此项目是针对PDF、docx、doc、PPT四种非结构化数据进行解析,识别里面的文本和图片。
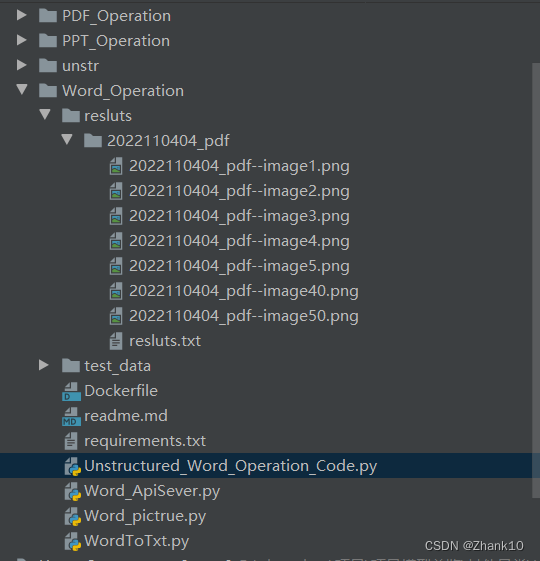
代码结构
├── Dockerfile
├── requirements
├── resluts
├── test_data
│ ├── 20151202033304658.pdf
│ ├── 2020_World_Energy_Data.pdf
│ ├── 2022110404_pdf.docx
│ ├── 2022110404_pdf.pdf
│ ├── H3_AP201701200282787162_01.pdf
│ ├── H3_AP202205271568109307_1.pdf
│ ├── H3_AP202205271568109307_1.pptx
│ ├── test.pdf
│ ├── test.pptx
│ ├── test_table.pdf
│ └── test_word.docx
├── Unstr_ApiSever.py ###----------API服务
├── Unstructured_PDF_Operation_Code.py
├── Unstructured_PPT_Operation_Code.py
├── Unstructured_Word_Operation_Code.py
PDF操作
部分代码展示
import fitz,os
doc = fitz.open('./test_data/2022110404_pdf.pdf')
def func(doc):
for i in range(len(doc)):
imglist = doc.getPageImageList(i)
for j, img in enumerate(imglist):
xref = img[0]
pix = fitz.Pixmap(doc, xref) # make pixmap from image
if pix.n - pix.alpha < 4: # can be saved as PNG
pix.writePNG("p%s-%s.png" % (i + 1, j + 1))
else: # CMYK: must convert first
pix0 = fitz.Pixmap(fitz.csRGB, pix)
pix0.writePNG("p%s-%s.png" % (i + 1, j + 1))
pix0 = None # free Pixmap resources
pix = None # free Pixmap resources
if __name__ == "__main__":
func(doc=fitz.open('./test_data/2022110404_pdf.pdf')) # input the path of pdf file
func1('./test_data') # input the path of pdf file
pdf_path = "./test_data/2022110404_pdf.pdf"
doc = fitz.open(pdf_path)
num_pages = doc.page_count
# Text info of PDF
for page_index in range(num_pages):
page = doc.load_page(page_index)
text = page.get_text()
print(f"第{page_index + 1}页的文本内容为:\n{text}\n")
结果如下:

word操作
import docx
import os, re
from docx import Document
class Word:
"""
Word操作
"""
def Word_get_pictures(self,infile):
try:
in_File = infile.split('/')[2][:-5] ##---------Word名称
new_filepath = os.path.join('%s/%s') % ('./resluts', in_File)
doc = docx.Document(infile)
dict_rel = doc.part._rels
for rel in dict_rel:
rel = dict_rel[rel]
if "image" in rel.target_ref:
if not os.path.exists(new_filepath):
os.makedirs(new_filepath)
img_name = re.findall("/(.*)", rel.target_ref)[0]
word_name = os.path.splitext(new_filepath)[0]
if os.sep in word_name:
new_name = word_name.split('\\')[-1]
else:
new_name = word_name.split('/')[-1]
img_name = f'{new_name}-' + '-' + f'{img_name}'
with open(f'{new_filepath}/{img_name}', "wb") as f:
f.write(rel.target_part.blob)
except:
pass
def Word_Get_txt(self,infile):
in_File = infile.split('/')[2][:-5] ##---------Word名称
new_filepath = os.path.join('%s/%s') % ('./resluts', in_File)
document = Document(infile)
all_paragraphs = document.paragraphs
all_tables = document.tables
with open(os.path.join("%s/%s.txt") % (new_filepath, "resluts"), 'w', encoding='utf-8') as f:
for paragraph in all_paragraphs:
# print(paragraph.text.replace(" ", "").replace(" ", ""))
f.write(paragraph.text.replace(" ", "").replace(" ", ""))
for table in all_tables:
for row in table.rows:
for cell in row.cells:
f.write(cell.text)
# print(cell.text) # 打印
if __name__ == '__main__':
# 获取文件夹下的word文档列表,路径自定义
# os.chdir("./test_data/2022110404_pdf.docx")
Word().Word_get_pictures("./test_data/2022110404_pdf.docx")
Word().Word_Get_txt("./test_data/2022110404_pdf.docx")
结果如下:
PPT操作
import os
from zipfile import ZipFile
from pptx import Presentation
from docx import Document
class PPT:
def PPT_get_pictrue(self,infile):
in_File = infile.split('/')[2][:-5]
new_filepath = os.path.join('%s/%s') % ('./resluts', in_File)
if not os.path.exists(new_filepath):
os.makedirs(new_filepath)
with ZipFile(infile) as f:
for file in f.namelist():
if file.startswith("ppt/media/"):
f.extract(file, path=new_filepath)
return new_filepath
def PPT_get_words_to_txt(self,inpath, outpath):
m_ppt = Presentation(inpath)
# print(len(m_ppt.slides))
with open(os.path.join('%s/%s.txt') % (outpath, 'resluts'), 'w', encoding='utf-8') as f:
for slide in m_ppt.slides:
for shape in slide.shapes:
if not shape.has_text_frame:
continue
for paragraph in shape.text_frame.paragraphs:
for content in paragraph.runs:
f.write(content.text + '\n')
def PPT_get_words_to_docx(self,filepath,save_path):
wordfile = Document()
pptx = Presentation(filepath)
for slide in pptx.slides:
for shape in slide.shapes:
if shape.has_text_frame:
text_frame = shape.text_frame
for paragraph in text_frame.paragraphs:
wordfile.add_paragraph(paragraph.text)
wordfile.save(save_path)
if __name__ == "__main__":
infile = "./test_data/OpenCV算法解析.pptx"
new_infile=PPT().PPT_get_pictrue(infile)
PPT().PPT_get_words_to_txt(infile,new_infile)
结果如下: