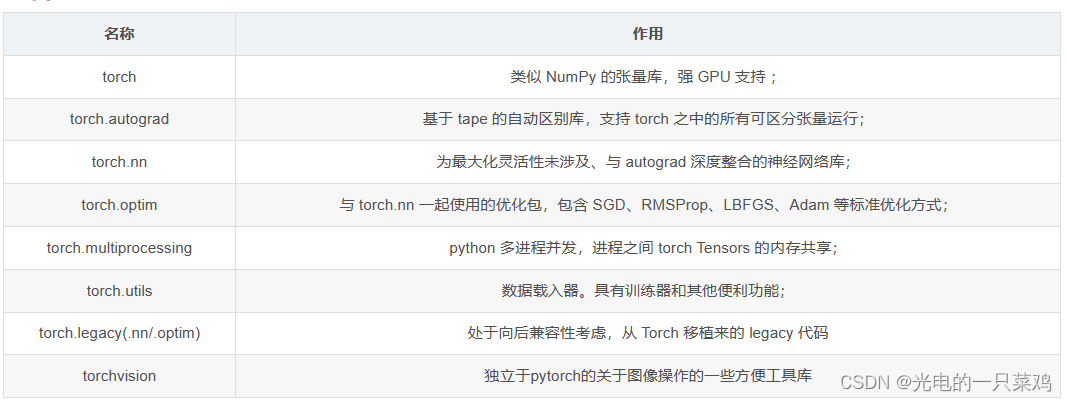
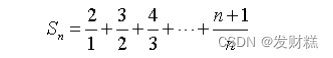1. Self-QA技术
1.1. 为什么要用Self-QA技术
关于为什么要搜集问答对,我在创新实训2024.04.07日志:提取QA对这篇文章中提到过:训练大模型需要从业务侧积累的问题、资料、文档中提取出一些指令-问答对作为输入的语料。
之前我们对于问答对的提取技术是通过对易学百科全书进行文档分割与分词,根据一些特征、标志来提取问题及其相应的回答。这建立在预处理后的易学百科全书是一个结构化的文本的基础上:前一个段落是问题,那么后一个段落一定是相应的回答,再后一个段落一定是下一个问题。
而易学相关的资料远远不止这本《易学百科全书》,我们还有许多原始的、未经过人工预处理的无结构文本。这些文本的内容和形式没有规律,因此无法采用原来的方式提取QA对。例如山东大学易学研究中心筹办30余年的《周易研究》期刊,上面涉及了大量的权威易学方面的著述,都是作为模型训练所需的语料的优质文档。当问题也如上所述,这些文档都是无结构的。例如:

这样的文档并没有明确地提出一个问题及其对应的解答,而是需要读者去仔细阅读、理解,并根据文章内容归纳出问题与解答。
而30余年的资料,我们团队并没有这么多人力与时间去仔细分析。因此我们便倾向于使用大语言模型,为我们阅读这批资料。
1.2. 什么是Self-QA技术
Self-QA技术的定义
Self-QA(Self Question Answering)技术是一种自然语言处理(NLP)技术,它旨在通过生成问题并自行回答来增强机器对文本的理解。这种技术通常用于提升机器学习模型,尤其是深度学习模型在问答、文本理解和生成等领域的性能。
Self-QA技术的核心思想是通过模型自身生成的问题来测试和提高其对文本的理解能力。在这个过程中,模型需要对给定的文本内容进行深入分析,生成相关的问题,然后使用文本内容来回答这些问题。通过这种方式,模型可以在没有额外标注数据的情况下进行自我训练和优化。
Self-QA技术的特点
自我监督学习:Self-QA技术是一种自我监督学习方法,这意味着模型不需要大量的标注数据来提高性能。模型通过生成问题并自行回答来进行自我训练,从而提高对文本的理解能力。
增强理解能力:通过自我生成的问题,模型被迫深入理解文本内容,这有助于提高模型对文本的语义理解。这种深入理解对于问答系统、文本摘要和机器翻译等任务至关重要。
数据集生成:Self-QA技术可以用于生成大规模的问答数据集。通过让模型对各种文本内容进行自我提问和回答,可以创建出大量的训练数据,这对于训练更强大的NLP模型非常有用。
可解释性:Self-QA技术可以提高模型的可解释性。由于模型需要生成问题并回答问题,这可以帮助研究人员和开发者理解模型是如何理解文本的,以及模型的决策过程。
可以看到,这项技术的增强理解能力、数据集生成能力,都是我们这个项目前期准备语料时迫切需要的。
2. 实现一个简单的Self-QA应用程序
在创新实训2024.04.11日志:self-instruct生成指令这篇文章中,我介绍了智谱AI开发平台。Self-Instruct任务就是基于这个平台的API完成的。
在本次任务中,我们仍选用该开发平台实现Self-QA应用程序。如果你对于这个平台还不了解,请移步我于04.11撰写的日志以及官网了解情况。
2.1. 掉电与宕机的容错机制
首先我们先来看一下原始语料长成什么样。简单来说就是一个根目录下,放置着某些年份的文件夹,进入某个文件夹后,放的是这一年每一期的文件夹,再向下一级就是每一期的文章。
![]()


很显然这种树型结构的文件目录结构,我们要写一个深搜/广搜来处理每一个不可再拆分的子文件。将其传输给智谱AI,命令他帮我们阅读文章并提出问答对。
不过这里的问题是,我是在自己的电脑上跑这个应用程序的。众所周知软件园校区工作日一到12点就要断电,掉电之后我的电脑不久就会因没电而关机,再次重启后就不知道应用程序执行到哪里了,或者说不知道处理到哪篇文章了。
因此我们需要加上一个掉电容错的机制,或者说我们要加入一个工作日志系统。
对此,我如是设计:
- 对于每个文件夹,规定:任务完成当且仅当
- 其下的所有子文件夹任务完成
- 其下的所有子文件任务完成(注意子文件仅涉及当前文件夹下的文件,而非子文件夹下的文件)
- 在每个文件夹下,生成一个名为"Workstation.txt”文件,其中保存了这个文件夹下的所有子文件夹名与子文件名
- 应用程序执行时,先查找当前目录的Workstation.txt文件,查看其中保存的任务名(子文件夹名+子文件名)。
- 随后,对于子文件,通过API接口喂给智谱AI平台,生成问答对并保存。
- 对于子文件夹,递归地调用这个过程。
- 当且仅当一个文件夹的任务完成时,我们清空其Workstation.txt文件中的文本。
当掉电发生时,我们重启机器与这个应用程序,至多冗余地询问某一年某一期的所有文章,但这样保证了我们一个任务都不会漏掉。
对于Workstation.txt的生成,显然也是个DFS就可以解决的。这里我要说一下,我一直都是个java程序员,因此我写代码的首选语言肯定是java,但是java做数据处理不太方便,因此有时候我会改成python。对于这个生成Workstation.txt的工作,用java很方便,我就选了java。
package Scripts;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class GenerateWorkStation {
static TargetDocRule target;
public static void main(String[] args) throws IOException {
String root = args[0];
File f = new File(root);
assert f.isDirectory();
target = new TargetDocRule(args[1]);
dfs(f);
}
private static void dfs(File f) throws IOException {
StringBuilder sb = new StringBuilder();
File[] files = f.listFiles();
assert files != null;
for (File child : files) {
String name = child.getName();
if(child.isDirectory()){
dfs(child);
sb.append(name).append("\n");
}
if(target.isTargetFile(name)){
sb.append(name).append("\n");
}
}
File file = new File(f.getAbsolutePath()+"\\Workstation.txt");
if(!file.exists()){
boolean created = file.createNewFile();
assert created;
}
try(FileWriter fw = new FileWriter(file)){
fw.append(sb.toString());
}
System.out.println("成功为"+f.getName()+"创建工作目录");
}
}
这个深搜的逻辑很简单了,创建文件并写入子文件名与子文件夹名也是基本操作。不过这里由于python对于复杂的pdf的支持不太好,因此我对于目标语料的选取,选择了docx。因此我为这个选取的过程注入了一个策略类:
class TargetDocRule{
public String docSuffix;
public TargetDocRule(String suffix){
this.docSuffix = suffix;
}
public boolean isTargetFile(String filename){
return filename.endsWith(docSuffix);
}
}每次检索到一个文件时,我们就看看他是否满足isTargetFile方法,这个方法检查了文件后缀(我的应用程序是跑在Windows操作系统上的)
举个例子,根目录下的Workstation.txt长成这样:

意味着有4个子任务待做,分别是2020-2023年。仅选择了4年的是因为智谱AI的token有限,做多了我token就不够用了,先做一部分再说。
2.2. 递归完成任务
深度优先搜索
接下来,我们就可以通过Workstation.txt的指引,完成本次Self-QA的任务。步骤如下:
- 打开本层目录的Workstation.txt
- 读取这个工作日志的内容,查看还有什么任务没有处理
- 读取一个未处理的任务,访问该文件(夹)
- 如果是文件,调用处理语料的函数
- 如果是文件夹,递归地调用该函数
- 当本文件夹地任务完成,将本层目录的Workstation.txt清空
def dfs(path):
work_station = path + '\\' + 'Workstation.txt'
with open(work_station, 'r+', encoding='UTF-8') as f:
tasks = f.readlines()
while len(tasks) > 0:
task = path + '\\' + tasks[0].rstrip()
if os.path.isdir(task):
dfs(task)
else:
do_task(task)
tasks = tasks[1:]
f.truncate(0)处理初始语料
所以重点就落在了do_task函数上:
首先,既然要调用大模型的API。我们就得想一个逻辑清晰、结构完整的Prompt。这里我先通过在线的智谱清言提问了几次,最终确定了prompt如下:
def gen_prompt(text: str) -> str:
prompt = "你是一名研究周易的专家。现在有一篇关于周易的文章,内容为:\n[" + text + "]\n"
prompt += ("请根据上述文章的内容生成5"
"个关于周易的尽可能专业且多样化的问题对(即一个问题及其对应的回答)。这些问答对中的问题可以是关于事实的问题,也可以是对相关内容的理解和评价。在提问时,请不要使用“这个”、“那个”等指示代词。\n")
prompt += "请按照以下格式生成问题与回答:\n"
prompt += "问题1:......\n回答1:......\n\n问题2:......\n回答2:......"
return prompt我们要先给大模型设置一个人设,这里就是“周易的专家”,然后把文章文本喂给它,最后告诉他生成问答对的格式,就生成了一个可用的prompt。
而文档的文本内容来自于docx文件,这里我调用了python-docx库,读取docx文档。
def read_docx(docx_path):
# 初始化一个Document对象,读取docx文件
doc = Document(docx_path)
# 初始化一个空字符串来存储文档中的纯文本
full_text = []
# 遍历文档中的每个段落
for para in doc.paragraphs:
# 添加段落文本到full_text列表中
full_text.append(para.text)
# 将列表中的文本合并成一个字符串并返回
return '\n'.join(full_text)这里我简单的采用了段落文本拼接'\n'换行符的方式生成字符串。
随后就可以请求API接口了:
global response
try:
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "user",
"content": content}
],
)
except Exception as e:
print(f"发生错误:{e}")这里有时候会监测敏感词,发生错误,因此要做一下异常处理。
随后我们就可以按提问的格式提取字符串了:
def extract_qa_pairs(input_str):
qa_pairs = []
# 分割输入字符串为问答对
pairs = input_str.split("\n\n")
# 遍历每个问答对
for i in range(len(pairs)):
pair = pairs[i]
# 分割问答对为问题和答案
lines = pair.strip().split("\n")
if len(lines) != 2:
continue
question = lines[0].strip("问题" + str(i + 1) + ": ")
answer = lines[1].strip("回答" + str(i + 1) + ": ")
# 将问答对添加到列表中
qa_pairs.append({
"question": question,
"answer": answer
})
return qa_pairs但是要注意到的是,这个列表里的数据可能和之前生成的QA对相似度很高,所以我们要做一下去重:
def compute_rouge_l_score(reference, summary):
"""
计算ROUGE-L分数
参数:
reference (str): 参考文本。
summary (str): 摘要文本。
返回:
dict: 包含ROUGE-L分数的字典,包括precision, recall, 和fmeasure。
"""
rouge = Rouge()
scores = rouge.get_scores(summary, reference, avg=True)
return scores['rouge-l']
def update_source_with_extension(source, extension, rouge_l_threshold=0.7):
"""
根据ROUGE-L分数更新source列表,将extension中与source中元素不相似(ROUGE-L分数不大于阈值)的元素添加到source中。
参数:
source (list): 原始的JSON对象列表。
extension (list): 要添加的JSON对象列表。
rouge_l_threshold (float): ROUGE-L分数的阈值,用于决定是否添加元素。
返回:
None (直接修改传入的source列表)
"""
for ext_element in extension:
ext_str = json_to_string(ext_element)
found_similar = False
for src_element in source:
src_str = json_to_string(src_element)
rouge_l = compute_rouge_l_score(src_str, ext_str)
print(rouge_l)
if rouge_l['f'] > rouge_l_threshold:
found_similar = True
break
if not found_similar:
source.append(ext_element)这里和self-instruct的pipeline不同的地方在于,我采用了rouge_l的分数,这是一个基于LCS(最长公共子序列)的评判标准。比较适合长文本之间的相似度比较。其中的f1分数是召回率r和精确率p的综合分数,如果>0.7相当于两个文本之间相似度高,我们应该予以舍弃。
最终,我们以json格式把问答对写入json文件中。
qa_pairs = extract_qa_pairs(qa)
with open('./self_QA/target/self_qa.json', 'r+', encoding='utf-8') as target_json:
context = target_json.read()
print("context:"+context)
ed = []
if context:
target_json.seek(0)
ed = json.load(target_json)
qa_json = qa_pairs_to_json(qa_pairs, ed)
print(qa_json)
target_json.truncate(0)
target_json.seek(0)
target_json.write(qa_json)3. 运行结果

4. 可能的问题
有时候大模型没那么“听话”,可能生成的QA对不符合格式,比如应该是一个问答对之间有一个空行,但是他生成出来变成了每个问题和答案之间都有一个空行。大模型在某些细节方面上可能还是没有那么智能。不过这种现象随着任务完成数的增多逐渐减少。最终还是可以完成任务的。
如果想要优化这一方面,可以从字符串的模式匹配方面入手,优化模式匹配函数,更精准的提取QA对。这个可以作为以后优化的方向。
5. 开源与复现
https://github.com/Liyanhao1209/ZhouYiLLM.git
java_scripts分支与python_scripts分支。注意,如果你要运行self_qa的脚本,请一定要先使用java_scripts分支下生成Workstation.txt的脚本,生成Workstation.txt。