🦐在指定目录下显示目录结构
!tree -L 显示级数限制 指定目录如:
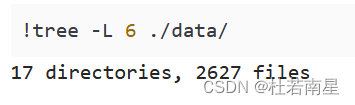
!tree -L 3 ./data/
表示:在目录 ./data/ 下显示目录结构,限制显示到第三级子目录或文件。这个命令通常在命令行环境(即shell)下使用,用于查看目录结构,以便更好地了解目录中包含的文件和子目录。

🦐将指定路径下的ZIP文件解压缩到目标路径下(unzip_data)
import zipfile
def unzip_data(src_path,target_path):
# 解压原始数据集,将src_path路径下的zip包解压至target_path目录下
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
unzip_data('data/data19638/insects.zip','data/data19638/insects')
unzip_data('data/data55217/Zebra.zip','data/data55217/Zebra')导入
zipfile模块,提供对zip文件的读取和解压缩功能定义了一个叫
unzip_data的函数参数
src_path:指定要解压的zip文件的路径参数
target_path:指定要将解压后的文件放置到的目标路径函数内部
首先通过
os.path.isdir(target_path)检查目标路径是否存在,如果不存在,则创建目标路径然后使用
zipfile.ZipFile(src_path, 'r')打开指定路径下的ZIP文件,使用读模式调用
z.extractall(path=target_path)方法将ZIP文件解压缩到目标路径下最后使用
z.close()关闭ZIP文件对象,释放资源
解压缩后调用tree指令查看结果:
🦐统计给定目录下所有不同文件类型的文件数量以及它们的总内存占用量(get_size_type)
import os
"""
通过给定目录,统计所有的不同子文件类型及占用内存
"""
size_dict = {}
type_dict = {}
def get_size_type(path):
files = os.listdir(path)
for filename in files:
temp_path = os.path.join(path, filename)
if os.path.isdir(temp_path):#是文件夹
# 递归调用函数,实现深度文件名解析
get_size_type(temp_path)
elif os.path.isfile(temp_path):#是文件
# 获取文件后缀
type_name=os.path.splitext(temp_path)[1]
#无后缀名的文件
if not type_name:
type_dict.setdefault("None", 0)
type_dict["None"] += 1
size_dict.setdefault("None", 0)
size_dict["None"] += os.path.getsize(temp_path)
# 有后缀的文件
else:
type_dict.setdefault(type_name, 0)
type_dict[type_name] += 1
size_dict.setdefault(type_name, 0)
# 获取文件大小
size_dict[type_name] += os.path.getsize(temp_path) 定义了两个空字典
size_dict和type_dict,用于分别记录不同文件类型的内存占用和数量定义了一个函数
get_size_type(path),该函数接受一个参数path,表示要统计的目录路径使用
os.listdir(path)获取指定路径下的所有文件和文件夹列表遍历列表中的每个文件和文件夹,使用
os.path.join(path, filename)构建完整的文件路径如果是文件夹,则递归调用
get_size_type(temp_path)来处理子文件夹如果是文件,则获取其文件后缀名,并根据是否有后缀名进行处理:
如果没有后缀名,则将其归类为"None"类型,并更新对应的数量和占用内存大小
如果有后缀名,则将其归类到对应的后缀名类型,并更新对应的数量和占用内存大小
统计完成后,size_dict和type_dict分别记录了不同文件类型的总内存占用和数量
🦐应用
path= "data/"
get_size_type(path)
for each_type in type_dict.keys():
print ("%5s下共有【%5s】的文件【%5d】个,占用内存【%7.2f】MB" %
(path,each_type,type_dict[each_type],\
size_dict[each_type]/(1024*1024)))
print("总文件数: 【%d】"%(sum(type_dict.values())))
print("总内存大小:【%.2f】GB"%(sum(size_dict.values())/(1024**3)))设置要统计的目录路径
调用
get_size_type函数,统计该目录下所有不同文件类型的文件数量以及它们的总内存占用量使用
for循环遍历type_dict字典中的每个键(即文件类型),并打印出文件类型、文件数量以及占用内存大小的信息通过
sum(type_dict.values())统计所有文件的总数,通过sum(size_dict.values())统计所有文件的总内存占用量将结果打印出来,其中内存大小单位转换为GB
机器学习还有python我接触的有点少,对我来说还是有难度的,如果有问题欢迎大家的指正,欢迎大家和我一起学习百度松果菁英班的机器学习内容,有问题我们随时评论区见~
⭐点赞收藏不迷路~































![P8749 [蓝桥杯 2021 省 B] 杨辉三角形](https://img-blog.csdnimg.cn/img_convert/75b5f627d9313517554a0187ab3c6258.jpeg)