参考资料:python统计分析【托马斯】
一、方差分析
1、原理
方差分析的思想是将方差分为组间方差和组内方差,看看这些分布是否符合零假设,即所有组都来自同一分布。区分不同群体的变量通常被称为因素或处理。
作为对比,t检验观察两组的均值,并检查他们是否和两组来自同一个分布的假设一致。
例如,如果我们有一组不进行处理,另一组用处理A,第三组用处理B,对它们进行比较,那么我们就在进行单因素方差分析,有时也称为单向方差分析,其中处理是分析的单因素。注意在方差分析中,在各分析组中有着相同的样本数是很重要的(这被称为平衡方差分析:平衡的设计是指对于所有可能的因素组合都有相同数量的观测值。)
由于无效假设是,组间没有差异,该检验基于观察到的组间变异(即,它们均值之间)和期望的观察到的组内变异(在对象间)的比较。
单因素方差分析假定所有的样本都来自同方差的正态分布总体。同方差的假设可以用Levene检验进行检验。
可参考:excel统计分析——Levene方差齐性检验_excel中方差齐性检验是什么-CSDN博客
方差分析使用了传统的术语。DF表示自由度(degrees of freedom),总和叫做平方和(SS),二者之间的比率叫做均方(MS),并且平方的项都偏离了样本均值。总的来说,样本方差被定义为:
最基本的技术就是将总的平方和SS分割为在模型中使用的相关组分的效应。因此,方差分析估计3中样本方差:基于所有观测偏离总体均值的总方差(SS_T),一个处理方差(SS_t),还有一个基于所有观测值偏离他们合适的处理均值的错误方差(SS_e)。处理方差是基于处理均值偏离总均值,结果被乘以了每个处理组的中的观测数,用于计算观测方差和均值方差之间的差距。这3个平方和的关系如下:
其中,SS_T是偏离总均值的平方和,SS_E是偏离组内均值的平方和,SS_t是每组均值和总均值的偏离平方和。如果无效假设为真,则所有的3个方差估计值是相等。
自由度的个数也可以用类似地方式进行分割:
2、案例
# 导入库
import numpy as np
from scipy import stats
# 写入案例数据
group_1=np.array([32.4,33.2,32.3,31.9])
group_2=np.array([24.7,31.2,25.8,27.5])
group_3=np.array([22.7,21.3,18.4,21.6])
group_4=np.array([23.3,21.1,22.3,21.9])
# 方法1:stats.f_oneway()函数
F,pVal=stats.f_oneway(group_1,group_2,group_3,group_4)
print("F统计量:",F)
print("p值:",pVal)
结果显示:处理间差异极显著。
# 方法2:statsmodels建立模型
# 导入库
import pandas as pd
import statsmodels.formula.api as smf
from statsmodels.stats.anova import anova_lm
# 获取符合要求的dataframe数据格式
df=pd.DataFrame({
"group_1":group_1,
"group_2":group_2,
"group_3":group_3,
"group_4":group_4
})
df=df.melt(var_name="treatment",value_name="value")
# 模型拟合
model=smf.ols('value~C(treatment)',df).fit()
anovaResults=anova_lm(model)
print(anovaResults)
方法一、方法二结果一致。
二、多重比较
单因素方差分析的无效假设是所有样本的均值是相同的。所以如果单因素方差分析分析产生了一个显著的结果,我们只知道他们不是相同的。
但是,我们常常并不只是关心所有的样本是否相同这样的联合假设,我们也想知道等着假设在哪对样本中被拒绝了。这种情况下,我们同时进行多种检验,每一个检验用于一对样本。
这些检验有时被称为事后分析。在实验的设计和分析中,事后分析由下列部分组成,在实验结束后检验数据的在之前没有预设的模式。现在就是这种情况,因为方差分析的无效假设就是组间没有差异。
随之而来的结果就是多重检验问题:由于我们进行了多重比较检验,我们应该补偿一下得到显著结果的风险,尽管我们的无效假设是真的。我们可以通过矫正p值来解决这个问题。
1、Tukey's检验
Tukey's检验,有时被称为Tukey诚实显著差异检验(HSD)方法,在多重检验时控制一类错误,是被一门广泛接受的技术。它基于一个我们还没遇到的一个统计量——学生化范围,常常用变量q表示。学生化范围通过一列数字进行计算:
其中,s是样本标准差。在Tukey HSD方法中,样本x1,x2,...,xn是均值的一组样本,q是基本的检验统计量。它可以在拒绝无效假设(即所有的组来自相同总体,它们的均值相等)后,用来在事后分析中检验哪两组均值有着显著差异。
参考:excel统计分析——Tukey法多重比较_用excel 进行tukey法统计-CSDN博客
excel统计分析——Tukey‘s-b法多重比较_ceres tukey鈥檚 biweight-CSDN博客
2、Bonferroni矫正
Tukey HSD是一个专门用来比较k个样本的所有配对的检验。相反,我们可以在所有的配对上进行t检验,计算p值,并应用一个多重检验问题中的p值矫正方法。最简单同时也是非常保守的方法是将得到的p值除以我们进行检验的次数(Bonferroni矫正)。
尽管多重比较还没有被标准化地包括在python中,我们可以从statsmodels包中获得许多多重比较检验校正。【注:《python统计分析》的出版时间是2018年】
参考:excel统计分析——Sidak、Bonferroni法多重比较_sidak多重比较-CSDN博客
3、Holm矫正
Holm调整,有时也叫作Holm-Bonferroni方法,按照顺序比较最低的p值和随着每次检验都逐渐减小的Ⅰ类错误率。
三、Kruskal-Wallis检验
当我们将两组进行相互比较的时候,如果是正态分布的,我们就用t检验,如果是非正态分布的,就用非参数的Mann-Whitney u检验。对于3组或3组以上的数据比较,如果是正态分布数据就用方差分析,如果是非正态分布的数据,对应的检验是Kruskal-Wallis H检验。当无效假设是真的情况下,Kruskal-Wallis检验的检验统计量服从卡方分布。
参考:excel统计分析——多组数据的秩和检验_多组秩和检验-CSDN博客
案例:
# 导入库
import numpy as np
from scipy import stats
# 录入数据
group_1=np.array([2.23,1.14,2.63,1.00,1.35,2.01,1.64,1.13,1.01,1.70])
group_2=np.array([5.59,0.96,6.96,1.23,1.61,2.94,1.96,3.68,1.54,2.59])
group_3=np.array([4.50,3.92,10.33,8.23,2.07,4.90,6.84,6.42,3.72,6.00])
group_4=np.array([1.35,1.06,0.74,0.96,1.16,2.08,0.69,0.68,0.84,1.34])
group_5=np.array([1.40,1.51,2.49,1.74,1.59,1.36,3.00,4.81,5.21,5.12])
# 多组数据的非参数检验
h,pVal=stats.kruskal(group_1,group_2,group_3,group_4,group_5)
print("H统计量:",h)
print("p值:",pVal)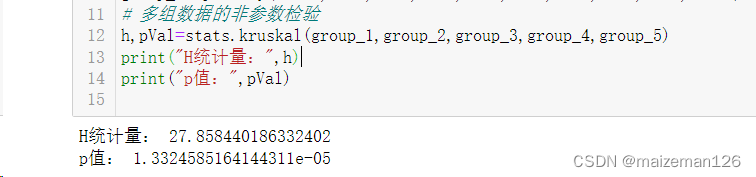
四、两因素方差分析
和单因素方差分析分析相比,用两因素方差分析时,我们不仅要观察每个因素是否显著,也需要检验这些因素的交互因素是否对数据的分布有显著影响。python进行两因素方差分析最好的方法是使用statsmodels。
代码参考如下:
# 导入库
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.formula.api as smf
from statsmodels.stats.anova import anova_lm
# 写入案例数据
data_1=np.array(["A1","A1","A1","A1","A1","A1","A1","A1","A1","A1","A1","A1","A2","A2","A2","A2","A2","A2","A2","A2","A2","A2","A2","A2","A3","A3","A3","A3","A3","A3","A3","A3","A3","A3","A3","A3","A4","A4","A4","A4","A4","A4","A4","A4","A4","A4","A4","A4"])
data_2=np.array(["B1","B1","B1","B2","B2","B2","B3","B3","B3","B4","B4","B4","B1","B1","B1","B2","B2","B2","B3","B3","B3","B4","B4","B4","B1","B1","B1","B2","B2","B2","B3","B3","B3","B4","B4","B4","B1","B1","B1","B2","B2","B2","B3","B3","B3","B4","B4","B4"])
data_3=np.array([22,26.5,24.4,30,27.5,26,32.4,26.5,27,30.5,27,25.1,23.5,25.8,27,33.2,28.5,30.1,38,35.5,33,26.5,24,25,30.5,26.8,25.5,36.5,34,33.5,28,30.5,24.6,20.5,22.5,19.5,34.5,31.4,29.3,29,27.5,28,27.5,26.3,28.5,18.5,20,19])
df=pd.DataFrame({
"factor_A":data_1,
"factor_B":data_2,
"value":data_3
})
# 用交互项确定方差分析
formula="value~C(factor_A)+C(factor_B)+C(factor_A):C(factor_B)"
lm=smf.ols(formula,df).fit()
anovaResults=anova_lm(lm)
# 输出方差分析结果
print(anovaResults)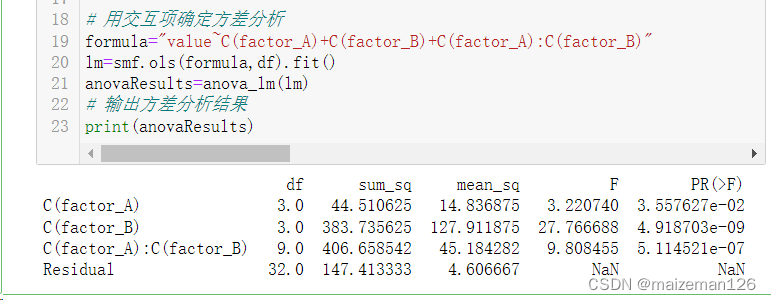
结论:A因素各水平差异显著,B因素各水平差异显著,A因素与B因素间存在显著的交互作用。
五、三因素方差分析
有两个以上的因素时,建议使用统计学建模的方法进行数据分析。当然,正如我们常常分析统计学数据那样,应该首先对数据进行可视化检查。



















![[蓝桥杯 2019 国 B] 解谜游戏](https://img-blog.csdnimg.cn/img_convert/6286eb3d8ec86c3c1caa73b3f602540c.png)