1. 什么是RAG技术
RAG is short for Retrieval Augmented Generation。结合了检索模型和生成模型的能力,以提高文本生成任务的性能。具体来说,RAG技术允许大型语言模型(Large Language Model, LLM)在生成回答时,不仅依赖于其内部知识,还能检索并利用外部数据源中的信息。
对于这个概念,我自己的理解是,大模型相当于是一个人,而RAG技术检索并利用的外部数据源就是书本、或者电子/数据资料。而RAG就是人检索并根据书本或者电子资料生成任务的能力。
比如一个人一目十行,理解能力强,可以快速地汲取知识并加以理解从而输出,就代表这个人的学习能力强,就相当于RAG技术性能优越。而另一个人阅读能力差,不容易理解新知识,就相当于RAG技术没做好,性能不行。

在这张图中,我把人类智能比作RAG技术,人类比作AI,外部知识来源比作向量数据库(一般与RAG一起使用)。RAG的实现越好,那么相当于越智能,则AI的能力越强。
2. RAG技术的Working Pipeline
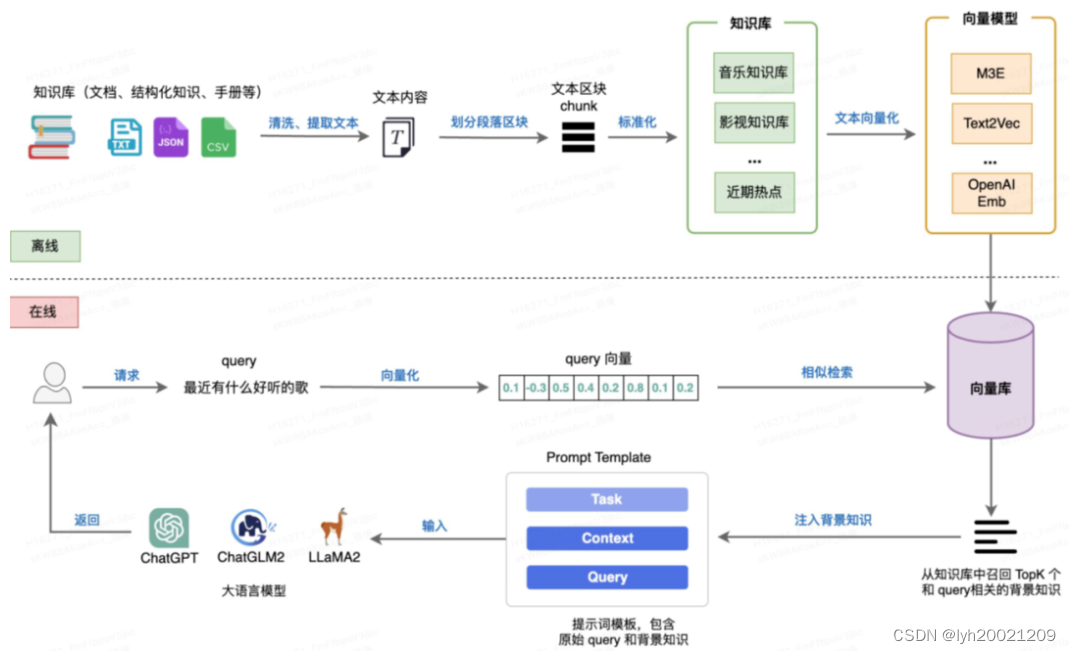
首先我们要搜集插入到向量数据库 中,也即实体的文档、结构化知识、手册,读取文本内容,进行文本分割,进行向量嵌入后插入向量数据库中。
当用户请求大模型时,首先将查询向量化,随后检索向量库得到相似度高的知识,作为背景注入到prompt,随后大模型再生成回答。
3. RAG的实现
在github上,有一个RAG实现的Web应用的Demo。Langchain-Chatchat
我们同样打算以Web应用的模式构建一个能够被请求用来检索知识的向量数据库。因此先学习阅读一下这个项目的代码。
3.1. Web应用的入口:挂载Web应用路径
这一部分其实和RAG本身关系不大了,属于是网络通信方面的部分。但因为它是整个应用的入口,所以有必要探索一下。
首先在这个项目的README文件中,我们发现了这个Web应用还有个在线的接口文档。
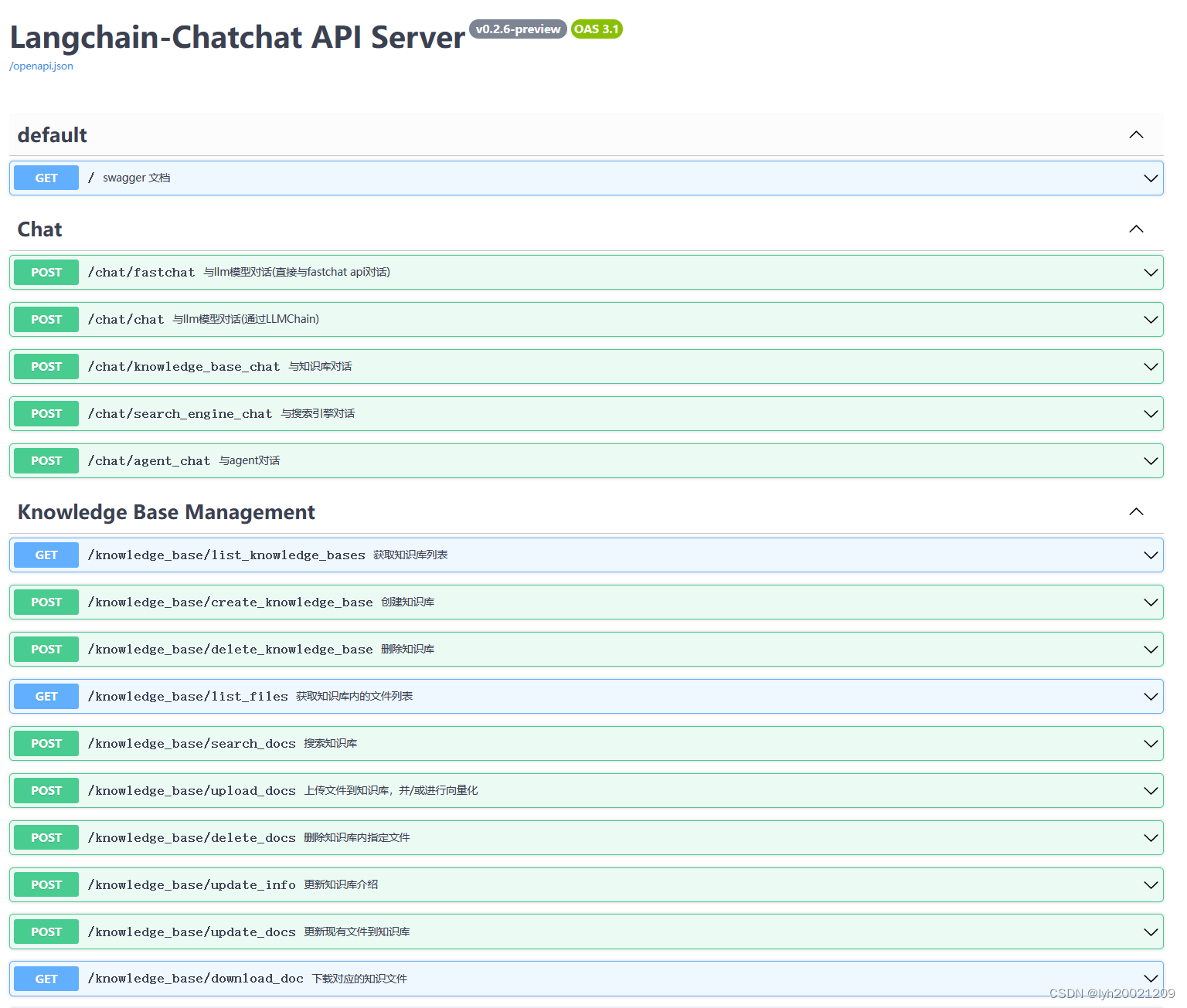
从这个接口文档中,可以看到对于知识库(Knowledge Base) 的接口,这一部分就涉及了向量数据库。
我们可以通过在IDE中全局搜索这些接口,来找到暴露这些应用路径的地方。
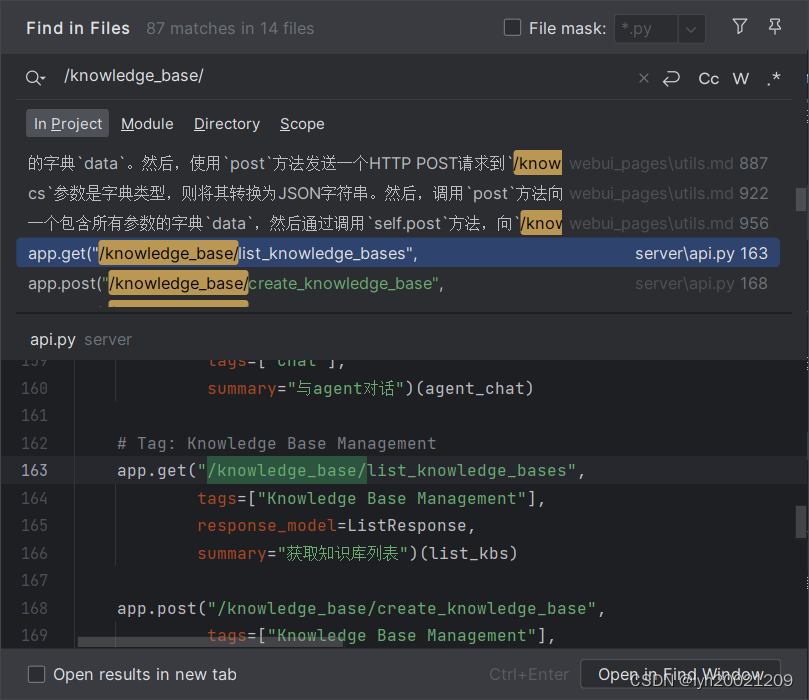
可以看到,server/api.py下挂载了这些接口,我们来到这个文件一探究竟。其中不乏这样的函数:
app.post("/knowledge_base/create_knowledge_base",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="创建知识库"
)(create_kb)
app.post("/knowledge_base/delete_knowledge_base",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="删除知识库"
)(delete_kb)
app.get("/knowledge_base/list_files",
tags=["Knowledge Base Management"],
response_model=ListResponse,
summary="获取知识库内的文件列表"
)(list_files)
app.post("/knowledge_base/search_docs",
tags=["Knowledge Base Management"],
response_model=List[DocumentWithVSId],
summary="搜索知识库"
)(search_docs)我们点到每个函数中的参数,即create_kb这样的参数,来到了一个名叫kb_api.py的文件,其中暴露了这个函数(create_kb)。
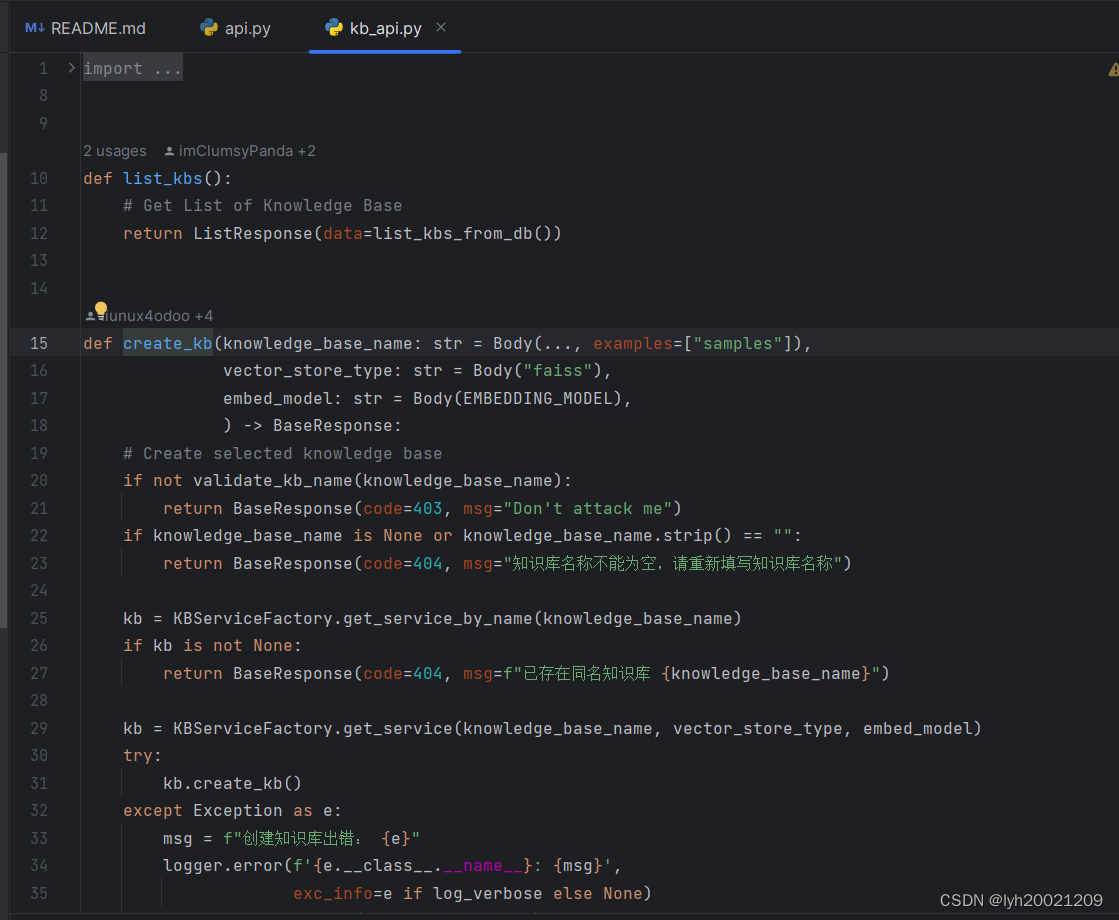
此时我们就通过挂载Web应用路径的入口,找到了与向量数据库交互的模块。
3.2. 与向量数据库交互
现在来看看这些与向量数据库交互的函数。
通过交互函数看知识库工程架构
首先我们关注到create_kb中的这样一部分代码:
kb = KBServiceFactory.get_service(knowledge_base_name, vector_store_type, embed_model)
try:
kb.create_kb()光看这个名字,我们就能知道,这是一个工厂方法的设计模式。获取知识库的方式并不是直接拿到知识库的操作柄,而是先通过提供知识库服务的工厂拿到一项知识库的服务。
对于get_service函数,如下:
@staticmethod
def get_service(kb_name: str,
vector_store_type: Union[str, SupportedVSType],
embed_model: str = EMBEDDING_MODEL,
) -> KBService:
if isinstance(vector_store_type, str):
vector_store_type = getattr(SupportedVSType, vector_store_type.upper())
if SupportedVSType.FAISS == vector_store_type:
from server.knowledge_base.kb_service.faiss_kb_service import FaissKBService
return FaissKBService(kb_name, embed_model=embed_model)
elif SupportedVSType.PG == vector_store_type:
from server.knowledge_base.kb_service.pg_kb_service import PGKBService
return PGKBService(kb_name, embed_model=embed_model)
elif SupportedVSType.MILVUS == vector_store_type:
from server.knowledge_base.kb_service.milvus_kb_service import MilvusKBService
return MilvusKBService(kb_name,embed_model=embed_model)
elif SupportedVSType.ZILLIZ == vector_store_type:
from server.knowledge_base.kb_service.zilliz_kb_service import ZillizKBService
return ZillizKBService(kb_name, embed_model=embed_model)
elif SupportedVSType.DEFAULT == vector_store_type:
from server.knowledge_base.kb_service.milvus_kb_service import MilvusKBService
return MilvusKBService(kb_name,
embed_model=embed_model) # other milvus parameters are set in model_config.kbs_config
elif SupportedVSType.ES == vector_store_type:
from server.knowledge_base.kb_service.es_kb_service import ESKBService
return ESKBService(kb_name, embed_model=embed_model)
elif SupportedVSType.CHROMADB == vector_store_type:
from server.knowledge_base.kb_service.chromadb_kb_service import ChromaKBService
return ChromaKBService(kb_name, embed_model=embed_model)
elif SupportedVSType.DEFAULT == vector_store_type: # kb_exists of default kbservice is False, to make validation easier.
from server.knowledge_base.kb_service.default_kb_service import DefaultKBService
return DefaultKBService(kb_name)那么这个是在干什么?显然,他根据向量嵌入的方式,确定要创建的数据库服务是基于哪个向量数据库的,可能是chroma,也可能是Faiss,等等。
总之,它返回了一个KBService子类的实例。而这里KBService并非是一个可实例化的类,因为它是抽象类。
在server/knowledge_base/kb_service中,我们可以看到Class Definition。
@abstractmethod
def do_create_kb(self):
"""
创建知识库子类实自己逻辑
"""
pass在类定义中,出现了@abstractmethod注解,说明这是个抽象类。
那么其实现都在哪里呢?经过一番翻阅,在server/knowledge_base/kb_service下,包括了大量的基于不同数据库的实现类。
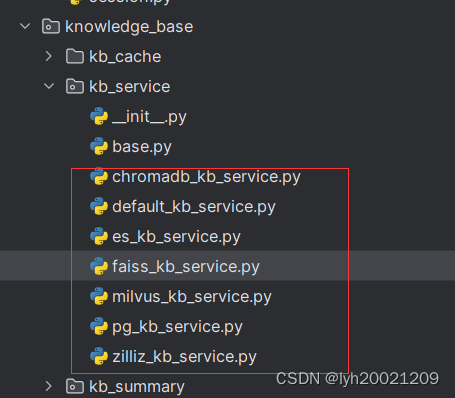
在翻阅代码时,我关注到了项目默认的向量数据库是faiss,因此我们可以来到faiss_kb_service中查看。
class FaissKBService(KBService):
vs_path: str
kb_path: str
vector_name: str = None类定义中,对于KBService的继承赫然在目。
再回到通过KBServiceFactory创建KBService处:
kb = KBServiceFactory.get_service(knowledge_base_name, vector_store_type, embed_model)
try:
kb.create_kb()我们溯源create_kb,可以发现:
def create_kb(self):
"""
创建知识库
"""
if not os.path.exists(self.doc_path):
os.makedirs(self.doc_path)
self.do_create_kb()
status = add_kb_to_db(self.kb_name, self.kb_info, self.vs_type(), self.embed_model)
return status可以看到,create_kb调用了self(实例自身)的do_create_kb()。而这就是刚才提到的抽象方法,也就是它会根据不同类对其的覆写,执行不同的逻辑。
def do_create_kb(self):
if not os.path.exists(self.vs_path):
os.makedirs(self.vs_path)
self.load_vector_store()
def load_vector_store(self) -> ThreadSafeFaiss:
return kb_faiss_pool.load_vector_store(kb_name=self.kb_name,
vector_name=self.vector_name,
embed_model=self.embed_model)例如faiss就有自己独特的创建数据库的方式。
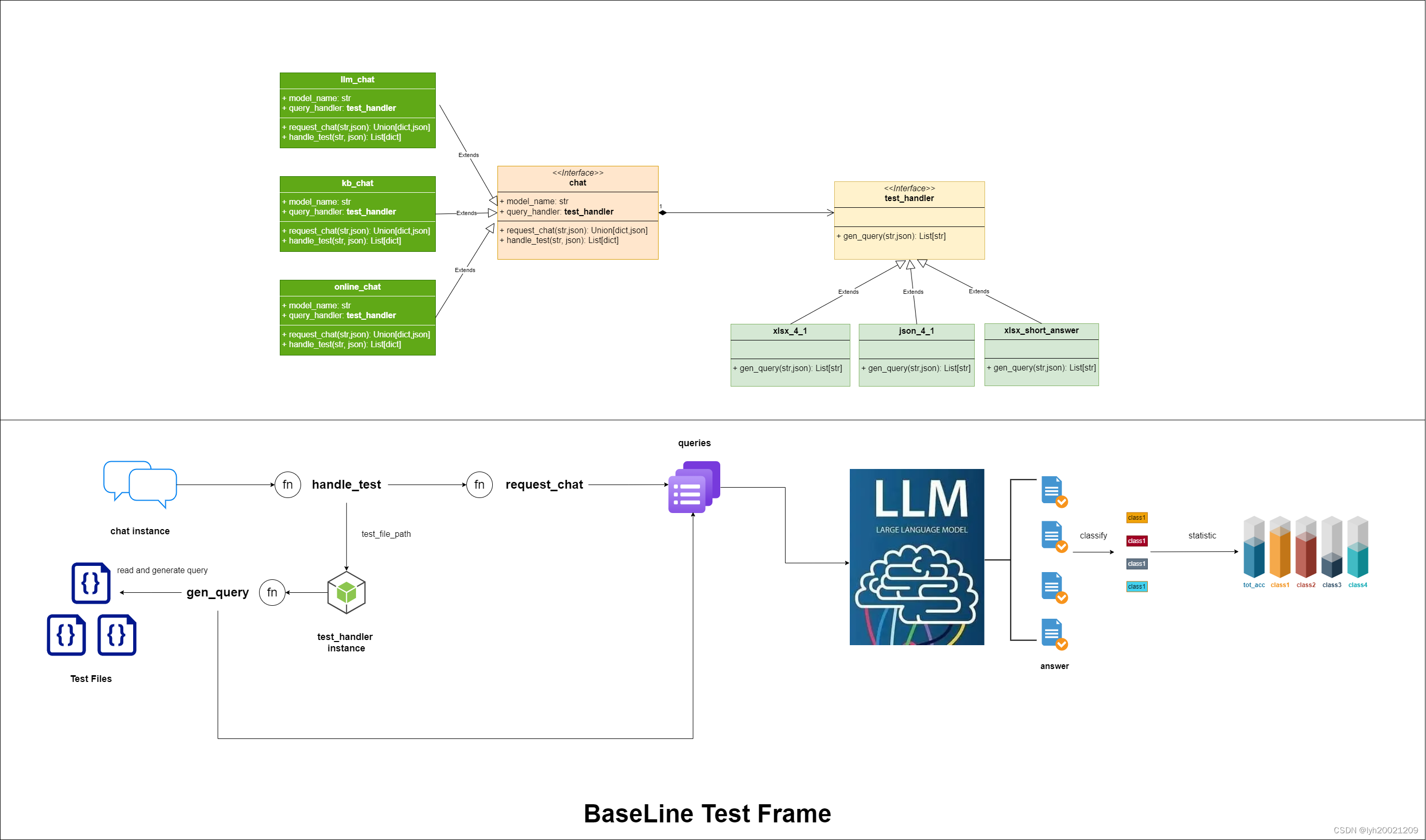
因此这个设计架构就明确了,是一个四层的Web-静态工厂-抽象类-实体类的架构。如下图所示:
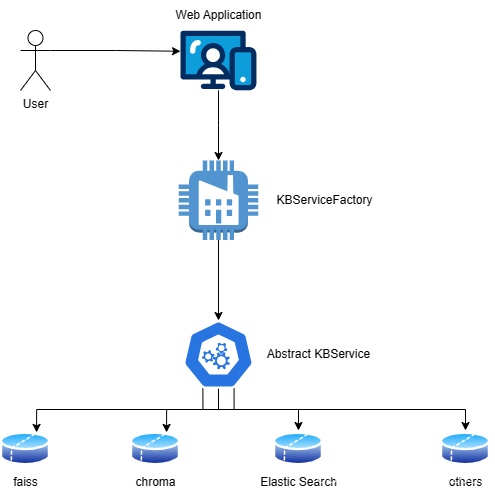
Mapping from Abstract Working Pipeline to Code
现在我们知道了如何获取一个向量数据库的服务。但在哪里使用它,如何使用它呢?正如先前RAG的Working Pipeline中所说,用户在请求大模型进行任务时,先通过检索向量数据库获取相似知识优化Prompt,再进行提问。那么这样一套流程,是如何映射到代码中的,我们是如何使用向量数据库提供的检索功能的?
找到RAG流程的入口
为了找到这个接口的入口,我还是先翻看了server/api.py文件,其中包括了:
app.post("/chat/chat",
tags=["Chat"],
summary="与llm模型对话(通过LLMChain)",
)(chat)
app.post("/chat/search_engine_chat",
tags=["Chat"],
summary="与搜索引擎对话",
)(search_engine_chat)
app.post("/chat/feedback",
tags=["Chat"],
summary="返回llm模型对话评分",
)(chat_feedback)
app.post("/chat/knowledge_base_chat",
tags=["Chat"],
summary="与知识库对话")(knowledge_base_chat)
app.post("/chat/file_chat",
tags=["Knowledge Base Management"],
summary="文件对话"
)(file_chat)
app.post("/chat/agent_chat",
tags=["Chat"],
summary="与agent对话")(agent_chat)一开始我以为/chat/chat这个接口是包括了RAG流程的接口,但后来我翻了翻代码,发觉并没有检索向量数据库。
随后经过一些翻阅,我找到了/chat/knowledge_base_chat这个一接口:
async def knowledge_base_chat(query: str = Body(..., description="用户输入", examples=["你好"]),
knowledge_base_name: str = Body(..., description="知识库名称", examples=["samples"]),
top_k: int = Body(VECTOR_SEARCH_TOP_K, description="匹配向量数"),
score_threshold: float = Body(
SCORE_THRESHOLD,
description="知识库匹配相关度阈值,取值范围在0-1之间,SCORE越小,相关度越高,取到1相当于不筛选,建议设置在0.5左右",
ge=0,
le=2
),
history: List[History] = Body(
[],
description="历史对话",
examples=[[
{"role": "user",
"content": "我们来玩成语接龙,我先来,生龙活虎"},
{"role": "assistant",
"content": "虎头虎脑"}]]
),
stream: bool = Body(False, description="流式输出"),
model_name: str = Body(LLM_MODELS[0], description="LLM 模型名称。"),
temperature: float = Body(TEMPERATURE, description="LLM 采样温度", ge=0.0, le=1.0),
max_tokens: Optional[int] = Body(
None,
description="限制LLM生成Token数量,默认None代表模型最大值"
),
prompt_name: str = Body(
"default",
description="使用的prompt模板名称(在configs/prompt_config.py中配置)"
),
request: Request = None,
):
kb = KBServiceFactory.get_service_by_name(knowledge_base_name)
if kb is None:
return BaseResponse(code=404, msg=f"未找到知识库 {knowledge_base_name}")
history = [History.from_data(h) for h in history]
async def knowledge_base_chat_iterator(
query: str,
top_k: int,
history: Optional[List[History]],
model_name: str = model_name,
prompt_name: str = prompt_name,
) -> AsyncIterable[str]:
nonlocal max_tokens
callback = AsyncIteratorCallbackHandler()
if isinstance(max_tokens, int) and max_tokens <= 0:
max_tokens = None
model = get_ChatOpenAI(
model_name=model_name,
temperature=temperature,
max_tokens=max_tokens,
callbacks=[callback],
)
docs = await run_in_threadpool(search_docs,
query=query,
knowledge_base_name=knowledge_base_name,
top_k=top_k,
score_threshold=score_threshold)
# 加入reranker
if USE_RERANKER:
reranker_model_path = get_model_path(RERANKER_MODEL)
reranker_model = LangchainReranker(top_n=top_k,
device=embedding_device(),
max_length=RERANKER_MAX_LENGTH,
model_name_or_path=reranker_model_path
)
print("-------------before rerank-----------------")
print(docs)
docs = reranker_model.compress_documents(documents=docs,
query=query)
print("------------after rerank------------------")
print(docs)
context = "\n".join([doc.page_content for doc in docs])
if len(docs) == 0: # 如果没有找到相关文档,使用empty模板
prompt_template = get_prompt_template("knowledge_base_chat", "empty")
else:
prompt_template = get_prompt_template("knowledge_base_chat", prompt_name)
input_msg = History(role="user", content=prompt_template).to_msg_template(False)
chat_prompt = ChatPromptTemplate.from_messages(
[i.to_msg_template() for i in history] + [input_msg])
chain = LLMChain(prompt=chat_prompt, llm=model)
# Begin a task that runs in the background.
task = asyncio.create_task(wrap_done(
chain.acall({"context": context, "question": query}),
callback.done),
)
source_documents = []
for inum, doc in enumerate(docs):
filename = doc.metadata.get("source")
parameters = urlencode({"knowledge_base_name": knowledge_base_name, "file_name": filename})
base_url = request.base_url
url = f"{base_url}knowledge_base/download_doc?" + parameters
text = f"""出处 [{inum + 1}] [{filename}]({url}) \n\n{doc.page_content}\n\n"""
source_documents.append(text)
if len(source_documents) == 0: # 没有找到相关文档
source_documents.append(f"<span style='color:red'>未找到相关文档,该回答为大模型自身能力解答!</span>")
if stream:
async for token in callback.aiter():
# Use server-sent-events to stream the response
yield json.dumps({"answer": token}, ensure_ascii=False)
yield json.dumps({"docs": source_documents}, ensure_ascii=False)
else:
answer = ""
async for token in callback.aiter():
answer += token
yield json.dumps({"answer": answer,
"docs": source_documents},
ensure_ascii=False)
await task
return EventSourceResponse(knowledge_base_chat_iterator(query, top_k, history,model_name,prompt_name))他这个函数签名非常长,一堆参数,但实际有用的其实主要还是集中在query,也即用户查询上,其他的都是要调用langchain的库或者与向量数据库交互的必要参数。top k个相关向量是RAG技术的一部分,也是必要的参数。
源码解读
首先,先获取了数据库服务。(当然也可能数据库不存在)
kb = KBServiceFactory.get_service_by_name(knowledge_base_name)
if kb is None:
return BaseResponse(code=404, msg=f"未找到知识库 {knowledge_base_name}")随后选择LLM模型实例:
model = get_ChatOpenAI(
model_name=model_name,
temperature=temperature,
max_tokens=max_tokens,
callbacks=[callback],
)再在对应的向量数据库中检索相关文档(top k个)
docs = await run_in_threadpool(search_docs,
query=query,
knowledge_base_name=knowledge_base_name,
top_k=top_k,
score_threshold=score_threshold)这个异步调用中的search_docs暴露自server/knowledge_basekb_doc_api.py,如下:
def search_docs(
query: str = Body("", description="用户输入", examples=["你好"]),
knowledge_base_name: str = Body(..., description="知识库名称", examples=["samples"]),
top_k: int = Body(VECTOR_SEARCH_TOP_K, description="匹配向量数"),
score_threshold: float = Body(SCORE_THRESHOLD,
description="知识库匹配相关度阈值,取值范围在0-1之间,"
"SCORE越小,相关度越高,"
"取到1相当于不筛选,建议设置在0.5左右",
ge=0, le=1),
file_name: str = Body("", description="文件名称,支持 sql 通配符"),
metadata: dict = Body({}, description="根据 metadata 进行过滤,仅支持一级键"),
) -> List[DocumentWithVSId]:
kb = KBServiceFactory.get_service_by_name(knowledge_base_name)
data = []
if kb is not None:
if query:
docs = kb.search_docs(query, top_k, score_threshold)
data = [DocumentWithVSId(**x[0].dict(), score=x[1], id=x[0].metadata.get("id")) for x in docs]
elif file_name or metadata:
data = kb.list_docs(file_name=file_name, metadata=metadata)
for d in data:
if "vector" in d.metadata:
del d.metadata["vector"]
return data首先还是获取数据库服务,随后调用服务类暴露的search_docs函数(这个很显然,对于不同向量数据库来说,肯定是具体实现不一样), 随后返回相似度在阈值内的top_k个结果。
if len(docs) == 0: # 如果没有找到相关文档,使用empty模板
prompt_template = get_prompt_template("knowledge_base_chat", "empty")
else:
prompt_template = get_prompt_template("knowledge_base_chat", prompt_name)
input_msg = History(role="user", content=prompt_template).to_msg_template(False)
chat_prompt = ChatPromptTemplate.from_messages(
[i.to_msg_template() for i in history] + [input_msg])
chain = LLMChain(prompt=chat_prompt, llm=model)随后,建立prompt模板。然后根据历史会话信息建立当前对话的prompt。
之后通过LangChain提供的LLMChain,获取能够进行用户任务的中间件。
# Begin a task that runs in the background.
task = asyncio.create_task(wrap_done(
chain.acall({"context": context, "question": query}),
callback.done),
)随后启动一个后台的异步任务,将向量数据库中检索到的文档作为知识背景,用户的输入作为问题。
source_documents = []
for inum, doc in enumerate(docs):
filename = doc.metadata.get("source")
parameters = urlencode({"knowledge_base_name": knowledge_base_name, "file_name": filename})
base_url = request.base_url
url = f"{base_url}knowledge_base/download_doc?" + parameters
text = f"""出处 [{inum + 1}] [{filename}]({url}) \n\n{doc.page_content}\n\n"""
source_documents.append(text)
if len(source_documents) == 0: # 没有找到相关文档
source_documents.append(f"<span style='color:red'>未找到相关文档,该回答为大模型自身能力解答!</span>")一般LLM回答问题,会把自己参考的文献放出来(比如说Kimi),这一部分做的就是拼接参考文献字符串。
return EventSourceResponse(knowledge_base_chat_iterator(query, top_k, history,model_name,prompt_name))
最后返回大模型的回答。
这个过程就是RAG的Working Pipeline在代码部分中的映射。
将知识嵌入到知识库
这一部分相对而言比较直接。在server/api.py中,有这么一段:
app.post("/knowledge_base/upload_docs",
tags=["Knowledge Base Management"],
response_model=BaseResponse,
summary="上传文件到知识库,并/或进行向量化"
)(upload_docs)找到对应的upload_docs,在server/knowledge_basekb_doc_api.py中。
def upload_docs(
files: List[UploadFile] = File(..., description="上传文件,支持多文件"),
knowledge_base_name: str = Form(..., description="知识库名称", examples=["samples"]),
override: bool = Form(False, description="覆盖已有文件"),
to_vector_store: bool = Form(True, description="上传文件后是否进行向量化"),
chunk_size: int = Form(CHUNK_SIZE, description="知识库中单段文本最大长度"),
chunk_overlap: int = Form(OVERLAP_SIZE, description="知识库中相邻文本重合长度"),
zh_title_enhance: bool = Form(ZH_TITLE_ENHANCE, description="是否开启中文标题加强"),
docs: Json = Form({}, description="自定义的docs,需要转为json字符串",
examples=[{"test.txt": [Document(page_content="custom doc")]}]),
not_refresh_vs_cache: bool = Form(False, description="暂不保存向量库(用于FAISS)"),
) -> BaseResponse:
"""
API接口:上传文件,并/或向量化
"""
if not validate_kb_name(knowledge_base_name):
return BaseResponse(code=403, msg="Don't attack me")
kb = KBServiceFactory.get_service_by_name(knowledge_base_name)
if kb is None:
return BaseResponse(code=404, msg=f"未找到知识库 {knowledge_base_name}")
failed_files = {}
file_names = list(docs.keys())
# 先将上传的文件保存到磁盘
for result in _save_files_in_thread(files, knowledge_base_name=knowledge_base_name, override=override):
filename = result["data"]["file_name"]
if result["code"] != 200:
failed_files[filename] = result["msg"]
if filename not in file_names:
file_names.append(filename)
# 对保存的文件进行向量化
if to_vector_store:
result = update_docs(
knowledge_base_name=knowledge_base_name,
file_names=file_names,
override_custom_docs=True,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
zh_title_enhance=zh_title_enhance,
docs=docs,
not_refresh_vs_cache=True,
)
failed_files.update(result.data["failed_files"])
if not not_refresh_vs_cache:
kb.save_vector_store()
return BaseResponse(code=200, msg="文件上传与向量化完成", data={"failed_files": failed_files})这一部分最重要的还是save_vector_store函数,不过这一部分属于每种数据库自己的实现了。
我们可以看一个faiss的
def load_vector_store(self) -> ThreadSafeFaiss:
return kb_faiss_pool.load_vector_store(kb_name=self.kb_name,
vector_name=self.vector_name,
embed_model=self.embed_model)
def load_vector_store(
self,
kb_name: str,
vector_name: str = None,
create: bool = True,
embed_model: str = EMBEDDING_MODEL,
embed_device: str = embedding_device(),
) -> ThreadSafeFaiss:
self.atomic.acquire()
vector_name = vector_name or embed_model
cache = self.get((kb_name, vector_name)) # 用元组比拼接字符串好一些
if cache is None:
item = ThreadSafeFaiss((kb_name, vector_name), pool=self)
self.set((kb_name, vector_name), item)
with item.acquire(msg="初始化"):
self.atomic.release()
logger.info(f"loading vector store in '{kb_name}/vector_store/{vector_name}' from disk.")
vs_path = get_vs_path(kb_name, vector_name)
if os.path.isfile(os.path.join(vs_path, "index.faiss")):
embeddings = self.load_kb_embeddings(kb_name=kb_name, embed_device=embed_device, default_embed_model=embed_model)
vector_store = FAISS.load_local(vs_path, embeddings, normalize_L2=True,distance_strategy="METRIC_INNER_PRODUCT")
elif create:
# create an empty vector store
if not os.path.exists(vs_path):
os.makedirs(vs_path)
vector_store = self.new_vector_store(embed_model=embed_model, embed_device=embed_device)
vector_store.save_local(vs_path)
else:
raise RuntimeError(f"knowledge base {kb_name} not exist.")
item.obj = vector_store
item.finish_loading()
else:
self.atomic.release()
return self.get((kb_name, vector_name))其实这个模块是个缓存机制,也就是说每次检索都会查看是否已经有这个向量数据库的操作柄了。如果有直接返回,如果没有则加载一遍,这个加载的过程集中在:
def get(self, key: str) -> ThreadSafeObject:
if cache := self._cache.get(key):
cache.wait_for_loading()
return cache那么他返回的是什么呢?是一个对应数据库的操作柄,定义如下:
class ThreadSafeFaiss(ThreadSafeObject):
def __repr__(self) -> str:
cls = type(self).__name__
return f"<{cls}: key: {self.key}, obj: {self._obj}, docs_count: {self.docs_count()}>"
def docs_count(self) -> int:
return len(self._obj.docstore._dict)
def save(self, path: str, create_path: bool = True):
with self.acquire():
if not os.path.isdir(path) and create_path:
os.makedirs(path)
ret = self._obj.save_local(path)
logger.info(f"已将向量库 {self.key} 保存到磁盘")
return ret
def clear(self):
ret = []
with self.acquire():
ids = list(self._obj.docstore._dict.keys())
if ids:
ret = self._obj.delete(ids)
assert len(self._obj.docstore._dict) == 0
logger.info(f"已将向量库 {self.key} 清空")
return ret本质上是存储向量化文档的一个对象。