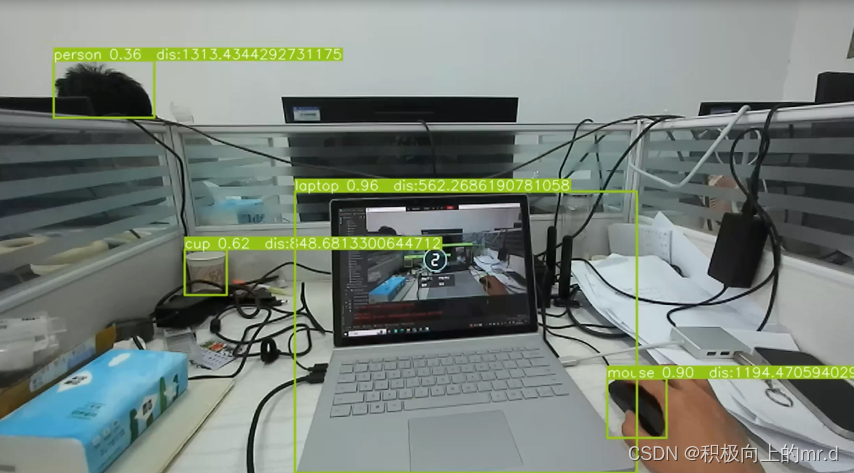
YOLOV9 + 双目测距
相关文章
1. YOLOV5 + 双目测距(python)
2. YOLOv7+双目测距(python)
3. YOLOv8+双目测距(python)
如果有用zed相机的,可以进我主页👇👇👇直接调用内部相机参数,精度比双目测距好很多
https://blog.csdn.net/qq_45077760
下载链接(求STAR):https://github.com/up-up-up-up/YOLOv9-stereo
1. 环境配置
python==3.8
Windows-pycharm
yolov9代码和yolov5类似,感觉还可以,挺好写
2. 测距流程和原理
2.1 测距流程
大致流程: 双目标定→双目校正→立体匹配→结合yolov9→深度测距
- 找到目标识别源代码中输出物体坐标框的代码段。
- 找到双目测距代码中计算物体深度的代码段。
- 将步骤2与步骤1结合,计算得到目标框中物体的深度。
- 找到目标识别网络中显示障碍物种类的代码段,将深度值添加到里面,进行显示
注:我所做的是在20m以内的检测,没计算过具体误差,当然标定误差越小精度会好一点,其次注意光线、亮度等影响因素,当然检测范围效果跟相机的好坏也有很大关系
2.2 测距原理
如果想了解双目测距原理,请移步该文章 双目三维测距(python)
3. 代码部分解析
3.1 相机参数stereoconfig.py
双目相机标定误差越小越好,我这里误差为0.1,尽量使误差在0.2以下
import numpy as np
# 双目相机参数
class stereoCamera(object):
def __init__(self):
self.cam_matrix_left = np.array([[1101.89299, 0, 1119.89634],
[0, 1100.75252, 636.75282],
[0, 0, 1]])
self.cam_matrix_right = np.array([[1091.11026, 0, 1117.16592],
[0, 1090.53772, 633.28256],
[0, 0, 1]])
self.distortion_l = np.array([[-0.08369, 0.05367, -0.00138, -0.0009, 0]])
self.distortion_r = np.array([[-0.09585, 0.07391, -0.00065, -0.00083, 0]])
self.R = np.array([[1.0000, -0.000603116945856524, 0.00377055351856816],
[0.000608108737333211, 1.0000, -0.00132288199083992],
[-0.00376975166958581, 0.00132516525298933, 1.0000]])
self.T = np.array([[-119.99423], [-0.22807], [0.18540]])
self.baseline = 119.99423
3.2 测距部分
这一部分我用了多线程加快速度,计算目标检测框中心点的深度值
config = stereoconfig_040_2.stereoCamera()
# 立体校正
map1x, map1y, map2x, map2y, Q = getRectifyTransform(720, 1280, config)
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
thread = MyThread(stereo_threading, args=(config, im0, map1x, map1y, map2x, map2y, Q))
thread.start()
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if (0 < xyxy[2] < 1280):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
x_center = (xyxy[0] + xyxy[2]) / 2
y_center = (xyxy[1] + xyxy[3]) / 2
x_0 = int(x_center)
y_0 = int(y_center)
if (0 < x_0 < 1280):
x1 = xyxy[0]
x2 = xyxy[2]
y1 = xyxy[1]
y2 = xyxy[3]
thread.join()
points_3d = thread.get_result()
a = points_3d[int(y_0), int(x_0), 0] / 1000
b = points_3d[int(y_0), int(x_0), 1] / 1000
c = points_3d[int(y_0), int(x_0), 2] / 1000
distance = ((a ** 2 + b ** 2 + c ** 2) ** 0.5)
# distance = []
# distance.append(dis)
if (distance != 0): ## Add bbox to image
label = f'{names[int(cls)]} {conf:.2f} '
annotator.box_label(xyxy, label, color=colors(c, True))
print('点 (%d, %d) 的 %s 距离左摄像头的相对距离为 %0.2f m' % (x_center, y_center, label, distance))
text_dis_avg = "dis:%0.2fm" % distance
# only put dis on frame
cv2.putText(im0, text_dis_avg, (int(x2 + 5), int(y1 + 30)),
cv2.FONT_ITALIC, 1.2,
(0, 255, 255), 3)
3.3 主代码yolov9-stereo.py
import argparse
import os
import platform
import sys
from pathlib import Path
from stereo import stereoconfig_040_2
from stereo.stereo import stereo_40
from stereo.stereo import stereo_threading, MyThread
from stereo.dianyuntu_yolo import preprocess, undistortion, getRectifyTransform, draw_line, rectifyImage, \
stereoMatchSGBM
import torch
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLO root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, smart_inference_mode
@smart_inference_mode()
def run(
weights=ROOT / 'yolo.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/coco.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
vid_stride=1, # video frame-rate stride
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
config = stereoconfig_040_2.stereoCamera()
# 立体校正
map1x, map1y, map2x, map2y, Q = getRectifyTransform(720, 1280, config)
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
thread = MyThread(stereo_threading, args=(config, im0, map1x, map1y, map2x, map2y, Q))
thread.start()
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if (0 < xyxy[2] < 1280):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(f'{txt_path}.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
x_center = (xyxy[0] + xyxy[2]) / 2
y_center = (xyxy[1] + xyxy[3]) / 2
x_0 = int(x_center)
y_0 = int(y_center)
if (0 < x_0 < 1280):
x1 = xyxy[0]
x2 = xyxy[2]
y1 = xyxy[1]
y2 = xyxy[3]
thread.join()
points_3d = thread.get_result()
a = points_3d[int(y_0), int(x_0), 0] / 1000
b = points_3d[int(y_0), int(x_0), 1] / 1000
c = points_3d[int(y_0), int(x_0), 2] / 1000
distance = ((a ** 2 + b ** 2 + c ** 2) ** 0.5)
# distance = []
# distance.append(dis)
if (distance != 0): ## Add bbox to image
label = f'{names[int(cls)]} {conf:.2f} '
annotator.box_label(xyxy, label, color=colors(c, True))
print('点 (%d, %d) 的 %s 距离左摄像头的相对距离为 %0.2f m' % (x_center, y_center, label, distance))
text_dis_avg = "dis:%0.2fm" % distance
# only put dis on frame
cv2.putText(im0, text_dis_avg, (int(x2 + 5), int(y1 + 30)),
cv2.FONT_ITALIC, 1.2,
(0, 255, 255), 3)
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Stream results
im0 = annotator.result()
if view_img:
if platform.system() == 'Linux' and p not in windows:
windows.append(p)
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
# Print time (inference-only)
LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
# Print results
t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
if update:
strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'gelan-c-det.pt', help='model path or triton URL')
parser.add_argument('--source', type=str, default=ROOT / 'data/images/a1.mp4', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', default=True,action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
# check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
4. 实验结果
4.1 测距