文章目录
前言
在深度学习领域,计算机视觉技术的发展日新月异,不断推动着图像识别、目标检测等应用的革新与进步。作为这一领域极具影响力的框架之一,YOLOv5以其卓越的速度、准确性和易用性,成为了众多开发者和研究者进行实时目标检测任务的首选工具。尤其是其基于PyTorch实现的简洁架构,不仅便于理解和修改,还能够无缝对接Python丰富的生态系统,进一步提升了开发效率与灵活性。
然而,面对YOLOv5与Python环境的搭建,初学者往往面临诸多挑战:如何高效配置依赖环境?如何确保兼容性强、性能优的硬件加速支持?如何从源码编译到项目实战,步步为营地展开深度学习之旅?本文正是为此应运而生,旨在提供一份详尽、实用的Python与YOLOv5安装教程,引领读者顺利步入目标检测技术的大门。
一、什么是 yolov5?
yolov5 是实时目标检测模型,以高效、精准著称,采用Focus、CSP、SPP等结构,通过网格划分预测物体位置、类别与置信度,运用Mosaic增强泛化性,提供多种尺寸变体,兼顾速度与精度。
二、部署过程
1. 下载 Python 3
根据 yolov5 官方在 Github 的说明,要想成功运行 yolov5,需要至少 Python 3.8 及以上才能运行。建议安装最新的 Python 版本。
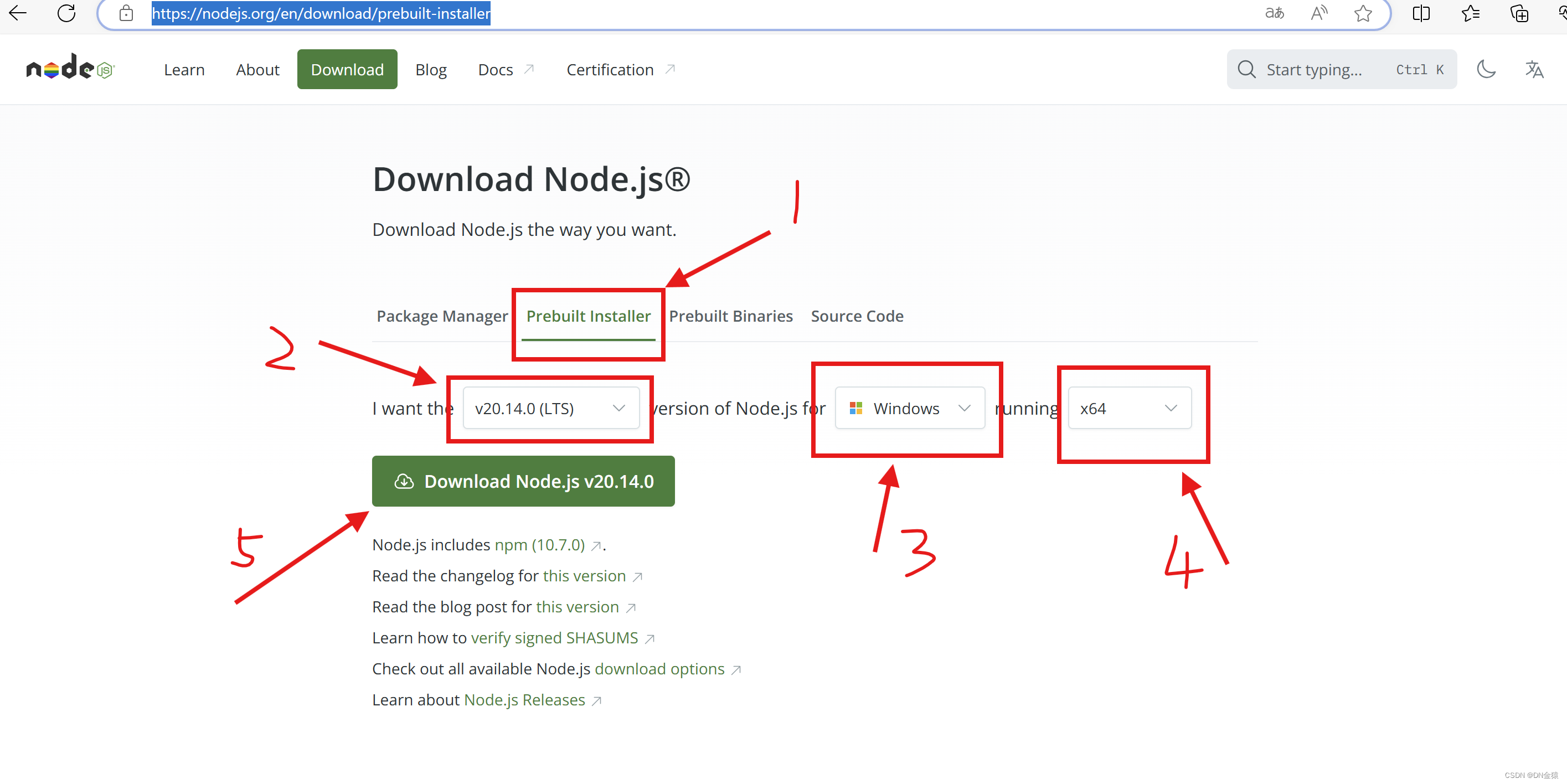
由此进入 Python 官方下载地址,如果官方地址下载较慢,也可以选择 国内镜像站 。在这里选择合适的 Python 版本下载。本文以 Windows 平台和 Python 3.12 为例。
下载了正确的 Python 版本后,双击打开安装包:

在这一步, 确保勾选了 “Add python.exe to PATH” ,还有一个选项框可以选也可以不选。勾选完后点击 Customize installation,进入下一步安装过程。
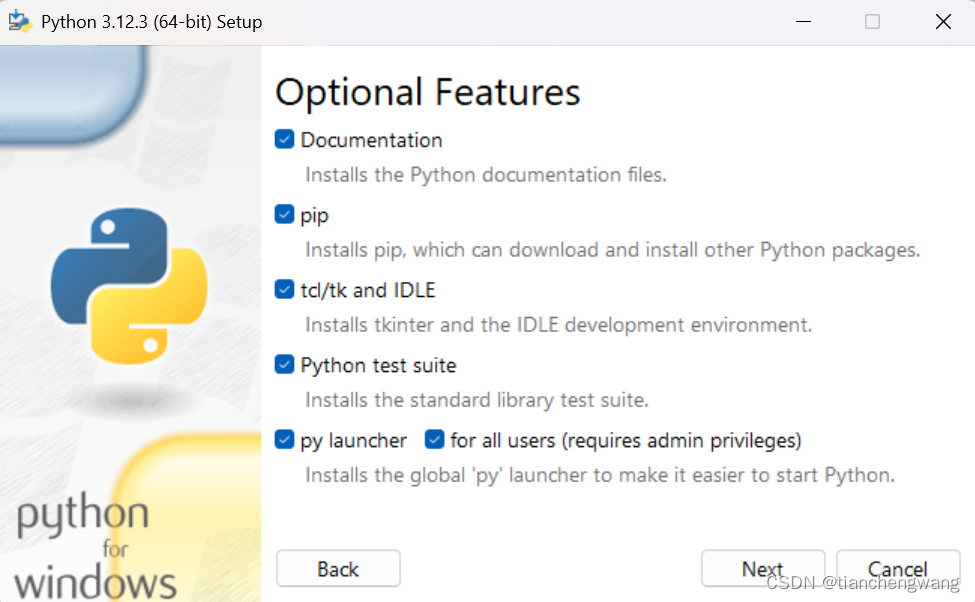
这一步不动,点击 Next。
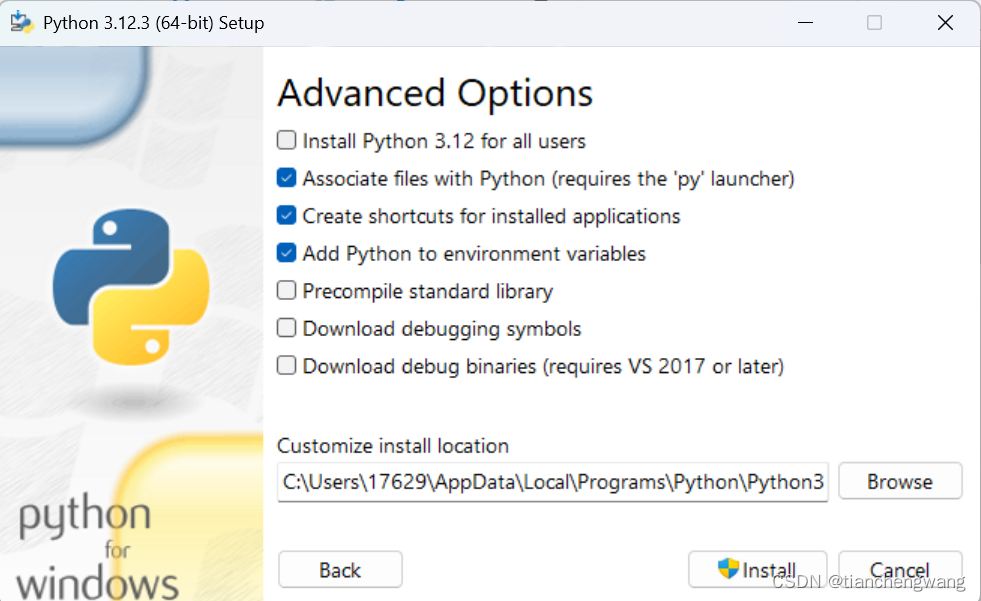
在这一步,勾选 Install Python 3.X for all users,Precompile standard library,剩下两个随意。
同时安装路径建议修改,因为 yolov5 依赖 PyTorch,C盘空间不足建议选择其他盘。
做完上述操作后,点击 Install 即可安装。
安装完成后,打开 Windows Terminal或 cmd 终端窗口。在打开的窗口中输入以下内容:
python --version
如果能正确输出版本号,如 3.12.3 之类的版本号,即为安装成功。
2. 更换镜像源
由于国内网络的原因,在国内访问 PyPI 可能会比较慢,网速可能也不够理想。因此在这一步需要换源,此处建议替换为 清华源。
在终端中输入:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
即可实现换源。
3. 安装 PyTorch
PyTorch 的安装取决于本机实际硬件情况。因此 不建议 直接从 pip 上下载,而是从 PyTorch 官网 获取下载链接下载。
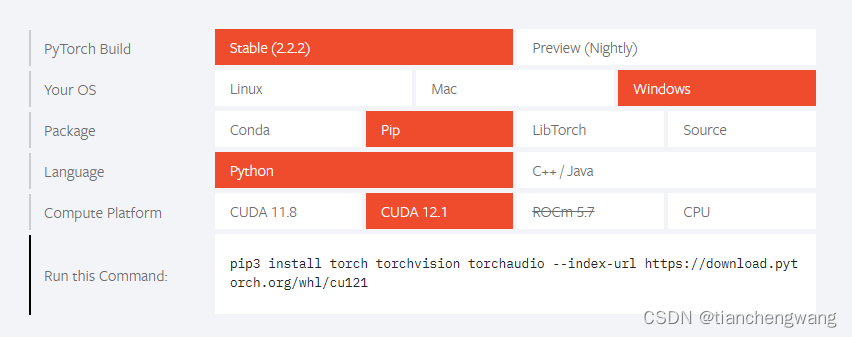
N 卡用户初次使用 PyTorch 时,往往会在上面界面中的 Compute Platform 中感到疑惑,如果正确安装了N 卡驱动,在终端输入:
nvidia-smi
便可以看到 CUDA 版本。选择和上方给出的版本中最接近的一个版本,复制给出的命令,在终端中粘贴,等待下载安装完成。由于 PyTorch 体积较大,此处可能会占用不少时间。
4. 获取 yolov5 源码
进入 yolov5 的 Github 仓库,下载 源代码 到任意位置,要求全英文路径。
源代码下载并解压完成后,在地址栏输入 cmd 或 powershell,打开终端窗口。
注意: 终端接下来需要多次使用,如无需要,请保持终端窗口打开状态, 并且不要随意改变终端定位路径。
在打开的终端中输入以下内容安装相关依赖:
pip install -r requirements.txt
安装完依赖后,打开 VSCode,PyCharm 等代码编辑器,并让编辑器打开源代码所在的文件夹。
在 源代码根目录 打开 detect.py ,并运行代码。该文件可用于进一步检查环境搭建情况。具体所需时间视网络环境而定。
5. 参数解释以及运行示例代码
接下来打开 train.py 文件,定位到 parse_opt 函数。该函数主要负责程序运行时需要的参数。
由于 yolov5 中的参数较多,本文仅选择几个作为介绍。
--weights 指定预训练权重文件路径,用于初始化模型。在 detect.py 中,yolov5 会自行下载 yolov5s.pt 并放在根目录。
--data 指定数据集配置文件(.yaml文件),包含训练集、验证集、类别列表、标签文件路径等信息。
--epochs 指定训练的总轮数
--batch-size 指定训练时每个批次包含的样本数
--imgsz --img --img-size 输入图像的尺寸,通常为正方形,如 640 表示图像被缩放到640x640像素
我们先运行示例代码,确保示例代码运行正常,再替换自己要训练的数据。
在终端中输入:
python train.py --epochs=10 --batch-size=4
注意: --batch-size 的具体取值与硬件配置有关,本文作者使用的硬件配置为 16 GB 的 RAM 以及 Nvidia GeForce RTX 4060 Laptop 运行上面的参数可以正常运行,具体参数请根据实际情况调整。
如果没有报错,并且看到类似于 Results saved to runs\train\exp 即为运行成功。
6. 使用自己的图片训练
假设你已经准备好了一组图片。将图片放在 /data/images 内,替换里面原本自带的图片。
做图片标注可以使用 精灵标注助手 或者其他的标注软件。在文件导出时务必选择符合 pascal-voc 规范的 xml 文件。将其全部放在 /data/xmls 内。
接下来,在 data 文件夹内新建一个文件,文件名为 xml2label.py ,放入以下内容:
import os
import xml.etree.ElementTree as ET
def convert_xml_to_yolo_v5_txt(xml_file, output_dir, img_dir):
# 解析XML文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像文件名及尺寸(用于坐标归一化)
img_name = root.find('filename').text
img_path = os.path.join(img_dir, img_name)
size = root.find('size')
img_width = int(size.find('width').text)
img_height = int(size.find('height').text)
# 创建输出txt文件路径
label_file = os.path.join(output_dir, os.path.splitext(img_name)[0] + '.txt')
with open(label_file, 'w') as f:
for obj in root.findall('object'):
# 提取类别名称
class_name = obj.find('name').text
# 提取坐标信息并进行归一化
bndbox = obj.find('bndbox')
xmin = float(bndbox.find('xmin').text)
ymin = float(bndbox.find('ymin').text)
xmax = float(bndbox.find('xmax').text)
ymax = float(bndbox.find('ymax').text)
# 计算归一化后的中心点坐标和宽高
center_x = (xmin + xmax) / 2 / img_width
center_y = (ymin + ymax) / 2 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
# 将类别名称转换为类别ID(假设类别ID是从0开始的整数,需要提前定义类别映射)
class_id = names.index(class_name)
# 写入txt文件,格式为:类别ID 中心点x 中心点y 宽 高
f.write(f"{class_id} {center_x} {center_y} {width} {height}\n")
def process_images_and_xmls(images_dir, xmls_dir, labels_dir):
if not os.path.exists(labels_dir):
os.makedirs(labels_dir)
for img_file in os.listdir(images_dir):
img_name, img_ext = os.path.splitext(img_file)
if img_ext.lower() != '.jpg' and img_ext.lower() != '.png':
continue # 跳过非图片文件
xml_file_path = os.path.join(xmls_dir, img_name + '.xml')
if not os.path.isfile(xml_file_path):
print(f"Warning: XML file not found for image '{img_file}'. Skipping.")
continue
convert_xml_to_yolo_v5_txt(xml_file_path, labels_dir, images_dir)
# 示例用法
images_dir = "images"
xmls_dir = "xmls"
labels_dir = "labels"
names = ["cake"]
process_images_and_xmls(images_dir, xmls_dir, labels_dir)
代码最后几行中的 names 是一个 List,这个列表内的数据取决于你实际标注时使用的名称,需要根据实际情况更改。
修改好文件后,打开终端,确保终端所在的位置为 data 文件夹
如果你在终端中看到是类似这种情况:
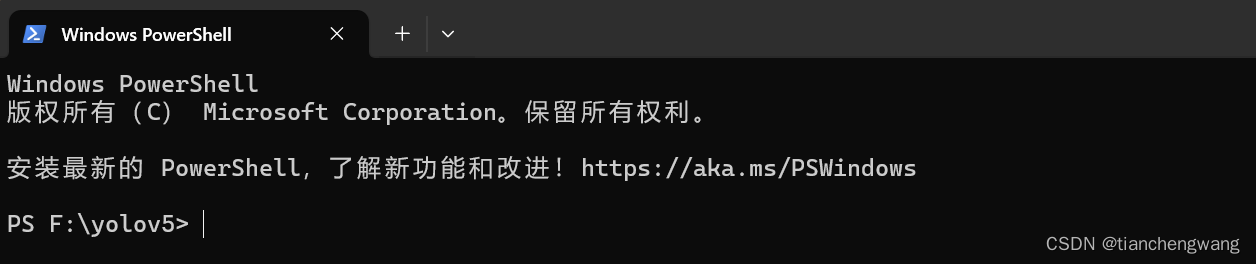
其中终端所在的 F:\yolov5 为代码的根目录,那么这个时候需要先执行以下内容:
cd data
再执行:
python xml2label.py
警告: 请不要直接执行 python data/xml2label.py 看似这行代码和上面的两步操作没有区别,但由于 Python 工作目录不同,会导致结果异常!
不出意外的话,运行之后会在 data/labels 文件夹中看到执行结果。
最后,在 data 文件夹下新建 mydataset.yaml 文件,添加以下内容:
path: data/
train: images/
val: images/
names:
0: cake
同样的:names 中的内容需要更改,并与 xml2label.py 中的 names 列表 保持一致。
例如:xml2label.py 中的 names 列表是这样的:
names = ["cat", "dog"]
那么 mydataset.yaml 文件中的内容则是:
names:
0: cat
1: dog
准备好以上内容之后,就可以开始训练了。
切换终端路径:
cd ..
然后输入以下内容:
python train.py --data .\data\mydataset.yaml --epochs 100 --batch-size=4
其中 --epochs 和 --batch-size 可根据实际情况调整。
运行上方的代码之后, yolov5 就已经开始训练了,具体需要消耗时间长短取决于图片数量和机器硬件水平。

训练结束后,如果看到类似于上面的窗口,就代表训练成功了。可以在终端输出的最后一行中提供的路径查看训练结果。
总结
本文全面介绍了Python与YOLOv5安装的全过程,旨在帮助读者轻松搭建高效、稳定的深度学习开发环境。从Python环境配置、硬件加速支持,到PyTorch安装、YOLOv5源码编译、依赖库安装,每个环节均提供了详尽的步骤与实用建议。通过实战演练,读者得以在配置好的环境中亲身体验YOLOv5的基本任务执行。






















![[Linux][环境配置][yum][vim][gcc/g++][gdb][makefile][git]详细讲解](https://img-blog.csdnimg.cn/direct/73c0478c24734f2792652e03a4dadcc2.png)


![华为OD-C卷-攀登者1[100分]](https://img-blog.csdnimg.cn/direct/538ba52235ab42708ca3c6a9ea7b1fcc.png)