MapReduce 是一种编程模型,用于处理和生成大数据集。MapReduce 分为两个阶段:Map 阶段和 Reduce 阶段。
Map 阶段:在这个阶段,输入数据被拆分成不同的数据块,这些数据块被分发到各个 Map 任务上。每个 Map 任务对输入的数据块进行处理并输出成一组键值对。具体的处理方式取决于编写 Map 任务的方式,这将由程序员决定。
Shuffle 阶段:在 Map 阶段之后,系统会根据 Map 阶段输出的键值对进行排序和分区。这个过程是系统自动完成的,不需要程序员编写代码。
Reduce 阶段:在这个阶段,一组键值对会送到同一个 Reduce 任务上。Reduce 任务会对这些键值对按照键来进行合并,并对每个键的所有值进行处理,输出处理结果。具体的处理方式也是由程序员编写的 Reduce 任务来决定。
通过 Map 和 Reduce 两个步骤,MapReduce 能够将大规模的数据计算工作分解成小规模的计算任务,这些小规模的计算任务可以在不同的计算节点上并行处理。这使得 MapReduce 可以处理非常大规模的数据。
例如,一个简单的MapReduce程序可能会将文本文件分成单词(map),然后计算每个单词的出现次数(reduce)。在这种情况下,Map任务将文本文件切分为单词,并输出每个单词的键值对(键是单词,值是1),然后Reduce任务将这些键值对按照键(单词)合并,并计算每个键(单词)的值(出现次数)的总和。
在真实的环境中,这个模型通常由分布式计算框架(如 Hadoop)来实现,框架会负责任务的调度、数据的分布和容错等工作,使得程序员可以专注于编写处理数据的 Map 和 Reduce 函数。
上demo:
// 导入 IOException 类,用于处理输入/输出错误
import java.io.IOException;
// 导入 StringTokenizer 类,用于解析字符串
import java.util.StringTokenizer;
// 导入 Hadoop 提供的 Configuration 类,用于 Hadoop 配置设置
import org.apache.hadoop.conf.Configuration;
// 导入 Hadoop 提供的 Path 类,处理 Hadoop 文件系统路径
import org.apache.hadoop.fs.Path;
// 导入 Hadoop 提供的 IntWritable 和 Text 类,数据类型转换
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
// 导入 Hadoop MapReduce Job 类,用于定义和提交 MapReduce 任务
import org.apache.hadoop.mapreduce.Job;
// 从 Hadoop MapReduce 库导入 Mapper 和 Reducer 类
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
// 导入 Hadoop IO 类库,用于 MapReduce 输入输出
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
// 定义 WordCount 类
public class WordCount {
// 定义公开的静态 TokenizerMapper 类,继承 Hadoop 的 Mapper 类
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
// 定义一个值为 1 的整型变量,作为每个单词计数的值
private final static IntWritable one = new IntWritable(1);
// 定义一个 Text 类型的变量,存储每个即将被计数的单词
private Text word = new Text();
// 重写 map 方法,这个方法会被 MapReduce 框架调用,每读入一行数据调用一次
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 使用 StringTokenizer 将每行的字符串拆解为单个的单词
StringTokenizer itr = new StringTokenizer(value.toString());
// 循环单词字符串
while (itr.hasMoreTokens()) {
// 为 word 对象设值
word.set(itr.nextToken());
// 将每个单词及其数量(默认为 1)输出
context.write(word, one);
}
}
}
// 定义公开的静态 IntSumReducer 类,继承 Hadoop 的 Reducer 类
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
// 定义 IntWritable 类型的对象,存储每个单词的计数总和
private IntWritable result = new IntWritable();
// 重写 reduce 方法,这个方法用于汇总每个单词的数量
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 定义 sum 变量,用于累加每个单词的数量
int sum = 0;
// 使用 for 循环,遍历当前单词的所有数量值,进行累加
for (IntWritable val : values) {
sum += val.get();
}
// 为结果设值
result.set(sum);
// 将每个单词及其最终计数总和写出
context.write(key, result);
}
}
// 定义主方法,运行 MapReduce 任务的入口
public static void main(String[] args) throws Exception {
// 创建 Hadoop 配置对象
Configuration conf = new Configuration();
// 创建 Job 实例,设置 Job 名称
Job job = Job.getInstance(conf, "word count");
// 设置 Jar 文件 这行代码的作用是设置该作业的 jar 文件。在 Hadoop 中执行一个 MapReduce 作业,需要将其打包为一个 jar 文件并上传到 Hadoop 集群中。这里的 WordCount.class 即是你的作业驱动类, Hadoop 将会通过这个类查找包含该类的 jar 文件,然后使用这个 jar 文件执行整个作业。这样设置可以确保作业在 Hadoop 集群中的每个节点上都可以正确执行。
job.setJarByClass(WordCount.class);
// 设置 Mapper 类 这行代码的作用是设置 MapReduce 作业的 Mapper 类。在 MapReduce 模型中,Mapper 是负责处理输入数据,将输入数据转换为一系列键值对的组件。TokenizerMapper.class 就是你写的处理数据的类,你可以在这个类中定义如何处理和映射输入数据。设置 Mapper 类是进行 MapReduce 作业的关键步骤之一。
job.setMapperClass(TokenizerMapper.class);
// 设置 Combiner 类 当一个特定的 Mapper 结束处理之后,它会输出很多记录,这些记录中可能有很多键是相同的。如果没有 Combiner,这些记录就会直接传递给 Reducer,这样可能会产生大量的网络 I/O,显著地影响性能。
//而有了 Combiner,我们可以在每个 Mapper 所在的节点上先进行一次局部的归约操作,将相同键的值合并后再传输到 Reducer,这样可以大大减少需要传输的数据量,提高任务的运行性能。
job.setCombinerClass(IntSumReducer.class);
// 设置 Reducer 类及其输出键-值对的类型
// 这行代码是设定了该 MapReduce 任务的 Reducer 类是 IntSumReducer。Reducer 类是对所有 Mapper 的输出进行汇总的部分,每一个 MapReduce 任务都需要设定一个 Reducer 类。这里的 IntSumReducer 类定义了如何对数据进行汇总操作。
job.setReducerClass(IntSumReducer.class);
//这行代码是设定了该 MapReduce 任务输出数据的键的类型是 Text。在 MapReduce 中,数据是以键值对的形式存储和传输的。这行代码指明了输出键的数据类型,确保处理结果的格式正确。
job.setOutputKeyClass(Text.class);
//这行代码是设定了该 MapReduce 任务输出数据的值的类型是 IntWritable。这是对job.setOutputKeyClass(Text.class)的补充,指明了输出值的数据类型。
job.setOutputValueClass(IntWritable.class);
// 设置输入数据的路径,取自程序参数
FileInputFormat.addInputPath(job, new Path(args[0]));
// 设置输出数据的路径,取自程序参数
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 等待任务完成后退出程序 这行代码是 MapReduce 任务的最后一步,作用是让主线程等待这个 MapReduce 任务完成。
//在这段代码中,waitForCompletion方法将主线程挂起,直到 MapReduce 任务完成为止。这里的参数 true 表示会在控制台上显示这个任务的进度,也就是说你运行这个程序的时候,会在控制台上看到任务的完成进度。
//这段代码的含义就是:如果任务成功完成,那么程序正常退出;如果任务执行过程中出现了错误,那么程序异常退出。
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
/**
MapReduce 模型的并发性体现在其 Map 和 Reduce 操作的实现中,这两个操作对数据进行分布式处理。在以上代码片段中,没有一行明确地标示了并发操作,因为并发性质是 MapReduce 框架内部管理的,并非是在业务代码中直接表现出来的。
然而,job.setMapperClass(TokenizerMapper.class); 和 job.setReducerClass(IntSumReducer.class);
这两行设置了 Mapper 类和 Reducer 类,这两类的实例在运行时会在多个节点上同时处理数据(一个节点处理输入数据的一部分),这便是 MapReduce 的并发性!!!
具体来说:
在 Mapper 阶段,输入的数据集会被划分成多个数据块,每一个数据块会被一个 Mapper 实例负责处理,这些 Mapper 实例是在集群的各个计算节点上同时运行的。
Reducer 阶段同样具有并发性,不同的 Reducer 实例会并发地处理 Mapper 输出的数据集中具有相同键的数据子集。
请注意,这些并发处理是由 Hadoop 框架自动管理的,并不需要在业务代码中明确地进行并发控制,这也是使用这种大数据处理框架的优点之一。
*/这个程序把一个任务分为两个部分:
- Mapper (TokenizerMapper class):接受一行文本,拆分成单词,然后返回一系列的<单词,1>这样的键值对。
- Reducer (IntSumReducer class):对所有相同的单词计数总和,并返回<单词,总计数>这样的键值对。
执行这个程序,需要有一个 Hadoop 环境并且把待统计名词的文本文件放到应当的路径,并将结果输出的路径设置为期望的路径进行查看结果。
请注意,这些并发处理是由 Hadoop 框架自动管理的,并不需要在业务代码中明确地进行并发控制,这也是使用这种大数据处理框架的优点之一。
"Hadoop 框架自动管理" 的主要体现在哪些方便?
数据划分和任务分派:在 Map 阶段,Hadoop 按照一定的规则(默认为按文件大小)将输入数据划分成多个块(block),并为每个数据块创建一个 Map 任务,然后分派到集群的多个节点上并行执行。这个过程是 Hadoop 框架自动完成的,用户无需在代码中做任何处理。
任务调度和监控:Hadoop 采用 master-slave 架构,其中 master 节点(即 JobTracker)负责管理和调度整个集群,slave 节点(即 TaskTracker)负责执行具体的任务。JobTracker 根据集群的资源情况和任务需求,智能调度任务到各个 TaskTracker 执行,并实时监控任务的执行状态,一旦某个任务失败,会自动重新调度该任务到其他节点执行。
数据局部性优化:在划分数据和分派任务时,Hadoop 尽可能将数据存放在本地,或者距离执行任务的计算节点较近的其他节点上,以提高数据读取速度,减少网络传输开销,这称为数据局部性优化。
容错处理:如果在执行过程中某个节点出现故障,Hadoop 可以自动将该节点上的任务重新分派到其他正常的节点上执行,用户无需人工干预,这就是 Hadoop 的高容错性。
以上这些都是 Hadoop 框架自动进行的管理操作,用户只需要关注业务逻辑的编写,无需在代码中处理这些底层的细节问题。这就是 Hadoop 框架的强大之处,能够帮助用户简化分布式计算的复杂性,大大提高开发效率。
MapReduce模型的体系结构:
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
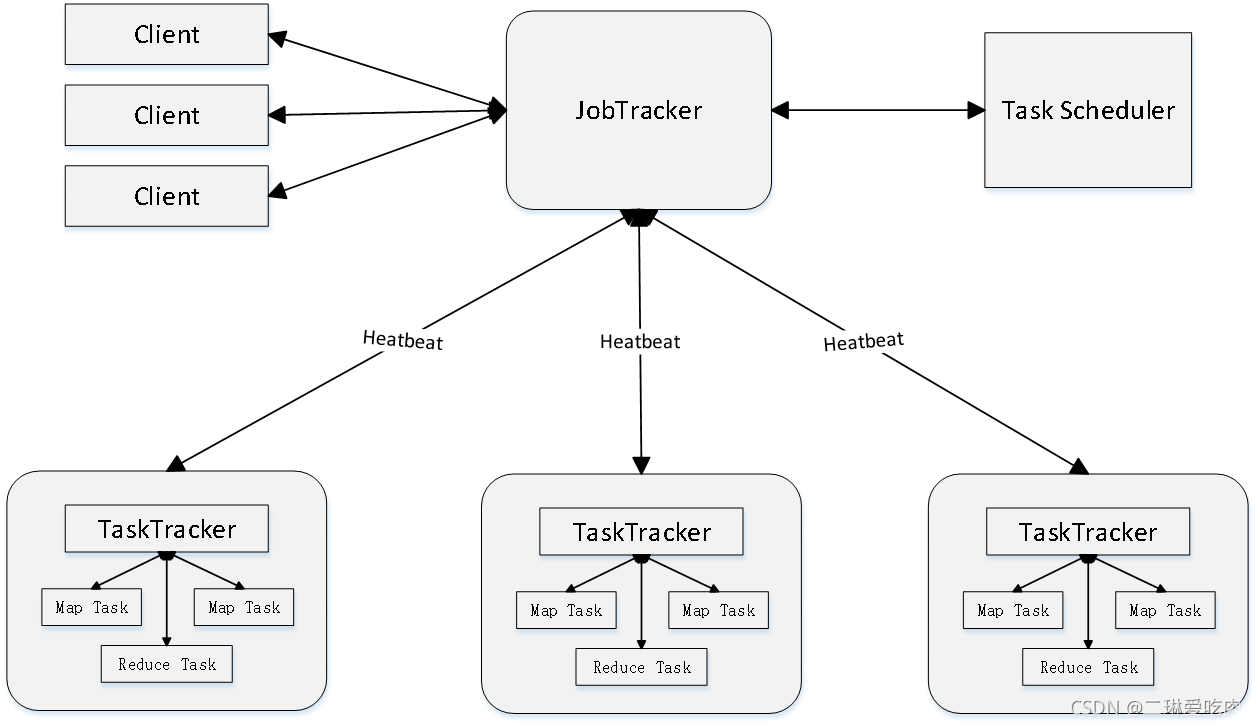
Client:Client 是用户交互的入口,用户编写的MapReduce程序通过Client提交到JobTracker。同时,用户也可以通过Client提供接口查看作业运行状态。
JobTracker:JobTracker 是集群的管理者,负责资源监控和作业调度。它监控TaskTracker与Job的状态,如有节点失败,将会将任务转移至其他节点。同时,JobTracker跟踪任务的执行进度、资源使用量等信息,并将这些信息提供给任务调度器(TaskScheduler),该调度器在资源出现空闲时选择合适的任务去使用这些资源。
TaskTracker:TaskTracker 是具体任务执行的工作节点,它会周期性地通过心跳信号将本节点上的资源使用情况和任务的运行进度汇报给JobTracker。任务调度器根据这些信息为任务分配资源。TaskTracker还会执行JobTracker发送的命令(如启动新任务、杀死任务等)。它使用“slot”对本节点上的资源进行划分(CPU、内存等)。一个Task 获取到一个slot 后才有机会运行。
Task:Task 是具体的执行单位,它们分为Map Task和Reduce Task两种,由TaskTracker启动。这两种任务分别处理Map和Reduce操作。
MapReduce模型的总体过程可以概括为:首先由Client提交作业,然后由JobTracker接收并管理这个作业,作业被分解为多个Task,然后由TaskTracker在各计算节点上执行这些任务。这就是MapReduce体系结构的工作方式。
![[ICCV2023]RenderIH:<span style='color:red;'>用于</span>3D交互手部姿态估计<span style='color:red;'>的</span><span style='color:red;'>大规模</span>合成<span style='color:red;'>数据</span><span style='color:red;'>集</span>](https://img-blog.csdnimg.cn/direct/fe3f20dcd8044da6a6939752efd1849e.png)