文章目录
前言
学习使用c#制作一个windows小程序在小说网站爬取小说。对于一些网络小说想要下下来却找不到下载的地方,只要能在线浏览的基本都可以通过分析后台的html来获取到内容。
一、准备工作
1.本文使用VS2022,为了程序的电脑通用性,使用比较老的.NET Framework2.0
2.小说网站的地址,http://www.ibookben.net/read/145998/67497399.html,随便找的一个作为参考
二、步骤
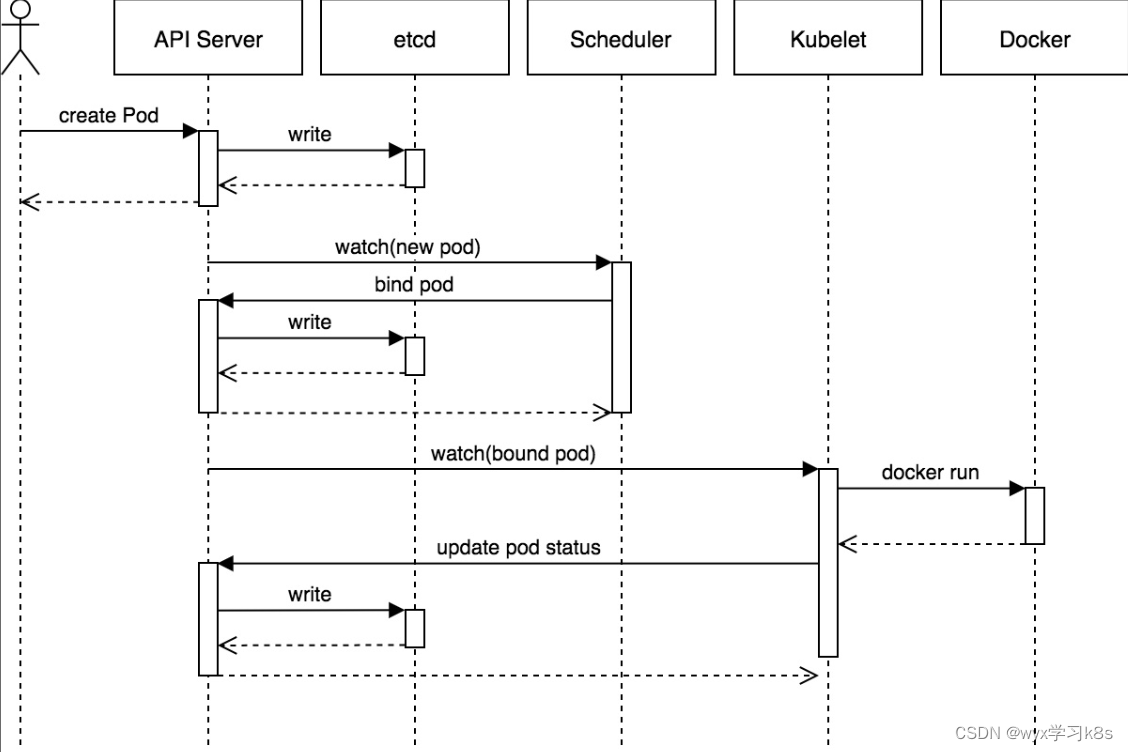
1.获取小说网站html内容
1.可以通过chrome浏览器的F12查看
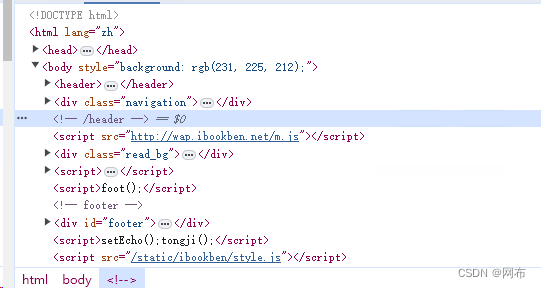
2.通过保存网页查看也可以,右键另存为,选择html,然后使用文本工具打开,如下图所示:

得到上图所示内容即可
2.编写VS C#代码
1.新建工程
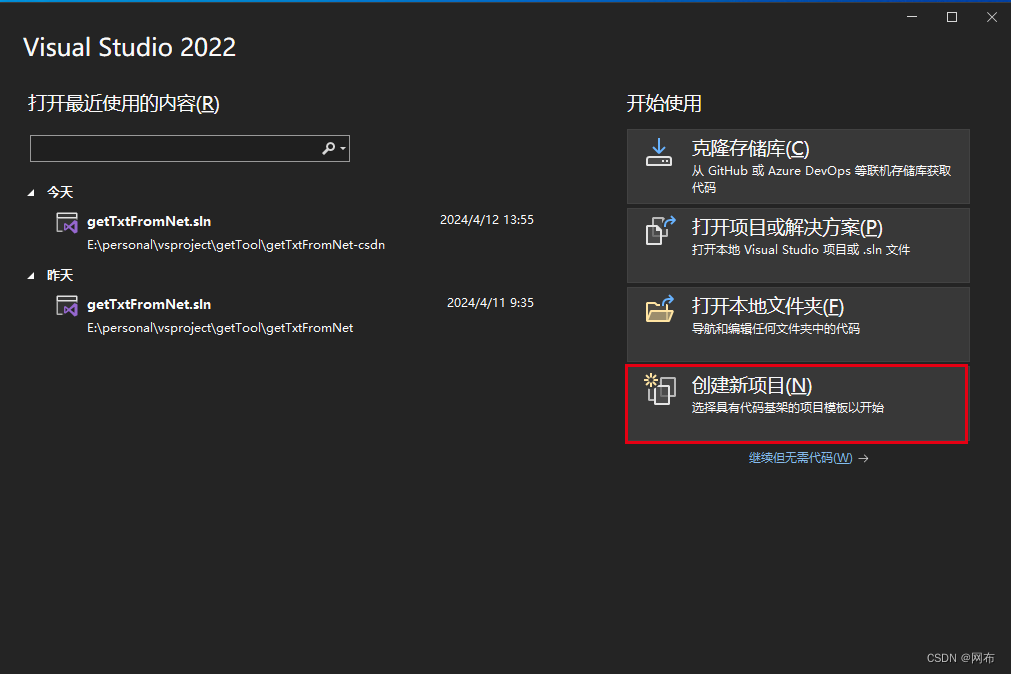
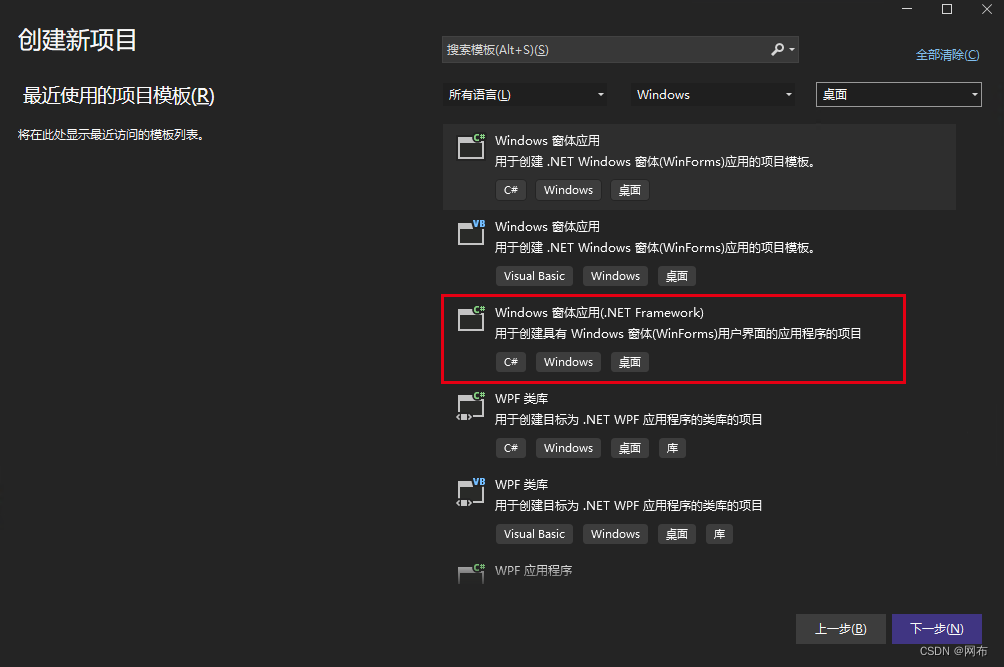
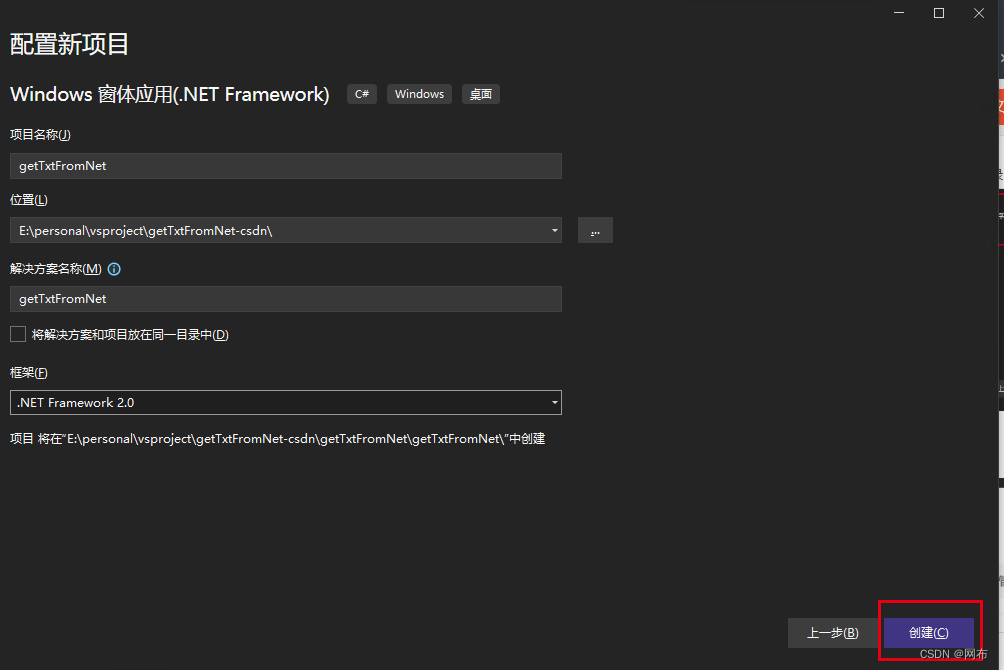
即可创建成功
2.添加库
依次打开,工具->NuGet包管理器->管理解决方案的NuGet程序包
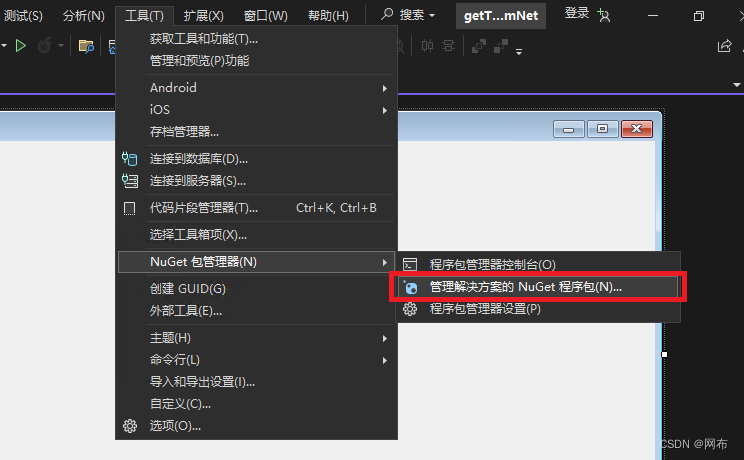
如下图在浏览中搜索winista,然后依次选择画红框的地方,最后点击安装即可安装成功
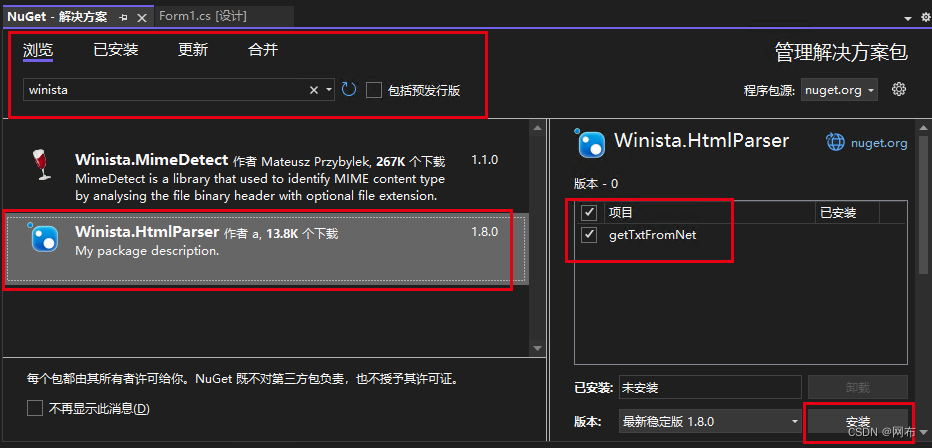
安装成功之后会在引用中出现:
3.调整窗口布局
这里调整下窗口布局,如果不想用到窗口程序,要在新建工程的时候使用控制台程序即可。我们给窗口增加一个名字:
添加一个TextBox文本框用于输入链接
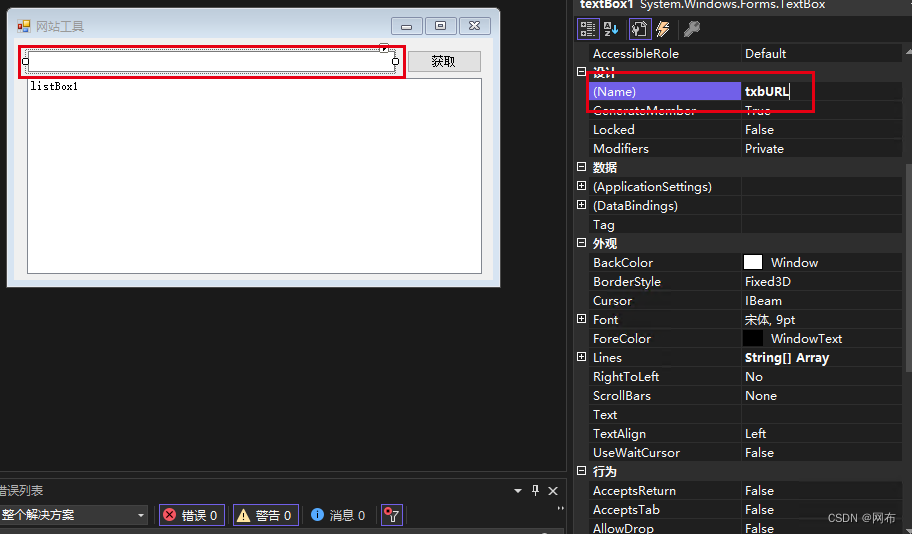
添加一个Button按钮用于启动整个程序,双击控件生成事件代码
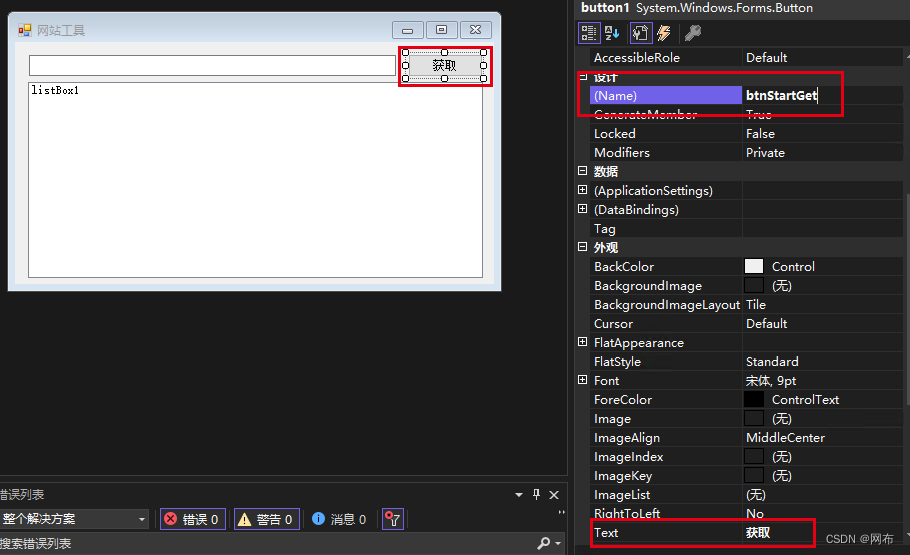
添加一个ListBox输出状态提示等信息
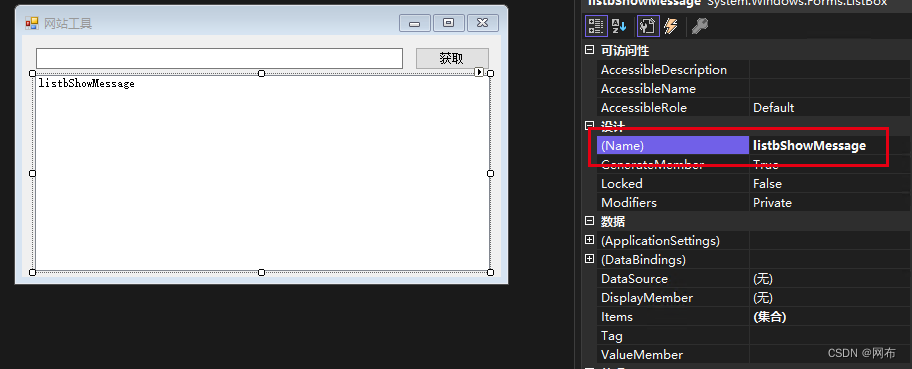
4.添加代码
1.在public Form1()中添加如下代码:
CheckForIllegalCrossThreadCalls = false;
2.在public partial class Form1 : Form中添加如下函数:
private void IncludeTextMessage(string strMsg)
{
listbShowMessage.Items.Add(DateTime.Now.TimeOfDay + ":" + strMsg);
listbShowMessage.SelectedIndex = listbShowMessage.Items.Count - 1;
while (listbShowMessage.Items.Count > 50)
{
listbShowMessage.Items.RemoveAt(0);
}
}
该函数用于在listbox中添加要显示的内容,可以自动定位到最后一行,可以通过滚动条存储50条。
3.在public partial class Form1 : Form中添加get_html函数:
string get_html(string url)
{
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Method = "GET";
request.Timeout = 5000;
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
StreamReader sr = new StreamReader(response.GetResponseStream(), Encoding.UTF8);
html = sr.ReadToEnd();
sr.Close();
response.Close();
return html;
}
该函数通过输入的url来生成html的字符串
3.解析html的内容
要把小说的内容抓取下来需要得到下面几个重要的内容,一个是当前章节的题目,第二个是当前章节的内容,第三个是下一个章节的链接,最后是结束的地方是怎么判断的,可以通过观察html文本依次解析出来:
1.当前章节的题目:
在该html文本中发现如下内容:
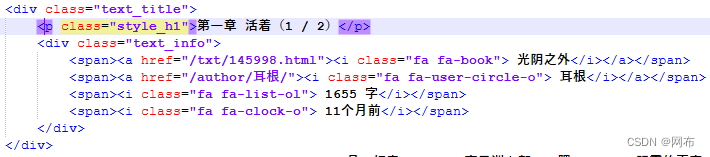
通过一个tag包裹的标题,“p”这个tag,并且具有属性class=“style_h1”,通过搜索发现只有这一个属性是style_h1,那就可以根据这个属性来找到后面的节点的内容也就是章节标题
string get_chapter_name(string html)
{
string chapter_name = "";
//根据传入的html字符串的内容生成一个解析器
Parser parser = Parser.CreateParser(html, null);
//在解析器中添加过滤的内容:tag是"p"并且有个属性是class值为style_h1
//得到返回值就是所有符合条件的节点
NodeList nodeList = parser.Parse(new AndFilter(new TagNameFilter("p"), new HasAttributeFilter("class", "style_h1")));
//因为在整个html中只有这一个节点符合内容,所以使用的是[0]来解析
//取出这个节点的第一个内容,也就是文档标题
chapter_name = nodeList[0].FirstChild.GetText() + "\n";
return chapter_name;
}
在按钮的事件代码里做验证,之前双击按钮生成了一个事件代码,在这个事件代码中添加打印文章标题的测试代码:
private void btnStartGet_Click(object sender, EventArgs e)
{
IncludeTextMessage(get_chapter_name(get_html("http://www.ibookben.net/read/145998/67497399.html")));
}
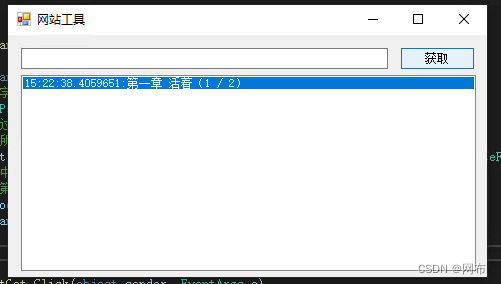
点击运行并在窗口中点击获取可以看到正确输出了文章章节的标题
2.当前章节的内容:
在该html文本中发现如下内容:

这回通过直接寻找"p"标签来提取内容不太行了,应为有很多相通的标签并且这些标签没有属性,不好区分,这个时候可以通过正文前面的那个tag来查找,通过找到article id="article"这个标签找到该节点,然后再用来siblingNode寻找所有的节点,也就是正文的内容,正文的内容是很多个siblingNode组成的,代码如下:
string get_context(string html)
{
string context = "";
//根据html创建解析器
Parser parser = Parser.CreateParser(html, null);
//在解析器中添加过滤的内容:tag是"article"并且有个属性是id值为article
//得到返回值就是所有符合条件的节点,其实只有一个
NodeList nodeList = parser.Parse(new AndFilter(new TagNameFilter("article"), new HasAttributeFilter("id", "article")));
//通过nextsibling获取这个节点下面的内容,不停的循环获取
INode siblingNode = nodeList[0].NextSibling;
while (siblingNode.FirstChild != null)
{
//如果需要换行就加上,不需要换行就去掉
context += siblingNode.FirstChild.GetText() + "\n";
siblingNode = siblingNode.NextSibling;
}
return context;
}
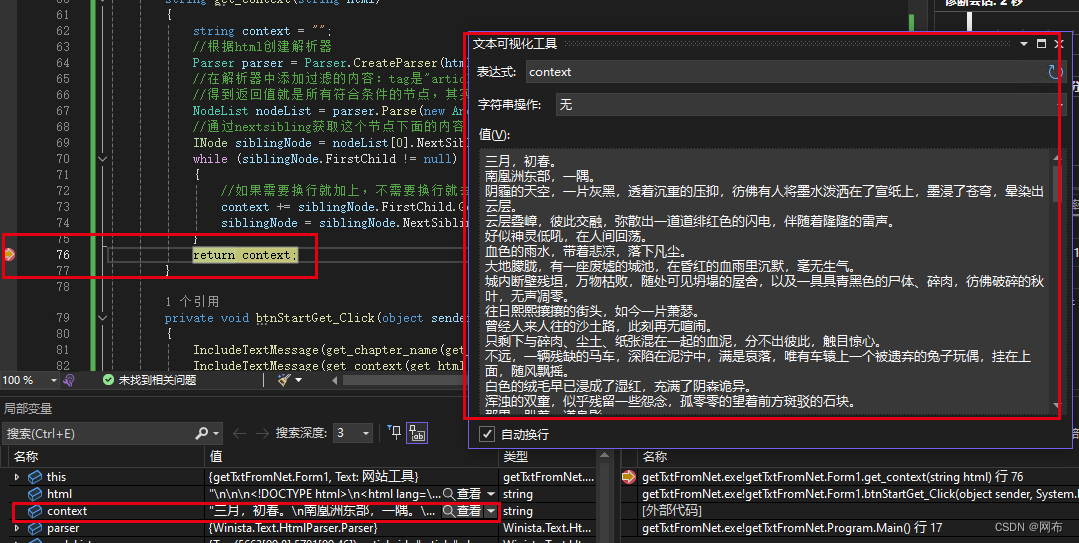
将断点设置在return context上,在按钮事件中加入get_context(get_html(“http://www.ibookben.net/read/145998/67497399.html”)),运行程序,点击按钮,程序停在断点处,在查看context内容,发现已经获取到所有的章节文本了。
3.下一个章节的链接:
在该html文本中发现如下内容:

根据之前的思路分析,可以知道寻找到tag是"a"并且属性是id值是next_url的地方就是链接所在的位置,但这里有个不一样的地方就是这里的链接是放在属性里面的,所以需要获取第二个属性是href的值,通过下面的代码可以获取到“/read/145998/67497399_2.html”这个值,再观察整个网页的链接“http://www.ibookben.net/read/145998/67497399.html”发现其实下一章的链接地址就是最后的斜杠后面的内容不一样,这样就可以通过字符串的拼接得到下一章节的地址了。
string get_next_page_url(string html)
{
string url = "";
//根据html创建解析器
Parser parser = Parser.CreateParser(html, null);
//在解析器中添加过滤的内容:tag是"a"并且有个属性是id值为next_url
NodeList nodeList = parser.Parse(new AndFilter(new TagNameFilter("a"), new HasAttributeFilter("id", "next_url")));
//获取这个节点的另一个属性是href的值并且跟网站网址的前半段拼接成完整的网址
url = "http://www.ibookben.net" + (nodeList[0] as ITag).GetAttribute("href");
return url;
}
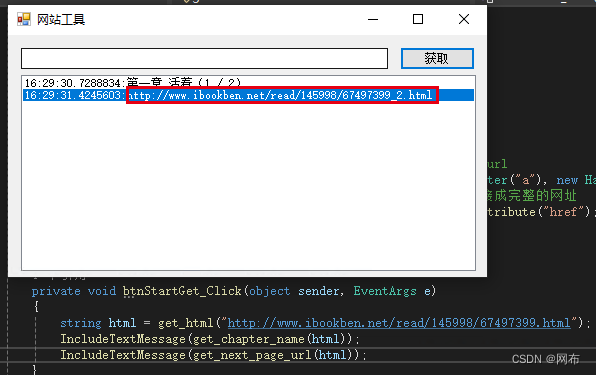
通过添加测试代码,可以正确获取到下一章节的地址
4.寻找结束的方式
最后要做的就是怎么才能判断已经获取到最后一章了,可以在网站上选择最后一章并且获取到html文本内容,观察html的内容发现在最后一页会出现”没有了“这个字眼:

在这个里面发现,最后如果结束了,在next_url的属性里面的href属性会有个链接,通过对比这个链接跟之前书页的链接发现,如果后续没有章节了,这里就会只到书目录那个位置,最后一个斜杠后面的就没有了,可以通过这个判断是否抓取结束。举个例子:该书的正常章节的链接是:“http://www.ibookben.net/read/145998/67497399.html”,最后结束的时候的next_url的链接就是:“http://www.ibookben.net/read/145998.html”,即少了最后的斜杠后面的内容。
修改之前函数get_next_page_url判断是否抓取完成:
string get_next_page_url(string html)
{
string url = "";
//根据html创建解析器
Parser parser = Parser.CreateParser(html, null);
//在解析器中添加过滤的内容:tag是"a"并且有个属性是id值为next_url
NodeList nodeList = parser.Parse(new AndFilter(new TagNameFilter("a"), new HasAttributeFilter("id", "next_url")));
//获取这个节点的另一个属性是href的值并且跟网站网址的前半段拼接成完整的网址
url = "http://www.ibookben.net" + (nodeList[0] as ITag).GetAttribute("href");
//判断是不是获取到了最后一个内容,这里如果比正常的链接少一个就表示结束了
if(url.Split('/').Length < 6)
{
url = "";
}
return url;
}
4.编写流程相关代码
1.在按钮事件中增加代码
private void btnStartGet_Click(object sender, EventArgs e)
{
//判断输入的起始章节地址是否正确
if(txbURL.Text.Contains("http://www.ibookben.net/read/")==false)
{
MessageBox.Show("非法链接,请重新输入");
return;
}
if(txbURL.Text.Split('/').Length!=6)
{
MessageBox.Show("请输入起始章节的链接");
return;
}
//新建线程操作抓取内容
System.Threading.Thread thread;
thread = new System.Threading.Thread(Receive_Thread);
thread.IsBackground = true;
thread.Start(txbURL.Text);
}
在线程中循环执行抓取操作:
private void Receive_Thread(object url)
{
string next_url = (string)url;
string chapter_name = "";
string content = "";
string html = "";
while (true)
{
//获取html内容
html = get_html(next_url);
//获取章节标题用于打印输出查看状态
chapter_name = get_chapter_name(html);
IncludeTextMessage(chapter_name);
//获取内容
content = chapter_name + get_context(html);
//保存章节题目以及内容,以追加的方式
System.IO.File.AppendAllText("./"+ ((string)url).Split('/')[4] + ".txt", content);
//获取下一章节链接,并判断是否结束
next_url = get_next_page_url(html);
//判断章节内容是否结束
if (next_url == "")
{
IncludeTextMessage("结束了");
break;
}
}
}
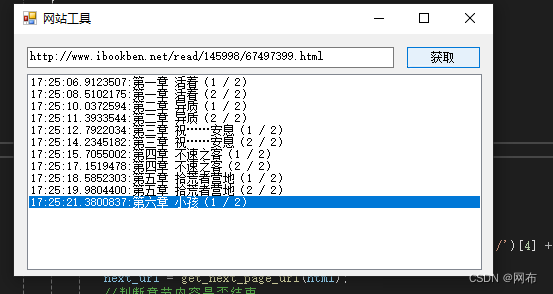
运行程序,输入链接地址,可以正常执行
总结
程序还有很多需要优化的地方,文章目的只是一个c#编程的练习,起到抛砖引玉的作用。后续有更多的想法可以在这个程序的基础上实施。比如将书名,作者提取出来等,希望大家自己发掘。
最后附上源代码链接给有需要的:https://download.csdn.net/download/wangbuu/89124831
延申
将生成的txt文档通过EasyPub应用程序转成epub格式的可以提取目录方便阅读