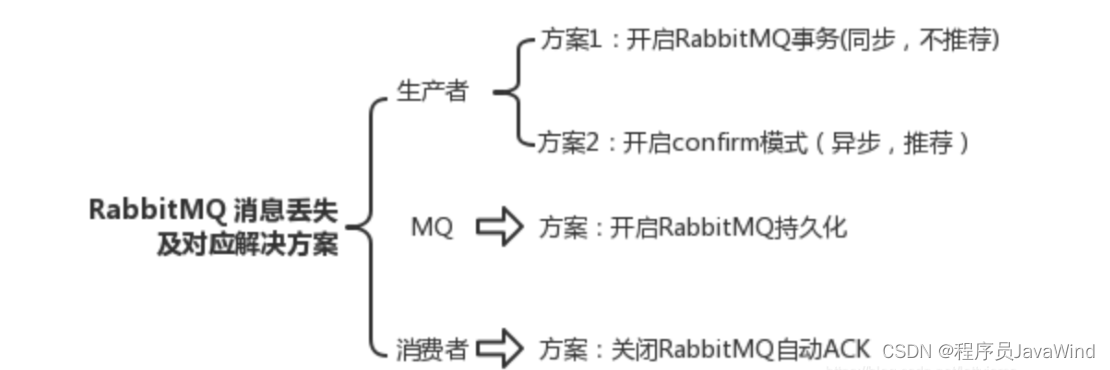
在使用 RabbitMQ 进行消息传递的时候,我们往往需要保证消息的可靠投递,防止 消息丢失。RabbitMQ 提供了多种机制来保证消息的准确投递,包括消息确认机制和事务机制。
1. 消息确认机制(ACK)
RabbitMQ 提供了消息确认机制,允许消费者告诉 RabbitMQ 当一条消息已经被接收并且处理完成,并且 RabbitMQ 可以从内存中释放这条消息。在 RabbitMQ 中我们可以通过 channel.basicAck 方法来发送确认信号。如果消费者因为某种原因(比如宕机)无法处理消息,RabbitMQ 会将该消息发送给其他消费者(如果存在)进行处理。 这有助于我们降低消息丢失的风险。
下面是一个简单的使用案例:
java
@RabbitListener(queues = "queue_name")
public void handle(Message message, Channel channel) {
try {
// 处理消息
...
// 手动发送ACK signal
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
System.err.println("消息处理出错," + e.getMessage());
}
}
2. 事务机制
事务是一种更强大的方式来保证消息的可靠投递。消费者可以在处理完所有相关的消息后再提交事务,这样如果在处理过程中发生错误,所有的操作(包括发送 ACK)都会回滚,RabbitMQ 会保留所有的消息。
但是,需要注意的是,使用事务机制会显著降低消息吞吐量。以下为一个事务的简单使用案例:
java
channel.txSelect(); // 开启事务
try {
// 消息处理
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
channel.txCommit(); // 提交事务
} catch (Exception e) {
channel.txRollback(); // 回滚事务
}
在 RabbitMQ,选择哪种机制取决于你的业务需求和消息的要求。事务机制提供了较高的安全性,但是在高并发或者高吞吐量的场景,消息确认机制一般是一个更好的选择,因为它在保证消息可靠性的同时,对性能的影响较小。
3、在 RabbitMQ 中使用消息确认机制进行批量确认
在 RabbitMQ 的消息确认机制中,我们通常处理一条消息就发送一次 ACK,但如果消息流很大,这会有很多的网络通信开销。针对这种情况,RabbitMQ 提供了批量确认的方式,即消费者可以在处理多条消息后,一次性向 RabbitMQ 发送一个 ACK,注意我们需要将基于每条消息的确认(channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);)中的第二个参数改为 true。同样我们需要在 channel.basicConsume 方法中关闭 autoAck(channel.basicConsume(QUEUE_NAME,false,deliverCallback,cancelCallback);)。代码示例如下:
java
@RabbitListener(queues = "queue_name")
public void handle(Message message, Channel channel) {
try {
// 处理消息
....
// 手动进行批量确认
channel.basicAck(message.getMessageProperties().getDeliveryTag(), true);
} catch (Exception e) {
System.err.println("消息处理出错," + e.getMessage());
}
}
上述代码中 basicAck 方法的第二个参数设置为 true,就表示批量进行消息确认,此时 RabbitMQ 会将该 delivery tag 之前的所有消息都确认掉。
4、在高并发场景下,如何处理消息处理过程中的异常情况
在处理消息的过程中,可能会遇到一些意外的情况,比如网络波动、程序错误等,这时候我们需要处理这些异常情况以防止消息丢失或者错误地确认。
一个常见的做法是捕获异常,然后将出现异常的消息重新放回到队列中:
java
@RabbitListener(queues = "queue_name")
public void handle(Message message, Channel channel) {
try {
// 处理消息
...
// 手动发送 ACK
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);
} catch (Exception e) {
System.err.println("消息处理出错," + e.getMessage());
try {
/*
* basicNack(long deliveryTag, boolean multiple, boolean requeue)
* deliveryTag:该消息的index
* multiple:是否批量.nack所有小于deliveryTag的消息
* requeue:被否重回队列.如果requeue=true,则消息会重回队列并被重新消费,如果requeue=false,则会告诉队列移除当前消息
*/
channel.basicNack(message.getMessageProperties().getDeliveryTag(), false, true);
} catch (IOException ioException) {
System.err.println("读写错误:" + ioException.getMessage());
}
}
}
上述代码中,如果消息处理过程中出现异常,使用 basicNack() 方法拒绝了消息,并让 RabbitMQ 重新将消息发送到队列,等待下一次的消费。
5、在使用 basicNack 方法拒绝消息时,如何避免消息在队列中无休止地重试?
在使用 basicNack 方法拒绝消息并且让消息重新进入队列时,为了避免消息在队列中无休止地重试,我们可以在消息里面添加一个重试次数的记录,每次消费失败重试之前检查一下这个计数,如果超过了我们设定的最大重试次数,那么我们就不再让它重回队列,比如将它发送到一个“死信队列”或者记录到日志里面。
RabbitMQ 本身并没有直接提供设置消息重试次数的机制,我们需要在应用层面进行额外的设计和实现。一个常见的做法是在消息中添加一个重试次数的字段,然后在每次重新发送或者处理消息的时候进行检查和更新。
以下是一个基础的实现思路:
(1). 添加重试次数字段
在发布消息的时候,我们可以添加一个 "retry_count" 的字段,并设置初始值为 0。例如:
json
{
"data": "Hello world",
"retry_count": 0
}
(2) 更新重试次数
当消费者接收到消息并处理失败后(比如发生异常),我们先获取到 "retry_count" 的值,然后将其加 1,然后再将消息和新的 "retry_count" 发送回队列。
(3) 检查重试次数
在每次消费者准备处理消息的时候,我们都检查 "retry_count" 的值。如果它达到了最大重试次数(这个值我们可以自己设定),那么我们就不再处理这个消息,可以选择将其发送到死信队列,或者记录到日志里进行后续处理。
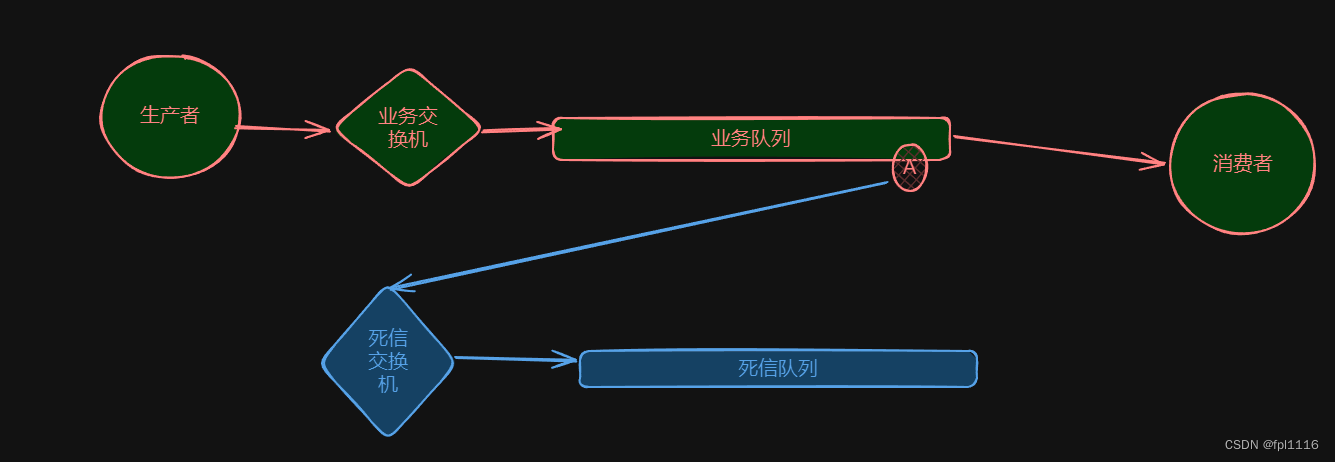
6、什么是死信队列,如何将处理失败的消息放入死信队列?
“死信队列”其实就是一个普通的 RabbitMQ 队列,我们可以在创建一个队列的时候为它指定 x-dead-letter-exchange 和 x-dead-letter-routing-key 参数,这样当这个队列中的消息因为各种原因被拒绝,并且设置的是不重新入队,那么 RabbitMQ 就会自动地将这个消息重新发布到我们指定的 exchange,并且用我们指定的 routing key 进行路由,从而实现消息的“死信”处理。
7、如何使用分布式锁等机制,避免在并发环境下出现的重复消费问题?
RabbitMQ 并不能完全保证每个消息只被消费一次,特别是在网络环境不稳定或者消费者应用程序发生故障时,我们常常需要处理重复消费的问题。
一个常见的解决方案是使用分布式锁(比如基于 Redis、ZooKeeper 等实现的分布式锁),每次消费消息的时候,我们都先查看这个消息是否已经被处理过,如果已经处理过就直接返回。
当然,分布式锁并不能完全解决这个问题,而且使用分布式锁也会带来一定的性能开销,难以应对非常高的并发。因此在一些场景下,我们更倾向于设计幂等的操作,也就是对于相同的消息,重复消费不会产生不同的结果。
这可以通过在数据库中维护一个全局唯一的 id 列表来实现,例如,我们可以将 messageId(这需要我们在发布消息的时候就生成并保存下来)作为一个全局唯一的 id,当消费者收到消息并处理成功后,就将这个 messageId 写入到数据库中,那么下次如果再收到相同的 messageId,我们就知道这个消息已经被处理过了。