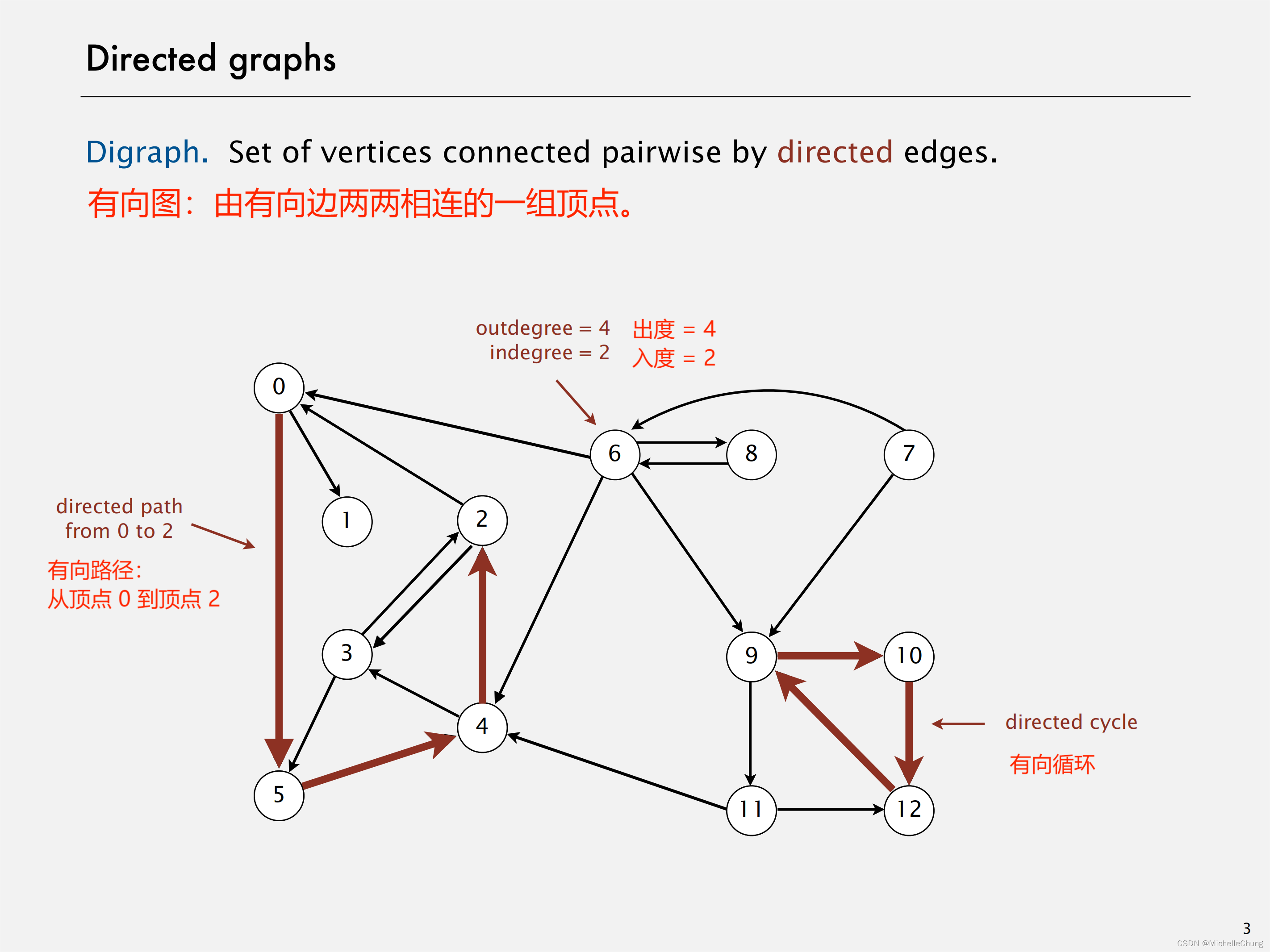
哈希桶实现哈希表
逻辑是指针数组存放链表的头节点;可以用vector<list>但是没必要任意位置插入,在哪里插入都一样,还会多prev指针,哨兵位的头节点,而且实现迭代器就会形成复合结构;插入要注意使用头插,还需要扩容,否则数据多了效率会下降,所以负载因子可以适当地放大,一般控制在1,意思就是大多数桶的数据个数控制在一个,每次扩容都会使得数据分散,这样平均下来时间复杂度就是O(1);
插入扩容时,要创建新表不需要复用insert直接用vector开空间,遍历旧表挂到新表,置空旧表,交换两个表;为了减少一次扩容太费时间redis使用了平均扩容消耗,即插入那个数据就将哪一个桶挂到新表,但是每次插入的时间就变慢了。使用find检查是否存在,存在就不插入。
删除时,由于子结构时单链表,使用find无法找到上一个节点,所以需要重新来一次查找,节点key值不存在不可以删除,要删除第一个元素,直接将桶位置的节点与第二个元素的节点链接起来,其他情况就是prev和next连接起来;
使用闭散列的开放定址法,成员变量是自定义类型+内置类型,而内置类型自带析构函数无需手动写,但是开散列的哈希桶法,由于vector的变量是节点指针,需要节点类型又是自己设计的,所以哈希表类型需要写析构函数,并且调用delete;
代码实现:
namespace HashBucket
{
template <class K>
struct Default // 仿函数强转为无符号整型
{
size_t operator()(const K &key)
{
return (size_t)key;
}
};
template <>
struct Default<std::string> // 模板的特化处理string字符串类型
{
size_t operator()(const std::string &key)
{
size_t i = 0;
for (const auto &ch : key)
{
i *= 131;
i += ch;
}
return i;
}
};
template <class T>
struct HashNode
{
HashNode(const T &data) : data_(data), next_(nullptr) {}
T data_;
HashNode<T> *next_;
};
template <class K, class T, class KeyOfT, class HashFunc = Default<K>>
class HashTable
{
typedef HashNode<T> node;
public:
HashTable() : size_(0)
{
table_.resize(10, nullptr);
}
~HashTable()
{
for (size_t i = 0; i < table_.size(); i++)
{
node *cur = table_[i];
while (cur)
{
node *next = cur->next_;
delete cur;
cur = next; //*cur被释放,cur->next就是野指针访问,所以需要记录next位置;
}
table_[i] = nullptr;
}
}
bool insert(const T &data)
{
KeyOfT kot;
HashFunc func;
node *cur = find(kot(data));
if (cur)
{
return false;
}
// 扩容
if (size_ == table_.size())
{
size_t newsize = table_.size() * 2;
std::vector<node *> newtable;
newtable.resize(newsize, nullptr);
// 遍历旧表,讲节点挂到新表
for (size_t i = 0; i < table_.size(); i++)
{
node *cur = table_[i];
while (cur)
{
node *next = cur->next_;
size_t hashi = func(kot(cur->data_)) % newsize;
cur->next_ = newtable[hashi];
newtable[hashi] = cur;
cur = cur->next_;
}
table_[i] = nullptr;
}
table_.swap(newtable);
}
size_t hashi = func(kot(data)) % table_.size();
// 头插 访问最新插入的元素较快
node *newnode = new node(data);
newnode->next_ = table_[hashi];
table_[hashi] = newnode;
++size_;
return true;
}
node *find(const K &key)
{
KeyOfT kot;
HashFunc func;
size_t hashi = func(key) % table_.size();
node *cur = table_[hashi];
while (cur)
{
if (kot(cur->data_) == key)
{
return cur;
}
cur = cur->next_;
}
return nullptr;
}
void print()
{
for (size_t i = 0; i < table_.size(); ++i)
{
KeyOfT kot;
printf("[%d] -> ", i);
node *cur = table_[i];
while (cur)
{
std::cout << kot(cur->data_) << " -> ";
cur = cur->next_;
}
if (!cur)
{
std::cout << "nullptr";
}
std::cout << std::endl;
}
std::cout << std::endl;
}
bool erase(const K &key)
{
KeyOfT kot;
HashFunc func;
if (!find(key))
{
return false;
}
size_t hashi = func(key) % table_.size();
node *cur = table_[hashi];
node *prev = cur;
if (kot(cur->data_) == key)
{
table_[hashi] = cur->next_;
delete cur;
return true;
}
else
{
while (cur)
{
if (kot(cur->data_) == key)
{
prev->next_ = cur->next_;
delete cur;
return true;
}
prev = cur;
cur = cur->next_;
}
return false;
}
}
private:
std::vector<node *> table_;
size_t size_; // 记录存储了多少有效数据
};
}


![详解—[C++数据结构]—<span style='color:red;'>哈</span><span style='color:red;'>希</span> <<span style='color:red;'>哈</span><span style='color:red;'>希</span><span style='color:red;'>表</span>&&<span style='color:red;'>哈</span><span style='color:red;'>希</span><span style='color:red;'>桶</span>>](https://img-blog.csdnimg.cn/direct/ce1c8ac6b2ef48f4be66c884135b22ef.png)
































![[R] Underline your idea with ggplot2](https://img-blog.csdnimg.cn/direct/5314ed386de044c09348425c59ec15e3.png)

