需求1:
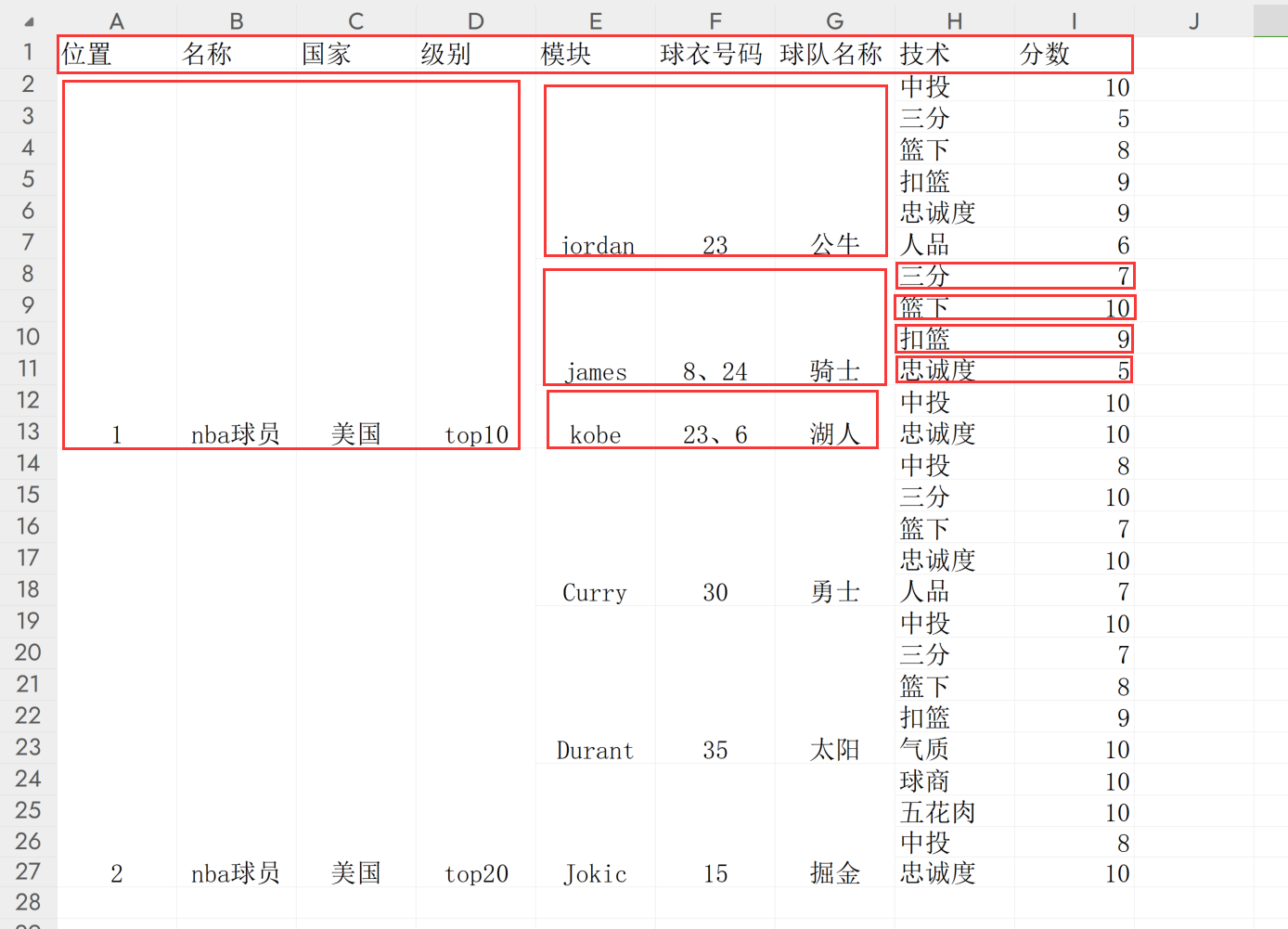
目标json格式
{"位置": 1, "名称": "nba球员", "国家": "美国", "级别": "top10", "level2": [{"模块": "jordan", "球衣号码": 23, "球队名称": "公牛", "level3": [{"技术": "中投", "分数": 10}, {"技术": "三分", "分数": 5}, {"技术": "篮下", "分数": 8}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 9}, {"技术": "人品", "分数": 6}]}, {"模块": "james", "球衣号码": "8、24", "球队名称": "骑士", "level3": [{"技术": "三分", "分数": 7}, {"技术": "篮下", "分数": 10}, {"技术": "扣篮", "分数": 9}, {"技术": "忠诚度", "分数": 5}]}, {"模块": "kobe", "球衣号码": "23、6", "球队名称": "湖人", "level3": [{"技术": "中投", "分数": 10}, {"技术": "忠诚度", "分数": 10}]}]}
转json格式链接: https://www.json.cn/#google_vignette

解决代码:
import json
import openpyxl as xl
import pandas as pd
def get_merge_cell_by_no(sheet_, column_no):
"""
:param sheet: sheet对象
:param column_no: 列索引 从1开始
:return: 返回给定的索引下的所有合并单元格
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet_.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
if merged_cell_range.min_col == column_no and merged_cell_range.max_col == column_no:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_merge_cell_by_special(sheet, start_row, end_row, start_col, end_col):
"""
在特定范围内的合并单元格坐标
:param sheet:
:param start_row:
:param end_row:
:param start_col:
:param end_col:
:return:
"""
merger_cell = [] # 第一列合并的单元格
merged_ranges = sheet.merged_cells.ranges # 获取当前工作表的所有合并区域列表
for merged_cell_range in merged_ranges:
up = merged_cell_range.min_row >= start_row
down = merged_cell_range.max_row <= end_row
left = merged_cell_range.min_col >= start_col
right = merged_cell_range.max_col <= end_col
if up and down and left and right:
merger_cell.append(merged_cell_range)
return sorted(merger_cell, key=lambda x: x.min_row) # 排序返回 默认不排序
def get_filed_by_row_id(sheet_, keys, row_id, col_level_index):
"""
get_filed_by_row_id 通过行id得到所有的json
"""
# for row_id in row_list:
filed_json = {}
for row in sheet_.iter_rows(min_row=row_id, max_row=row_id, min_col=col_level_index[2], max_col=col_level_index[3], values_only=True):
filed_json = get_dict_by_list(keys, row)
# print(row)
return filed_json
def get_dict_by_list(keys, values):
"""
get_dict_by_list
"""
data_dict = {}
for key, value in zip(keys, values):
data_dict[key] = value
return data_dict
def save_jsonline_json(json_list, target_path):
"""
json_list ---> jsonline
:param json_list:
:param target_path:
:return:
"""
with open(target_path, 'w', encoding="utf-8") as json_file:
for item in json_list:
json.dump(item, json_file, ensure_ascii=False)
json_file.write("\n")
print("Json列表已经保存到 {} 文件中。 每一行为一个json对象".format(target_path))
def excel_to_json_tree_e2e(sheet_, col_level_index):
alphabet = " ABCDEFGHIJKLMNOPQRSTUVWXYZ"
level_merge_list = get_merge_cell_by_no(sheet_, col_level_index[0]) # 一级逻辑关系所有的列\
json_list = []
for index_level1, merge_level1 in enumerate(level_merge_list):
start_row_level1 = merge_level1.min_row
end_row_level1 = merge_level1.max_row
level1_map = {}
for col in range(col_level_index[0], col_level_index[1]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
cell_ref = sheet_[alphabet[col] + str(start_row_level1)].value # 因为第二行,所以+1
level1_map[key] = cell_ref # 第一个阶段结束
level1_map["level2"] = []
level2_merge_list = get_merge_cell_by_special(sheet_, start_row_level1, end_row_level1,
col_level_index[1], col_level_index[1])
level2_list = []
for index_level2, merge_cell_level2 in enumerate(level2_merge_list):
start_row_level2 = merge_cell_level2.min_row
end_row_level2 = merge_cell_level2.max_row
level2_list.append([i for i in range(start_row_level2, end_row_level2 + 1)])
level2_map = {}
for col in range(col_level_index[1], col_level_index[2]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
cell_ref = sheet_[alphabet[col] + str(start_row_level2)].value # 因为第二行,所以+1
level2_map[key] = cell_ref # 第一个阶段结束
column_name_list = []
for col in range(col_level_index[2], col_level_index[3]): # 列A是1,列D是4
key = sheet_[alphabet[col] + str(1)].value
column_name_list.append(key)
level2_map["level3"] = []
for row_id in range(start_row_level2, end_row_level2+1):
current_filed_json = get_filed_by_row_id(sheet_, column_name_list, row_id, col_level_index)
level2_map["level3"].append(current_filed_json)
level1_map["level2"].append(level2_map)
json_list.append(level1_map)
return json_list
if __name__ == '__main__':
excel_file = "excel/merge_new.xlsx"
output_path = "output/nba_json.json"
wb = xl.load_workbook(excel_file)
sheet = wb["nba"]
col_level_index = [1, 5, 8, 10] # level1, level2, level3, level4
json_list = excel_to_json_tree_e2e(sheet, col_level_index)
save_jsonline_json(json_list, output_path)