参考文档
[Raft Kafka on k8s 部署实战操作 - 掘金 (juejin.cn)](https://juejin.cn/post/7349437605857411083?from=search-suggest)
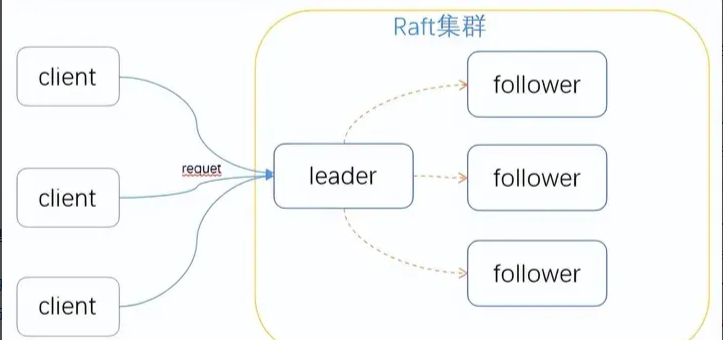
部署 Raft Kafka(Kafka 3.3.1 及以上版本引入的 KRaft 模式)在 Kubernetes (k8s) 上,可以简化 Kafka 集群的管理,因为它不再依赖于 Zookeeper
集群测试参考文档
[Helm实践---安装kafka集群 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/642515749)
部署 Raft Kafka 集群的基本步骤
1)准备 Kubernetes 集群
确保你有一个运行中的 Kubernetes 集群,并且已经配置了 kubectl 命令行工具。 部署教程如下:
创建storageclass做动态存储
(1)创建ServiceAccount、ClusterRole、ClusterRoleBinding等,为nfs-client-provisioner授权
# rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
(2)部署nfs-client-provisioner
vim 02-nfs-provisioner.yaml
nfs-client-provisioner 是一个 Kubernetes 的简易 NFS 的外部 provisioner,本身不提供 NFS,需要现有的 NFS 服务器提供存储。
注意:地址和目录要改成实际的NFS服务对应配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default #与RBAC文件中的namespace保持一致
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
#image: quay.io/external_storage/nfs-client-provisioner:latest
#这里特别注意,在k8s-1.20以后版本中使用上面提供的包,并不好用,这里我折腾了好久,才解决,后来在官方的github上,别人提的问题中建议使用下面这个包才解决的,我这里是下载后,传到我自已的仓库里
image: gmoney23/nfs-client-provisioner:latest
# image: easzlab/nfs-subdir-external-provisioner:v4.0.1
# image: registry-op.test.cn/nfs-subdir-external-provisioner:v4.0.1
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: kafka-nfs-storage #provisioner名称,请确保该名称与 nfs-StorageClass.yaml文件中的provisioner名称保持一致
- name: NFS_SERVER
value: #NFS Server IP地址
- name: NFS_PATH
value: "/data/kafka" #NFS挂载卷
volumes:
- name: nfs-client-root
nfs:
server: #NFS Server IP地址
path: "/data/kafka" #NFS 挂载卷
# imagePullSecrets:
# - name: registry-op.test.cn
部署
kubectl apply -f rbac.yaml
kubectl apply -f nfs-provisioner.yaml
kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-888d748c6-7c8hh 1/1 Running 0 4m24s
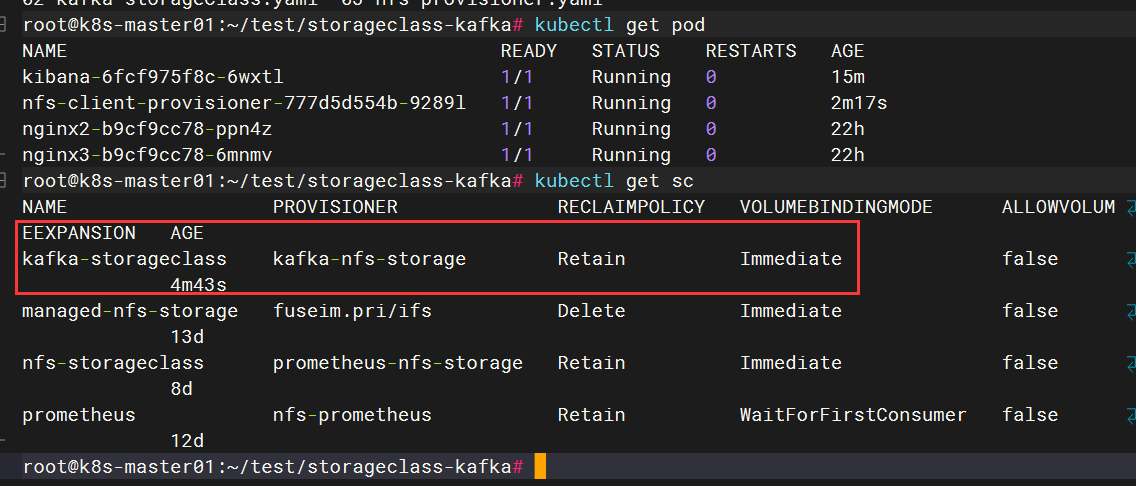
三、创建StorageClass
/root/test/storageclass-kafka
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storageclass
provisioner: kafka-nfs-storage #这里的名称要和provisioner配置文件中的环境变量PROVISIONER_NAME保持一致
parameters:
# archiveOnDelete: "false"
archiveOnDelete: "true"
reclaimPolicy: Retain
安装 helm
# 下载包
wget https://get.helm.sh/helm-v3.9.4-linux-amd64.tar.gz
# 解压压缩包
tar -xf helm-v3.9.4-linux-amd64.tar.gz
# 制作软连接
ln -s /opt/helm/linux-amd64/helm /usr/local/bin/helm
# 验证
helm version
helm help
配置 Helm chart
如果你使用 Bitnami 的 Kafka Helm chart,你需要创建一个 values.yaml 文件来配置 Kafka 集群。在该文件中,你可以启用 KRaft 模式并配置其他设置,如认证、端口等。
# 添加下载源
helm repo add bitnami https://charts.bitnami.com/bitnami
# 下载
helm pull bitnami/kafka --version 26.0.0
# 解压
tar -xf kafka-26.0.0.tgz
# 修改配置
vi kafka/values.yaml
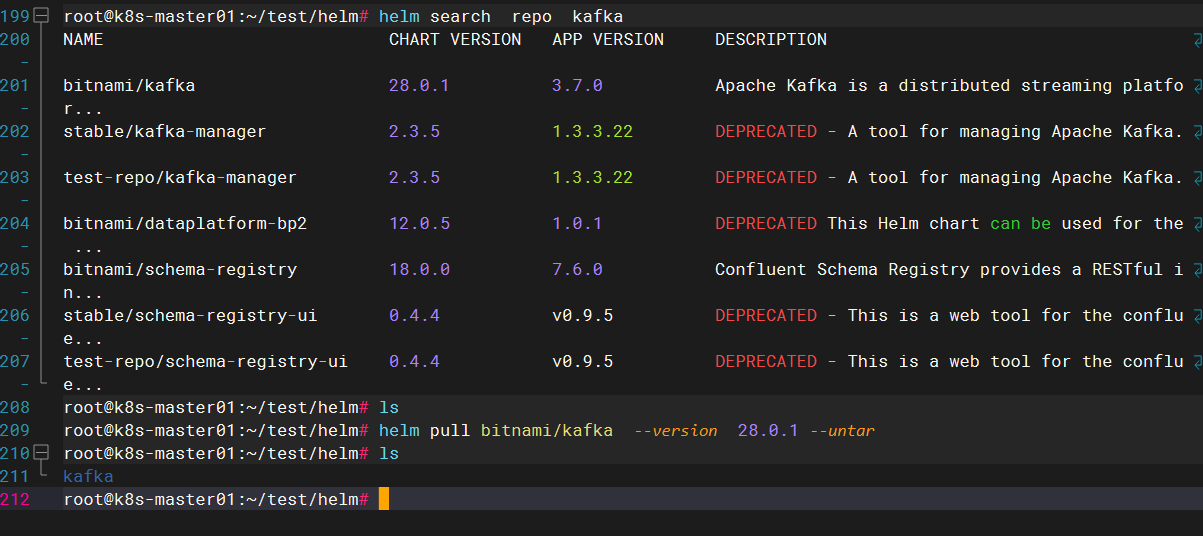
#搜索kafka
helm search repo kafka
(3).拉取chart包格式:
# helm pull 远程仓库chart包名 --version 0.4.3 --untar
#从远程仓库拉取指定版本的chart包到本地并解压,--untar是解压,不加就是压缩包
# helm pull 远程仓库chart包名 --untar #从远程仓库拉取最新版本的chart包到本地并解压,--untar是解压,不加就是压缩包
以下是一个 values.yaml 的示例配置:
先备份模板自带的
image:
registry: docker.io
repository: bitnami/kafka
tag: 3.7.0-debian-12-r0
listeners:
client:
containerPort: 9092
# 默认是带鉴权的,SASL_PLAINTEXT
protocol: PLAINTEXT
name: CLIENT
sslClientAuth: ""
controller:
replicaCount: 3 # 控制器的数量
persistence:
storageClass: "kafka-controller-local-storage"
size: "10Gi"
# 目录需要提前在宿主机上创建
local:
- name: kafka-controller-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/kraft/kafka-controller/data1"
- name: kafka-controller-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/kraft/kafka-controller/data1"
- name: kafka-controller-2
host: "local-168-182-112"
path: "/opt/bigdata/servers/kraft/kafka-controller/data1"
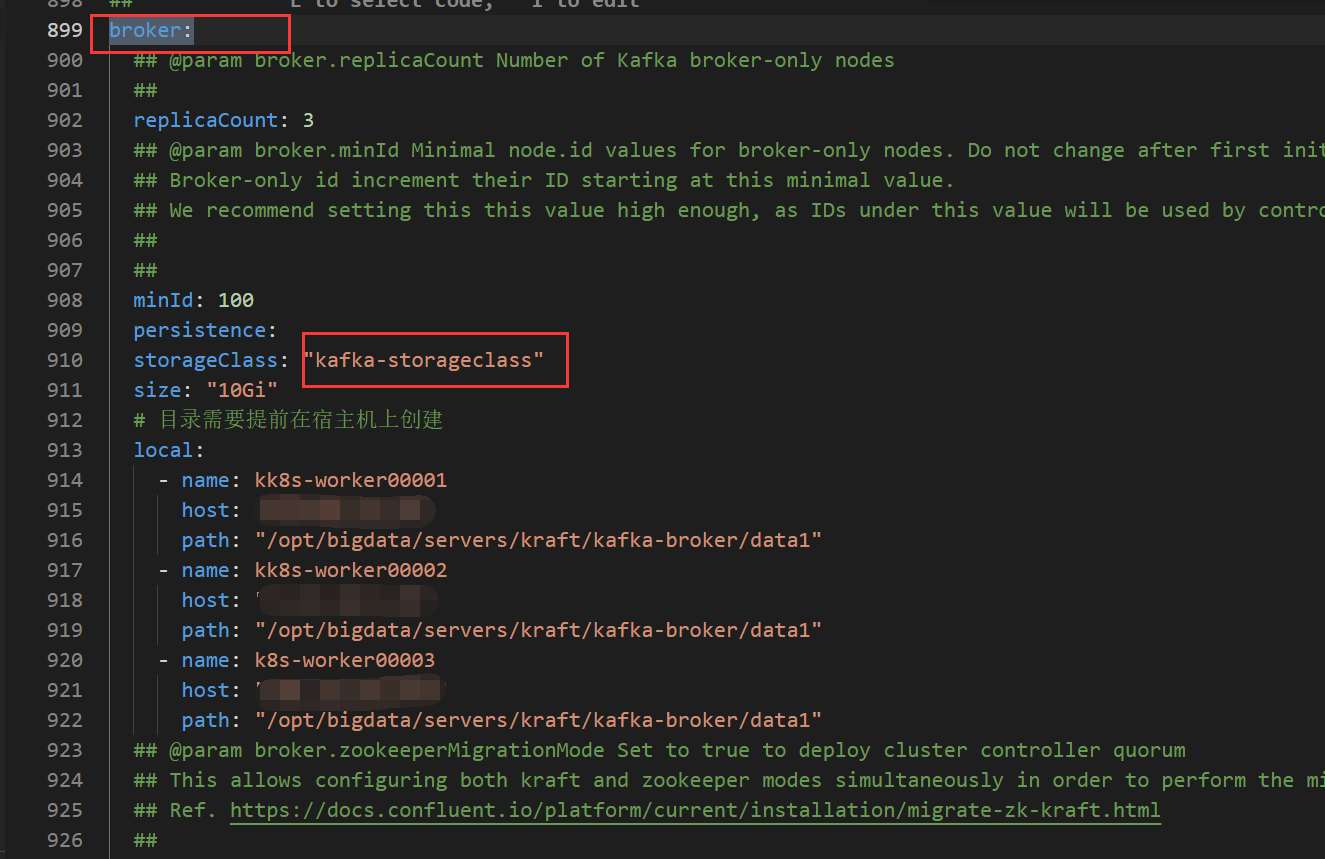
broker:
replicaCount: 3 # 代理的数量
persistence:
storageClass: "kafka-broker-local-storage"
size: "10Gi"
# 目录需要提前在宿主机上创建
local:
- name: kafka-broker-0
host: "local-168-182-110"
path: "/opt/bigdata/servers/kraft/kafka-broker/data1"
- name: kafka-broker-1
host: "local-168-182-111"
path: "/opt/bigdata/servers/kraft/kafka-broker/data1"
- name: kafka-broker-2
host: "local-168-182-112"
path: "/opt/bigdata/servers/kraft/kafka-broker/data1"
service:
type: NodePort
nodePorts:
#NodePort 默认范围是 30000-32767
client: "32181"
tls: "32182"
# Enable Prometheus to access ZooKeeper metrics endpoint
metrics:
enabled: true
kraft:
enabled: true
重点修改地方
1
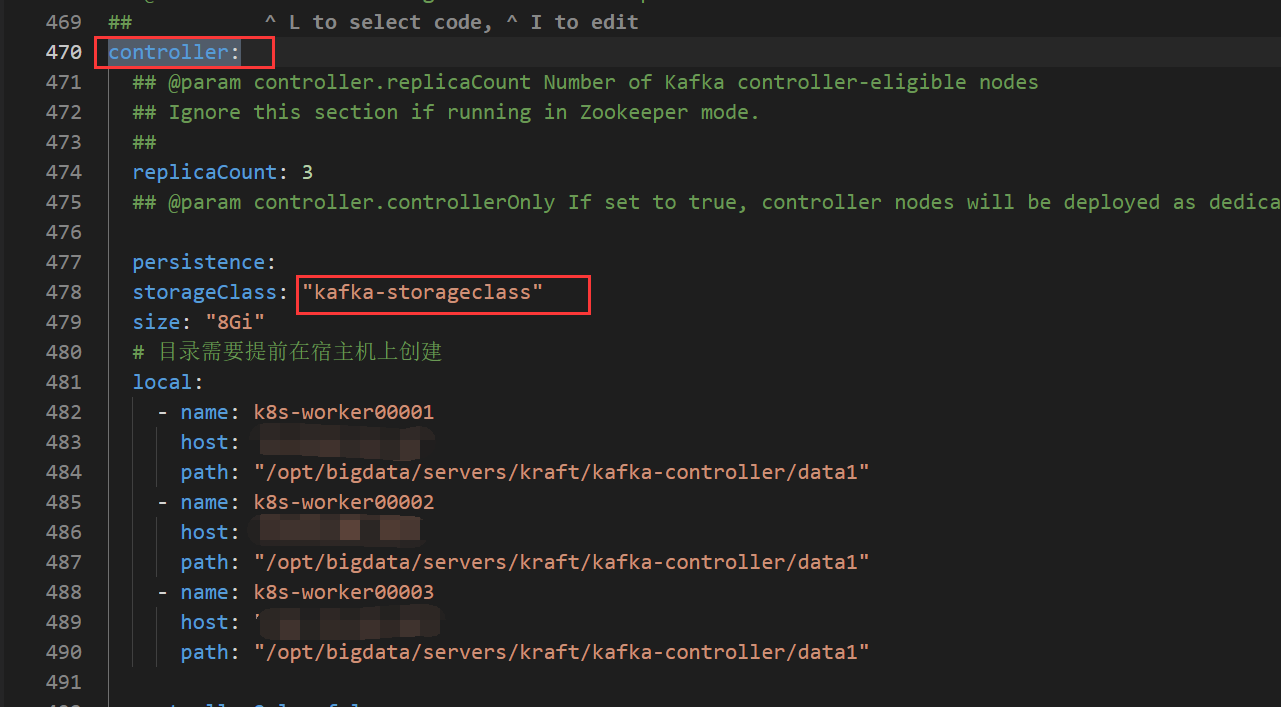
2
添加以下几个文件:
kafka/templates/broker/pv.yaml
{{- range .Values.broker.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: {{ .name }}
labels:
name: {{ .name }}
spec:
storageClassName: {{ $.Values.broker.persistence.storageClass }}
capacity:
storage: {{ $.Values.broker.persistence.size }}
accessModes:
- ReadWriteOnce
local:
path: {{ .path }}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- {{ .host }}
---
{{- end }}
- kafka/templates/broker/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: {{ .Values.broker.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
- kafka/templates/controller-eligible/pv.yaml
{{- range .Values.controller.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: {{ .name }}
labels:
name: {{ .name }}
spec:
storageClassName: {{ $.Values.controller.persistence.storageClass }}
capacity:
storage: {{ $.Values.controller.persistence.size }}
accessModes:
- ReadWriteOnce
local:
path: {{ .path }}
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- {{ .host }}
---
{{- end }}
- kafka/templates/controller-eligible/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: {{ .Values.controller.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
宿主机准备工作

4使用 Helm 部署 Kafka 集群
# 先准备好镜像
docker pull docker.io/bitnami/kafka:3.6.0-debian-11-r0
docker tag docker.io/bitnami/kafka:3.6.0-debian-11-r0 registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0
docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/kafka:3.6.0-debian-11-r0
# 开始安装
$ kubectl create namespace kafka
$ helm install -f values.yaml kafka bitnami/kafka --namespace kafka
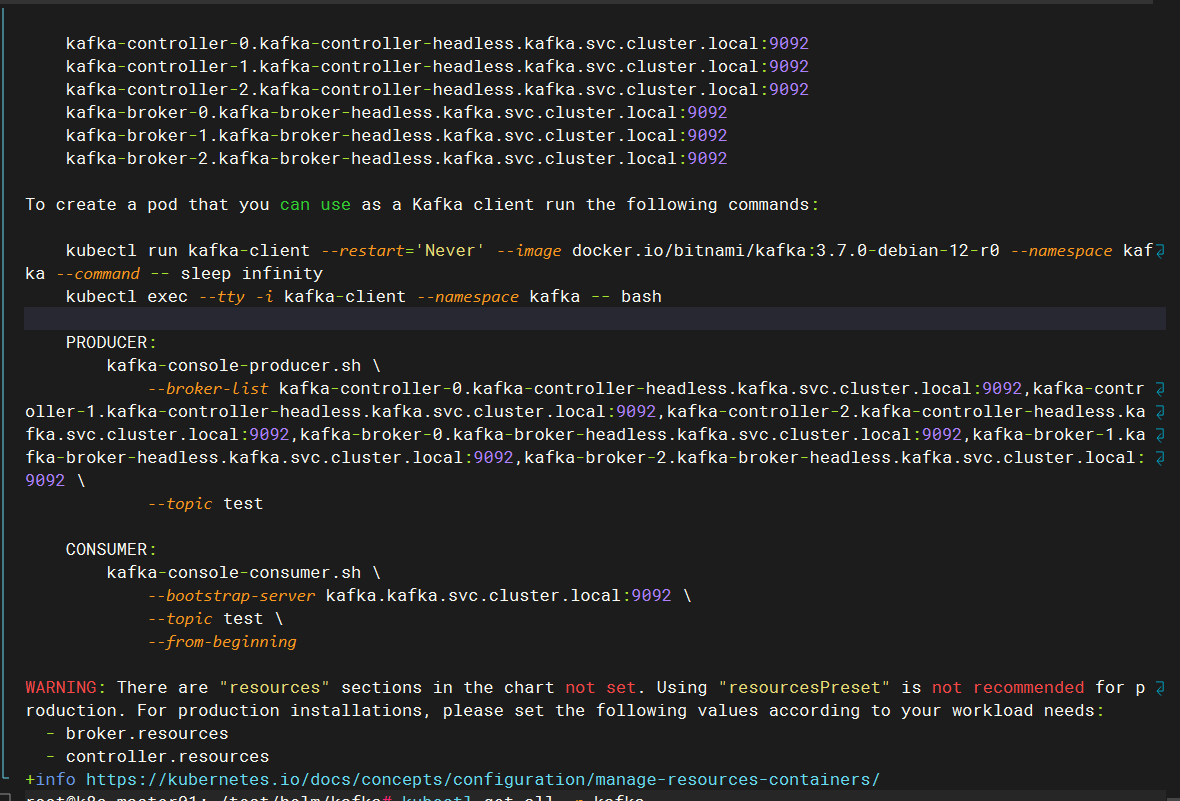
查看运行的pod

部署单节点集群
- 下面这个案例关闭了持久化存储,仅演示部署效果
helm upgrade --install kafka \
--namespace kafka-demo \
--create-namespace \
--set broker.combinedMode.enabled="true" \
--set broker.persistence.enabled="false" \
bitnami/kafka

Controller 与 Broker 分离部署
helm upgrade --install kafka \
--namespace kafka-demo \
--create-namespace \
--set broker.persistence.size="20Gi" \
bitnami/kafka
默认已开启持久化存储。
获取ip和port
方式一:
其实安装kafka安装好之后输出的信息里面就有打印ip,关键是这个ip是我们自己定义的,所以我们事前也是知道的
方式二:当然你也可以通过下面命令获取
获取IP地址:
kubectl get nodes --namespace kafka -o jsonpath="{.items[0].status.addresses[0].address}"
获取端口:
方式一:
kubectl get --namespace kafka -o jsonpath="{.spec.ports[0].nodePort}" services kafka
方式二:
echo "$(kubectl get svc --namespace kafka -l "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=kafka,app.kubernetes.io/component=kafka,pod" -o jsonpath='{.items[*].spec.ports[0].nodePort}' | tr ' ' '\n')"
获取取ip和port之后,我们通过配置springcloud stream即可创建新连接,如下所示:
kafka集群测试
这里通过两种方式测试下kafka集群,区别只是一个是新起一个容器进行测试,另一个则是在原来的基础进行测试:
3.1 方式一
新起一个容器
1.运行一个kafka-client,用于连接kafka集群
# 创建客户端
kubectl run kraft-kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.7.0-debian-12-r0 --namespace kafka --command -- sleep infinity
kubectl run kraft-kafka-client --restart='Never' \
--image docker.io/bitnami/kafka:3.7.0-debian-12-r0 \
--namespace kafka --command -- sleep infinity
上面参数说明:
- `kubectl run kafka-client`:
使用 `kubectl` 命令创建一个名为 `kafka-client` 的 Pod
- `--restart='Never'`:
设置 Pod 的重启策略为 "Never",这意味着 Pod 不会自动重启
- `--image registry.cn-hangzhou.aliyuncs.com/abroad_images/kafka:3.5.0-debian-11-r1`:
指定要在 Pod 中使用的容器镜像。这里使用的是 `registry.cn-hangzhou.aliyuncs.com/abroad_images/kafka:3.5.0-debian-11-r1` 镜像
- `--namespace public-service`:
指定要在名为 `public-service` 的命名空间中创建 Pod
- `--command -- sleep infinity`:
在容器中执行命令 `sleep infinity`,以保持 Pod 持续运行。`--command` 表示后面的内容是一个命令而不是一个参数,`sleep infinity` 是一个常用的命令,使得容器无限期地休眠
查看pod,已成功建立
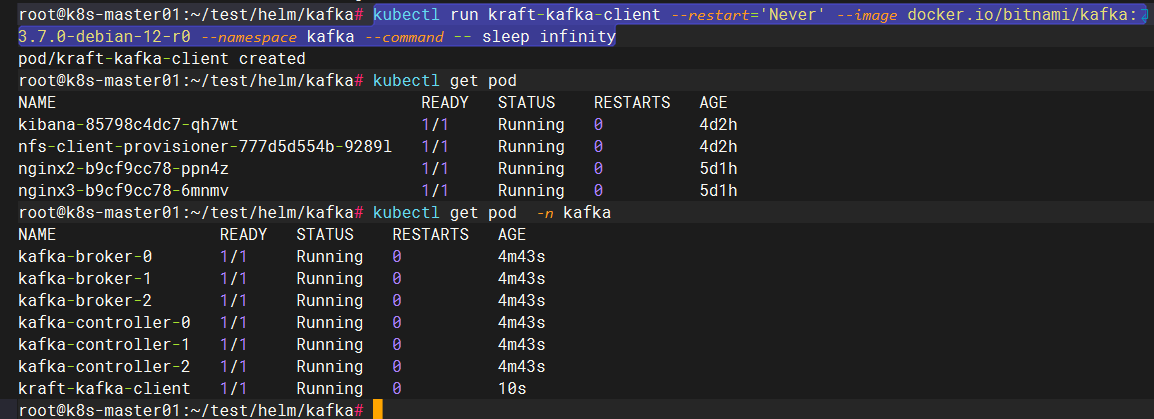
2.在k8s-master01节点上开启两个窗口,一个用于生产者,一个用作消费者。
(1)生产者窗口
进入kafka创建一个名为test的topic,出现>代表成功
2.1方式一
[root@k8s-master01 kafka]# kubectl exec -it kraft-kafka-client -n kafka -- /bin/bash
I have no name!@kafka-client:/$ cd /opt/bitnami/kafka/bin
I have no name!@kafka-client:/opt/bitnami/kafka/bin$ kafka-console-producer.sh --broker-list kafka-broker-0.kafka-broker-headless.kafka.svc.cluster.local:9092,kafka-broker-1.kafka-broker-headless.kafka.svc.cluster.local:9092,kafka-broker-2.kafka-broker-headless.kafka.svc.cluster.local:9092 --topic test
>
kafka-console-producer.sh --broker-list \
kafka-broker-0.kafka-broker-headless.kafka.svc.cluster.local:9092,\
kafka-broker-1.kafka-broker-headless.kafka.svc.cluster.local:9092,\
kafka-broker-2.kafka-broker-headless.kafka.svc.cluster.local:9092 \
--topic test
上面参数说明:
- `kafka-console-producer.sh`:用于创建生产者
- `--broker-list kafka-0.kafka-headless.public-service.svc.cluster.local:9092,kafka-1.kafka-headless.public-service.svc.cluster.local:9092,kafka-2.kafka-headless.public-service.svc.cluster.local:9092`:指定要连接的 Kafka Broker 列表。使用逗号分隔多个 Broker 的地址。在这里,指定了三个 Kafka Broker 的地址
- `--topic test`:指定要发布消息的主题名称,这里使用的是 "test"

(2)消费者窗口
[root@k8s-master01 kafka]# kubectl exec -it kafka-client -n public-service -- bash
I have no name!@kafka-client:/$ cd /opt/bitnami/kafka/bin/
I have no name!@kafka-client:/opt/bitnami/kafka/bin$ kafka-console-consumer.sh --bootstrap-server kafka.public-service.svc.cluster.local:9092
上面参数说明:
- `kafka-console-consumer.sh`:
用于启动消费者
- `--bootstrap-server localhost:9092`:
指定用于引导连接到 Kafka 集群的 Kafka Broker 的地址。使用的是本地主机(localhost)上的 Kafka Broker,并监听 9092 端口
- `--topic test`:
指定要发布消息的主题名称,这里使用的是 "test"
- `--from-beginning`:
设置消费者从主题的开始处开始消费消息。这意味着消费者将从主题中的最早可用消息开始消费
- 3.开始测试,观察到消费正常
(1)生产者窗口
>test2
>test1
(2)消费者窗口
test2
test1
2.2 方式二
1.进入kafka创建一个名为testtopic的topic
kubectl exec -it kafka-0 -n public-service -- bash
cd /opt/bitnami/kafka/bin
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic testtopic
Created topic testtopic.
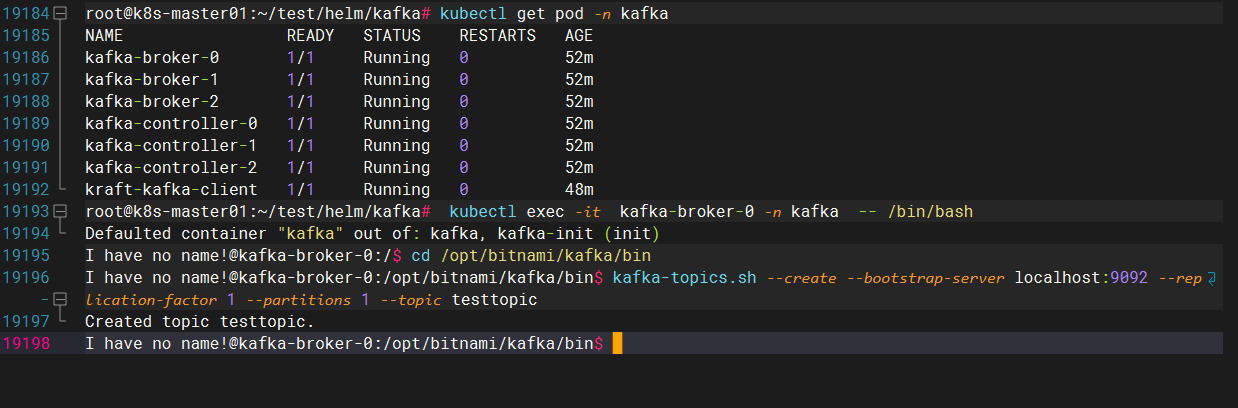
上面参数说明:
- `--create`:指示 `kafka-topics.sh` 命令创建一个新的主题
- `kafka-topics.sh`:用于创建topic
- `--bootstrap-server localhost:9092`:指定用于引导连接到 Kafka 集群的 Kafka Broker 的地址。使用的是本地主机(localhost)上的 Kafka Broker,并监听 9092 端口
- `--replication-factor 1`:设置主题的副本因子(replication factor),指定每个分区的副本数量。
- `--partitions 1`:设置主题的分区数,指定要创建的分区数量
- `--topic testtopic`:指定要创建的主题的名称,这里使用的是 "testtopic"
2.启动消费者
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testtopic
上面参数说明:
- `kafka-console-consumer.sh`:用于创建消费者
- `--bootstrap-server localhost:9092`:指定用于引导连接到 Kafka 集群的 Kafka Broker 的地址。使用的是本地主机(localhost)上的 Kafka Broker,并监听 9092 端口
3.新起一个窗口后,进入kafka,启动一个生产者后,输出hello字段
[root@k8s-master01 kafka]# kubectl exec -it kafka-0 -n public-service -- bash
I have no name!@kafka-0:/$ kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testtopic
>hello
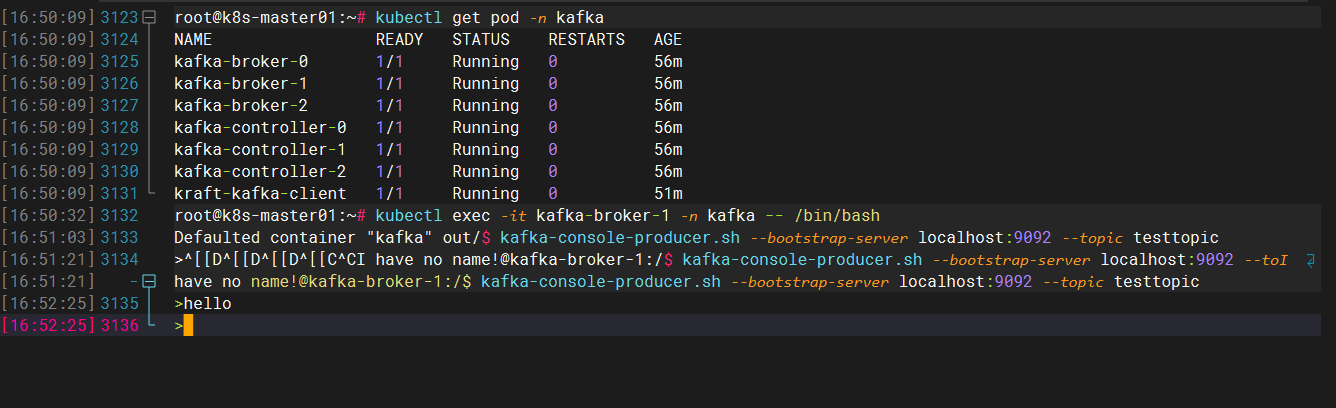
上面参数说明:
- `kafka-console-consumer.sh`:用于创建生产者
- `--bootstrap-server localhost:9092`:指定用于引导连接到 Kafka 集群的 Kafka Broker 的地址。使用的是本地主机(localhost)上的 Kafka Broker,并监听 9092 端口
4.在消费者窗口上进行查看,观察到消费正常
I have no name!@kafka-broker-0:/opt/bitnami/kafka/bin$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testtopic
hello
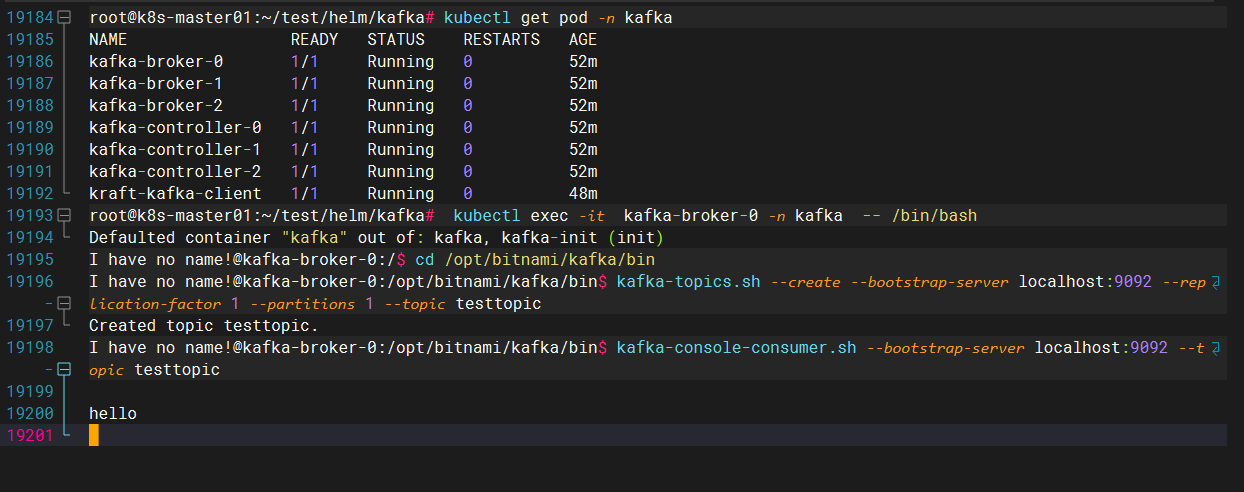
四、kafka集群扩容
关于kafka集群扩容,这里介绍两种方式:一种是修改副本数进行扩容,另一种是使用helm upgrade进行扩容
4.1 方式一
1.修改values.yaml相应配置,搜索replicaCount,将副本数修改为5
[root@k8s-master01 ~]# cd /root/kafka
[root@k8s-master01 kafka]# vim values.yaml
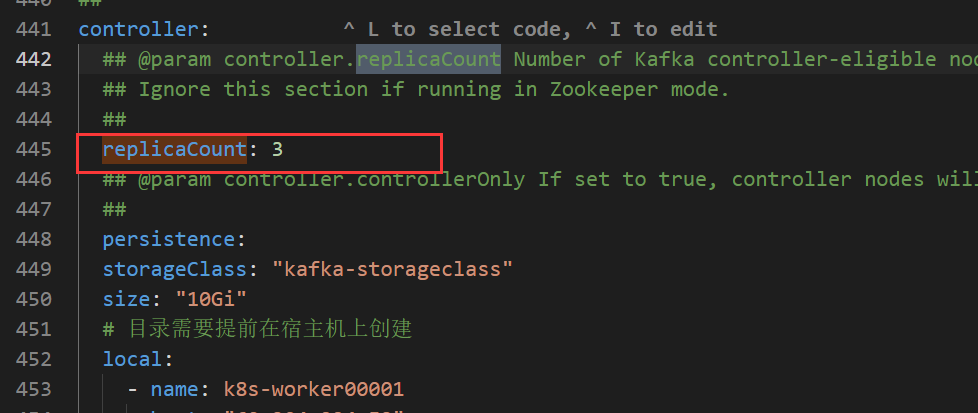
2.开始扩容
[root@k8s-master01 ~]# cd /root/kafka
[root@k8s-master01 kafka]# helm upgrade -n public-service kafka .
3.查看pod建立情况,观察到已经成功扩容
4.2 方式二
其实这种方式只针对命令行方式安装kafka集群
1.直接使用helm upgrade命令进行扩容
helm upgrade kafka bitnami/kafka --set zookeeper.enabled=false --set replicaCount=3 --set externalZookeeper.servers=zookeeper --set persistence.enabled=false -n public-service
2.查看pod建立情况,观察到已经成功扩容
五、kafka集群删除
1.查看安装的集群
helm list -A

2.删除kafka集群
helm delete kafka -n kafka
3. 删除实例
helm uninstall kafka -n kafka
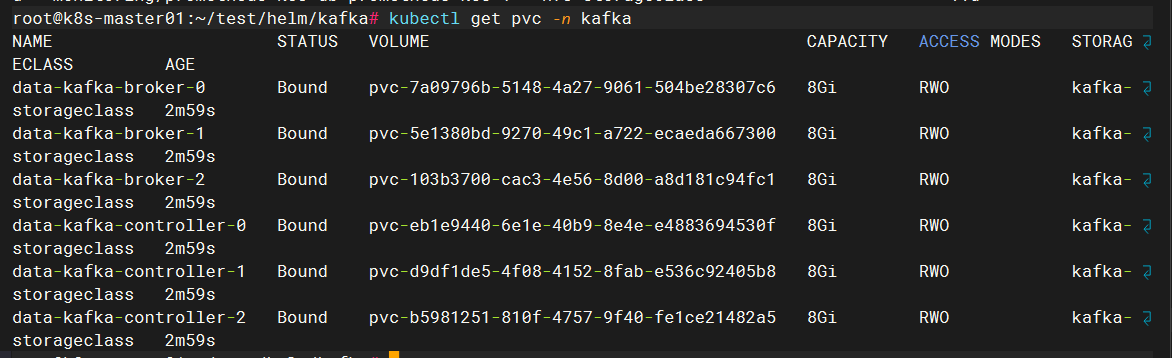
4. 删除Kafka 命名空间下的所有 PVC(持久卷声明)
kubectl delete pvc --all -n kafka


![[Kubernetes]<span style='color:red;'>8</span>. <span style='color:red;'>K</span><span style='color:red;'>8</span><span style='color:red;'>s</span>使用<span style='color:red;'>Helm</span>部署mysql<span style='color:red;'>集</span><span style='color:red;'>群</span>(主从数据库<span style='color:red;'>集</span><span style='color:red;'>群</span>)](https://img-blog.csdnimg.cn/direct/04682aad82044f01b7e36feb2aa722e3.png)