心法利器
本栏目主要和大家一起讨论近期自己学习的心得和体会。具体介绍:仓颉专项:飞机大炮我都会,利器心法我还有。
2023年新的文章合集已经发布,获取方式看这里:又添十万字-CS的陋室2023年文章合集来袭,更有历史文章合集,欢迎下载。
往期回顾
上一期是写了最近RAG文章的小结(心法利器[111] | 近期RAG技术总结和串讲(4w字RAG文章纪念)),里面提到RAG比较早的一篇论文,可见RAG这个概念并非大模型之后才有的,早在2020年就已经有这样的一篇文章,提出了真正意义的RAG,今天让我们来讨论这篇论文吧。
原论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
论文翻译:https://blog.csdn.net/m0_52695557/article/details/134307931
论文笔记:https://blog.csdn.net/weixin_73479446/article/details/133278543
叠个甲,本文没有覆盖全文内容,更多是从文章中抽取了值得分享和分析的部分来讲,如果要深入了解,包括当时视角的研究现状,论文内具体使用的技术、实验数据等,还是需要回到论文里详细看的。
目录:
Introduction精读
模型
实践细节和实验
分析讨论
Introduction精读
看完这篇文章的introduction,感觉很有必要解读一下,因为这里面对RAG模型的意义理解的还是很透彻的,充分体现出了RAG的价值,时至今日,RAG的价值很大程度也是围绕着这个在推广(也就4年前的事,怎么感觉好像很久远的样子)。
They cannot easily expand or revise their memory, can’t straightforwardly provide insight into their predictions, and may produce “hallucinations”.
很多更老的模型并不能拓展或者更新知识,不能直接提供对预测的见解,并容易产生幻觉,这应该就是原有模型的劣势,而作者的解决方式就是通过RAG,这个是作者的解释。
We endow pre-trained, parametric-memory generation models with a non-parametric memory through a general-purpose fine-tuning approach which we refer to as retrieval-augmented generation (RAG).
紧跟着对这个概念进行了展开。
We build RAG models where the parametric memory is a pre-trained seq2seq transformer, and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever. We combine these components in a probabilistic model trained end-to-end.
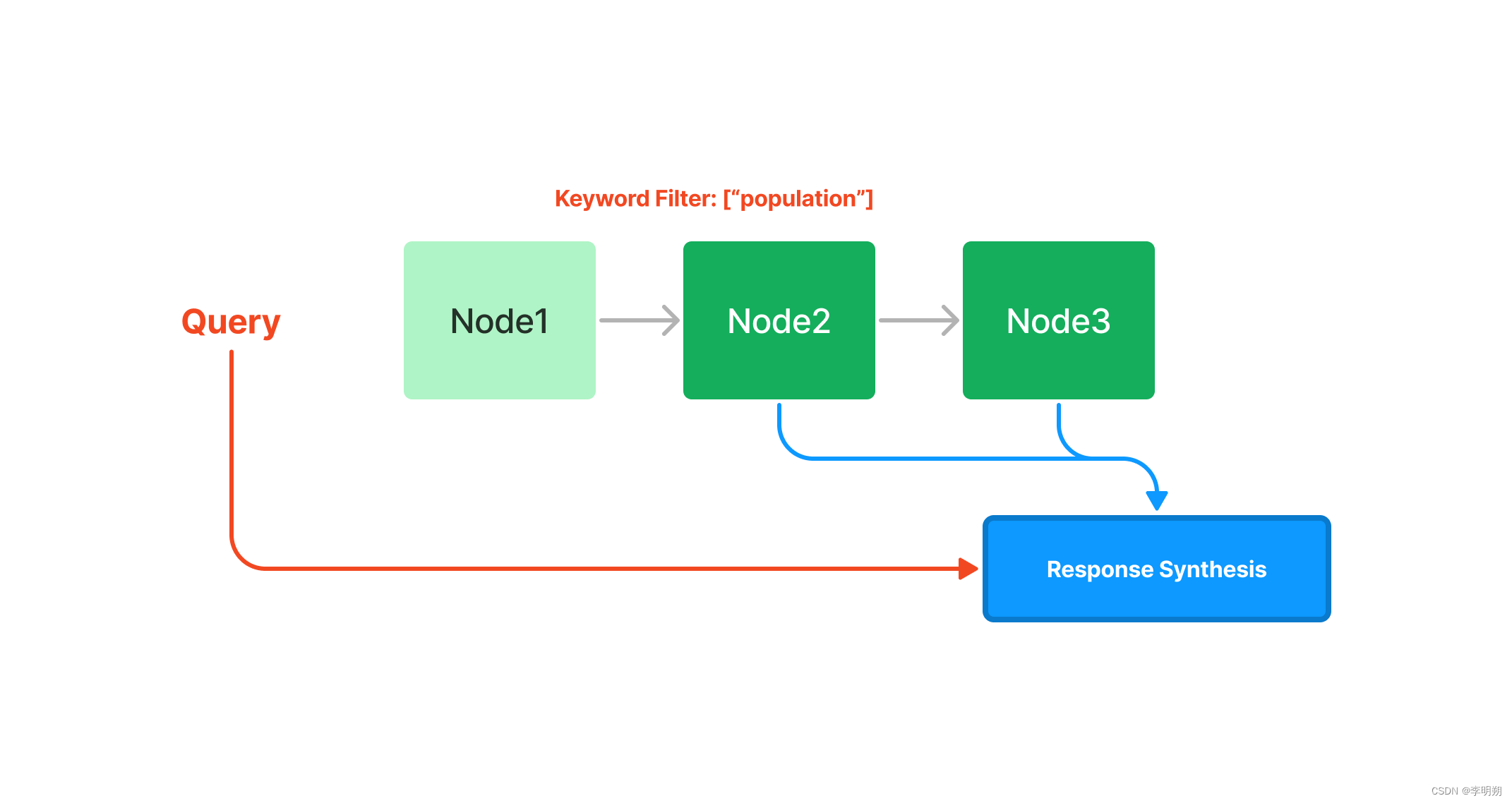
从这几句话可以理解到,这个"the parametric memory"就是一个生成模型,此处是用的一个预训练好的seq2seq模型,而非参数的记忆是用一堆向量来存储的,这里的知识来自于维基百科,而记忆的获取则是通过预训练好的neural retriever来实现的,整体就形成一个端到端的模型,此时,再看作者的图,就更好理解了。
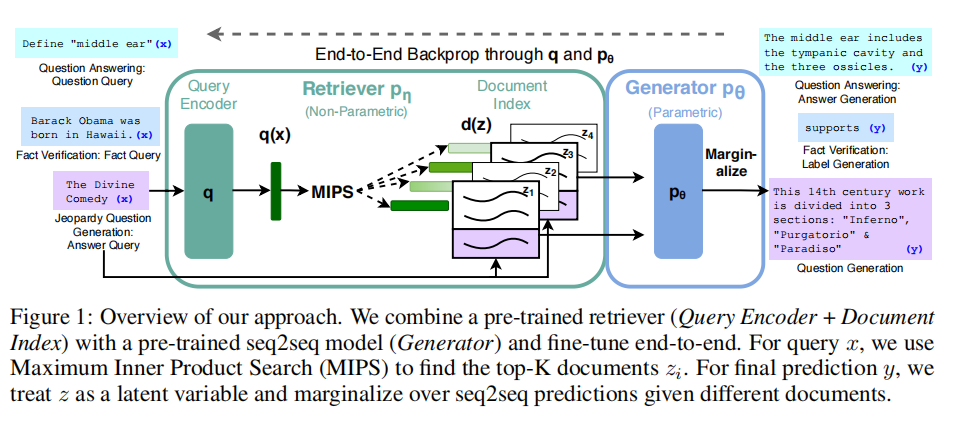
这个架构显然和现在的RAG是完全一样的,query-encoder就是一个向量表征模型,后续存入库中,就可以做向量召回,MIPS就是最近邻检索,也就是所谓的向量检索了(有关向量召回和向量检索的概念,可以参考这篇:),而后对top-K文章,可以进行拼接,交给seq2seq模型进行预测。
在此基础上,作者进一步阐述了RAG结构的优势,省去论证讨论的话术,这里我直接说作者提及的结论:
知识更新层面,RAG能够快速拓展或者更新知识。参数和非参数记忆组件都是预先训练并预先加载了广泛的知识,无需额外训练就可以获得新知识。
生成内容层面,RAG相比直接生成,内容会更加真实、具体和多样。
模型
从上面的图可以看到,整个模型的核心组件就是两个。
一个检索器,给定输入的query ,输出top K相似度的文档。
一个生成器,基于检索器的返回的文档以及query ,给出最终的回复结果。
模型结构是类似的,但是根据训练和使用策略的不同,文章中提出了两种方案,RAG-Sequence和RAG-Token,其实对应的是两种映射关系,一个是用单个文档预测出序列输出的结果,另一个是基于单个token,用多个文章综合预测出结果。
这里就可以看到,两者的区别就在于,一个是先积再和,一个是先和再积,具体两者有什么效果上的区别,后续作者会做实验。
在模型的选用上,基本都是选用比较常见的方案了。检索上,作者从简是选择了BERT的向量化,用的DPR方案(Dense passage retrieval for open-domain question answering),在当时的视角也并不算一个落后的方案,类似simcse是21年才出来的(EMNLP21),而生成器,选用了BART( BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension)。
训练上,文章选用的方案是联合训练,即联合检索器和生成器一起训练,直接对端到端的和进行训练。值得注意的是,联合训练的过程,因为检索的编码器,也就是DPR那个模型的文档编码器会更新,这导致检索的索引也需要伴随更新,为了降低这块的性能要求,此处就对doc的文档编码器就不更新,只更新对query的编码器,生成器照常更新。
解码是文本生成的重要一步,对RAG-Sequence和RAG-Token有不一样的操作方法,后者直接用beam search即可,而前者则不可以,而是采用了“彻底解码”和“快速解码”两个方式来分别解决短句和长句的解码问题。
实践细节和实验
首先是实践上,作者使用的是维基百科数据,每篇文章会被切分,用编码器进行编码,然后存入FAISS中方便检索。
实验上,作者设计了开放域问答、抽象问答(自由文本问答)、Jeopardy问答(直译是危险,但感觉不像,这里是指猜实体,例如In 1986 Mexico scored as the first country to host this international sports competition twice的答案是The World Cup)、事实验证这4个任务来判断RAG的具体能力,并借助消融实验判断RAG中各个设计对最终效果的影响。
实验结果就不过多赘述,不过作者在这里的一些发现我想拿出来分享一下。
即使RAG抽取出来的文档相关但不包含答案,仍对最终效果有收益。甚至即使没检索到正确文档,RAG仍能得到更优的结果。
RAG的幻觉似乎比直接生成(BART)要少,而且多样性也更高。
RAG在特定任务场景,更不需要对中间的检索进行训练。
索引支持热更新,能让模型更敏捷地更新知识。
对文档的检测数量,作者也进行了实验,RAG-Sequence对召回文档数量的性能影响不大,感觉很可能因为最后的加权稀释,影响变小而且趋于稳定,但对RAG-Token会有些明显,一般文档越多效果越好。
检索模块作者只是用了BM25作对比,感觉有些受限,不过从最终的结果看来,随着任务的变化,在一些任务中差距可能会很大,但也有好几个任务来看效果差距并不是很大,甚至可能比向量召回还要好。
分析讨论
这篇文章从现在的视角看,能有如下启发:
即使是小模型,经过训练,仍然能很大程度能理解灌入的知识,并借助知识的支持回答问题。
RAG中的R和G存在联合训练的可能,并且联合训练对最终的结果输出是有收益的,现在我们如果要对RAG效果做提升,也可以考虑这个方案。
检索模块的返回,即使并非正确,但只要相关,就有可能对最终结果产生收益,当然如果能正确,收益会更加大。
思路要拓宽,向量召回不是唯一方法,类似BM25之类的字面方案,也是有收益的。
当然对比现在的大模型,大模型目前有更好的底子,对知识的处理不那么依赖训练了,而是大模型本身就有知识处理、理解的能力,从而降低了联合训练的必要性,当然了,考虑到大模型的成本,为了压缩成本也可以考虑用大模型做预标注之类的手段辅助做小模型的训练支撑,也是一个思路。