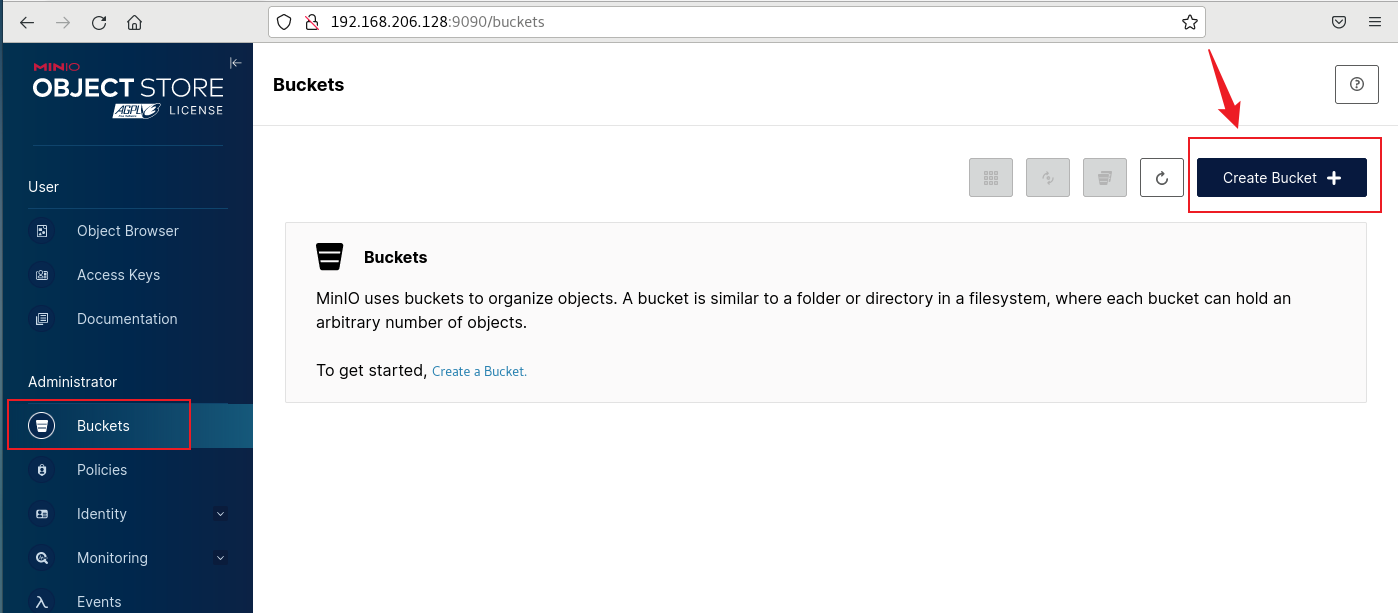
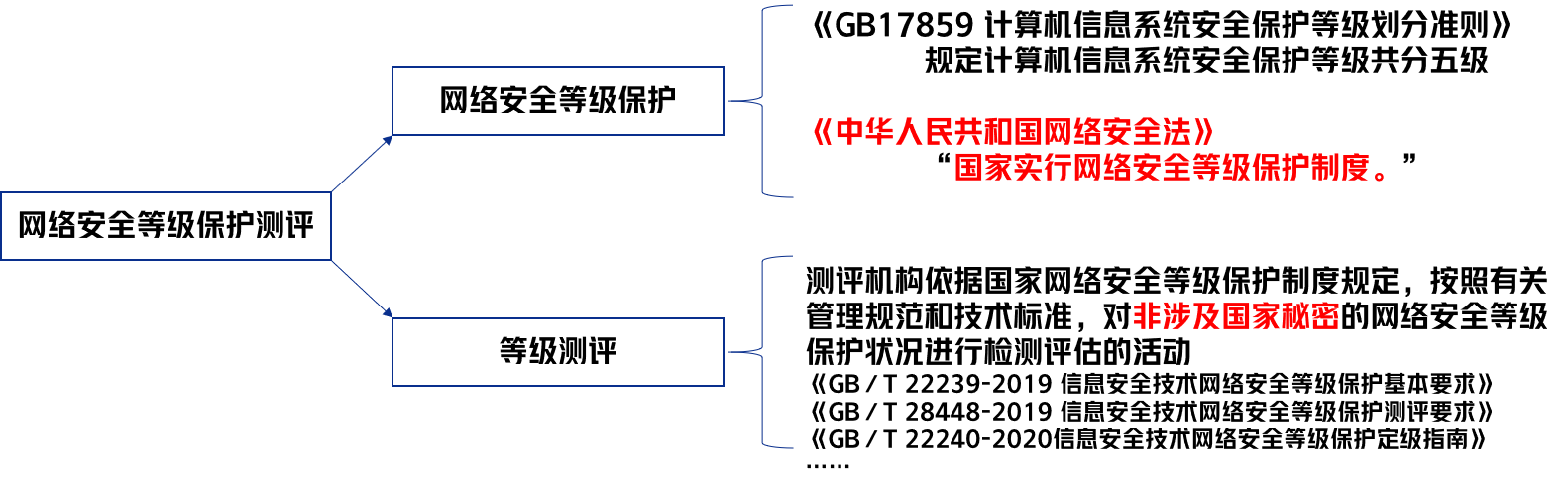
View-Consistent 3D Editing with Gaussian Splatting
使用高斯溅射进行视图一致的3D编辑
Abstract 摘要
View-Consistent 3D Editing with Gaussian Splatting
The advent of 3D Gaussian Splatting (3DGS) has revolutionized 3D editing, offering efficient, high-fidelity rendering and enabling precise local manipulations. Currently, diffusion-based 2D editing models are harnessed to modify multi-view rendered images, which then guide the editing of 3DGS models. However, this approach faces a critical issue of multi-view inconsistency, where the guidance images exhibit significant discrepancies across views, leading to mode collapse and visual artifacts of 3DGS. To this end, we introduce View-consistent Editing (VcEdit), a novel framework that seamlessly incorporates 3DGS into image editing processes, ensuring multi-view consistency in edited guidance images and effectively mitigating mode collapse issues. VcEdit employs two innovative consistency modules: the Cross-attention Consistency Module and the Editing Consistency Module, both designed to reduce inconsistencies in edited images. By incorporating these consistency modules into an iterative pattern, VcEdit proficiently resolves the issue of multi-view inconsistency, facilitating high-quality 3DGS editing across a diverse range of scenes.
3D高斯溅射(3DGS)的出现彻底改变了3D编辑,提供了高效、高保真的渲染,并实现了精确的局部操作。目前,基于扩散的2D编辑模型被用来修改多视图渲染图像,然后指导3DGS模型的编辑。然而,这种方法面临着多视图不一致的关键问题,其中引导图像在视图之间表现出显著的差异,导致模式崩溃和3DGS的视觉伪影。为此,我们引入了视图一致性编辑(VcEdit),这是一种将3DGS无缝集成到图像编辑过程中的新型框架,可确保编辑的指导图像中的多视图一致性,并有效缓解模式崩溃问题。VcEdit采用了两个创新的一致性模块:交叉注意一致性模块和编辑一致性模块,两者都旨在减少编辑图像中的不一致性。 通过将这些一致性模块整合到迭代模式中,VcEdit熟练地解决了多视图不一致的问题,促进了在各种场景中进行高质量的3DGS编辑。
Keywords:
3D Editing 3D Gaussian Splating Multi-view Consistency关键词:3D编辑3D高斯拼接多视图一致性

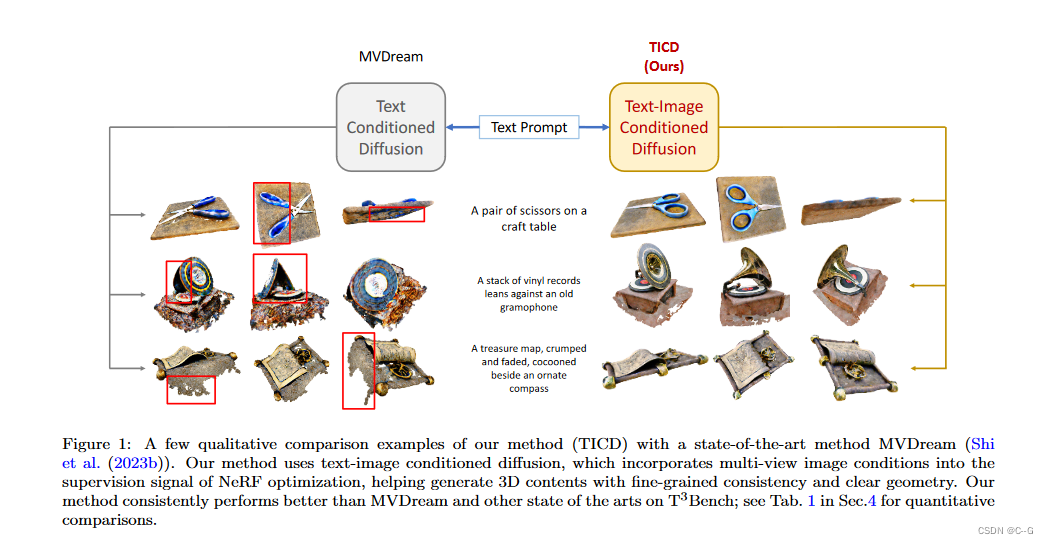
Figure 1:Capability highlight of our method: VcEdit. Given a source 3D Gaussian Splatting and a user-specified text prompt, our VcEdit enables versatile scene and object editing. By ensuring multi-view consistent image guidance, VcEdit alleviates artifacts and excels in high-quality editing.
图1:我们的方法的功能亮点:VcEdit。给定源3D高斯飞溅和用户指定的文本提示,我们的VcEdit可以实现多功能场景和对象编辑。通过确保多视图一致的图像引导,VcEdit消除了伪影,并在高质量编辑方面表现出色。
1Introduction 1介绍
We consider the problem of text-driven 3D model editing: given a source 3D model and user-specified text instructions, the task is to modify the 3D model according to the instructions, as depicted in Fig. 1, ensuring both editing fidelity and preservation of essential source content [34, 5, 7, 4, 18]. This problem holds paramount importance across a variety of industrial applications, such as real-time outfit changes for 3D digital humans and immersive AR/VR interactive environments[39, 3, 42]. Recently, groundbreaking 3D Gaussian Splatting (3DGS) [19] has emerged as a promising “silver bullet” for 3D editing, notable for its efficient, high-fidelity rendering and explicit representation (3D anisotropic balls known as Gaussians) suitable for local manipulation.
我们考虑文本驱动的3D模型编辑问题:给定源3D模型和用户指定的文本指令,任务是根据指令修改3D模型,如图1所示,确保编辑保真度和保留基本源内容[ 34,5,7,4,18]。这个问题在各种工业应用中至关重要,例如3D数字人和沉浸式AR/VR交互环境的实时服装变化[ 39,3,42]。最近,突破性的3D高斯溅射(3DGS)[ 19]已经成为3D编辑的一个有前途的“银弹”,以其高效,高保真渲染和显式表示(3D各向异性球称为高斯)而闻名,适合局部操作。
In the context of editing 3DGS models, thanks to recent progress in large-scale pre-trained 2D diffusion models, existing methods [15, 8, 9, 6, 10] leverage off-the-shelf 2D editing models [12, 14, 28, 38, 11, 1] to guide optimization of the 3DGS model. As shown in Fig. 2(a), this pattern renders source 3DGS into multi-view 2D images, manipulates them via 2D editing models using text prompts, and then employs these adjusted images to fine-tune the original 3DGS. Beyond achieving plausible editing outcomes, this image-based pattern also facilitates user-friendly interaction, enabling users to pre-select their preferred edited images and personalize the editing workflow.
在编辑3DGS模型的背景下,由于大规模预训练2D扩散模型的最新进展,现有方法[15,8,9,6,10]利用现成的2D编辑模型[12,14,28,38,11,1]来指导3DGS模型的优化。如图2(a)所示,该模式将源3DGS渲染成多视图2D图像,使用文本提示经由2D编辑模型操纵它们,然后采用这些调整后的图像来微调原始3DGS。除了实现合理的编辑结果外,这种基于图像的模式还促进了用户友好的交互,使用户能够预先选择他们喜欢的编辑图像并个性化编辑工作流程。
However, such image-guided 3DGS editing has a notorious multi-view inconsistency that cannot be ignored. Fig. 2(a) vividly illustrates that images edited separately using a state-of-the-art 2D editing model [38] manifest pronounced inconsistencies across views — the views of a man are edited to different styles of clowns. Utilizing these significantly varied edited images as guidance, the 3DGS model will struggle with the issue that few training images are coherent, whereas the majority display conflicting information. Unfortunately, the explicitness and inherent densification process of 3DGS make it especially vulnerable to multi-view inconsistency, which complicates 3DGS in densifying under-reconstruction regions or pruning over-reconstruction regions [35]. Consequently, training with the multi-view inconsistent guidance can lead to the mode collapse of 3DGS, characterized by the ambiguity between the source and target, as well as the flickering artifacts revealed in Fig. 2(a).
然而,这种图像引导的3DGS编辑具有不能忽视的臭名昭著的多视图不一致性。图2(a)生动地说明了使用最先进的2D编辑模型[ 38]单独编辑的图像在视图之间表现出明显的不一致性-一个人的视图被编辑为不同风格的小丑。利用这些显著变化的编辑图像作为指导,3DGS模型将努力解决很少有训练图像是一致的,而大多数显示冲突信息的问题。不幸的是,3DGS的显式性和固有的致密化过程使其特别容易受到多视图不一致的影响,这使得3DGS在致密化重建不足区域或修剪重建过度区域时变得复杂[ 35]。因此,使用多视图不一致引导的训练可能导致3DGS的模式崩溃,其特征在于源和目标之间的模糊性,以及图2(a)中揭示的闪烁伪影。
Thus, the crux lies in addressing the multi-view inconsistency of the image guidance. We conjecture such a problem stems from the lack of 3D awareness in 2D editing models; that is, they inherently process each view in isolation. Therefore, we introduce the View-consistent Editing (VcEdit), a high-quality image-guided 3DGS editing framework. This framework seamlessly incorporates 3DGS into image editing processes to achieve multi-view consistent guidance, thus effectively addressing the issue of 3DGS mode collapse. As illustrated in Fig. 2(b), VcEdit employs specially-designed multi-view consistency modules within an iterative pattern.
因此,关键在于解决图像引导的多视图不一致性。我们推测这样的问题源于2D编辑模型中缺乏3D意识;也就是说,它们固有地孤立地处理每个视图。因此,我们介绍了视图一致性编辑(VcEdit),一个高质量的图像引导的3DGS编辑框架。该框架将3DGS无缝集成到图像编辑过程中,实现多视图一致引导,从而有效解决了3DGS模式崩溃的问题。如图2(B)所示,VcEdit在迭代模式中采用专门设计的多视图一致性模块。
Primarily, we design two effective consistency modules using the explicit nature and fast rendering capability of 3DGS: (1) The Cross-attention Consistency Module (CCM) that consolidates the multi-view cross-attention maps in the diffusion-based image editing model, thus harmonizing the model’s attentive 3D region across all views. More concretely, this process inverse-renders the original cross-attention maps from all views onto each Gaussian within the source 3DGS, thereby creating an averaged 3D map. Subsequently, this 3D map is rendered back to 2D, serving as the consolidated cross-attention maps to replace the originals for more coherent edits. (2) The Editing Consistency Module (ECM) that directly calibrates the multi-view inconsistent editing outputs: We fine-tune a source-cloned 3DGS with the editing outputs and then render the 3DGS back to images. Taking advantage of the rapid rendering speed of the 3DGS, this mechanism efficiently decreases incoherent content in each edited image.
首先,我们设计了两个有效的一致性模块使用显式的性质和快速渲染能力的3DGS:(1)交叉注意一致性模块(CCM),巩固多视图交叉注意力地图在基于扩散的图像编辑模型,从而协调模型的关注3D区域在所有视图。更具体地,该过程将来自所有视图的原始交叉注意力图逆渲染到源3DGS内的每个高斯上,从而创建平均3D图。随后,这个3D地图被渲染回2D,作为合并的交叉注意力地图,以取代原始地图,进行更连贯的编辑。(2)编辑一致性模块(ECM)直接校准多视图不一致的编辑输出:我们使用编辑输出微调源克隆的3DGS,然后将3DGS渲染回图像。 利用3DGS的快速渲染速度,该机制有效地减少了每个编辑图像中的不相干内容。
To further mitigate the multi-view inconsistency issue, we extend our VcEdit to an iterative pattern: editing rendered images → updating the 3DGS → repeating. In situations where the image editing model yields overly inconsistent initial edits, it allows for the correction of initially inconsistent views in later iterations [15], which continuously refines the 3DGS and fosters a reciprocal cycle. Fig. 2(b) illustrates that the 3DGS of a “man” is iteratively guided to a consistent style that aligns with the desired “clown” target. To meet the demand for rapid iteration, VcEdit integrates InfEdit [38], a high-quality, fast image editing model that bypasses the lengthy DDIM-inversion phase. Depending on the complexity of the editing scene and user instructions, the processing time in our VcEdit for each sample ranged from 10 to 20 minutes.
为了进一步缓解多视图不一致问题,我们将VcEdit扩展为迭代模式:编辑渲染图像 → 更新3DGS → 重复。在图像编辑模型产生过度不一致的初始编辑的情况下,它允许在以后的迭代中纠正最初不一致的视图[ 15],这会不断细化3DGS并促进相互循环。图2(B)示出了“人”的3DGS被迭代地引导到与期望的“小丑”目标对准的一致样式。为了满足快速迭代的需求,VcEdit集成了InfEdit [ 38],这是一种高质量,快速的图像编辑模型,可以绕过冗长的DDIM反转阶段。根据编辑场景的复杂性和用户说明,每个样本在我们的VcEdit中的处理时间从10分钟到20分钟不等。

Figure 2:(a): Current image-guided 3DGS editing pipeline and its multi-view inconsistency issue: The rendered views of a man are separately edited to different styles of clowns, leading to the mode collapse issue of learned 3DGS. (b): The iterative pattern and our consistency modules deployed in each iteration. The 3DGS is progressively guided to a coherent style that aligns with the “clown” through the iterative pattern.
图二:(a):当前图像引导的3DGS编辑流水线及其多视图不一致问题:一个人的渲染视图被单独编辑为不同风格的小丑,导致学习3DGS的模式崩溃问题。(b)迭代模式和我们在每次迭代中部署的一致性模块。3DGS通过迭代模式逐步引导到与“小丑”对齐的连贯风格。
As illustrated in Fig. 1, by incorporating consistency modules and the iterative pattern, VcEdit significantly enhances the multi-view consistency in guidance images, leading to superior editing quality. We conducted comprehensive evaluations of VcEdit in various real-world scenes. Both qualitative and quantitative experiments clearly indicate that VcEdit can address the mode collapse of 3DGS, continuously outperforming other state-of-the-art methods. Our contributions can be summarized in three aspects:
如图1所示,通过合并一致性模块和迭代模式,VcEdit显著增强了引导图像中的多视图一致性,从而导致上级编辑质量。我们在各种真实场景中对VcEdit进行了全面评估。定性和定量实验都清楚地表明,VcEdit可以解决3DGS的模式崩溃,连续优于其他最先进的方法。我们的贡献可以概括为三个方面:
- •
We propose effective multi-view consistency modules that harmonize the inconsistent multi-view guidance images.
·我们提出了有效的多视图一致性模块,协调不一致的多视图引导图像。 - •
Based on our designed consistency module, we construct an effective iterative pattern that offers high-quality 3DGS editing.
基于我们设计的一致性模块,我们构建了一个有效的迭代模式,提供高质量的3DGS编辑。 - •
We pioneer a paradigm that integrates 3DGS characteristics with multi-view consistency design, inspiring further efforts and explorations.
·我们开创了将3DGS特性与多视图一致性设计相结合的范例,激发了进一步的努力和探索。
2Related Works 2相关作品
Text-guided Image Editing. Large-scale pretrained Text-to-image (T2I) diffusion models [32, 37] have been widely adopted in generative image editing, guided by specific text prompts. Textual Inversion [12] optimizes special prompt token(s) in text embedding space to represent the specified concept, whereas Prompt-to-Prompt leverages cross-attention information to maintain integrity in unmodified regions. Pix2pix-zero [28] utilizes embedding vector mechanisms to establish controllable editing. InstructPix2Pix [14] merges the capacities of GPT and Stable Diffusion [32] to generate a multi-modal dataset and fine-tunes Stable Diffusion to achieve instructed diverse editing. Our VcEdit integrates InfEdit [38], which implies a virtual inversion strategy and attention control mechanisms for a controllable and faithful editing. Nevertheless, all the above works mainly focus on editing a single image, and obtaining high-quality paired data with multi-view consistency from the 2D diffusion model is extremely challenging, resulting in the application of 3D-aware editing impractical.
文本引导的图像编辑。大规模预训练的文本到图像(T2 I)扩散模型[ 32,37]已被广泛用于生成图像编辑,由特定的文本提示引导。Textual Inversion [ 12]优化了文本嵌入空间中的特殊提示标记以表示指定的概念,而提示到提示利用交叉注意信息来保持未修改区域的完整性。Pix 2 pix-zero [ 28]利用嵌入向量机制来建立可控编辑。InstructPix 2 Pix [ 14]合并了GPT和Stable Diffusion [ 32]的功能,以生成多模态数据集并微调Stable Diffusion以实现指示的多样化编辑。我们的VcEdit集成了InfEdit [ 38],这意味着一个虚拟的反转策略和注意力控制机制,用于可控和忠实的编辑。 然而,所有上述工作主要集中在编辑单个图像,并且从2D扩散模型获得具有多视图一致性的高质量配对数据是极具挑战性的,导致3D感知编辑的应用不切实际。
3D Field Editing. In the last few years, NeRF-based approaches [26, 31, 17, 41, 46, 27, 20, 2, 18] have overtaken traditional point cloud and triangle mesh approaches [43, 36, 45, 27, 2] for 3D field editing. DreamEditor [47] updates textual attention areas with score distillation sampling (SDS) guidance [29]. DDS [16] and PDS [22] introduce an advance SDS loss with cleaner optimization direction for better instruction alignment. FocalDreamer [24] generates new geometries in specified empty spaces from the text input. Instruct-NeRF2NeRF [15] iteratively refines dataset images using the InstructPix2Pix diffusion model and NeRF, a pattern widely adopted in subsequent research [9, 23]. However, the inherent computational demands and the implicit nature of NeRF usually require time-consuming fine-tuning for edit operations and lack of precise controllability, which cannot support practical interactive editing use cases. More recent works [10, 6] integrate Gaussian splatting into 3D field editing and surpasses previous 3D editing methods in terms of effectiveness, speed, and controllability. Our VcEdit builds upon the above image-based 3DGS editing approaches and further harmonizes the inconsistent multi-view image guidance they overlook, which enables more high-fidelity editing quality without mode collapse.
3D字段编辑在过去的几年中,基于NeRF的方法[ 26,31,17,41,46,27,20,2,18]已经超过了传统的点云和三角形网格方法[ 43,36,45,27,2]用于3D字段编辑。DreamEditor [ 47]使用分数蒸馏采样(SDS)指南[ 29]更新文本注意区域。DDS [ 16]和PDS [ 22]引入了一种先进的SDS损失,具有更清晰的优化方向,以实现更好的指令对齐。FocalDreamer [ 24]从文本输入中在指定的空白空间中生成新的几何形状。Instruct-NeRF 2NeRF [ 15]使用InstructPix 2 Pix扩散模型和NeRF迭代地细化数据集图像,这是一种在后续研究中广泛采用的模式[ 9,23]。然而,固有的计算需求和NeRF的隐式性质通常需要对编辑操作进行耗时的微调,并且缺乏精确的可控性,这无法支持实际的交互式编辑用例。 最近的作品[10,6]将高斯溅射集成到3D字段编辑中,并在有效性,速度和可控性方面超越了以前的3D编辑方法。我们的VcEdit建立在上述基于图像的3DGS编辑方法的基础上,并进一步协调了它们忽略的不一致的多视图图像指导,从而实现了更高保真的编辑质量,而不会出现模式崩溃。
3Preliminary 3初步
3.13D Gaussian Splatting 3.13D高斯溅射
3D Gaussian splatting (3DGS) has emerged as a prominent efficient explicit 3D representation technique, employing anisotropic 3D Gaussians for intricate modeling [19]. Each Gaussian, represented as �, is characterized by its mean �∈ℝ3, covariance matrix Σ, associated color �∈ℝ3, and opacity �∈ℝ. For better optimization, the covariance matrix Σ is decomposed into a scaling matrix �∈ℝ3 and a rotation matrix �∈ℝ3×3, with Σ defined as Σ=������. A Gaussian centered at � is expressed as �(�)=exp(−12��Σ−1�), where � denotes the displacement from � to a point in space. In the splatting rendering process, we render the color � for a pixel by blending all sampled 3D points along the ray going through this pixel:
3D高斯溅射(3DGS)已经成为一种突出的高效显式3D表示技术,采用各向异性3D高斯进行复杂建模[ 19]。表示为 � 的每个高斯由其均值 �∈ℝ3 、协方差矩阵 Σ 、相关联的颜色 �∈ℝ3 和不透明度 �∈ℝ 表征。为了更好地优化,协方差矩阵 Σ 被分解为缩放矩阵 �∈ℝ3 和旋转矩阵 �∈ℝ3×3 ,其中 Σ 被定义为 Σ=������ 。以 � 为中心的高斯表示为 �(�)=exp(−12��Σ−1�) ,其中 � 表示从 � 到空间中的一点的位移。在飞溅渲染过程中,我们通过混合所有采样的3D点来渲染像素的颜色 � ,这些点沿着穿过该像素的光线:
| �=∑������(��)∏�=1�−1(1−���(��)). | (1) |
An efficient tile-based rasterizer [19] allows for rapid forward and backward passes, supporting high-quality real-time rendering. The optimization of 3D Gaussian properties is conducted in tandem with an adaptive density control mechanism, involving densifying and pruning operations, where Gaussians are added and occasionally removed. By incorporating all the Gaussians �, the 3DGS model, denoted as 𝒢, represents complete 3D scenes and objects.
一个高效的基于瓦片的光栅化器[ 19]允许快速向前和向后传递,支持高质量的实时渲染。3D高斯属性的优化与自适应密度控制机制协同进行,包括加密和修剪操作,其中添加高斯并偶尔删除。通过合并所有高斯 � ,3DGS模型(表示为 𝒢 )表示完整的3D场景和对象。
3.2Image-guided 3DGS Editing
3.2图像引导的3DGS编辑
Given a source 3D Gaussian Splatting (3DGS) model 𝒢src and a user-specified target prompt �, the goal of 3DGS editing is to transform 𝒢src into an edited version 𝒢edit that aligns with �. In image-guided 3DGS editing, 𝒢src is first rendered from multiple views 𝒱={�}, generating a collection of source images ℐsrc. Subsequently, a 2D editing model transforms ℐsrc into edited images ℐedit according to �. Finally, these edited images serve as training guidance to refine 𝒢src into the edited version 𝒢edit. Specifically, an editing loss �Edit is calculated for each view between the real-time rendering and the edited images. The final edited 3DGS model is obtained by minimizing the editing loss across all views 𝒱:
给定源3D高斯溅射(3DGS)模型 𝒢src 和用户指定的目标提示 � ,3DGS编辑的目标是将 𝒢src 转换为与 � 对齐的编辑版本 𝒢edit 。在图像引导的3DGS编辑中,首先从多个视图 𝒱={�} 渲染 𝒢src ,生成源图像 ℐsrc 的集合。随后,2D编辑模型根据 � 将 ℐsrc 变换为编辑图像 ℐedit 。最后,这些编辑后的图像作为训练指导,将 𝒢src 细化为编辑后的版本 𝒢edit 。具体地,针对实时绘制和编辑图像之间的每个视图计算编辑损失 �Edit 。通过最小化所有视图的编辑损失来获得最终编辑的3DGS模型 𝒱 :
| 𝒢edit=argmin𝒢∑�∈𝒱ℒEdit(ℛ(𝒢,�),ℐedit), | (2) |
where ℛ represents the rendering function that projects 3DGS to image given a specific view �.
其中 ℛ 表示在给定特定视图 � 的情况下将3DGS投影到图像的渲染函数。
4Our Method 4我们的方法
In this section, we introduce the View-Consistent Editing (VcEdit), a novel approach for 3DGS editing. First, we outline the general pipeline of VcEdit in Sec. 4.1. Subsequently, we introduce two innovative Consistency Modules designed to address the multi-view inconsistency issue. Particularly, in Sec. 4.2, we introduce the Cross-attention Consistency Module, which aims to reduce multi-view editing variance by improving the attention consistency. In Sec. 4.3, we present the Editing Consistency Module, which directly calibrates multi-view editing predictions to ensure consistency across all predictions. Finally, in Sec. 4.4, we extend our framework to an iterative pattern, which facilitates the iterative improvement of consistency between ℐedit and 𝒢edit.
在本节中,我们将介绍视图一致性编辑(VcEdit),这是一种用于3DGS编辑的新方法。首先,我们在第二节中概述了VcEdit的一般管道。4.1.随后,我们介绍了两个创新的一致性模块,旨在解决多视图不一致的问题。特别是在SEC。4.2引入了交叉注意一致性模块,通过提高注意一致性来降低多视图编辑方差。节中4.3,我们提出了编辑一致性模块,它直接校准多视图编辑预测,以确保所有预测的一致性。最后,在第4.4,我们将我们的框架扩展到迭代模式,这有助于迭代改进 ℐedit 和 𝒢edit 之间的一致性。
4.1View-consistent Editing Pipeline
4.1视图一致的编辑管道
Fig. 3 illustrates the overview of our framework, VcEdit. To perform image-guided 3DGS editing, we utilize the pre-trained 2D diffusion model [32, 37] to generate a series of edited images given a set of multi-view rendered images.
图3展示了我们的框架VcEdit的概述。为了执行图像引导的3DGS编辑,我们利用预先训练的2D扩散模型[32,37]来生成一系列编辑图像,给定一组多视图渲染图像。
Inspired by [38], we adopt an annealed timestep schedule from the largest timestep � to 1, where we evenly sample � timesteps from the schedule, denoted as �∈{��}�=1�. Before the start of the first timestep �1, the rendered images, denoted as ℐsrc, are encoded into multi-view source latents �src.
受[ 38]的启发,我们采用从最大时间步 � 到 1 的退火时间步调度,其中我们从调度中均匀采样 � 时间步,表示为 �∈{��}�=1� 。在第一时间步 �1 开始之前,表示为 ℐsrc 的渲染图像被编码到多视图源潜伏期 �src 中。
For each sampled timestep, the source latents �src go through an editing process. Specifically, at timestep �, we first adopt the forward diffusion process to perturb the given rendered images with random Gaussian noise � as follows:
对于每个采样的时间步,源潜伏期 �src 经历编辑过程。具体地,在时间步 � ,我们首先采用前向扩散过程来用随机高斯噪声 � 扰动给定的渲染图像,如下所示:
| ��=���src+1−���,�∼𝒩(𝟎,𝐈), | (3) |
where the �� is a time-variant hyper-parameter, �src is the encoded latent images. Then we feed the noisy latents �� into a pre-trained diffusion model �� to generate denoised images as edited latents based on the user’s target prompt �:
其中 �� 是时变超参数, �src 是编码的潜像。然后,我们将噪声潜伏期 �� 馈送到预先训练的扩散模型 �� 中,以基于用户的目标提示 � 生成降噪图像作为编辑的潜伏期:
| �edit=(��−1−��⋅��(��,�))/��. | (4) |
However, we observe that the edited images generated by simply adopting pre-trained 2D diffusion models lacks of multi-view consistency, which often leads to mode collapse in the learned 3DGS [25]. Therefore, we propose the Cross-attention Consistency Module in Sec. 4.2, which consolidates multi-view cross-attention maps within each layer of the diffusion model’s U-Net architecture, improving the view-consistency in �edit.
然而,我们观察到通过简单地采用预先训练的2D扩散模型生成的编辑图像缺乏多视图一致性,这通常会导致学习的3DGS中的模式崩溃[ 25]。因此,我们在第二节中提出了交叉注意一致性模块。4.2,它在扩散模型的U-Net架构的每一层内整合了多视图交叉注意力图,提高了 �edit 中的视图一致性。
Upon obtaining the edited latents, we aim to further improve the multi-view consistency of the edited guidance images. To this end, we design the Editing Consistency Module, where we adopt a fine-tuning and rendering process using 3DGS to calibrate �edit, producing a set of more consistent latents, denoted as �con. Finally, a local blending process is conducted to preserve source information, generating the blended latents, denoted as �bld, which serve as the output of the current timestep �. Details are demonstrated in Sec. 4.3.
在获得编辑后的潜伏期后,我们的目标是进一步提高编辑后的引导图像的多视图一致性。为此,我们设计了编辑一致性模块,其中我们采用了微调和渲染过程,使用3DGS来校准 �edit ,产生一组更一致的潜伏期,表示为 �con 。最后,进行局部混合过程以保留源信息,生成混合的潜伏期,表示为 �bld ,其用作当前时间步 � 的输出。详细信息见第二节。4.3.
Upon completion of one timestep, its output, �bld, continually serves as the input of the succeeding timestep. This editing process is repeated as � progresses from �1 to ��. Finally, the last timestep’s output are decoded back to multi-view edited images, denoted as ℐedit, which serves as the view-consistent guidance images to fine-tune the 𝒢src, where the training objective includes a MAE loss and a VGG-based LPIPS loss [44, 33]:
一个时间步完成后,其输出 �bld 将继续作为后续时间步的输入。当 � 从 �1 进展到 �� 时,重复该编辑过程。最后,最后一个时间步的输出被解码回多视图编辑图像,表示为 ℐedit ,其用作视图一致的引导图像以微调 𝒢src ,其中训练目标包括MAE损失和基于VGG的LPIPS损失[ 44,33]:
| ℒ=�1ℒMAE(ℛ(𝒢,�),ℐedit)+�2ℒLPIPS(ℛ(𝒢,�),ℐedit) | (5) |
In summary, VcEdit is integrated with two effective consistency modules. In Sec. 6.1, our experiments thoroughly demonstrate that it can produce consistent image editing results which are directly used as guidance.
总之,VcEdit集成了两个有效的一致性模块。节中6.1,我们的实验充分证明它可以产生一致的图像编辑结果,直接用作指导。

Figure 3:The pipeline of our VcEdit: VcEdit employs an image-guided editing pipeline. In the image editing stage, the Cross-attention Consistency Module and Editing Consistency Module are employed to ensure the multi-view consistency of edited images. We provide a detailed overview in Sec. 4.1.
图3:我们的VcEdit管道:VcEdit采用了图像引导的编辑管道。在图像编辑阶段,采用交叉注意一致性模块和编辑一致性模块,保证编辑后图像的多视点一致性。我们在第二节中提供了详细的概述。4.1.
4.2Cross-attention Consistency Module
4.2交叉注意一致性模块
As discussed in Sec. 1, existing image-guided 3DGS editing approaches [15, 10, 6] frequently encounter multi-view inconsistencies in the generated guidance images. We suggest that this inconsistency arises from the lack of cross-view information exchange during the editing process.
正如在SEC中所讨论的那样。1,现有的图像引导的3DGS编辑方法[15,10,6]经常在生成的引导图像中遇到多视图不一致。我们认为,这种不一致性是由于编辑过程中缺乏跨视图信息交换造成的。
Therefore, we develop the Cross-attention Consistency Module (CCM) that consolidates the cross-attention maps from all views during the forward pass of the U-Net, where these maps indicate the pixel-to-text correlations between images and user prompts. In this way, we successfully enable cross-view information exchange within the backbone network in a seamless, plug-and-play manner, thereby facilitating multi-view consistency in the generation of edited images.
因此,我们开发了交叉注意一致性模块(CCM),它在U-Net的前向传递过程中合并了来自所有视图的交叉注意图,这些图指示图像和用户提示之间的像素到文本的相关性。通过这种方式,我们成功地实现了骨干网络内的跨视图信息交换,以无缝,即插即用的方式,从而促进多视图的一致性,在编辑图像的生成。
As illustrated in the top of Fig. 3, we first employ inverse-rendering [19, 6] to map the 2D cross-attention maps 𝐌 back onto the 3D Gaussians within 𝒢src, generating a 3D map 𝕄. Given the �-th Gaussian in 𝒢src and the pixel p in the �-th 2D map 𝐌�, the ��(𝐩), ��,�(𝐩), 𝐌�,𝐩 denote the opacity, transmittance matrix, and cross-attention weight, respectively. Specifically, for the �-th Gaussian in 𝒢src, its value in the 3D map 𝕄� is computed as:
如图3的顶部所示,我们首先采用逆渲染[19,6]将2D交叉注意力映射 𝐌 映射回 𝒢src 内的3D高斯,生成3D映射 𝕄 。给定 𝒢src 中的第 � 高斯和第 � 2D图 𝐌� 中的像素p, ��(𝐩) 、 ��,�(𝐩) 、 𝐌�,𝐩 分别表示不透明度、透射率矩阵和交叉关注权重。具体地,对于 𝒢src 中的第 � 高斯,其在3D图 𝕄� 中的值被计算为:
| 𝕄�=1��∑�∈�∑𝐩∈𝐌���(𝐩)⋅��,�(𝐩)⋅𝐌�,𝐩 | (6) |
The �� is the count indicating the total number of values that assigned to � by 𝐌�,𝐩 across all 𝐩 and �. In the created 3D map 𝕄, each Gaussian receives an attention weight towards each word in the prompt. Subsequently, we render the 𝕄 back to 2D space to obtain a set of consistent cross-attention maps, denoted as 𝐌con.
�� 是指示在所有 𝐩 和 � 中由 𝐌�,𝐩 分配给 � 的值的总数的计数。在所创建的3D地图 𝕄 中,每个高斯接收对提示中的每个单词的关注权重。随后,我们将 𝕄 渲染回2D空间,以获得一组一致的交叉注意力图,表示为 𝐌con 。
By replacing the vanilla cross-attention maps 𝐌 with the consistent attention maps 𝐌con , our CCM conducts an 3D average pooling to unify model’s attentive region across different views. In this way, the U-Net model ensures uniform attention is given to the same 3D region across different views during the editing process, facilitating the production of more consistent edited latents. Our experiments, detailed in Sec. 6.1, validate that this cross-attention control mechanism significantly bolsters view consistency.
通过用一致的注意力图 𝐌con 替换普通的交叉注意力图 𝐌 ,我们的CCM进行了3D平均池化,以统一模型在不同视图中的注意力区域。通过这种方式,U-Net模型确保在编辑过程中对不同视图中的相同3D区域给予统一的关注,从而促进产生更一致的编辑潜在内容。我们的实验,在SEC中详细介绍。6.1,验证这种交叉注意力控制机制显著增强了视图一致性。
4.3Editing Consistency Module
4.3编辑一致性模块
Incorporating the CCM described in Sec. 4.2 allows the diffusion models to produce �edit with enhanced consistency. Yet, it is still inadequate for updating the 3DGS directly, since 3DGS is based on spatial physical modeling that requires coherent representation across views. Therefore, we introduce Editing Consistency Module (ECM) which distills the image guidance into an intermediate model incorporating physical modeling and consistency constraints. This intermediate model is then utilized to generate more coherent multi-view edited guidance images.
验证第2.2节中所述的CCM。4.2允许扩散模型产生具有增强一致性的 �edit 。然而,它仍然不足以直接更新3DGS,因为3DGS是基于空间物理建模,需要跨视图的连贯表示。因此,我们引入了编辑一致性模块(ECM),它将图像引导提炼成一个中间模型,结合物理建模和一致性约束。然后利用该中间模型来生成更连贯的多视图编辑的引导图像。
We illustrate the proposed module in the bottom-right of Fig. 3. Initially, we decode the multi-view edited latents �edit into images, denoted as 𝒟(�edit), which are subsequently used as guidance to fine-tuned a copy of the original 3DGS model 𝒢src, which is denoted as 𝒢ft:
我们在图3的右下角说明了所提出的模块。最初,我们将多视图编辑的潜在项 �edit 解码为图像,表示为 𝒟(�edit) ,其随后用作指导以微调原始3DGS模型 𝒢src 的副本,其表示为 𝒢ft :
| 𝒢ft=argmin𝒢∑�∈𝒱ℒedit(ℛ(𝒢,�),𝒟(��edit)) | (7) |
Following the rapid fine-tuning process, we render the fine-tuned model 𝒢ft from each viewpoint �∈𝒱, yielding a collection of rendered images that exhibit significantly enhanced coherence. Finally, these images are encoded to the consistent latents, denoted as �con.
在快速微调过程之后,我们从每个视点 �∈𝒱 渲染微调后的模型 𝒢ft ,产生呈现显著增强的相干性的渲染图像的集合。最后,这些图像被编码为一致的潜伏期,表示为 �con 。
Afterwards, we follow [38] and employ a Local Blend module to preserve the unedited details in the source image: Given the cross-attention maps 𝐌con, the source latents �src, and the consistent latents �con, the blending is conducted by:
之后,我们遵循[ 38]并采用局部混合模块来保留源图像中未编辑的细节:给定交叉注意力映射 𝐌con ,源潜伏期 �src 和一致潜伏期 �con ,混合通过以下方式进行:
| �bld=𝐌con*�con+(1−𝐌con)*�src | (8) |
Our empirical findings in appendix suggest that 3DGS is capable of rectifying inconsistencies when the discrepancies between views are minor. Our image editing process, unfolding across various diffusion timesteps following InfEdit [38], guarantees that �edit undergoes only slight changes from �src, maintaining a low level of inconsistencies at each step. Consequently, through continuously calibration at each timestep, the ECM effectively prevents the inconsistencies from accumulating. In our ablation study (Sec. 6.1), we demonstrate the significant capability of this mechanism to address multi-view inconsistencies.
我们在附录中的实证研究结果表明,3DGS是能够纠正不一致的意见之间的差异是轻微的。我们的图像编辑过程,在InfEdit [ 38]之后的各种扩散时间步中展开,保证 �edit 仅从 �src 发生轻微变化,在每个步骤中保持低水平的不一致性。因此,通过在每个时间步长连续校准,ECM有效地防止不一致性累积。在我们的消融研究中(Sec. 6.1),我们证明了这种机制的显着能力,以解决多视图不一致。
4.4Iterative Pattern Extension
4.4迭代模式扩展
To further alleviate the multi-view inconsistency issue, we evolve our VcEdit into an iterative pattern [40]. Based on the image-guided editing pipeline detailed in Sec. 3.2, we define each sequence of transitions —from 𝒢src to ℐsrc, from ℐsrc to ℐedit, and from ℐedit to 𝒢edit—as an iteration. Upon completion of one iteration, the 𝒢edit is forwarded to the subsequent iteration and serves as the new 𝒢src.
为了进一步缓解多视图不一致的问题,我们将VcEdit发展为迭代模式[ 40]。基于第2节中详细介绍的图像引导编辑管道。在图3.2中,我们将每个转换序列-从 𝒢src 到 ℐsrc ,从 ℐsrc 到 ℐedit ,以及从 ℐedit 到 𝒢edit -定义为迭代。在一次迭代完成后, 𝒢edit 被转发到下一次迭代,并作为新的 𝒢src 。
In this pattern, each iteration incrementally aligns the 3DGS more closely with the user’s prompt, facilitating smoother image editing. This fosters a mutual cycle, where ℐedit and 𝒢edit successively refine each other, resulting in ongoing enhancements of editing quality [15]. This leads to more consistent and higher-quality guidance images, which in turn refines the 3DGS for improved 𝒢edit. Taking advantage of our two effective Consistency Modules proposed in Sec. 4.2 and Sec. 4.3, only a few iterations are needed to achieve satisfying editing results. By integrating these strategies, our VcEdit framework effectively ensures multi-view consistency in guidance images and excellence in 3DGS editing.
在此模式中,每次迭代都会使3DGS与用户的提示更紧密地对齐,从而促进更平滑的图像编辑。这促进了一个相互的循环,其中 ℐedit 和 𝒢edit 相继地彼此完善,从而导致编辑质量的持续增强[ 15]。这导致更一致和更高质量的引导图像,这反过来又细化了3DGS,以改进 𝒢edit 。利用我们在第二节中提出的两个有效的一致性模块。4.2与次级4.3,只需要几次迭代就可以达到令人满意的编辑效果。通过集成这些策略,我们的VcEdit框架有效地确保了引导图像的多视图一致性和3DGS编辑的卓越性。
5Experiments 5实验
5.1Implementation Details
5.1实现细节
We implement our experiments using PyTorch based on the official codebase of 3D Gaussian splatting [19]. All of our experiments are conducted on a single NVIDIA RTX A6000 GPU. We used Adam optimizer [21] with a learning rate of 0.001 in both fine-tuning the source 3DGS and our Editing Consistency Module. For each 3DGS editing task, we conduct one to three editing iterations where the source 3DGS is optimized for 400 steps.
我们使用PyTorch基于3D高斯溅射的官方代码库实现我们的实验[ 19]。我们所有的实验都是在一个NVIDIA RTX A6000 GPU上进行的。我们使用Adam优化器[ 21],学习率为0.001,用于微调源3DGS和编辑一致性模块。对于每个3DGS编辑任务,我们进行一到三次编辑迭代,其中源3DGS被优化为400步。
5.2Baselines and Evaluation Protocol
5.2基线和评价方案
We compare our proposed VcEdit method with two baselines: (1) Delta Distillation Sampling (DDS) [16], which utilizes an implicit score function loss derived from a diffusion model as guidance, and (2) the state-of-the-art GSEditor [6], which employs image-guided editing and iteratively updates a training set to steer 3DGS modifications. To ensure a fair comparison, all methods incorporate the same local 3DGS update process pioneered by GSEditor. Our quantitative comparisons assess the similarity of appearance between the edited 3DGS and the user’s prompt with the CLIP-similarity metrics [13]. Furthermore, a user study was conducted to evaluate the effectiveness of editing methods from a human perspective. Please refers to Appendix for the detailed configuration of the user study.
我们将我们提出的VcEdit方法与两个基线进行比较:(1)Delta Distillation Sampling(DDS)[ 16],它利用从扩散模型导出的隐式评分函数损失作为指导,以及(2)最先进的GSEditor [ 6],它采用图像引导编辑并迭代更新训练集以引导3DGS修改。为了确保公平的比较,所有方法都采用了GSEditor首创的相同的本地3DGS更新过程。我们的定量比较评估了编辑的3DGS与用户提示之间的外观相似性,并使用CLIP相似性度量[ 13]。此外,还进行了一项用户研究,从人的角度评估编辑方法的有效性。用户研究的详细配置请参见附录。

Figure 4:Qualitative comparison with the DDS [16] and the GSEditor [6]: The topmost row demonstrate the original views, while the bottom rows show the rendering view of edited 3DGS. VcEdit excels by effectively addressing the multi-view inconsistency, resulting in superior editing quality. In contrast, other methods encounter challenges with mode collapse and exhibit flickering artifacts.
图四:与DDS [ 16]和GSEditor [ 6]的定性比较:最上面的一行展示了原始视图,而下面的一行显示了编辑后的3DGS的渲染视图。VcEdit擅长有效地解决多视图不一致性,从而获得上级编辑质量。相比之下,其他方法遇到模式崩溃的挑战并表现出闪烁伪影。

Figure 5:Extensive Results of VcEdit: Our method is capable of various editing tasks, including face, object, and large-scale scene editing. The leftmost column demonstrates the original view, while the right four columns show the rendered view of edited 3DGS.
图5:VcEdit的广泛结果:我们的方法能够执行各种编辑任务,包括面部,对象和大规模场景编辑。最左边的列显示原始视图,而右边的四列显示编辑后的3DGS的渲染视图。
5.3Qualitative Comparisons
5.3定性比较
We meticulously select three challenging scenarios ranging from human face editing to outdoor scene editing. In the first column of Fig. 4, the precision-demanding task of human face editing highlights the critical importance of accurate manipulation due to the sensitivity of facial features to imperfections. Subsequent columns feature objects placed within outdoor scenes with panoramic rendering views, posing a challenge for methods to maintain view-consistent guidance during editing.
我们精心挑选了三个具有挑战性的场景,从人脸编辑到户外场景编辑。在图4的第一列中,人脸编辑的精度要求高的任务突出了由于面部特征对缺陷的敏感性而导致的精确操纵的至关重要性。随后的列具有放置在具有全景渲染视图的室外场景内的对象,这对在编辑期间保持视图一致性指导的方法构成了挑战。
Fig. 4 shows the editing results achieved by our VcEdit along with those of the baseline methods. (1) We observe a notable editing failure in all the DDS results, where the 3DGS presents severe noisy coloration and shape distortion. (2) When compared to DDS, the output from GSEditor shows better alignment with the target prompt. However, the resulting 3DGS exhibits noticeable artifacts, including noisy coloration and blurred edges. (3) Unlike DDS and GSEditor, our VcEdit consistently delivers clean and intricately detailed edits in all scenes. Our results confirm that VcEdit exhibits superior editing performance compared to other baselines.
图4显示了我们的VcEdit沿着与基线方法一起实现的编辑结果。(1)我们观察到一个显着的编辑失败,在所有的DDS结果,其中的3DGS提出了严重的噪声着色和形状失真。(2)与DDS相比,GSEditor的输出显示出与目标提示更好的一致性。然而,所得到的3DGS表现出明显的伪影,包括嘈杂的着色和模糊的边缘。(3)与DDS和GSEditor不同,我们的VcEdit在所有场景中始终提供清晰和复杂的详细编辑。我们的研究结果证实,VcEdit表现出上级编辑性能相比,其他基线。
Table 1:Quantitative Comparison: Our VcEdit performs in both user study evaluations and CLIP T2I Directional Similarity [12] metrics.
表1:定量比较:我们的VcEdit在用户研究评估和CLIP T2I方向相似性[ 12]指标中均表现出色。
| Metrics\Methods 方法 | DDS [16] | GSEditor [6] | VcEdit |
|---|---|---|---|
| User Study | 1.57% | 34.49% | 63.93% |
| CLIP similarity[13] CLIP相似性[ 13] | 0.1470 | 0.1917 | 0.2108 |
5.4Quantitative Comparisons
5.4定量比较
Despite the subjective nature of 3D scene generation and editing, we adhere to established practices by utilizing the CLIP [30] text-to-image directional similarity metric [13] for quantitative analysis. This metric quantifies the semantic differences between the original and edited 3DGS scenes in relation to their corresponding prompts. Furthermore, we carried out a user study that collected data from 25 participants in 11 samples, each participant tasked with selecting the most superior edit from the edited outcomes of all comparison methods considering alignment to the target prompt and visual quality. Table 1 presents the quantitative results of the evaluation of our approach comparing with DDS and GSEditor in various test scenes. VcEdit not only achieves superior results in the user study but also outperforms in CLIP text-to-image directional similarity. This performance indicates that VcEdit provides high-quality edits that are closely aligned with the intended prompts, significantly outpacing the baseline methods in terms of editing quality and effectiveness.
尽管3D场景生成和编辑具有主观性,但我们坚持利用CLIP [ 30]文本到图像方向相似性度量[ 13]进行定量分析的既定实践。该度量量化了原始和编辑的3DGS场景之间相对于其相应提示的语义差异。此外,我们进行了一项用户研究,从11个样本中的25名参与者收集数据,每个参与者的任务是从所有比较方法的编辑结果中选择最上级的编辑,考虑与目标提示和视觉质量的对齐。表1给出了在各种测试场景中与DDS和GSEditor相比,我们的方法的评估的定量结果。VcEdit不仅在用户研究中取得了上级的结果,而且在CLIP文本到图像的方向相似性方面也表现出色。 这一性能表明,VcEdit提供了与预期提示密切一致的高质量编辑,在编辑质量和有效性方面大大超过了基线方法。
5.5Editing with Diverse Source
5.5编辑不同的来源
Fig. 5 highlights our VcEdit’s adaptability in handling a wide range of challenging scenes and prompts, spanning from intricate face and object transformations to extensive adjustments in large-scale scenes. In the first row, our VcEdit produces an editing result that vividly presents the facial details of the target, “grandma”. The second example highlights VcEdit’s ability to transform a small “doll” into a “robot” while carefully preserving the doll’s key characteristics. In the last row, VcEdit demonstrates its capacity for large-scale scene modifications, convincingly altering a woodland scene to depict it as “on fire”. These instances affirm VcEdit’s competency in delivering high-quality edits across a diverse array of tasks.
图5突出了我们的VcEdit在处理各种具有挑战性的场景和提示时的适应性,从复杂的面部和对象变换到大规模场景中的广泛调整。在第一行中,我们的VcEdit产生了一个编辑结果,生动地呈现了目标“奶奶”的面部细节。第二个例子突出了VcEdit将一个小“娃娃”转换为“机器人”的能力,同时仔细保留了娃娃的关键特征。在最后一行,VcEdit展示了它的大规模场景修改能力,令人信服地改变了林地场景,将其描绘为“着火”。这些实例肯定了VcEdit在各种任务中提供高质量编辑的能力。
6Ablation and Discussion 6消融和讨论
6.1Ablation on Consistency Modules
6.1消融一致性模块
Sec. 4.2 and 4.3 respectively introduced the Cross-attention Consistency Module (CCM) and the Editing Consistency Module (ECM). This section presents an ablation study to assess the impact of these modules. Given the critical role of multi-view consistent guidance in image-guided 3D editing as discussed in Sec. 1, our analysis focuses on the view-consistency of the edited 2D images. To understand why VcEdit outperforms the baseline methods, we revisit the cases of “clown” and “brown bear” from Sec. 5.3 for a detailed analysis.
秒4.2和4.3分别介绍了交叉注意一致性模块(CCM)和编辑一致性模块(ECM)。本节介绍了一项消融研究,以评估这些模块的影响。鉴于多视图一致性指导在图像引导3D编辑中的关键作用,如第1,我们的分析集中在编辑的2D图像的视图一致性。为了理解为什么VcEdit优于基线方法,我们重新审视了来自SEC的“小丑”和“棕熊”的案例。5.3进行详细分析。
We conducted a comparative analysis of the edited images produced by three variant versions of VcEdit: the vanilla version without any consistency module; the version with CCM but without ECM; and the version that employs both CCM and ECM. The top 3 rows in Fig. 6 displays the comparison results: (1) The edited images of the vanilla version contain significant view inconsistencies in the two samples. These incoherent edited contents among views can lead to the anomalies in the 3DGS. (2) Applying the CCM markedly enhances the view consistency. Compared to the vanilla version, the edited images show a reduction of the incoherent content. (3) When both consistency modules are employed, the results are in perfect coherence among the edited views. In conclusion, both the Cross-attention and Editing Consistency Modules play vital roles in addressing multi-view inconsistency, enabling VcEdit to provide more accurate and detailed 3D editing through consistent image guidance.
我们对VcEdit的三个变体版本产生的编辑图像进行了比较分析:没有任何一致性模块的vanilla版本;有CCM但没有ECM的版本;以及同时使用CCM和ECM的版本。图6中的前3行显示了比较结果:(1)vanilla版本的编辑图像在两个样本中包含显著的视图不一致。这些视图之间不一致的编辑内容可能导致3DGS中的异常。(2)应用CCM显著提高了视图的一致性。与普通版本相比,编辑后的图像减少了不连贯的内容。(3)当使用这两个一致性模块时,编辑的视图之间的结果是完全一致的。总之,交叉注意和编辑一致性模块在解决多视图不一致性方面发挥着至关重要的作用,使VcEdit能够通过一致的图像指导提供更准确和详细的3D编辑。
In addition, we further compare the edited images produced by our VcEdit and GSEditor in the bottom 2 rows of Fig. 6. The edited guidance images of our VcEdit employing both CCM and ECM achieves significantly better multi-view consistency than that of using GSEditor, which explains the performance gap in edited 3DGS discussed in Sec. 5.3.
此外,我们进一步比较了在图6的底部2行中由我们的VcEdit和GSEditor生成的编辑图像。我们的VcEdit使用CCM和ECM编辑的制导图像比使用GSEditor实现了更好的多视图一致性,这解释了第2节中讨论的编辑3DGS中的性能差距。5.3.

Figure 6:Top: 2D edited guidance images using three variant versions of VcEdit: vanilla version without any consistency module, version without ECM, and the original VcEdit employs both CCM and ECM. Bottom: 2D edited guidance images using GSEditor
图6:顶部:使用VcEdit的三个变体版本进行2D编辑的制导图像:没有任何一致性模块的vanilla版本,没有ECM的版本,以及原始VcEdit同时使用CCM和ECM。底部:使用GSEditor编辑的2D引导图像
6.2Ablation on Iterative Pattern
6.2迭代模式下的消融
In Sec. 4.4, we expand our framework to include an iterative pattern to further reduce the adverse effects of multi-view inconsistency. This section analyzes the impact of this iterative approach on the 3DGS editing performance. We specifically re-examine the “man to grandma" and “man to clown" examples by comparing the 3DGS editing outcomes of the first and second iterations. Our findings, presented in Fig. 7, show that: (1) In the “man to grandma" case, the second iteration significantly refines facial details and clothing. (2) In the “man to clown" case, the second iteration further accentuates the “clown" features by intensifying the makeup and smoothing facial details. (3) Even in the first iteration, our VcEdit achieves relatively satisfying multi-view consistency, which is attributed to our effective Consistency Modules. These enhancements confirm that through reciprocal and continuous refinement of 3DGS and image guidance, the iterative pattern progressively steers the samples towards a consistent style that aligns with the desired target, leading to improved editing quality.
节中4.4,我们扩展了我们的框架,包括一个迭代模式,以进一步减少多视图不一致的不利影响。本节分析此迭代方法对3DGS编辑性能的影响。我们通过比较第一次和第二次迭代的3DGS编辑结果,特别重新检查了“男人到奶奶”和“男人到小丑”的例子。我们的发现,如图7所示,表明:(1)在“男人到奶奶”的情况下,第二次迭代显着细化面部细节和服装。(2)在“男人变小丑”的情况下,第二次迭代通过强化化妆和平滑面部细节来进一步突出“小丑”的特征。(3)即使在第一次迭代中,我们的VcEdit也实现了相对令人满意的多视图一致性,这归功于我们有效的一致性模块。 这些增强功能证实,通过3DGS和图像引导的相互和持续改进,迭代模式可逐步将样本转向与所需目标一致的风格,从而提高编辑质量。
6.3Limitations
In line with earlier efforts in 3D editing [15, 6] that utilize the image-guided editing pipeline, our VcEdit depends on the 2D editing models to generate image guidance, which leads to two specific limitations: (1) Current diffusion-based image editing models occasionally fail to deliver high-quality image editing for intricate prompts, thus impacting the efficacy of 3D editing. (2) In non-rigid editing scenarios that request drastically changing of object shape, current diffusion models produce highly variant editing results among views, which makes it hard for our consistency modules to rectify the tremendous inconsistency, thereby limits the quality of 3D editing.
与利用图像引导编辑管道的3D编辑[15,6]的早期努力一致,我们的VcEdit依赖于2D编辑模型来生成图像引导,这导致了两个特定的限制:(1)当前基于扩散的图像编辑模型偶尔无法为复杂的提示提供高质量的图像编辑,从而影响3D编辑的功效。(2)在非刚性编辑场景中,要求对象形状发生剧烈变化,当前的扩散模型在视图之间产生高度变化的编辑结果,这使得我们的一致性模块难以纠正巨大的不一致性,从而限制了3D编辑的质量。

Figure 7:Edited 3DGS after each iteration: Following the iterative pattern, the edited 3DGS is progressively refined by each iteration.
图7:每次迭代后编辑的3DGS:按照迭代模式,编辑的3DGS在每次迭代中逐渐细化。
7Conclusion 7结论
In this paper, we propose the View-consistent Editing (VcEdit) framework for 3D Editing using text instruction, aiming to address the multi-view inconsistency issue in image-guided 3DGS editing. By seamlessly incorporating 3DGS into the editing processes of the rendered images, VcEdit ensures the multi-view consistency in image guidance, effectively mitigating mode collapse issues and achieving high-quality 3DGS editing. Several techniques are proposed to achieve multi-view consistency in the guidance images, including two innovative Consistency Modules integrated in an iterative pattern. Our extensive evaluations across various real-world scenes have demonstrated VcEdit’s ability to outperform existing state-of-the-art methods, thereby setting a new standard for text-driven 3D model editing. The introduction of VcEdit solves a critical problem in 3DGS editing, inspiring the exploration of future efforts.
针对图像引导三维图形编辑中的多视图不一致问题,提出了基于文本指令的视图一致性编辑框架(VcEdit)。通过将3DGS无缝地整合到渲染图像的编辑过程中,VcEdit确保了图像引导中的多视图一致性,有效地缓解了模式崩溃问题并实现了高质量的3DGS编辑。提出了几种技术来实现多视图的指导图像的一致性,包括两个创新的一致性模块集成在一个迭代模式。我们对各种真实场景的广泛评估表明,VcEdit的性能优于现有的最先进的方法,从而为文本驱动的3D模型编辑设定了新的标准。VcEdit的引入解决了3DGS编辑中的一个关键问题,激发了未来努力的探索。