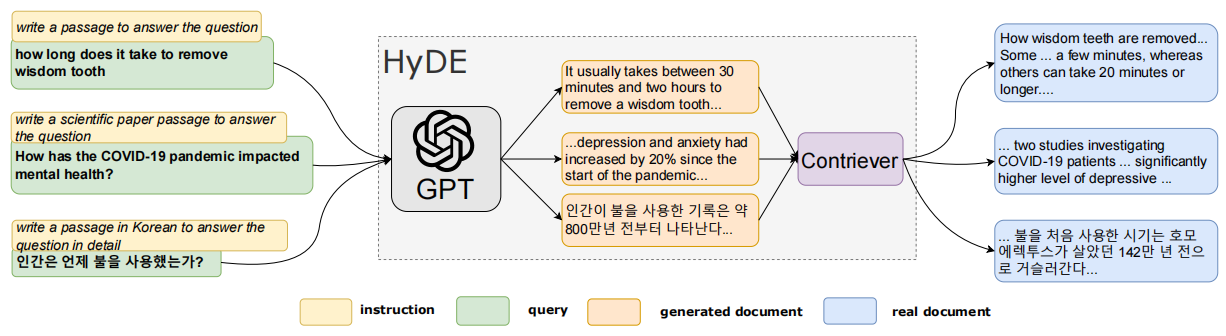
论文:Query Rewriting in Retrieval-Augmented Large Language Models
⭐⭐⭐⭐
EMNLP 2023
Code: github.com/xbmxb/RAG-query-rewriting
一、论文速读
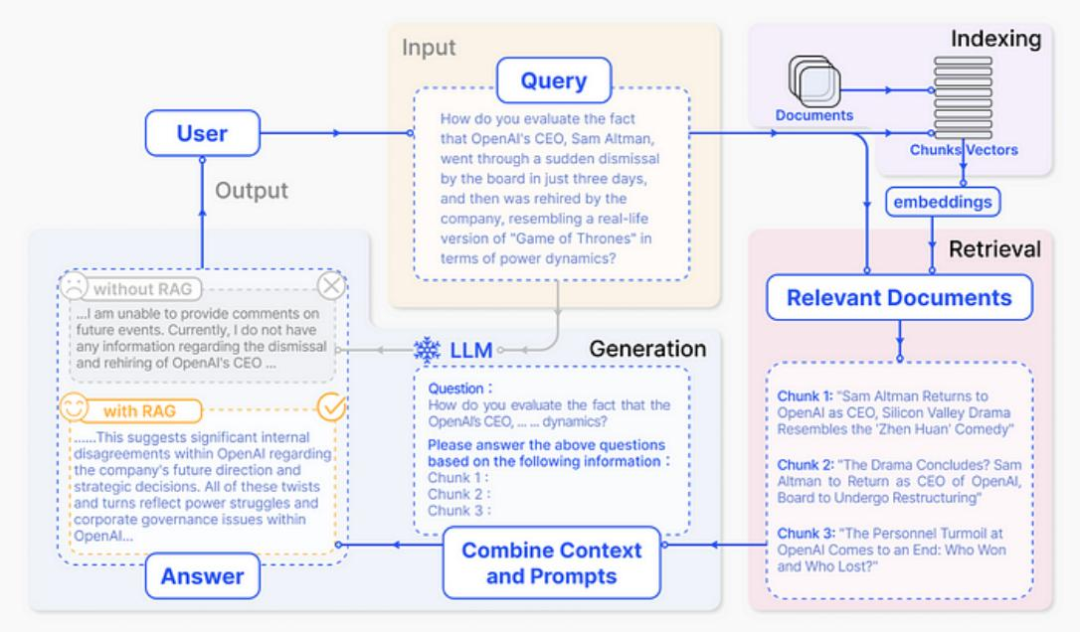
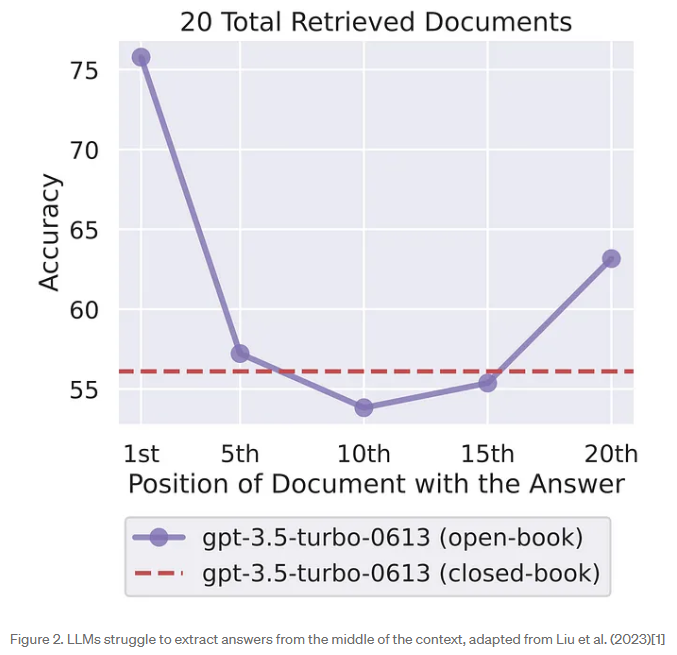
如下是一个常见的 RAG pipeline:
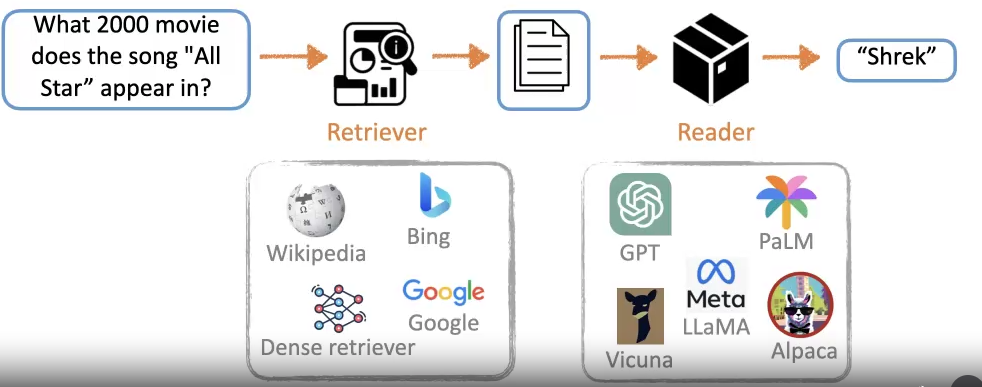
但这存在一个缺点:input text 和需要 query 的 knowledge 之间不可避免地会存在一个 gap。
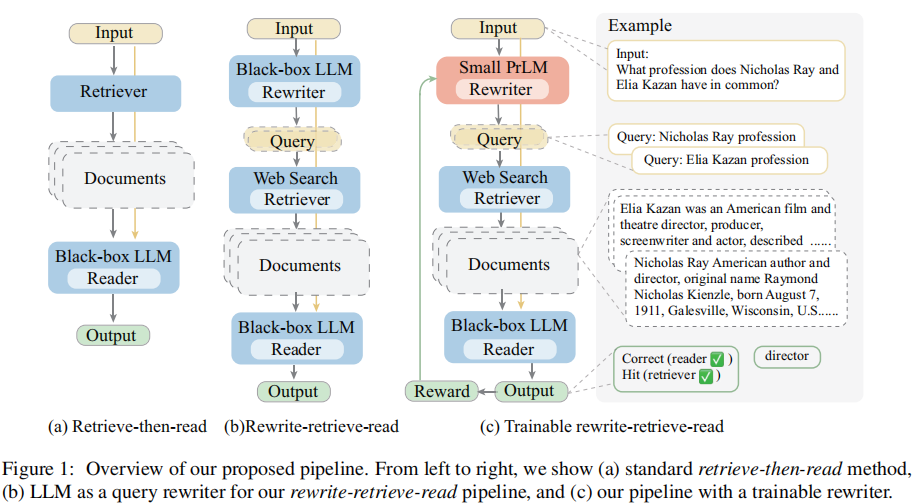
本文提出:在将 query 输入给 retriever 之前,增加一个 query rewrite 步骤来弥补这个 gap:

这样,就把之前 RAG 的 retrieve-then-read 改为了 Rewrite-Retrieve-Read 的框架。
同时,根据 rewriter 的技术选型,这里又分成了两种:
- 将 LLM 作为 query rewriter:由于 LLM 往往是不可训练的(比如 ChatGPT),所以 LLM 可以视作一个 black-box,由它来执行 query rewrite
- 可训练的 rewrite-retrieve-read:将一个小的 LM 作为 query rewriter,同时根据 reader 的 output 是否 correct 或者 hit 来作为对 rewriter 的反馈,进而对 query rewriter 做强化学习来训练 rewriter
如下图所示:
二、实验结果
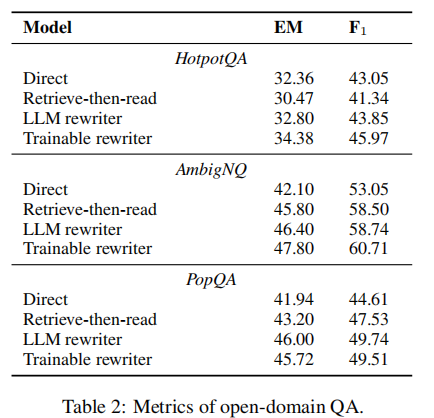
可以看到,无论将 frozen LLM 还是 trainable LM 作为 rewriter,都可以改进 RAG 的效果。
论文也给出了使用不同方法时的 prompt:

三、总结与分析
本文提出了使用 query rewrite 来改进 RAG 的 pipeline 来提高表现,同时给出了一个可训练的 rewriter 的训练思路。
同时,本文的研究还存在以下限制:
- 在下游任务上,仍然需要一个 generalization 和 specialization 的 trade-off。因为目前额外增加了一个训练过程,让该方法相比于 in-context learning 的 scalability 降低了。
- 在知识密集型的场景下,使用 web search engine 可能不如经过过滤的 knowledge base 更加专业好用。