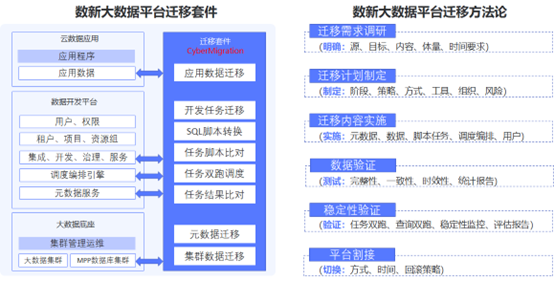
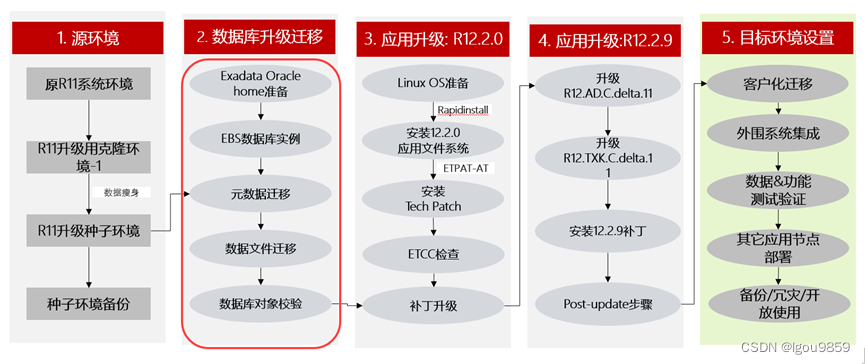
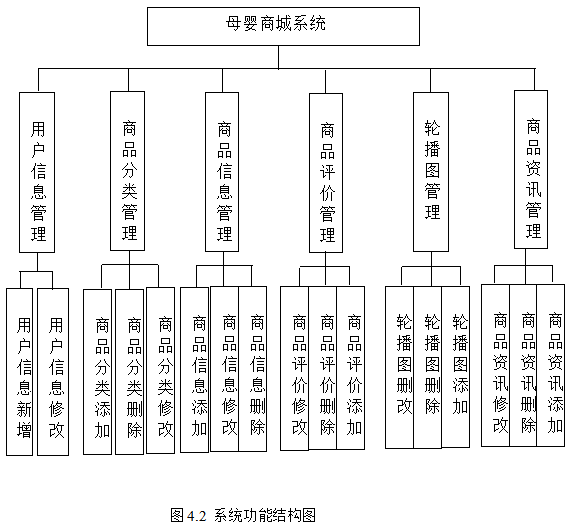
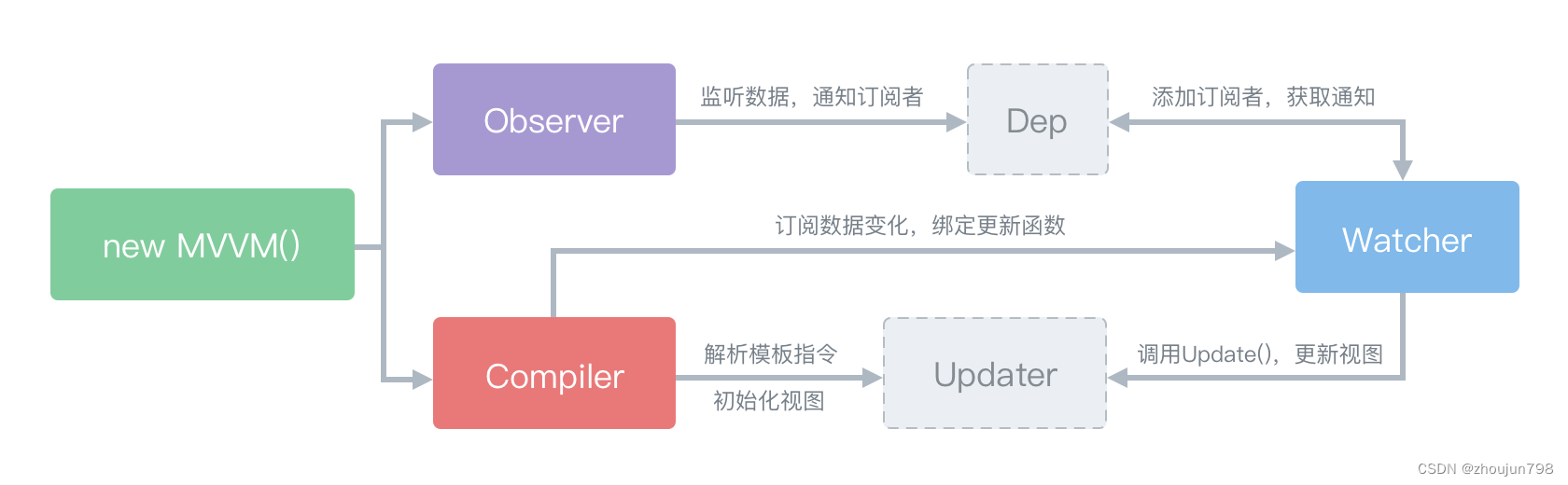
数据库迁移流程:
迁移前:迁移评估
迁移中:结构迁移 数据迁移 数据校验 流量切割 业务验证 反向回滚
迁移后:压测 巡检
架构思考
交互层:
产品模块:数据迁移,数据订阅,数据同步
通用服务:用户管理,权限管理,审核,基本任务信息管理,变更管理
核心设计:任务的流程:创建,启动,停止,释放,审核,健全
控制层:
运维:监控,启停,扩容
引擎层:
数据迁移:Datax
数据订阅:canal
数据同步:otter
其他参考:dbswitch,flink cdc
一、 dbswitch (https://gitee.com/dromara/dbswitch)
1、 工具介绍
功能描述
一句话,dbswitch工具提供源端数据库向目的端数据库的批量迁移同步功能,支持数据的全量和增量方式同步。包括:
结构迁移
支持字段类型、主键信息、建表语句等的转换,并生成建表SQL语句。
支持基于正则表达式转换的表名与字段名映射转换。
数据同步。
基于JDBC的分批次读取源端数据库数据,并基于insert/copy方式将数据分批次写入目的数据库。
支持有主键表的 增量变更同步 (变化数据计算Change Data Calculate)功能(千万级以上数据量的性能尚需在生产环境验证)
2、 一键安装部署
curl -sSL https://gitee.com/dromara/dbswitch/attach_files/1696955/download > /tmp/dbswitch_install.sh && bash /tmp/dbswitch_install.sh
3、登录(基于web方式)
http://10.0.71.39:9088/#/dashboard
密码 admin/123456
4、基于配置文件使用方式
dbswitch工具提供基于conf/config.yml配置的dbswitch-data模块启动方式和基于conf/application.yml的dbswitch-admin模块的WEB端使用方式;
1) 配置文件
配置文件信息请见部署包中的:conf/config.yml(注:也同时支持使用conf/config.properties配置文件名的properties格式),示例配置如下:
dbswitch:
source:
# source database connection information
## support multiple source database connection
url: jdbc:oracle:thin:@172.17.2.10:1521:ORCL
driver-class-name: 'oracle.jdbc.driver.OracleDriver'
driver-path: D:/Workspace/dbswitch/driver/oracle/oracle-12c
username: 'system'
password: '123456'
# source database configuration parameters
## fetch size for query source database
fetch-size: 10000
## schema name for query source schemas, separate by ','
source-schema: 'TANG'
## table type which include or exclude,option: TABLE,VIEW
table-type: 'TABLE'
## table name include from table lists, separate by ','
source-includes: ''
## table name exclude from table lists, separate by ','
source-excludes: ''
## table name convert mapper by regular expression
regex-table-mapper:
- from-pattern: '^'
to-value: 'T_'
## columns name convert mapper by regular expression like regex-table-mapper
regex-column-mapper:
target:
# target database connection information
## Best support for Oracle/PostgreSQL/Greenplum/DM(But not is Hive) etc.
url: jdbc:postgresql://172.17.2.10:5432/test
driver-class-name: org.postgresql.Driver
driver-path: D:/Workspace/dbswitch/driver/postgresql/postgresql-11.4
username: test
password: 123456
# target database configuration parameters
## schema name for create/insert table data
target-schema: public
## table name to uppper case, option: UPPER,LOWER,NONE
table-name-case: UPPER
## column name to uppper case, option: UPPER,LOWER,NONE
column-name-case: UPPER
## whether drop-create table when target table exist
target-drop: true
## whether create table support auto increment for primary key field
create-table-auto-increment: false
## whether use insert engine to write data for target database
## Only useful for PostgreSQL/Greenplum database
writer-engine-insert: false
## whether use change data synchronize to target database table
change-data-sync: true
| 配置参数 | 配置说明 | 示例 | 备注 |
|---|---|---|---|
| dbswitch.source.url | 来源端JDBC连接的URL | jdbc:oracle:thin:@10.17.1.158:1521:ORCL | 可为:oracle/mysql/mariadb/sqlserver/postgresql/db2/dm/kingbase8/highgo |
| dbswitch.source.driver-class-name | 来源端数据库的驱动类名称 | oracle.jdbc.driver.OracleDriver | 对应数据库的驱动类 |
| dbswitch.source.driver-path | 来源端数据库的驱动JAR所在目录 | D:/Workspace/dbswitch/driver/oracle/oracle-12c | 对应数据库的驱动JAR所在目录 |
| dbswitch.source.username | 来源端连接帐号名 | test | 无 |
| dbswitch.source.password | 来源端连接帐号密码 | 123456 | 无 |
| dbswitch.source.fetch-size | 来源端数据库查询时的fetch_size设置 | 10000 | 需要大于100有效 |
| dbswitch.source.source-schema | 来源端的schema名称 | dbo,test | 多个之间用英文逗号分隔 |
| dbswitch.source.table-type | 来源端表的类型 | TABLE | 可选值为:TABLE、VIEW ,分别代表物理表和试图表 |
| dbswitch.source.source-includes | 来源端schema下的表中需要包含的表名称 | users1,orgs1 | 支持多个表(多个之间用英文逗号分隔);支持支持正则表达式(不能含有逗号) |
| dbswitch.source.source-excludes | 来源端schema下的表中需要过滤的表名称 | users,orgs | 不包含的表名称,多个之间用英文逗号分隔 |
| dbswitch.source.regex-table-mapper | 基于正则表达式的表名称映射关系 | [{“from-pattern”: “^”,“to-value”: “T_”}] | 为list类型,元素存在顺序关系 |
| dbswitch.source.regex-column-mapper | 基于正则表达式的字段名映射关系 | [{“from-pattern”: “$”,“to-value”: “_x”}] | 为list类型,元素存在顺序关系 |
| dbswitch.target.url | 目的端JDBC连接的URL | jdbc:postgresql://10.17.1.90:5432/study | 可为:oracle/sqlserver/postgresql/greenplum,mysql/mariadb/db2/dm/kingbase8/highgo也支持,但字段类型兼容性问题比较多 |
| dbswitch.target.driver-class-name | 目的端数据库的驱动类名称 | org.postgresql.Driver | 对应数据库的驱动类 |
| dbswitch.target.driver-path | 目的端数据库的驱动JAR所在目录 | D:/Workspace/dbswitch/driver/postgresql/postgresql-11.4 | 对应数据库的驱动JAR所在目录 |
| dbswitch.target.username | 目的端连接帐号名 | test | 无 |
| dbswitch.target.password | 目的端连接帐号密码 | 123456 | 无 |
| dbswitch.target.target-schema | 目的端的schema名称 | public | 目的端的schema名称只能有且只有一个 |
| dbswitch.target.table-name-case | 表名大小写转换策略 | UPPER | 可选值为: UPPER,LOWER,NONE |
| dbswitch.target.column-name-case | 列名大小写转换策略 | UPPER | 可选值为: UPPER,LOWER,NONE |
| dbswitch.target.target-drop | 是否执行先drop表然后create表命令,当target.datasource-target.drop=true时有效 | true | 可选值为:true、false |
| dbswitch.target.create-table-auto-increment | 是否执启用支持create表时主键自增 | true | 可选值为:true、false |
| dbswitch.target.writer-engine-insert | 是否使用insert写入数据 | false | 可选值为:true为insert写入、false为copy写入,只针对目的端数据库为PostgreSQL/Greenplum的有效 |
| dbswitch.target.change-data-sync | 是否启用增量变更同步,dbswitch.target.target-drop为false时且表有主键情况下有效,千万级以上数据量建议设为false | false | 可选值为:true、false |
| 注意: | |||
| (1)如果dbswitch.source.source-includes不为空,则按照包含表的方式来执行; | |||
| (2)如果dbswitch.source.source-includes为空,则按照dbswitch.source.source-excludes排除表的方式来执行。 | |||
| (3)如果dbswitch.target.target-drop=false,dbswitch.target.change-data-synch=true;时会对有主键表启用增量变更方式同步 | |||
| (4)对于regex-table-mapper和regex-column-mappe,为基于正则表达式替换的表名映射和字段名映射,均可以为空(代表原名映射,即源的表t_a映射到目的端也为t_a) | |||
| 提示:如果要将源端所有表名(或者字段名)添加前缀,可以配置"from-pattern": “^”,“to-value”: “T_”; | |||
| (5)支持的数据库产品及其JDBC驱动连接示例如下: |
MySQL/MariaDB数据库
jdbc连接地址:jdbc:mysql://172.17.2.10:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&tinyInt1isBit=false&rewriteBatchedStatements=true&useCompression=true
jdbc驱动名称: com.mysql.jdbc.Driver
与:
jdbc连接地址:jdbc:mariadb://172.17.2.10:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&tinyInt1isBit=false&rewriteBatchedStatements=true&useCompression=true
jdbc驱动名称: org.mariadb.jdbc.Driver
Oracle数据库
jdbc连接地址:jdbc:oracle:thin:@172.17.2.10:1521:ORCL 或 jdbc:oracle:thin:@//172.17.2.10:1521/ORCL
jdbc驱动名称:oracle.jdbc.driver.OracleDriver
SQL Server(>=2005)数据库
jdbc连接地址:jdbc:sqlserver://172.17.2.10:1433;DatabaseName=test
jdbc驱动名称:com.microsoft.sqlserver.jdbc.SQLServerDriver
Sybase数据库
jdbc连接地址:jdbc:sybase:Tds:172.17.2.10:5000/test?charset=cp936
jdbc驱动名称:com.sybase.jdbc4.jdbc.SybDriver
JDBC连接Sybase数据库使用中文时只能使用CP936这个字符集
PostgreSQL/Greenplum数据库
jdbc连接地址:jdbc:postgresql://172.17.2.10:5432/test
jdbc驱动名称:org.postgresql.Driver
DB2数据库
jdbc连接地址:jdbc:db2://172.17.2.10:50000/testdb:driverType=4;fullyMaterializeLobData=true;fullyMaterializeInputStreams=true;progressiveStreaming=2;progresssiveLocators=2;
jdbc驱动名称:com.ibm.db2.jcc.DB2Driver
达梦DM数据库
jdbc连接地址:jdbc:dm://172.17.2.10:5236
jdbc驱动名称:dm.jdbc.driver.DmDriver
人大金仓Kingbase8数据库
jdbc连接地址:jdbc:kingbase8://172.17.2.10:54321/MYTEST
jdbc驱动名称:com.kingbase8.Driver
神通Oscar数据库
jdbc连接地址:jdbc:oscar://172.17.2.10:2003/OSRDB
jdbc驱动名称:com.oscar.Driver
南大通用GBase8a数据库
jdbc连接地址:jdbc:gbase://172.17.2.10:5258/gbase
jdbc驱动名称:com.gbase.jdbc.Driver
翰高HighGo数据库(可按PostgreSQL使用)
jdbc连接地址:jdbc:highgo://172.17.2.10:5866/highgo
jdbc驱动名称:com.highgo.jdbc.Driver
Apache Hive数据库
jdbc连接地址:jdbc:hive2://172.17.2.12:10000/default
jdbc驱动名称:org.apache.hive.jdbc.HiveDriver
注意:当前只支持hive version 3.x的账号密码认证方式。
OpenGauss数据库
jdbc连接地址:jdbc:opengauss://172.17.2.10:5866/test
jdbc驱动名称:org.opengauss.Driver
ClickHouse数据库
jdbc连接地址:jdbc:clickhouse://172.17.2.10:8123/default
jdbc驱动名称:com.clickhouse.jdbc.ClickHouseDriver
SQLite数据库
jdbc连接地址:jdbc:sqlite:/tmp/test.db 或者 jdbc:sqlite::resource:http://172.17.2.12:8080/test.db
jdbc驱动名称:org.sqlite.JDBC
注意:
(a) 本地文件方式:jdbc:sqlite:/tmp/test.db , 该方式适用于dbswitch为实体机器部署的场景。
(b) 远程文件方式: jdbc:sqlite::resource:http://172.17.2.12:8080/test.db ,该方式适用于容器方式部署的场景, 搭建文件服务器的方法可使 用如下docker方式快速部署(/home/files为服务器上存放sqlite数据库文件的目录):
docker run -d --name http_file_server -p 8080:8080 -v /home/files:/data inrgihc/http_file_server:latest
说明:远程服务器文件将会被下载到本地System.getProperty(“java.io.tmpdir”)所指定的目录下(linux为/tmp/,Windows为C:/temp/),并以 sqlite-jdbc-tmp-{XXX}.db的方式进行文件命名,其中{XXX}为文件网络地址(例如上述为http://192.168.31.57:8080/test.db) 的字符串哈希值, 如果本地文件已经存在则不会再次进行下载而是直接使用该文件(当已经下载过文件后,远程服务器即使关闭了,该sqlite的jdbc-url任然可 用,直至本地的sqlite-jdbc-tmp-XXX.db文件被人为手动删除)
© 不支持内存及其他方式;本地文件方式可以作为源端和目的端,而远程服务器方式只能作为源端。
(d) SQLite为单写多读方式,禁止人为方式造成多写导致锁表。
MongoDB数据库
jdbc连接地址:jdbc:mongodb://172.17.2.12:27017/admin?authSource=admin&authMechanism=SCRAM-SHA-1
jdbc驱动名称:com.gitee.jdbc.mongodb.JdbcDriver
ElasticSearch数据库
jdbc连接地址:jdbc:jest://172.17.2.12:9200?useHttps=false
jdbc驱动名称:com.gitee.jdbc.elasticsearch.JdbcDriver
2) 启动方法
linux系统下:
cd dbswitch-release-X.X.X/
bin/datasync.sh
windows系统下:
切换到dbswitch-release-X.X.X/bin/目录下,双击datasync.cmd脚本文件即可启动
3) 额外说明
1)对于向目的库为PostgreSQL/Greenplum的数据离线同步默认采用copy方式写入数据,说明如下:
(a) 如若使用copy方式写入,配置文件中需配置为postgresql的jdbc url和驱动类(不能为greenplum的驱动包),
(b) 如若使用insert方式写入,需要在config.properties配置文件中设置如下参数为true:
dbswitch.target.writer-engine-insert=true
2)dbswitch离线同步工具支持的数据类型包括:整型、时间、文本、二进制等常用数据类型;
3)Oracle的表虽然设置了主键,如果主键约束实际为DISABLED状态,那在进行结构转换时会按照没有此主键处理。
4)关于增量变更同步方式的使用说明
步骤A:先通过设置dbswitch.target.target-drop=true,dbswitch.target.change-data-sync=false;启动程序进行表结构和数据的全量同步;
步骤B:然后设置dbswitch.target.target-drop=false,dbswitch.target.change-data-sync=true;再启动程序对(有主键表)数据进行增量变更同步。
注:如果待同步的两端表结构已经一致或源端字段是目的端字段的子集,也可直接用步骤B配置进行变更同步
二、TIS数据同步
1、 简介
实时ETL数仓
TIS的愿景是实现企业大数据ETL(Extraction-Transformation-Loading)全覆盖的中台产品,数据抽取(Extraction)是大数据处理所有环节中的第一步,也是最重要的环节。
最新版本的TIS数据抽取组件是基于:
- Alibaba DataX,并且在原生DataX之上添加了功能特性大大提高了DataX的可用性
- 实时数据同步框架Flink-CDC和Chunjun
![[Pasted image 20240410160903.png]]
当业务分析场景中只需要T+1的数据报表分析,则只需要开启基于DataX的批量数据同步功能。如需要启用实时OLAP数据分析功能,则需要开启基于Flink的实时数据同步功能。
2、 功能特性
基于Web UI的开箱即用
TIS基于ng-zorro-antd UI组件开发了一套覆盖DataX 任务定义、执行、更新等生命周期的流程实现,让用户轻松点击鼠标,让各种类型的数据在个端之间畅通无阻。
系统中提供了各种校验及错误提示机制,让用户不需要直接编辑DataX JSON格式的脚本,而是,TIS系统自动生成DataX JSON配置脚本。因此,大大避免了原生DataX配置目繁杂带来的不必要的错误。
支持分布式任务分发
原生开源版DataX解决方案是单机执行的,由于单节点执行任务吞吐量的限制,需要对DataX进行二次开发才能在生产环境中部署。
TIS支持单节点和分布式两种任务执行模式。分布式模式基于ZK的Curator分布式任务队列实现Master-Slaver模式,由K8S容器中的Slaver节点来消费任务。
全新的基于微内核的运行环境
按照DataX UserGuid介绍,为了运行DataX需要在本地部署多个组件,对于普通小白用户来说有一定门槛。
TIS采用微内核的架构设计,参照Jenkins的插件架构体系,初始安装包只有300兆。运行时根据需要,在控制台中轻点鼠标,动态加载具体的DataX Plugin(Reader/Writer)。
对于企业级大数据中台产品内部会有非常多的组件,但是用户只会用到部分组件,采用微内核按需加载的方式会带来非常多的好处。
**功能覆盖DataX大部分(Reader/Writer)Plugin
- 最新版本已经支持了DataX官方大部分核心Reader/Writer插件,其他插件将会在后续版本中添加。
- 新版本额外添加了对TiDB Reader Plugin支持
重构DataX的Classloader
重构DataX默认ClassLoadercom.alibaba.datax.core.util.container.JarLoader,对其功能嫁接到了TIS的com.qlangtech.tis.datax.TISJarLoader之上,实现了基于TIS平台可视化的插件加载机制,提升了用户体验。
支持RDBMS类型的Writer自动生成目标表
部分RDMS类型的Writer数据源如MySQL,Clickhouse等系统实现了通过反射Reader数据源的Meta信息,自动生成Writer Plugin对应的目标数据表,免去了手动创建Writer目标表的DDL语句。
支持Hive,Spark表自动创建,自动添加Partition(基于日期的)
简化DataX部署方式:
原生DataX部署方案要求,需要在本地环境中支持Python运行环境DataX UserGuid,根据以往经验,Python运行环境的各种问题,常常导致DataX脚本无法正常执行,其实Python只是起到了DataX命令行参数的传递的作用。 所以在TIS的DataX整合方案中已经将Pyhton环境部署的环节去除掉了,这样一来提高了DataX运行稳定性。
该部分待测
二、 数据库结构导入
mysqldump
三、数据结构对比
mysqldiff
DBCompare --功能很鸡肋
结构修复
四、记录数对比
mysqldbcompare
pt-table-checksum
pt-table-checksum
一致性修复
pt-table-sync
五、 增量同步
canal
flink cdc
六、其他功能