本文系列主要作用就是读书笔记,自己看的话比较杂,没怎么归类过,所以现在跟着这个分类走一遍。本文主要内容为前两章,特征工程和模型评估。
如果我想起一些相关的内容也会做适当的补充,主打就是一个intuition(感觉除了数学表示之外,intuition最重要了,虽然比起数学表达更抽象了,但是对人来说更好记忆和理解)
特征工程
特征工程师对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展示数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂志和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
个人理解是,就是把原始数据改成能用的。比如清理数据,比如做one-hot encoding,比如做降维等等。
结构化数据:可以看做关系型数据库的一张表,每一列都有清晰的定义,包含了数值型、类别型两种基本类型;每一行数据表示一个样本信息。
非结构化数据:主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同
特征归一化
为了消除数据特征之间的量纲影响,使得不同指标之间具有可比性。比如人的身高和体重,假设身高用毫米为单位,体重用千克做单位,那两者的数据差异在1000倍左右,在做梯度下降的时候显然会出现zigzag(也就是在身高的方向上走多点,在体重上走少点),首先这会造成找到weight的过程很曲折,而且万一走到局部最优呢,就很尴尬了。同时这也会对weight有影响,比如都差1000倍了,那身高显然就没啥影响了,一个1000+,一个就1.5左右,那这个1.5的有没有也就跟加不加bias没差了。
为什么要对数值类型的特征做归一化
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,
为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
如何理解归一化(normalization)? - 知乎 (zhihu.com)
这里补充一下一些normalization的方法,在之前的学习中我们看到过batch normalization和layer normalization的区别,其中batch normalization是针对每个加载进来的batch,对其中的每一个特征做归一化,而layer normalization是对每一个样本做归一化。换言之就是batch normalization保持了同一个特征下的样本之间的大小关系,而layer normalization保持了同一个样本之中的各个特征的大小关系(很好理解用layer normalization而不用batch normalization的原因,为了保留样本的信息,比如做NLP的时候,一句话用了哪些token,这个肯定是要保留的信息)
深度学习笔记(二):Normalization(原因、BN、WN、LN、IN、权重数据伸缩不变性)_`2 normalization-CSDN博客

常用的归一化方法
- 线性函数归一化(min-max scaling)
对原始数据进行线性变换,是结果映射到[0, 1]的范围,实现对原数据的等比缩放。归一化公式:- 零均值归一化(Z-score normalization)
将原始数据映射到均值为0,标准差为1的分布上。归一化公式:
这个书里给的不是很详细,可以参考如何理解归一化(normalization)? - 知乎 (zhihu.com)
数据预处理之Normalization - 知乎 (zhihu.com)
最大最小标准化(Min-Max Normalization)
(1) 线性函数将原始数据线性化的方法转换到[0 1]的范围, 计算结果为归一化后的数据,X为原始数据
(2) 本归一化方法比较适用在数值比较集中的情况;
(3) 缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围
z—score 标准化
(1) 将原始数据集归一化为均值为0、方差1的数据集
(2) 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。并且所有样本数据均要大于等于1。
机器学习中的标准化和归一化方法 | J. Xu (xujinzh.github.io)
类别型特征
在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于logistic regression、SVM等模型,类别型特征必须经过处理转换成数值型特征才能正常工作。
在对数据进行预处理时,应该怎样处理类别型特征?


- 序号编码。按程度、大小关系进行编码,有点类似于赋分制,拿优秀就给95分,拿良好就给80分,拿及格就给60这样。
- one-hot编码,按照有没有、是不是进行编码,比如性别,就可以分成男性、女性、沃尔玛购物袋(×),one-hot的意思就是变成是不是男性(是:1,不是:0),是不是女性(是:1,不是:0)
- 二进制编码,类似序号编码,不过是二进制形式,比如8个类别,不用1-8表示,用000-100表示。
【补充】决策树
一文看懂决策树(Decision Tree) - 知乎 (zhihu.com)
【决策树】深入浅出讲解决策树算法(原理、构建)_决策树算法原理-CSDN博客
【机器学习sklearn】决策树(Decision Tree)算法_sklearn中决策树是什么算法-CSDN博客
sklearn的决策树能够处理字符串数据吗吗?_决策树特征里面不能有字符型吗-CSDN博客
machine learning - strings as features in decision tree/random forest - Data Science Stack Exchange
似乎如果决策树使用sklearn还是要做编码。
决策树要做的就是做决策来把类别分开,比如分辨谁会去买奶茶,我们先决策,喜欢甜食的人会购买,那么人群就被分成两部分,喜欢甜食,不喜欢甜食;然后再对不喜欢甜食的人分,有朋友喜欢甜食的人,可能会给朋友买奶茶,又分两类,这样。
只不过做决策的方式是计算机来做,分类的指标是信息熵增益大/gini小
高维组合特征的处理
什么是组合特征?如何处理组合特征?


怎样有效地找到组合特征?


文本表示模型
感觉这里书给的不怎么样orz。
有哪些文本表示模型?它们各有什么优缺点?
有哪些文本表示模型,它们各有什么优缺点? - 知乎 (zhihu.com)
词袋模型
词向量之词袋模型(BOW)详解_bow词袋模型-CSDN博客
词袋模型(Bag-of-Words model,BOW)BoW(Bag of Words)词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定对于一个文本,忽略其词序和语法、句法,仅仅将其看做是一些词汇的集合,而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子(因为里面装的都是词汇,所以称为词袋,Bag of words即因此而来),然后看这个袋子里装的都是些什么词汇,将其分类。
比如在一篇文章的袋子里面,看到各种各样的专业术语,我们倾向于这是一篇专业的文章,我们看到一个袋子里装的都是柴米油盐酱醋茶,我们肯定觉得这是一个讲生活的文章,非常符合人类的认知。

显然能看出来,这样完全没有重要性的区别,也没有顺序。如果是“小猫和小狗是好朋友”那么“小狗和小猫是好朋友”没什么大问题,但是如果是“小明这次考试没有考过小红”,变成“小红这次考试没有考过小明”,明显语义信息就没有得到保留了。(当然这也限制了使用场景,我记得在学校作业里这个只是用来对新闻文本分类的,没要求我理解每个文章是什么意思)
TF-IDF
机器学习:生动理解TF-IDF算法 - 知乎 (zhihu.com)
用来解决BOW没有重要性的问题,比如一篇文章里面出现“的”、“是”这种没有实际作用的词很多(就像英文里出现“is”,“there”这种不会影响判断的词)。
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词,而且算法简单高效,常被工业用于最开始的文本数据清洗。
TF-IDF有两层意思,一层是"词频"(Term Frequency,缩写为TF),另一层是"逆文档频率"(Inverse Document Frequency,缩写为IDF)。
TF:某个词在文章中出现的次数
IDF:越常见的词给的权重越低
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。

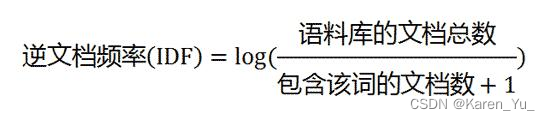
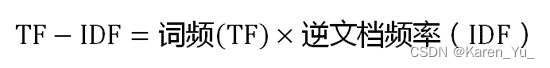
优缺点
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。如果要体现词的上下文结构,那么你可能需要使用word2vec算法来支持。
简要来说,就是可以在一定程度上体现一个词的重要性,但是仅仅靠词的组合是无法体现句意/文意的,也就是我们需要上下文信息来实现更复杂的算法。
N-gram

自然语言处理中N-Gram模型介绍 - 知乎 (zhihu.com)
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。



总结一下,有点类似于词语联想,在手机上打字的时候,输入一个字之后后面会出现一些联想词,比如输入“回”,大概率后面就有“家”,这样,就是说某个词后面出现某个词的概率。
这里就开始有上下文了。
不过这个显然也有问题啊,一个是看的范围少,一个是需要统计的也太多了吧,上哪儿穷举去,太离谱了,肯定慢啊。
word embedding
万物皆可Embedding之Word Embedding - 知乎 (zhihu.com)
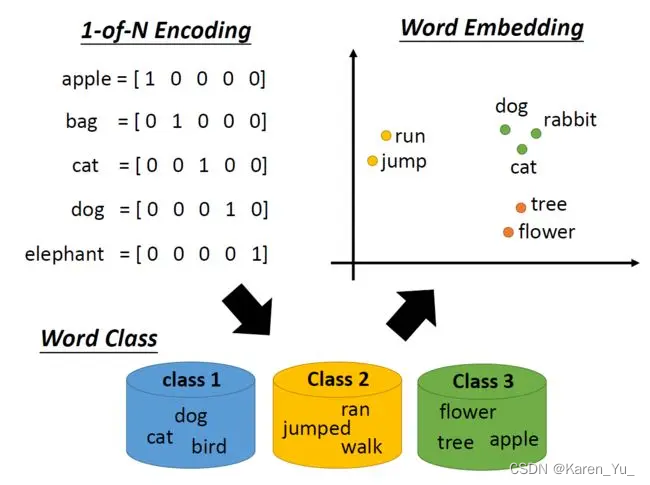
相似意思的接近。
现有的机器学习方法往往无法直接处理文本数据,因此需要找到合适的方法,将文本数据转换为数值型数据,由此引出了Word Embedding(词嵌入)的概念。
词嵌入是自然语言处理(NLP)中语言模型与表征学习技术的统称,它是NLP里的早期预训练技术。它是指把一个维数为所有词的数量的高维空间嵌入到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量,这也是分布式表示:向量的每一维度都没有实际意义,而整体代表一个具体概念。
分布式表示相较于传统的独热编码(one-hot)表示具备更强的表示能力,而独热编码存在维度灾难和语义鸿沟(不能进行相似度计算)等问题。传统的分布式表示方法,如矩阵分解(SVD/LSA)、LDA等均是根据全局语料进行训练,是机器学习时代的产物。
Word Embedding的输入是原始文本中的一组不重叠的词汇,假设有句子:apple on a apple tree。那么为了便于处理,我们可以将这些词汇放置到一个dictionary里,例如:[“apple”, “on”, “a”, “tree”],这个dictionary就可以看作是Word Embedding的一个输入。
Word Embedding的输出就是每个word的向量表示。对于上文中的原始输入,假设使用最简单的one hot编码方式,那么每个word都对应了一种数值表示。例如,apple对应的vector就是[1, 0, 0, 0],a对应的vector就是[0, 0, 1, 0],各种机器学习应用可以基于这种word的数值表示来构建各自的模型。当然,这是一种最简单的映射方法,但却足以阐述Word Embedding的意义。
用一个vector来代替某个词,关于这个vector怎么表示方法很多样。
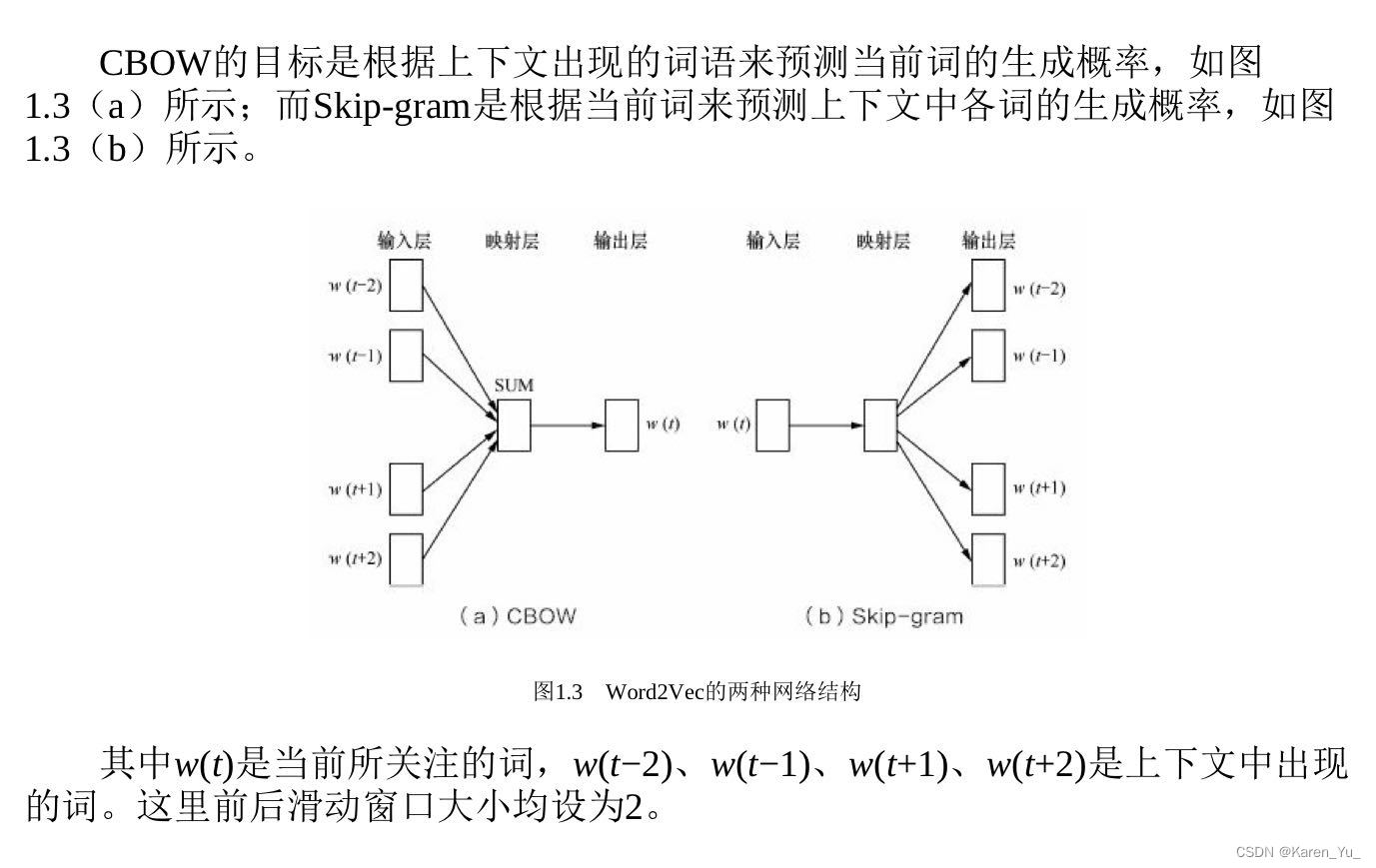
Word2Vec
常用的词嵌入模型之一,是一个浅层的生姜网络模型,有两种网络结构,分别是CBOW(continues bag of word)和skip-gram


Word2Vec是如何工作的?
[NLP] 秒懂词向量Word2vec的本质 - 知乎 (zhihu.com)
深入浅出Word2Vec原理解析 - 知乎 (zhihu.com)
万物皆可Embedding之Word Embedding - 知乎 (zhihu.com)
为了更好的了解模型深处的原理,我们先从Simple CBOW model(仅输入一个词,输出一个词)框架说起。
- input layer输入的X是单词的one-hot representation
- 输入层到隐藏层之间有一个权重矩阵W,隐藏层得到的值是由输入X乘上权重矩阵得到的(细心的人会发现,0-1向量乘上一个矩阵,就相当于选择了权重矩阵的某一行,如图:输入的向量X是[0,0,1,0,0,0],W的转置乘上X就相当于从矩阵中选择第3行[2,1,3]作为隐藏层的值);
- 隐藏层到输出层也有一个权重矩阵W',因此,输出层向量y的每一个值,其实就是隐藏层的向量点乘权重向量W'的每一列,比如输出层的第一个数7,就是向量[2,1,3]和列向量[1,2,1]点乘之后的结果;
- 最终的输出需要经过softmax函数,将输出向量中的每一个元素归一化到0-1之间的概率,概率最大的,就是预测的词。
对比可以发现,和simple CBOW不同之处在于,输入由1个词变成了C个词
Skip-gram model是通过输入一个词去预测多个词的概率。输入层到隐藏层的原理和simple CBOW一样,不同的是隐藏层到输出层,损失函数变成了C个词损失函数的总和,权重矩阵W'还是共享的。
一般神经网络语言模型在预测的时候,输出的是预测目标词的概率,也就是说我每一次预测都要基于全部的数据集进行计算,这无疑会带来很大的时间开销。不同于其他神经网络,Word2Vec提出两种加快训练速度的方式,一种是Hierarchical softmax,另一种是Negative Sampling。


embedding的问题:

CBOW(Continuous Bag-of-Words Model)和Skip-gram (Continuous Skip-gram Model),是Word2vec 的两种训练模式。
CBOW
通过上下文来预测当前值。相当于一句话中扣掉一个词,让你猜这个词是什么。
Skip-gram
用当前词来预测上下文。相当于给你一个词,让你猜前面和后面可能出现什么词。
优化方法
为了提高速度,Word2vec 经常采用 2 种加速方式:
- Negative Sample(负采样)
- Hierarchical Softmax
Word2vec 的优缺点
需要说明的是:Word2vec 是上一代的产物(18 年之前), 18 年之后想要得到最好的效果,已经不使用 Word Embedding 的方法了,所以也不会用到 Word2vec。
优点:
- 由于 Word2vec 会考虑上下文,跟之前的 Embedding 方法相比,效果要更好(但不如 18 年之后的方法)
- 比之前的 Embedding方 法维度更少,所以速度更快
- 通用性很强,可以用在各种 NLP 任务中
缺点:
- 由于词和向量是一对一的关系,所以多义词的问题无法解决。
- Word2vec 是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化



Word2Vec和LDA有什么区别和联系?
Word2Vec和LDA的区别与联系 - 早起的小虫子 - 博客园 (cnblogs.com)Word2vec的词聚类结果与LDA的主题词聚类结果,有什么不同? - 知乎 (zhihu.com)
Word2Vec与LDA的区别和联系_lda和word2vec-CSDN博客
Word2Vec主要包含两个模型,一个是CBOW模型,上下文预测中间词,还有一个是SG模型,中间词预测上下文,Word2Vec通过训练这两个模型,得到模型训练的副产物-词向量。
LDA是基于文档中单词的共现关系来对单词进行主题聚类,或者说是对“文档-单词”矩阵进行分解为“文档-主题”和“主题-单词”。
接下来我们对其区别和联系进行具体分析:
Word2Vec生成的词向量,由于词向量信息的丰富,不同词向量之间会存在一定的联系,那么其实也可以被理解为一种聚类,那么这样就和LDA的主题词聚类对应上了。
Word2Vec是基于上下文的,而LDA是基于隐含的主题的,从更细节的角度去理解,Word2Vec里关注的更多是语义、语法级别的信息,而LDA关注的是更高的level-文章主题信息。甚至可以说Word2Vec关注细粒度信息,而LDA关注粗粒度。
简单的说,词向量所体现的是语义(semantic)和语法(syntactic)这些 low-level的信息。而LDA的主题词表现的是更 high-level的文章主题(topic)这一层的信息。
所以Word2vec的一些比较精细的应用,LDA是做不了的。比如:
1)计算词的相似度。同样在电子产品这个主题下,“苹果”是更接近于“三星”还是“小米”?
2)词的类比关系:vector(小米)- vector(苹果)+ vector(乔布斯)近似于 vector(雷军)。
3)计算文章的相似度。这个LDA也能做但是效果不好。而用词向量,即使在文章topic接近的情况下,计算出的相似度也能体现相同、相似、相关的区别。
反过来说,想用词向量的聚类去得到topic这一级别的信息也是很难的。很有可能,“苹果”和“小米”被聚到了一类,而“乔布斯”和“雷军”则聚到另一类。
这种差别,本质上说是因为Word2vec利用的是词与上下文的共现,而LDA利用的是词与文章之间的共现。
作者:Xiaoran
链接:https://www.zhihu.com/question/26680505/answer/34014109
Word2Vec和LDA的联系:
1、在方法模型上,他们两者是不同的,但是产生的结果从语义上来说,都是相当于近义词的聚类,只不过LDA是基于隐含主题的,WORD2VEC是基于词的上下文的,或者说LDA关注doc和word的共现,而word2vec真正关注的是word和context的共现。
2、主题模型通过一定的结构调整可以基于”上下文-单词“矩阵进行主题推理。同样的,词嵌入方法也可以根据”文档-单词“矩阵学习出词的隐含向量表示。
3、加入LDA的结果作为word embeddings的输入,可以增强文章分类效果。
看了一下基本的描述,本质上压根不是干一个事的,LDA应该更偏向于high-level的理解(比如文章的种类),而Word2Vec则更关注单词本身的语义。
很震惊的点在于学校讲LDA的时候压根没提这和词有什么关系,本质上就是将数据从高维投影到低维的方法,感觉就是个降维和分类的(这很合理,因为在上述的描述中LDA就是通过把各个单词聚在一起,让不同类型的文章有不同的词语的聚类,所以显然这并不是)
机器学习-LDA(线性判别降维算法) - 知乎 (zhihu.com)
请参考上述链接(我倾向于认为这并不是一个好的题目)
图像数据不足时的处理方法
(直接加数据不就好了吗:×)
在图像分类任务中,训练数据不足会带来什么问题?
【机器学习与深度学习理论要点】04.训练数据不足带来的问题及解决方法?_训练数据不足,请减小上下文长度或增加训练数据-CSDN博客
05-训练数据不足的影响及处理方式 - 赵家小伙儿 - 博客园 (cnblogs.com)
具体到分类任务上,训练数据不足带来的问题主要体现在过拟合方面。即模型在训练样本上的效果可能不错,但在测试数据集上泛化效果不佳
数据不足怎么处理?
机器学习笔试面试之图像数据不足时的处理方法、检验方法、不均衡样本集的重采样 - 知乎 (zhihu.com)
具体到图像分类任务中,在保持图像类别不变的前提下,可以对训练集中的每幅圄像进行以下变换。
- 一定程度内的随机旋转、平移、缩版、裁剪、填充、左右翻转等,这些变换对应着同一个目标在不同角度的观察结果。
- 对图像中的像素添加躁声扰动。
- 颜色变换
- 改变图像的亮度、清晰度、对比度、锐度等。
CV — 目标检测:数据增强_目标检测数据集增强-CSDN博客
目标检测图像增强方法(Data Augmentation)_目标检测中的图像增强-CSDN博客
一个有效的小目标检测的数据增强方法Mixup及其变体填鸭式_小目标增强-CSDN博客
模型评估
掏出之前的笔记

常见评估指标
总结详见上图。
下面尽量找一下当时看的内容:
一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC - AIQ (6aiq.com)
机器学习的评价指标(一):Accuracy、Precision、Recall、F1 Score - 知乎 (zhihu.com)
一文看懂机器学习指标:准确率、精准率、召回率、F1、ROC曲线、AUC曲线 (easyai.tech)
余弦距离的应用




总结一下,其实这是在回答几个问题:
- 什么是余弦距离
- 为什么要用余弦距离
- 余弦距离与其他距离有什么区别
- 各种距离的使用场景是什么
机器学习中的数学——距离定义(八):余弦距离(Cosine Distance)-CSDN博客
余弦距离(Cosine Distance)也可以叫余弦相似度。 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。
余弦取值范围为[ −1 , 1],求得两个向量的夹角,并得出夹角对应的余弦值,此余弦值就可以用来表示这两个向量的相似性。夹角越小,趋近于0度,余弦值越接近于1,它们的方向更加吻合,则越相似;当两个向量的方向完全相反夹角余弦取最小值-1;当余弦值为0时,两向量正交,夹角为90度。因此可以看出,余弦相似度与向量的幅值无关,只与向量的方向相关。
比如DNA和脱氧核糖核酸,长度不一样,但是理论上距离应该很近。
再比如,我们看两个人的行为(去图书馆的次数,在图书馆待的总时长),A是(1, 120),B是(10, 1200),可以看出两个人在图书馆停留的平均时长都是一样的,但是明显B看起来更卷王一点。
如果是计算欧氏距离:
1166481
如果计算余弦距离就是:
0.000006943962225
因此可以看出,不同的距离实际上是为了衡量不同的相似程度。
A/B测试
暂时不考虑做这段的笔记,和生物实验设计差不多,主打就是一个控制变量
超参数调优
sklearn.model_selection.GridSearchCV — scikit-learn 1.4.0 documentation
sklearn.model_selection.RandomizedSearchCV — scikit-learn 1.4.0 documentation
API Reference — scikit-learn 1.4.0 documentation
还有很多其他的,自取
后期会补充:各个方法之间的区别和联系
过拟合和欠拟合
过拟合的解决策略
- 获得更多的数据
- 降低模型的复杂度(增加线性,降低非线性,即variance↓,bias↑)
神经网络中可以减少网络层数、神经元个数、决策树则可以降低树的深度,剪枝等 - 正则化(加penalty)
欠拟合的解决策略
- 增加特征
- 增加模型复杂度
- 减少正则化系数
这个答案给的不太好,建议忽略。可以参考下面这篇文章:
欠拟合和过拟合出现原因及解决方案 - 范中豪 - 博客园 (cnblogs.com)
附录:梯度消失和梯度爆炸
发现这个很经常被问到哎。结果书里好像没有提到,有点尴尬 ̄□ ̄||
一般而言,这类问题都是两方面,是什么引起的,怎么做可以缓解。我想再添一个方面,为什么能缓解(这是一个相当intuition的问题orz,因为我没办法给出实验or数学表达式上的推导,但是如果不问为什么能缓解,就觉得没有解决前面两个问题)
是什么
梯度爆炸
在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。 网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。 梯度爆炸引发的问题 在深度多层感知机网络中,梯度爆炸会引起网络不稳定,最好的结果是无法从训练数据中学习,而最坏的结果是出现无法再更新的 NaN 权重值。
The exploding gradient problem describes a situation in the training of neural networks where the gradients used to update the weights grow exponentially. This prevents the backpropagation algorithm from making reasonable updates to the weights, and learning becomes unstable.
爆炸梯度问题描述了神经网络训练中用于更新权值的梯度呈指数增长的情况。这使得反向传播算法无法对权重进行合理的更新,并且学习变得不稳定。
梯度消失
和爆炸梯度一样,消失梯度很大程度上是由Wt - k引起的。如果|W|<1,则|Wt−k|会迅速缩小到0,特别是在s型非线性的情况下。对于之前的长距离步骤,梯度将变为0,这使得RNN很难学习长距离依赖关系。消失梯度比爆炸梯度问题更大,因为它不仅是RNN的普遍问题,而且是任何多层深度神经网络的普遍问题。
The vanishing gradient problem describes a situation encountered in the training of neural networks where the gradients used to update the weights shrink exponentially. As a consequence, the weights are not updated anymore, and learning stalls.
梯度消失问题描述了神经网络训练中遇到的一种情况,即用于更新权重的梯度呈指数级缩小。结果,权重不再更新,学习就停滞了。
为什么
【梯度消失】经常出现,产生的原因有:一是在深层网络中,二是采用了不合适的损失函数,比如sigmoid。当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。
【梯度爆炸】一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
梯度爆炸会伴随一些细微的信号,如:①模型不稳定,导致更新过程中的损失出现显著变化;②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
- 深层网络
由于深度网络是多层非线性函数的堆砌,整个深度网络可以视为是一个复合的非线性多元函数(这些非线性多元函数其实就是每层的激活函数),那么对loss function求不同层的权值偏导,相当于应用梯度下降的链式法则,链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数传播。
如果接近输出层的激活函数求导后梯度值大于1,那么层数增多的时候,最终求出的梯度很容易指数级增长,就会产生梯度爆炸;相反,如果小于1,那么经过链式法则的连乘形式,也会很容易衰减至0,就会产生梯度消失。
从深层网络角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则,属于先天不足。
由于深层网络+链式法则,如果梯度超过或者低于某个阈值的情况连续发生,那么就会导致数值上的问题- 激活函数
这个是梯度消失的原因:如果使用sigmoid作为激活函数(引用的文章应该写错了),那么其天然的就带来了小的梯度,就更容易在链式求导的时候使得梯度值滑向0
- 初始权重过大
这个是梯度爆炸的原因:初始权重很大,使得求导时出现大于1的情况



怎么做
解决方案1-预训练加微调
此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。Hinton在训练深度信念网络(Deep Belief Networks中,使用了这个方法,在各层预训练完成后,再利用BP算法对整个网络进行训练。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
解决方案2-梯度剪切、正则化
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
注:在WGAN中也有梯度剪切限制操作,但是和这个是不一样的,WGAN限制梯度更新信息是为了保证lipchitz条件。
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization)比较常见的是l1正则,和l2正则,在各个深度框架中都有相应的API可以使用正则化。
解决方案3-relu、leakrelu、elu等激活函数
Relu:思想也很简单,如果激活函数的导数为1,那么就不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。先看一下relu的数学表达式:
relu的主要贡献在于:
- 缓解了梯度消失、爆炸的问题
- 计算方便,计算速度快
- 加速了网络的训练
同时也存在一些缺点:
由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)
输出不是以0为中心的
解决方案4-batchnorm/批规范化
Batchnorm是深度学习发展以来提出的最重要的成果之一了,目前已经被广泛的应用到了各大网络中,具有加速网络收敛速度,提升训练稳定性的效果,Batchnorm本质上是解决反向传播过程中的梯度问题。batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1保证网络的稳定性。
解决方案5-残差结构
残差结构说起残差的话,不得不提这篇论文了:Deep Residual Learning for Image Recognition,关于这篇论文的解读,可以参考机器学习算法全栈工程师知乎专栏文章链接:https://zhuanlan.zhihu.com/p/31852747这里只简单介绍残差如何解决梯度的问题。
事实上,就是残差网络的出现导致了image net比赛的终结,自从残差提出后,几乎所有的深度网络都离不开残差的身影,相比较之前的几层,几十层的深度网络,在残差网络面前都不值一提,残差可以很轻松的构建几百层,一千多层的网络而不用担心梯度消失过快的问题,原因就在于残差的捷径(shortcut)部分,其中残差单元如下图所示:
解决方案6-LSTM
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates),如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。


这里提一嘴,relu的问题可以采用leakrelu替代,这是为了防止有些neuron永远都不会被激活,因为小于0的就一直是0,另外有一种方法是elu,但是由于这个牵涉到exp()求导,所以会相对慢一些,毕竟前面的relu和leakrelu求导都是常数,在计算上肯定就更快,介于训练得训练好多轮,肯定希望算快点。
为什么可以这么做
- 预训练+微调
老实说这个方法超常见的,基本上就和爸妈盯着写作业然后家长签字交给老师,那么老师拿到没有做完的作业的概率就会很低了。 - 梯度剪切,正则化
在NLP的课程中,老师提到过在最开始很多人都没办法train起来network,因为这个平面过于崎岖了,很可能某个位置前一秒还是平坦的,下一秒就马里亚纳海沟了,一脚踩进去直接爆炸,所以实际上当时采用的思路是,限制梯度,如果高/低于某个值,就锁死在这个值,这样即使一脚踩进去,也不至于飞天上去。对权重做正则化也很好理解,有的地方太离谱了就给揍狠一点,那么下次就知道不要往这边走太多。 - 激活函数
本身激活函数就可能是造成梯度爆炸/梯度消失的元凶首恶,直接对它下手也很好理解 - batch normalization
似乎在前面的normalization部分介绍了batchnorm是什么了已经。这个作用其实还是希望在走向收敛的路上别走弯路(尽量团成一个正常的圆) - resnet
本身resnet就用了batchnorm,这里可以解决梯度消失的问题是采用了残差链接的方式。即使那边已经挂了,这边至少还有一个输入的x。
本来我们学的是F(x),现在学的是F(x)-x(据说这么做的好处除了防止梯度消失,而且残差更好学)。当然,本身resnet是解决了退化的问题。
这里的“退化”指的是,随着网络的加深,accuracy先逐渐升高到达饱和,然后迅速衰退。文中指出这一问题并非由过拟合导致(并不是模型过于复杂)。这一问题也说明了,我们并不能简单的认为通过堆叠层数来优化模型。 - LSTM
RNN和LSTM在面对memory的时候,处理的operation其实是不一样的。在RNN里面,其实在每一个时间点,memory里面的信息都会被洗掉,在每一个时间点,output的值都会被放到memory里面去,所以每个时间点memory里面的值都会被覆盖掉。
但是在LSTM里面不一样,是把原来memory里面的值乘上一个值,再加上input的值加起来放到memory里面。所以,如果现在的weight可以影响到memory里面的值,一旦发生影响,这个影响会一直存在。
不像RNN里面每个时间点的memory里面的值都会被format掉,只要一被format掉,这个值就消失了。但是在LSTM里面,一旦能对memory造成影响,那个影响会永远保留,除非forget gate决定吧当前memory里面的值洗掉(关闭forget gate)。
即使这样,也有forget gate,这也有可能会把memory里面的值洗掉。事实上在最开始的结构里是没有forget gate的(因为设计出来就是为了解决gradient vanish的问题的),forget gate实际上是后面加进来的,一般而言是给forget gate比较大的bias,确保forget gate在大部分时间是开启的。
(摘自弹幕:LSTM可以解决梯度消失的原因是来自上一时序的信息以相加的方式保存在memory unit中,所以当forget gate一直保持开启时,这部分梯度就始终存在)
LSTM,会把比较平坦的地方去掉,也就是让error surface不要那么崎岖(可以解决gradient vanish的问题),这个时候就可以放心的把learning rate设的小一点->可以在learning rate特别小的情况下训练。
简单来说就是,resnet采用连接的方式维持一个梯度的体面不要丢失,LSTM采用把以前的梯度都吃掉融为一体(什么恶魔的报恩方法)

参考链接
警惕!损失Loss为Nan或者超级大的原因_损失值为nan-CSDN博客
深度网络梯度爆炸的原因、产生的影响和解决方法(常用激活函数)_tanh 稳定网络-CSDN博客
梯度爆炸与梯度消失是什么?有什么影响?如何解决?-CSDN博客
梯度消失和梯度爆炸及解决方法 - 知乎 (zhihu.com)
详解深度学习中的梯度消失、爆炸原因及其解决方法 - 知乎 (zhihu.com)
出现梯度消失与梯度爆炸的原因以及解决方案 - 知乎 (zhihu.com)
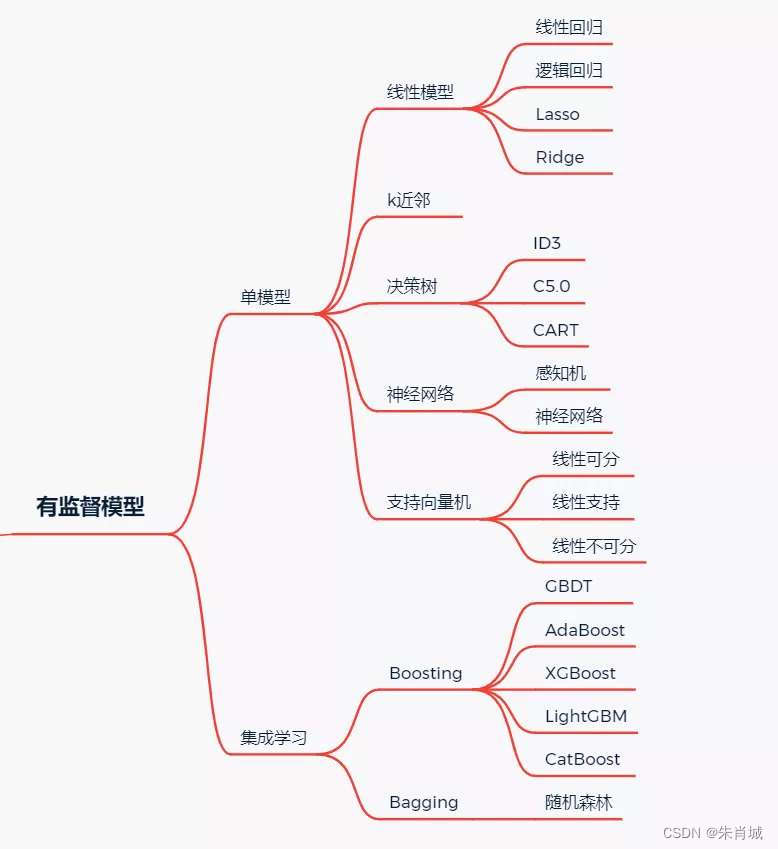
附录:GDBT与XGBoost的联系和区别
这个也很经常被问到,但是在数的第12章,感觉看到这里要很久哎~
所以提前放出来好啦✿✿ヽ(°▽°)ノ✿
第一次被问到的时候我愣住了,XGBoost不是一个通用的库嘛,里面封装了一系列方法。XGBoost Documentation — xgboost 2.0.3 documentation
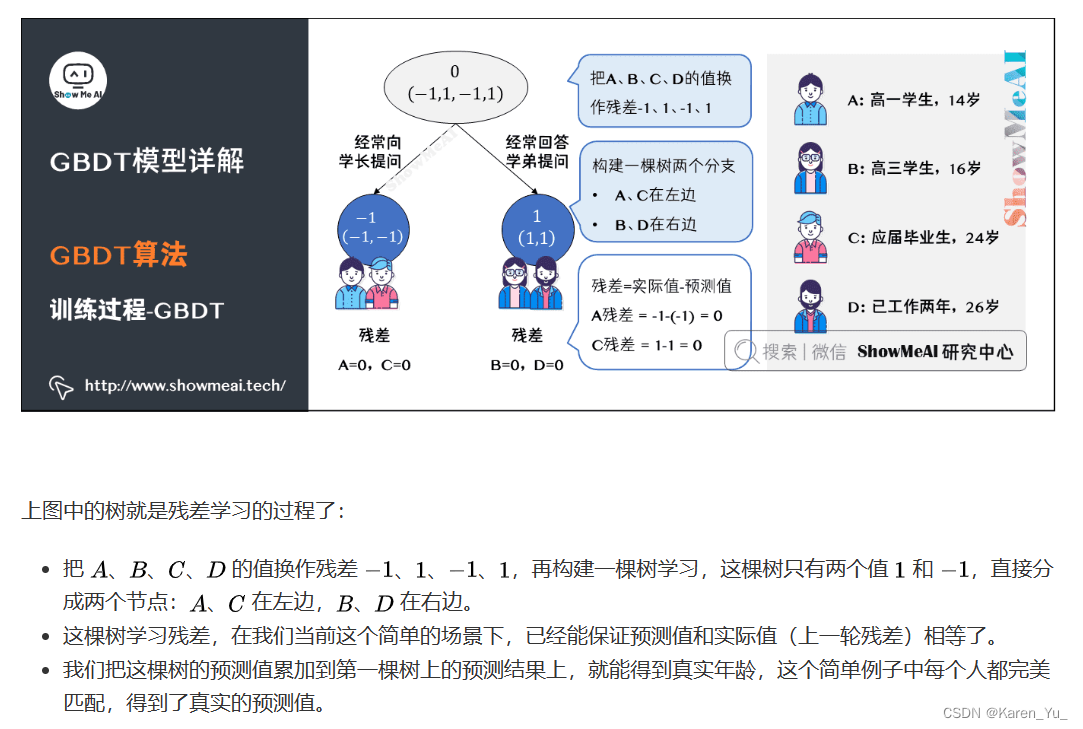
GDBT
GBDT也是集成学习Boosting家族的成员,但是却和传统的Adaboost有很大的不同。回顾下Adaboost,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去。GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时同时GBDT是基于残差学习的算,没有AdaBoost中的样本权重的概念。
请参考:图解机器学习 | GBDT模型详解 (showmeai.tech)图解,看例子
XGBoost
XGBoost(eXtreme Gradient Boosting)极致梯度提升,是一种基于GBDT的算法或者说工程实现。
XGBoost的基本思想和GBDT相同,但是做了一些优化,比如二阶导数使损失函数更精准;正则项避免树过拟合;Block存储可以并行计算等。
请参考图解机器学习 | XGBoost模型详解 (showmeai.tech)查看图解

差异
①提升树基于残差,每一次迭代当前模型都在尽可能拟合残差;
②GBDT基于一阶导数(梯度下降法优化);
③Xgboost基于GBDT的思想,使用了一阶和二阶导数信息(牛顿法优化,牛顿法:可参见[优化方法] 梯度下降法、最小二乘法、牛顿法、拟牛顿法、共轭梯度法)。提升树、GBDT、Xgboost关系如下(最开始的时候总是搞不懂,网上很多资料把最原始的GBDT和Xgboost都混在一起讲了):
①提升树的思想是基于加法模型,不断拟合残差。
②GBDT和Xgboost都是基于提升树的思想。
③GBDT的全称是Gradient Boosting Decision Tree,之所以有Gradient是因为GBDT中引入了梯度作为提升树中“残差”的近似值(提升树的每次迭代都是为了使当前模型拟合残差,就是使求得的增量模型尽可能等于残差)。
④Xgboost可以说是GBDT的一种,因为其也是基于Gradient和Boosting思想,但是和原始GBDT的不同是:Xgboost中引入了二阶导数和正则化,除此之外,Xgboost的作者陈天奇博士在工程实现方面做了大量的优化策略。
大概意思是提升树(残差)->GBDT(用负梯度作为残差近似值)->Xgboost(加了二阶导数和正则化等优化策略)
为什么已经有了基于残差的回归树,还提出基于负梯度来替代残差的替代提升树?
《统计学习方法》中给出的解释是:当损失函数是平方损失和对数损失时,每一步的优化是很简单的,但是对于一般的损失函数而言,往往每一步的优化不是那么容易,使用负梯度代替残差。kaggle blog给出的解释是:Although we can minimize this function directly, gradient descent will let us minimize more complicated loss functions that we can’t minimize directly.
原文链接:https://blog.csdn.net/quiet_girl/article/details/88756843
参考链接
XGBoost的原理、公式推导、Python实现和应用 - 知乎 (zhihu.com)
深入理解XGBoost,优缺点分析,原理推导及工程实现-CSDN博客
GBDT和Xgboost:原理、推导、比较_xgboost是gbdt的一种吗-CSDN博客
Xgboost和GBDT的区别? (zhihu.com)
梯度提升树(GBDT) - 知乎 (zhihu.com)
GBDT算法原理以及实例理解_gbdt算法实例 csdn-CSDN博客
梯度提升树(GBDT)原理小结 - 刘建平Pinard - 博客园 (cnblogs.com)


























![[已解决]mysql关闭SSL功能和永久关闭SSL设置](https://img-blog.csdnimg.cn/direct/802a2f43e21044179da1af704c588b59.png)