JDK体系结构

Java语言的跨平台特性

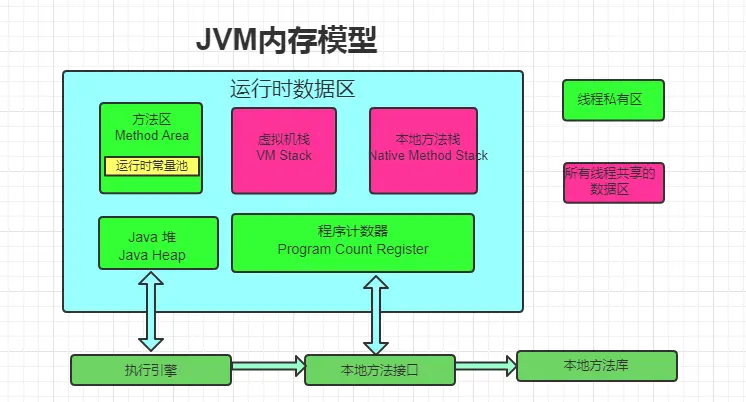
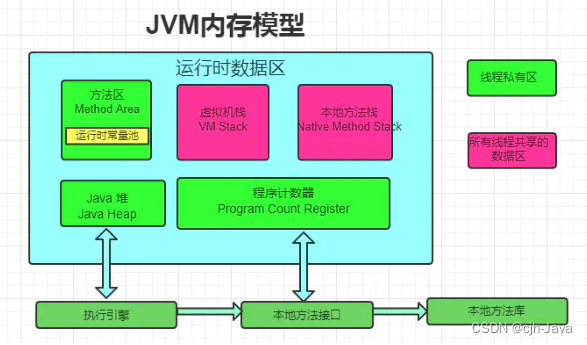
JDK整体结构及内存模型
JVM虚拟机

JVM主要由以下三个部分组成
- 类装载子系统:负责将Java类文件加载到运行时数据区中.并在运行时由类加载器创建Java类对象.
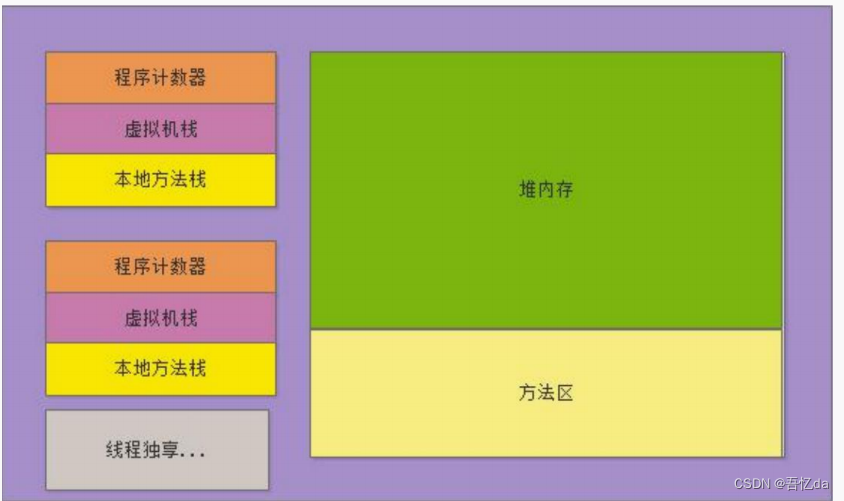
- 运行时数据区:运行时数据区是JVM用于存储数据的内存区域.它包括方法区,堆,栈,本地方法栈和程序计数器等部分.这些区域在JVM的生命周期中用于不同的目的.
- 方法区(共享):方法区是JVM中一块内存区域,用于存储类的结构信息,静态变量,常量,方法字节码等数据.在方法区中,每个类都有一个唯一的类对象,存储了类的结构信息,如字段,方法等.
- 堆(共享):堆是JVM用于存储对象实例的内存区域.所有通过关键字 new 创建的对象都会在堆上分配内存.堆是运行时数据区中最大的一块内存区域.它被所有现成共享,但对象的分配和回收是由垃圾回收器负责的.堆的内存大小可以通过启动参数来配置
- 栈(私有):栈是为每个线程分配的内存区域.用于存储方法调用的局部变量,操作数栈,方法返回值等数据.栈会随着方法的调用和返回动态地伸缩,栈内存的大小也可以通过启动参数来配置.每个方法在执行时都会创建一个栈帧 (FILO,先进后出),栈帧主要包含以下几个部分:
- 局部变量表:局部变量表用于存储方法中的局部变量以及方法参数.局部变量包含基本数据类型和对象的引用
- 操作数栈:操作数栈用于存储方法执行过程中的操作数.Java字节码指令通常将操作数放入操作数栈进行运算.例如:对两个数进行相加,需要将这两个数分别压入操作数栈,然后执行加法指令,将结果弹出栈.操作数栈是一个 后进先出(LIFO) 的数据结构,用于暂存和处理方法执行过程中的中间结果
- 动态链接:动态链接包含了执行运行时常量池中该方法的引用,用于方法调用时进行动态链接.Java虚拟机支持动态方法调用,其中方法具体调用目标在编译时不确定,需要在运行时根据方法调用的上下文进行解析和链接
- 方法出口:方法出口是指在方法执行完毕后,JVM需要返回到那个位置继续执行的地址.在方法执行前,JVM会将方法返回地址存储在栈帧中.方法执行完成后,JVM会根据这个地址返回调用该方法的位置,继续执行后续的指令
- 本地方法栈(私有):本地方法栈和栈类似,但是它用于执行 本地方法(native关键字修饰的方法) 的调用.本地方法是使用其他语言(如C,C++)编写并通过JNI(Java Native Interface)调用的方法.
- 程序计数器(私有):程序计数器是每个线程私有的内存区域,用于记录当前线程执行的字节码指令地址.在多线程环境中,程序计数器用于线程切换后恢复执行的位置.对于Java方法,程序计数器存储当前正在执行的字节码指令的地址;对于本地方法,程序计数器则是空的.
- 字节码引擎:字节码引擎负责执行由Java字节码组成的指令集.它将字节码翻译成本地机器码或者通过解释执行来执行程序
通过代码演示
public class Math {
public static final int INIT_DATA = 666;
public static final User user = new User();
/**
* 一个方法对应一块栈帧内存区域
*
* @return
*/
public int compute() {
int a = 1;
int b = 2;
int c = 10 * (a + b);
return c;
}
public static void main(String[] args) {
Math math = new Math();
int res = math.compute();
System.out.println(res);
}
}
# 通过javap命令生成Math类的字节码文件
javap -c Math.class > Math.txt
Compiled from "Math.java"
public class com.fanqiechaodan.redis.demo.Math {
public static final int INIT_DATA;
public static final com.fanqiechaodan.redis.entity.User user;
public com.fanqiechaodan.redis.demo.Math();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int compute();
Code:
0: iconst_1
1: istore_1
2: iconst_2
3: istore_2
4: bipush 10
6: iload_1
7: iload_2
8: iadd
9: imul
10: istore_3
11: iload_3
12: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/fanqiechaodan/redis/demo/Math
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method compute:()I
12: istore_2
13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
16: iload_2
17: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
20: return
static {};
Code:
0: new #7 // class com/fanqiechaodan/redis/entity/User
3: dup
4: invokespecial #8 // Method com/fanqiechaodan/redis/entity/User."<init>":()V
7: putstatic #9 // Field user:Lcom/fanqiechaodan/redis/entity/User;
10: return
}
代码执行时,会对当前main线程在栈上开辟一块儿内存空间,每个方法在执行时都会创建一个栈帧.如下图:

使用字节码手册来分析字节码文件;字节码手册百度云(提取码:3xvh);重点查看compute方法;
iconst_1:将int类型常量1压入操作数栈

istore_1 将int类型值存入局部变量1

省略重复步骤.最终完整图为:

GC
GC过程

当新创建的对象再Java虚拟机中被分配内存时,通常会被放置到新生代的Eden区.当Eden区被填满时会触发一次Minor GC.总体过程如下:
- 会从方法区,栈,本地方法栈中找到很多 GCRoot (栈中的本地变量,方法区的静态变量,本地方法栈中的变量)
- 从GC Root出发,去找它所有引用的对象,直到找不到为止.那么这条引用链上的对象都属于非垃圾对象
- 将这些非垃圾对象复制到空闲Survivor区.而Eden区剩下的对象就是垃圾对象,进行回收
- 如果一个对象经历过一次Minor GC没有被回收掉,它的分代年龄(存储再对象头中)会+1
- 等到再次发生Minor GC时会回收Eden区和非空闲的Survivor区.找到的非垃圾对象会复制到空闲的Survivor区
- 当存活的对象再S0和S1不停的复制,分代年龄增长到一定阈值后(默认15,可以由虚拟机参数控制),这个对象会被挪到老年代,当老年代填满后会触发Full GC(过程与Minor GC类似.但是回收的是整个堆以及方法区).如果回收不到垃圾对象,等到下次再有对象放置时就会 内存溢出(OOM)
Visual GC插件演示
public class HeapDemo {
/**
* 1MB
*/
byte[] BYTES = new byte[1024 * 1024];
public static void main(String[] args) throws InterruptedException {
List<HeapDemo> heapDemoList = new ArrayList<>();
while (true) {
heapDemoList.add(new HeapDemo());
Thread.sleep(5);
}
}
}
这段代码最后肯定会 java.lang.OutOfMemoryError,因为所有的对象都会一直被引用没有可回收的垃圾对象.
## 打开Visual GC插件,查看GC过程
jvisualvm

什么样的对象会被放到老年代?
静态变量,静态变量引用的对象,对象池,缓存,Spring容器中的对象,将这些对象直接放置再老年代的原因主要是为了减少垃圾收集的频率和提高垃圾收集的效率.因为老年代中的对象生命周期长,对于这些对象进行垃圾回收的开销相对较小.而且可以减少新生代的垃圾回收压力
再Minor GC和Full GC时会触发STW(Stop The World)机制.实际上就是停止用户发起的所有线程;用户会感知到系统卡顿.这种机制对用户体验是有一定影响的.JVM性能调优主要就是减少Minor GC和Full GC的次数.主要是Full GC.因为Full GC收集的区域大,时间也较长,STW的时间也会比较久
如果没有这个机制.那么出现GC时,用GC Root去找非垃圾对象的过程中,用户线程执行完了.那么线程中的局部变量出栈了.对应的引用也都没有了.找到的非垃圾对象可能就会变成垃圾对象.为了保证垃圾收集器的安全性和正确性,垃圾收集器会在进行重要操作时暂停所有用户线程.直到垃圾收集器完成了必要的操作.然后再恢复所有被暂停的线程.
JVM参数设置

Spring Boot程序的JVM参数设置格式:
java -Xms2048M -Xmx2048M -Xss512K -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -jar demo.jar
-Xss: 每个线程的栈大小
-Xms: 设置堆的初始可用大小,默认物理内存的1/64
-Xmx: 设置堆的最大可用大小,默认物理内存的1/4
-Xmn: 新生代大小
-XX:NewRatio: 默认2表示新生代占老年带的1/2,即占整个堆的1/3
-XX:SurvivorRatio: 默认8,表示一个survivor区占用Eden的1/8,即占整个新生代的1/10
关于元空间的JVM参数有两个:
-XX:MaxMetaspaceSize: 设置元空间的最大值,默认是-1,即不限制或者说只首先于本地内存大小
-XX:MetaspaceSize:指定元空间出发Full GC的初始阈值(元空间无固定初始大小),以字节为单位,默认是21M左右,达到该值就会触发Full GC进行类型卸载,同时收集器会对该值进行调整:如果释放了大量的空间,就适当降低该值,如果释放了很少的空间,那么在不超过 -XX:MaxMetaspaceSize(如果有设置的话)的情况下,适当提高该值.这个跟早期jdk版本的 -XX:PermSize 参数意思不一样, -XX:PermSize代表永久代的初始容量
由于调整元空间大小需要Full GC,这是非常昂贵的操作,如果应用在启动的时候发生大量Full GC,通常都是由于永久代或元空间发生了大小调整,基于这种情况,一般建议在JVM参数中将MetaspaceSize和MaxMetaspaceSize设置成一样的值,并设置的比初始值要大.如果机器为8G物理内存,建议两个值都设置为256M.
StackOverflowError示例
public class StackOverflowDemo {
private static int COUNT = 0;
private static void redo(){
COUNT++;
redo();
}
public static void main(String[] args) {
try {
redo();
} catch (Throwable t) {
System.out.println(COUNT);
t.printStackTrace();
}
}
}
上述代码是一定会报 java.lang.StackOverflowError 栈内存溢出的.当设置-Xss128K时,count的值为1141.代表redo()递归调用了1141次,当一个线程的大小为128K时,还可以开辟出1141块栈帧.当设置-Xss为1M时,count的值为24193.redo()递归调用24193,可以开启24193块栈帧
结论:-Xss设置越小,count值越小,说明一个线程栈里能分配的栈帧就越少,但是对于JVM整体来说能开启的线程数就会更多.