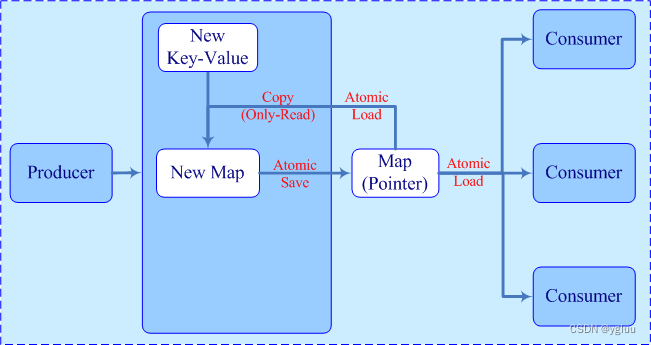
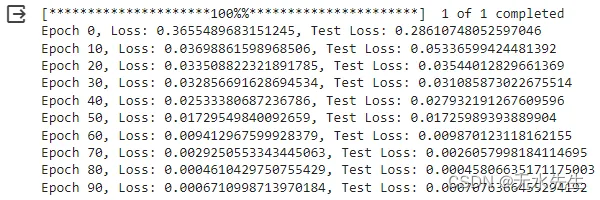
无锁环形缓冲区是一种多线程环境下用于在单生产者和单消费者之间安全传递数据的数据结构,它通常使用原子操作来保证线程安全性,而不需要使用显式的锁。这种数据结构通常用于提高多线程程序的性能,因为无锁操作比锁操作具有更低的开销。
单生产者单消费者场景下无锁缓冲区的特点:
- 消费者取出元素时,其它元素位置不需要移动
- 一般适用于缓冲区容量固定的场景
- 根据不同的策略可以选择:读线程读取时缓冲区为空的策略,写线程写数据时缓冲区满了的策略
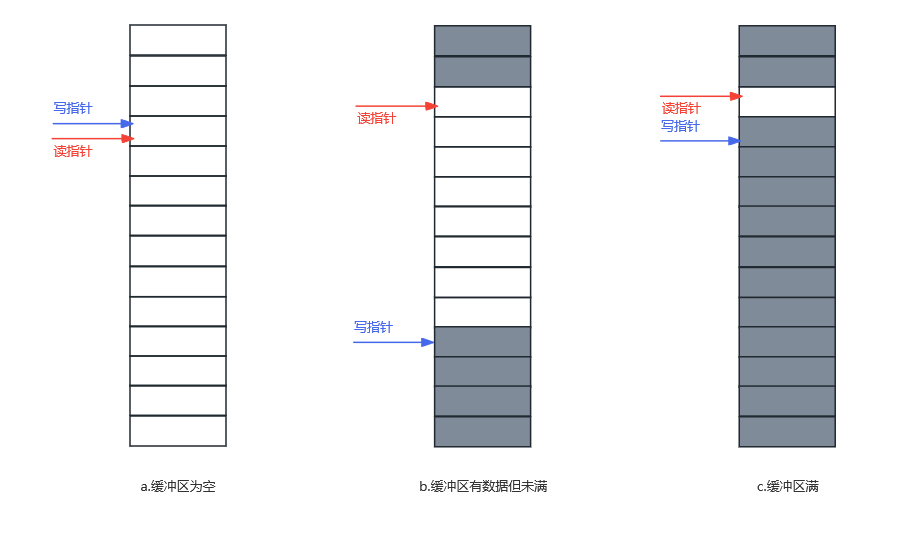
读写数据时分析
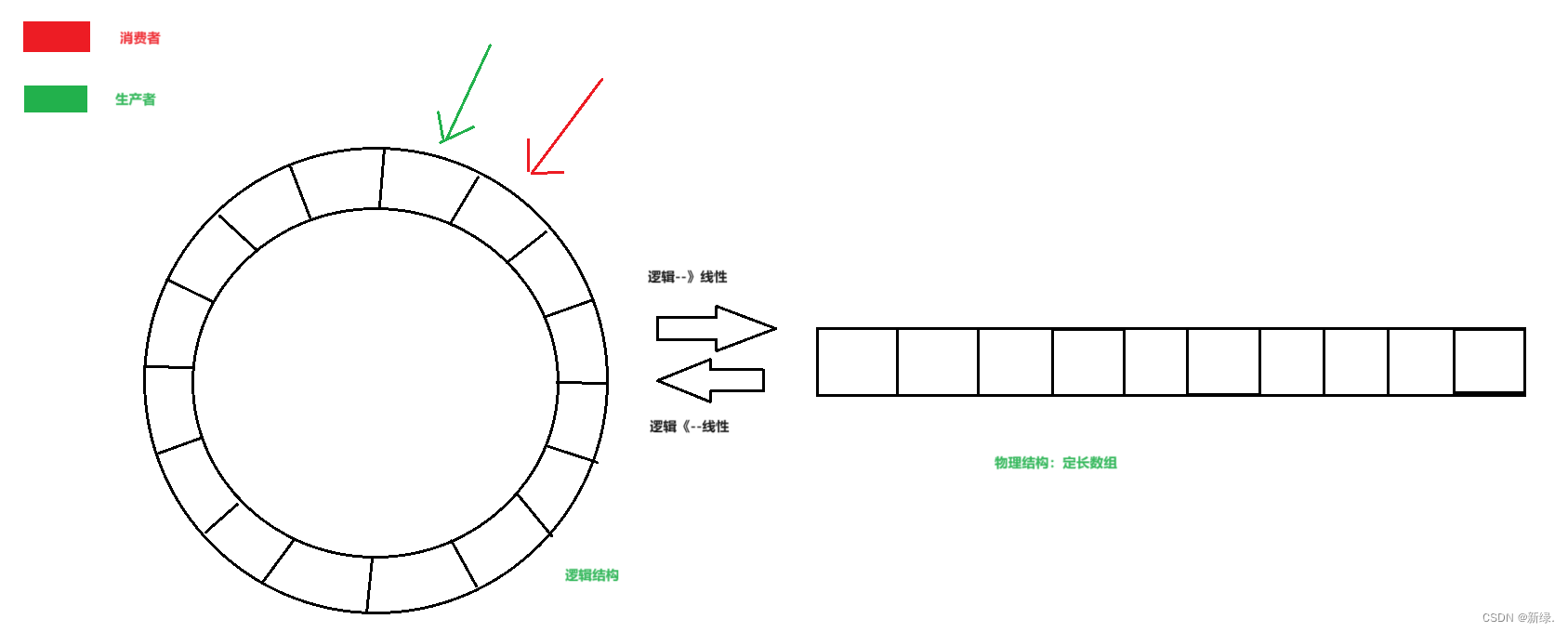
实际实现无锁环形缓冲区时,会首先申请一块大小(max_size表示数组最大可以存储元素的数量)固定的数组来存储数据,同时使用两个指针,一个读指针(read_index),一个写(write_index)指针,通过两个指针的移动来读写数据;在本例中read_index指向最近一个读取完数据的位置,write_index指向最近一个数据写入的位置。
- 缓冲区为空判断条件:read_index == write_index
- 缓冲区满的判断条件:(write_index + 1) % max_size == read_index(可以知道,实现可以存储的数据大小为max_size - 1)
- 写数据时,首先判断缓冲区是否满(如果满了的策略)---->然后先写数据---->然后再更新写指针的索引(避免数据还未写入完全,就被读取了)
- 读数据时,首先判断缓冲区是否为空(如果为空的策略)---->然后先读数据---->然后再更新读指针的索引(避免数据被读取了一个,就被覆盖)
- 获取当前缓冲区中可读取的数据长度:(write_index + max_size - read_index)% max_size,注意在读线程中(考虑写线程写入数据),实现长度>=该值;在写线程中(考虑读线程读取数据),实际长度<=该值;
以下是代码实现,以及测试案例
#include <atomic>
#include <array>
#include <vector>
#include <memory>
#include <iostream>
#include <thread>
#include <cstdlib>
#include <chrono>
template<typename T, std::size_t N>
class LockFreeRingBuffer {
public:
LockFreeRingBuffer() : m_writeIndex(0), m_readIndex(0), m_size(N) {}
bool push(const T& item) {
std::size_t currentWriteIndex = m_writeIndex.load(std::memory_order_relaxed);
std::size_t nextWriteIndex = (currentWriteIndex + 1) % m_size;
if (nextWriteIndex == m_readIndex.load(std::memory_order_acquire)) {
return false;
}
//先写入数据,再更新索引
m_buffer[nextWriteIndex] = item;
m_writeIndex.store(nextWriteIndex, std::memory_order_release);
return true;
}
bool pop(T& item) {
std::size_t currenReadIndex = m_readIndex.load(std::memory_order_relaxed);
if (currenReadIndex == m_writeIndex.load(std::memory_order_acquire)) {
return false; // Buffer is empty
}
//先读取数据,再更新索引
std::size_t nextReadIndex = (currenReadIndex + 1) % m_size;
item = m_buffer[nextReadIndex];
m_readIndex.store(nextReadIndex, std::memory_order_release);
return true;
}
std::size_t size() const {
std::size_t currentWriteIndex = m_readIndex.load(std::memory_order_acquire);
std::size_t currenReadIndex = m_readIndex.load(std::memory_order_acquire);
//注意加减的顺序,由于索引类型是std::size_t,则如果currentWriteIndex直接-currenReadIndex可能会导致溢出
return (currentWriteIndex + m_size - currenReadIndex);
}
private:
std::atomic<std::size_t> m_writeIndex;
std::atomic<std::size_t> m_readIndex;
const std::size_t m_size;
std::array<T, N> m_buffer;
};
/*------------------------测试用例---------------------------------------*/
template<typename T, size_t N>
void producer_consumer_test() {
LockFreeRingBuffer<T, 2048> buffer;
std::vector<T> readBuffer(N);
std::vector<T> writeBuffer(N);
auto now = std::chrono::system_clock::now();
auto duration = now.time_since_epoch();
unsigned int seed = static_cast<unsigned int>(duration.count());
std::srand(seed);
std::thread producer([&]() {
for (std::size_t i = 0; i < N; ++i)
{
int data = std::rand() % 10 + 1;
while (!buffer.push(data)) {} // 等待直到成功推送数据
writeBuffer[i] = data;
std::cout << "write data:" << i << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(data));
}
});
std::thread consumer([&]() {
int value;
for (std::size_t i = 0; i < N; ++i)
{
while (!buffer.pop(value)) {} // 等待直到成功弹出数据
readBuffer[i] = value;
std::cout << "read data:" << i << std::endl;
int data = std::rand() % 10 + 1;
std::this_thread::sleep_for(std::chrono::milliseconds(data));
}
});
producer.join();
consumer.join();
std::this_thread::sleep_for(std::chrono::seconds(2));
for (std::size_t i = 0; i < N; ++i)
{
if (readBuffer[i] != writeBuffer[i])
{
std::cout << "Error:" << i << "--->" << "readBuffer[i]:" << readBuffer[i] << " " << " writeBuffer[i]" << writeBuffer[i] << std::endl;
}
}
std::cout << "over!!!" << std::endl;
}
int main() {
constexpr size_t N = 100000;
producer_consumer_test<int, N>();
return 0;
}