尤其是在需要对大型语言模型进行微调的场景中。例如,可以在推理分割任务中应用LISA,通过自我推理能力增强现有的视觉分割器,处理复杂推理和世界知识的任务。此外,LISA还可以用于多模态大型语言模型,通过将分割功能注入到多模态LLM中,解锁当前感知系统的自我推理能力。
七、结论
在本文中,我们提出了逐层重要性采样AdamW(LISA),这是一种基于给定概率随机冻结LLM层的优化算法。受到LoRA权重范数分布偏斜观察的启发,我们引入了一种简单且内存高效的冻结范式,用于LLM训练,在包括LLaMA-2-70B在内的各种模型的下游微调任务上,其性能显著优于LoRA。进一步针对特定领域的训练实验也证明了其有效性,显示出LISA作为LoRA替代方案在LLM训练中的巨大潜力。
LISA技术在提高大型语言模型微调效率、节约内存消耗以及提升模型性能方面具有显著的优势。与LoRA技术相比,LISA以其更快的速度、更低的内存消耗和更好的模型性能表现,成为了一个更有效的微调选项。这使得LISA有望在大模型的普及和发展中扮演重要角色,尤其是在资源有限的情况下。
最后给大家介绍一下来源:
论文链接:https://arxiv.org/abs/2403.17919
开源地址:https://github.com/OptimalScale/LMFlow





















![[目标检测] OCR: 文字检测、文字识别、text spotter](https://img-blog.csdnimg.cn/direct/91748be96c9d4ad9940de92ffa9ee9bf.png)