注意力机制篇 | YOLOv8改进之添加多尺度全局注意力机制DilateFormer(MSDA)| 即插即用
- 开发
- 14
-

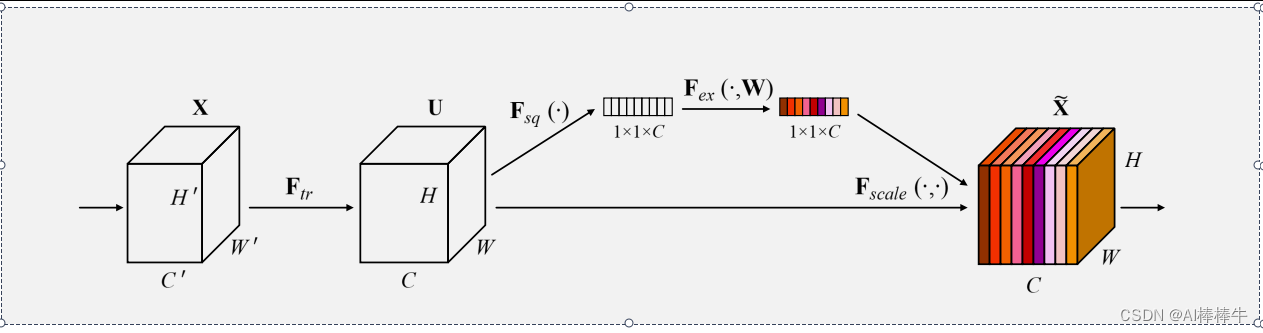
前言:Hello大家好,我是小哥谈。多尺度全局注意力机制DilateFormer是一种用图像识别任务的深度学习模型。它是在Transformer模型的基础上进行改进的,旨在提高模型对图像中不同尺度信息的感知能力。DilateFormer引入了多尺度卷积和全局注意力机制来实现多尺度感知。具体来说,它使用了一系列不同尺度的卷积核对输入图像进行卷积操作,从而捕捉到不同尺度下的特征信息。这样可以使得模型在处理图像时能够同时关注到细节和整体的特征。本文所做出的改进即在YOLOv8网络结构中添加DilateFormer注意力机制!~🌈
目录
🚀1.基础概念
原文地址:https://blog.csdn.net/weixin_61961691/article/details/137391807
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。
本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:https://www.suanlizi.com/kf/1776128649364377600.html
如若内容造成侵权/违法违规/事实不符,请联系《酸梨子》网邮箱:1419361763@qq.com进行投诉反馈,一经查实,立即删除!