目录
本文所有图片均来自25王道考研数据结构。
一、串的概念
1.1 串的定义
串:即字符串(string)是由另个或多个字符组成的有限序列。
子串:串中任意个连续的字符组成的子序列。(空串也可以是子序列)
主串:包含子串的串。
字符在主串中的位置:字符在串中的序号。(编号从1开始,和位序相同,空格也算作一个字符,没有特殊说明的话一般是指该字符第一次出现的位置)
子串在主串中的位置:子串的第一个字符在主串中的位置。
空串和空格串是不同的,空串是:M='',两个单引号之间什么也没有;空格串是指:N=' ',两个单引号里面有一些空格,每个空格占1B。
1.2 串与线性表
串是一种特殊的线性表,数据元素之间呈线性关系。
串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等)。
串的基本操作,如增删改查等通常以子串为操作对象;线性表的基本操作通常是对表中某一个元素进行操作。
1.3 串的基本操作
最重要的是后三个,要知道如何实现,后面有代码实现和代码解析。
| 函数名 | 作用 |
|---|---|
| StrAssign(&T,chars) | 赋值操作。把chars赋给串T。 |
| StrCopy(&T,S) | 复制操作。由串S复制得到串T。 |
| StrEmpty(S) | 判空操作。若S为空串,则返回TRUE,否则返回false。 |
| StrLength(S) | 求串长。返回串S的元素个数。 |
| ClearString(&S) | 清空操作。将S清空为空串。 |
| DestroyString(&S) | 销毁串。将串S销毁,即回收存储空间。 |
| Concat(&T,S1,S2) | 串联接。用T返回S1和S2链接而成的新串。 |
| SubString(*Sub,S,pos,len) | 求子串。用Sub返回串S的第pos个字符起,长度为len的子串。 |
| Index(S,T) | 定位操作。若主串S中存在于串T值相同的子串,则返回它在主串S中第一次出现的位置;否则返回0. |
| StrCompare(S,T) | 比较操作。若S>T,返回值>0;若S=T,返回值=0;若S<T,返回值<0。 |
如何比较字符串的大小:
对于两个字符串,从第一个字符开始往后依次对比,先出现更大字符的字符串的值就更大。比如正序版英文单词书;
长串的前缀与短串相同时,长串更大。
二、串的存储结构
2.1 顺序存储
2.1.1 实现
//相当于静态数组
typedef struct {
char ch[MaxSize]; //每个分量存储一个字符
int length; //串的实际长度
}SString;
//相当于动态数组
typedef struct {
char* ch; //按串长分配存储区,ch指向串的基地址
int length; //串的长度
}HString;
void test() {
HString S;
S.ch = (char*)malloc(sizeof(char) * MaxSize); //申请内存空间
S.length = 0; //长度初始化为0
}顺序存储有两种方式,一种是静态数组,长度不可变,缺点很明显,就是长度固定。还有一种是动态数组,长度可变,每次调用结束之后要手动free释放内存空间。
2.2.2 顺序存储的存储方案
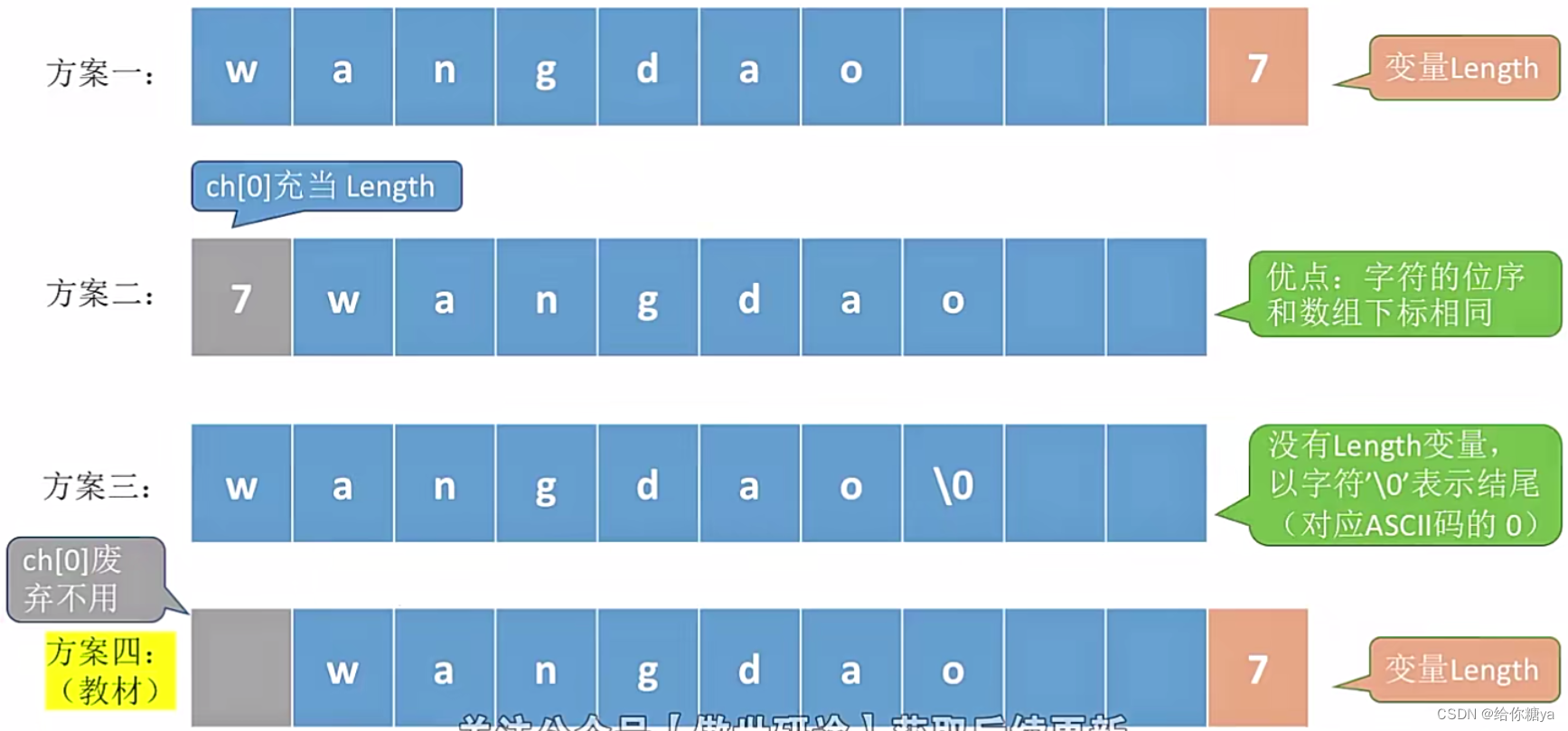
第一种方案就是最普通的,在末尾用一块存储空间存储数组长度length;
第二种方案是将ch的第一块内存空间用来充当length,优点是字符的位序和数组下标相同,缺点是length只能是0-255的数字,因为char类型数组一块内存空间只有1B,即8个bit位,只能存储0-255的范围。
第三种方案是在字符串末尾加一个'\0',没有length变量,缺点很明显,就是不能很方便地得到数组长度,需要从头遍历。
第四种方案是将ch[0]废弃不用,在末尾专门用一块内存存储数组长度。结合了第一二种方案的优点。之后默认使用这种。
2.2 链式存储
//链式存储
//方法1
typedef struct StringNode {
char ch;
struct StringNode* next;
}StringNode, * String;
//方法2
typedef struct StringNode {
char ch[4];
struct StringNode* next;
}StringNode, * String;方法1:在链式存储中,由于每个字符占1B,而每个StringNode指针类型占4B,所以就造成每个结点的有用数据(字符数据)太少,即存储密度低。
方法2:可以让每个结点存储的数据多一些,比如一个节点存储4个字节,就可以有效改进上述问题。另外注意,当存储的字符串最后一个结点不足4个字符时,剩余位置可以用一些特殊字符(如'#','$'等)代替。
链式存储优点是可以很方便地插入、删除,缺点是不能随机存取。
2.3 基本操作的实现
2.3.1 求子串
用Sub返回串S的第pos个字符起,长度为len的子串。
//求子串
bool SubString(SString& Sub, SString S, int pos, int len) {
//子串范围越界
if (pos + len - 1 > S.length)
return false;
for (int i = pos; i < pos + len; i++)
Sub.ch[i - pos + 1] = S.ch[i];
Sub.length = len;
return true;
}代码解析:
先判断第pos个字符后有没有len个字符,如果不够的话就说明越界了,返回false;
然后依次遍历pos~pos+len,将S中的字符赋给Sub,注意Sub的访问下标从1开始;
最后修改Sub的长度即可。
2.3.2 比较操作
若S>T,返回值>0;若S=T,返回值=0;若S<T,返回值<0。
//比较操作
int StrCompare(SString S, SString T) {
for (int i = 0; i <= S.length && i <= T.length; i++) {
if (S.ch[i] != T.ch[i])
return S.ch[i] - T.ch[i];
}
//扫描过的字符都相同,则长度长的串更大
return S.length - T.length;
}代码解析:
同时从头开始遍历 S和T 两个串,当遍历到某个字符两者不相等的时候,就返回两个字符相减的结果,这和两个串的大小是对应的,若在下标为 i 处的字符 S 比 T 的更大,则串 S 比串 T 更大。
如果扫描过的字符都相同,那么长度长的串更大,返回两者长度的差值。
2.3.3 定位操作
若主串S中存在于串T值相同的子串,则返回它在主串S中第一次出现的位置;否则返回0.
//定位操作
int Index(SString S, SString T) {
int i = 1, n = StrLength(S), m = StrLength(T);
SString sub;
while (i <= n - m + 1) {
SubString(sub, S, i, m); //取出从位置i开始长度为m的子串
if (StrCompare(sub, T) != 0) //子串和模式串对比,若不匹配,则匹配下一个子串
++i;
else
return i;
}
return 0;
}
代码解析:
用到了前面提到的比较操作 StrCompare 。先用 n 和 m 保存主串S和串T的长度。整体思路是依次从主串 S 中取 m 个字符,让这 m 个字符与串 T 进行比较,如果相同就返回 i 值(i 是取出来的 m 个字符的第一个字符的下标),如果不同就让 i++ 继续取 m 个字符比较。最后如果没有相同的 m 个字符,就返回 0。最多匹配 n-m+1 次就能得出结果。
三、串的模式匹配
定义:字符串模式匹配,就是在主串中找到与模式串相同的子串,并返回其所在位置。
在408考试中需要掌握两种模式匹配算法:朴素模式匹配算法 和 KMP算法。
子串:是主串的一部分,一定存在;
模式串:不一定能在主串中找到。
3.1 朴素模式匹配算法
思想:暴力解法。将主串中所有长度为 m 的子串依次与模式串进行对比,直到找到一个完全匹配的子串,或所有的子串都不匹配为止。相当于 2.3 中讲的 Index 函数的思想。
若主串长度为 n ,模式串长度为 m ,那么最多会匹配 n-m+1 次。
算法思想:
设两个指针i,j代表数组下标,分别代表主串S和模式串T的数组下标,从头开始同时遍历两个串。
若当前子串匹配失败,则主串指针 i 指向下一个子串的第一个位置,模式串指针 j 回到模式串的第一个位置。这里的变换是这样的:i=i-j+2,j=1。对于第一个式子, j表示当前匹配到了模式串的第几个字符,i-j 就指向了匹配字符串的前一个字符,而我们要指向下一个子串的第一个位置,就再 +2 。
若 j>T.length,则当前子串匹配成功,返回当前子串第一个字符的位置,即 i - T.length。
//朴素模式匹配算法
int Index(SString S, SString T) {
int i = 1, j = 1;
while (i <= S.length && j <= T.length) {
if (S.ch[i] == T.ch[j]) { //继续比较后续字符
i++;
j++;
}
else { //匹配失败,指针后退再次比较
i = i - j + 2;
j = 1;
}
}
if (j > T.length) //匹配成功
return i - T.length;
else
return 0;
}时间复杂度:若主串和模式串长度分别为n,m,则时间复杂度为O(mn)。
3.2 KMP算法
KMP算法在考研中的地位和难度:KMP算法是考研过程中难度排前三的算法,但考研并不要求掌握代码怎么写,考研要求掌握手推 next 数组和 nextval 数组,手动模拟 KMP 算法的执行过程,大多以选择题形式考察,代码题考察的概率不大。在考研大纲中,串这一章不算是一个重点,当然KMP也不是一个重点,但确实是一个难点,大家不用花费很大精力在KMP算法上面,只需要会手推两个数组即可。
KMP 算法主要分为两步:求 next 数组和匹配字符串。
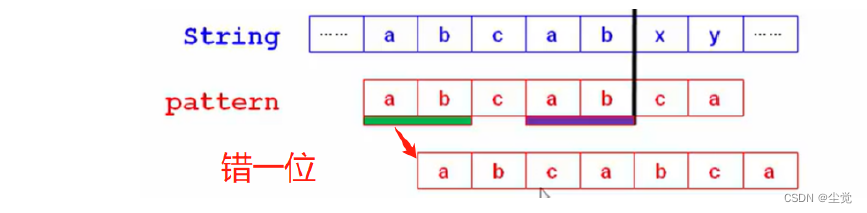
KMP 算法每次在失配时,不是把模式串T往后移动一位,而是把模式串T往后移动至下一次可以和前面部分匹配的位置,这样就可以跳过大多数的失配步骤。而每次模式串T移动的步数就是通过查找next[ ]数组确定的。
3.2.1 next数组
如何求next数组?
假设主串S是未知的,S和T的数组下标都从1开始。假设匹配到模式串T的第i个位置时匹配失败(i要把T的所有可能取值都取一遍,比如T有6个字符,i就要取1-6),此时S的前 i-1 个元素是已知的,我们要做的就是S不动,将T逐个后移,直到T前面露出来的部分与S完全匹配时为止(这句话不理解的就看下面的例子,一定会懂的),然后将 j 指向的元素修改为 i 对应元素下面的那个元素,修改 j 的下标为这个元素的下标;然后设置 next[i] = j 。下面是详细过程:
主串S:?????????????????
模式串T:abaabc===============================第1步:
当第6个字符匹配失败时:
此时S的前五个字符是已知的,即
i
S:a b a a b ? ?
T:a b a a b c
j
那么开始移动T,直到如下情况:
i
S:a b a a b ? ?
T: a b a a b c
j
此时将j修改为3,即“将j指向的元素修改为i对应元素下面的那个元素,修改j的下标为这个元素的下标”,设置next[6]=3,表明当第6个字符匹配失败时,将j修改为3。===============================第2步:
当第5个字符匹配失败时:
此时S的前4个字符是已知的,即
i
S:a b a a ? ? ?
T:a b a a b c
j
开始移动T,直到如下情况:
i
S:a b a a ? ? ?
T: a b a a b c
j
此时将j修改为2,设置next[5]=2,表明当第5个字符匹配失败时,将j修改为2===============================第3步:
当第4个字符匹配失败时:
此时S的前3个字符是已知的,即
i
S:a b a ? ? ? ?
T:a b a a b c
j
开始移动T,直到如下情况:
i
S:a b a ? ? ? ?
T: a b a a b c
j
此时将j修改为2,设置next[4]=2,表明当第4个字符匹配失败时,将j修改为2===============================第4步:
当第3个字符匹配失败时:
此时S的前2个字符是已知的,即
i
S:a b ? ? ? ? ?
T:a b a a b c
j
开始移动T,直到如下情况:
i
S:a b ? ? ? ? ?
T: a b a a b c
j
此时将j修改为1,设置next[3]=1,表明当第3个字符匹配失败时,将j修改为1===============================第5步:
当第2个字符匹配失败时:
此时S的前1个字符是已知的,即
i
S:a ? ? ? ? ? ?
T:a b a a b c
j
开始移动T,直到如下情况:
i
S:a ? ? ? ? ? ?
T: a b a a b c
j
此时将j修改为1,设置next[2]=1,表明当第2个字符匹配失败时,将j修改为1===============================第6步:
当第1个字符匹配失败时:
此时S全都是未知的,即
i
S:? ? ? ? ? ? ?
T:a b a a b c
j
开始移动T,直到如下情况:
i
S:? ? ? ? ? ? ?
T: a b a a b c
j
这时会发现j的位置已经不合法了,为了和前面的步骤保持一致,即前面都是令i不变,j等于某个值,这里令j=0,然后i++,j++。
此时将j修改为0,设置next[1]=0,表明当第1个字符匹配失败时,将j修改为0于是我们就得到了一个所谓的next数组:
next[1]=0
next[2]=1
next[3]=1
next[4]=2
next[5]=2
next[6]=3
这时如果有个例题的主串S:abaabaabcabaabc,模式串T:abaabc,用KMP算法进行模式匹配,效率会大大提高。
===============================第1步:
i
S:a b a a b a a b c a b a a b c
T:a b a a b c
j
当匹配到第6个字符时匹配失败,根据next数组,此时令j=3,即变为如下情况:
===============================第2步:
i
S:a b a a b a a b c a b a a b c
T: a b a a b c
j
此时再将i,j依次向后遍历比较,就减少了比较次数,提高了效率,匹配成功。
现在,再回头看上述文本框前面的那段话,是否有新的理解?另外,要注意几点:
next[1]=0。无论是哪个模式串,只要第一个字符不匹配,都要将 j 设置为0,然后让 i++,j++。切记不是 next[1]=1。
next[1]=0,next[2]=1。这两个恒成立(前提是串的下标从1开始)
next数组的值和模式串T有关,和主串S无关;
KMP算法高效的原因在于,主串的指针 i 不回溯;
KMP算法时间复杂度:O(m+n)
3.2.2 模式匹配
下面是KMP的实现代码:
这个代码没有管next数组是怎么实现的,代码比较简单,不做讲解,看着注释应该可以理解。
int Index_KMP(SString S, SString T, int next[]) {
int i = 1, j = 1; //两个串数组下标为1,这里也设置指针从1开始
while (i <= S.length && j <= T.length) {
if (j == 0 || S.ch[i] == T.ch[j]) { //j=0的特殊处理
++i;
++j; //继续比较后面的字符
}
else
j = next[j]; //模式串向右移动,移动位数和next数组存储的数据有关
}
if (j > T.length)
return i - T.length; //匹配成功
else
return 0;
}
3.2.3 nextval数组
nextval数组是next数组的优化。至于为什么我们又需要一个nextval数组,我们看一个例子:
依然用3.2.1小节中示例里面的模式串T,他的next数组我们是知道的。
模式串T:a b a a b c
next[1]=0
next[2]=1
next[3]=1
next[4]=2
next[5]=2
next[6]=3====================================1.
若第3个字符不匹配,即如下情况:
i
S:a b ? ? ? ? ?
T:a b a a b c
j
此时按照next数组,需要令j=1,即如下情况:
i
S:a b ? ? ? ? ?
T: a b a a b c
j
但我们根据第一步,虽然不知道S[3]具体是什么,但可以肯定的是S[3]!='a',而依照next数组,我们接下来需要比较T[1]和S[3],我们也知道T[1]='a',所以这一次比较是注定失败的,就浪费了可以避免浪费的时间。====================================2.
同样,若第5个字符不匹配,即如下情况:
i
S:a b a a ? ? ?
T:a b a a b c
j
此时按照next数组,需要令j=2,即如下情况:
i
S:a b a a ? ? ?
T: a b a a b c
j
但我们根据上一步,可以肯定的是S[5]!='b',而依照next数组,我们接下来需要比较的T[2]一定不等于S[5],这一次比较注定是失败的,就浪费了时间。由上面这两个例子可以看出,next数组虽然好,但还不够好,它仍然存在一些多余的比较,这些多余的比较出现在如下情况:即当指针i,j扫描的当前位置不匹配时,T[j]==T[next[j]]。这个时候,我们就需要优化next数组。
那么我们需要如何得到nextval数组呢?
由上段分析我们知道,当指针i,j扫描的当前位置不匹配 且 T[j]==T[next[j]]时,T[j]一定和S[i]不匹配,而T[next[j]]也一定不匹配,所以我们可以直接修改next[j]的值为next[next[j]]。为了区分nextval数组和next数组,将其写为:nextval[j]=nextval[next[j]],而这行代码的执行条件为“T[j]==T[next[j]]”
于是我们可以得到如下的计算nextval数组的手推过程:
nextval[1] = 0;
for (int j = 2; j <= T.length; j++) {
if (T.ch[next[j]] == T.ch[j])
nextval[j] = nextval[next[j]];
else
nextval[j] = next[j];
}另外,要注意几点:
nextval[1]=0 恒成立(前提是串的下标从1开始)
修改nextval的语句为:nextval[j]=nextval[next[j]],执行条件为:T[j]==T[next[j]]。不一定要记住,会手推即可。
给出一个例题以供练习:
Q: 模式串T:ababaa,求其next数组和nextval数组。
A: next数组为 0 1 1 2 3 4
nextval数组为 0 1 0 1 0 4