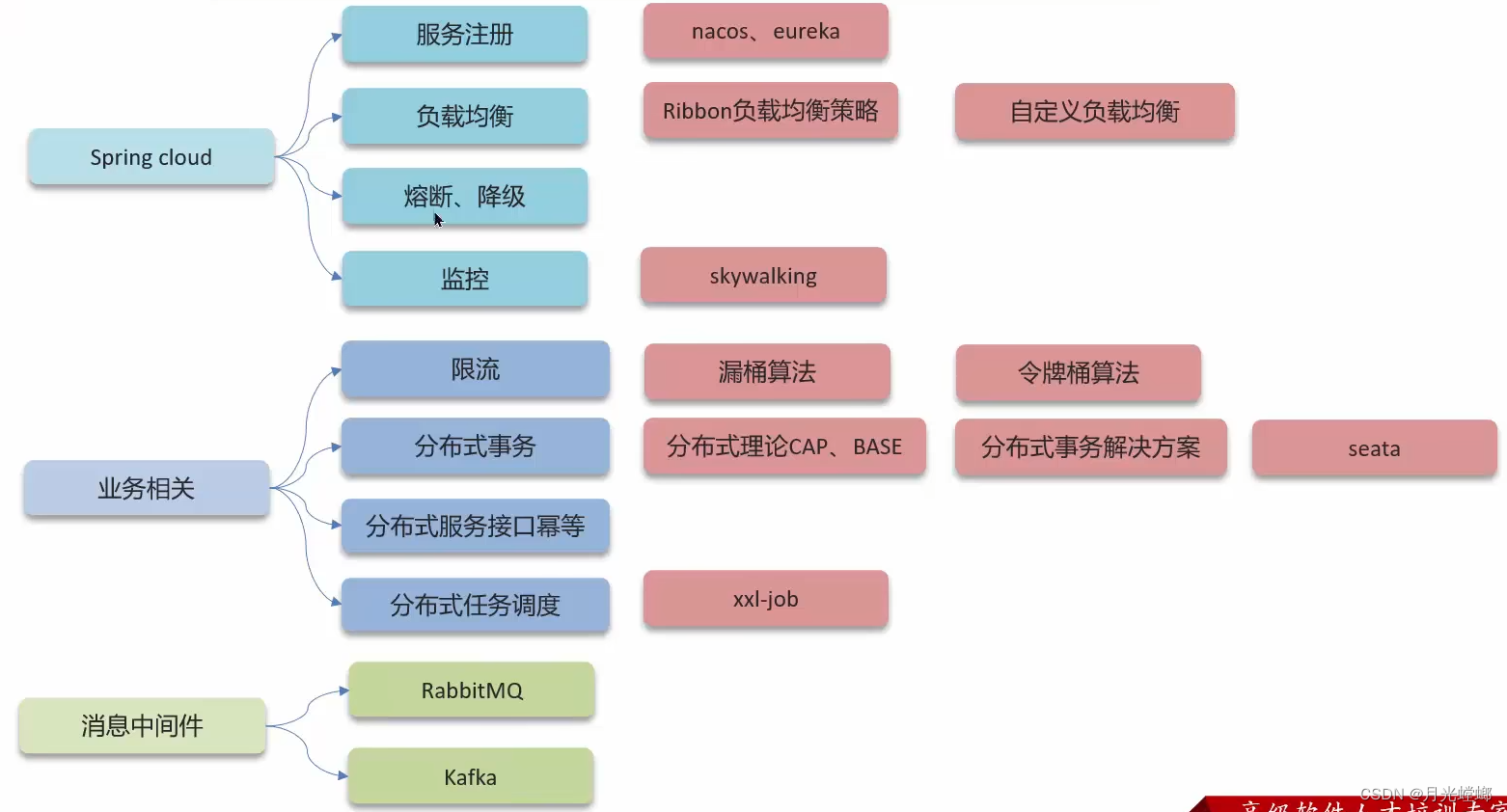
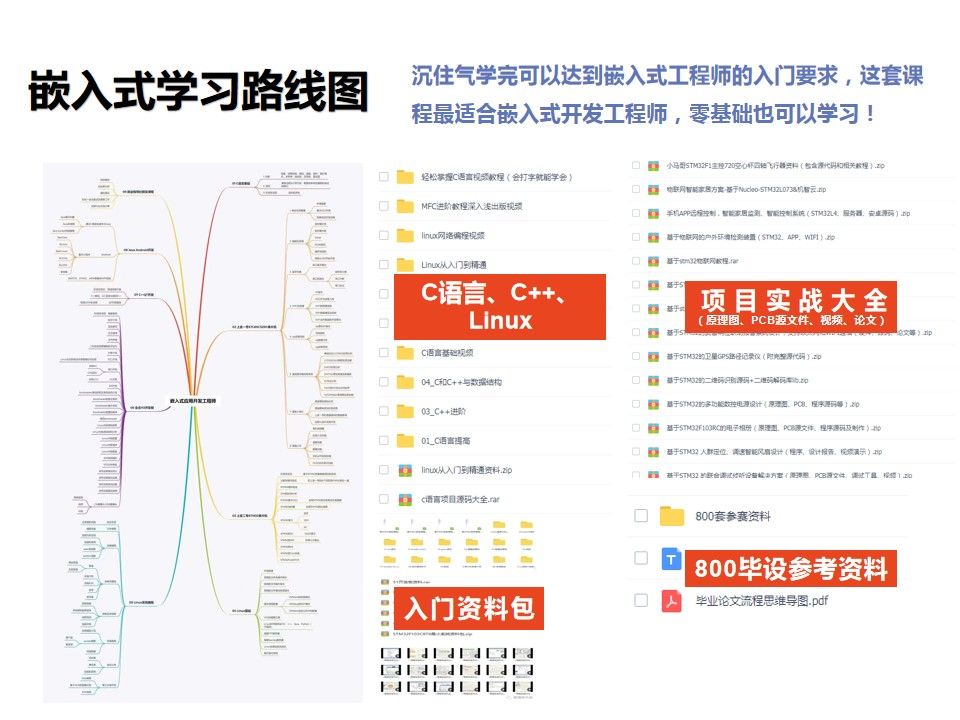
Hudi部署
完成解压安装及配置后使用maven对hudi进行构建(spark3.1,scala-2.12),使用spark-shell操作hudi(启动时若需要hudi-spark3.1-bundle_2.12-0.12.0.jar,该包已放置在/opt/software下,若不需要请忽略),将spark-shell启动命令复制并粘贴至对应报告中;使用spark-shell运行下面给到的案例,并将最终查询结果截图粘贴至对应报告中。
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode.
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
val dataGen = new DataGenerator
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)
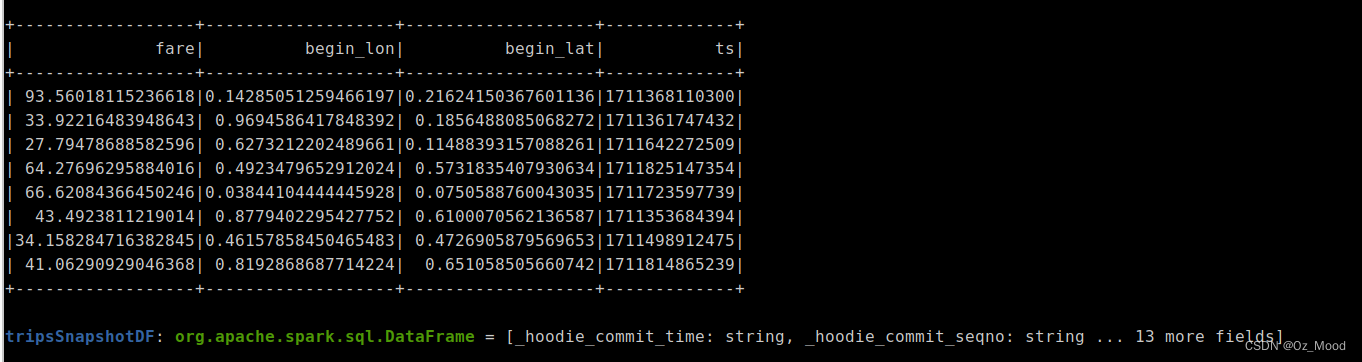
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()操作步骤:
1 将编译完成与spark集成的jar包,集成后使用spark-shell操作hudi,启动spark-shell。
spark-shell \
--jars /opt/software/hudi-spark3.1-bundle_2.12-0.12.0.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'2 在spark-shell使用:paste编译多条语句按下ctrl+D执行多行语句
:paste
// 导入依赖包
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecord
// 定义Hudi映射到的文件目录,以及存储表的名称
val tableName = "hudi_trips_cow"
val basePath = "file:///tmp/hudi_trips_cow"
// 创建数据生成器实例
val dataGen = new DataGenerator
// 使用Hudi的数据生成器生成10条JSON数据
val inserts = convertToStringList(dataGen.generateInserts(10))ctrl+D //执行多行语句
3 将10条JSON数据加载到DataFrame中,并写入hudi,实现一个简单的ETL处理
:paste
// 读取json数据到DataFrame中
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
// 将DataFrame写入数据湖
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)ctrl+D //执行多行语句
4 将10条JSON数据加载到DataFrame中,并写入hudi,实现一个简单的ETL处理
:paste
// 从数据湖中读取数据到DataFrame中
val tripsSnapshotDF = spark.read.format("hudi").load(basePath + "/*/*/*/*")
// 注册临时表
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
// 执行SQL查询,并显示
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()ctrl+D //执行多行语句