本文全面整理了各种回归预测模型,旨在帮助读者更好地学习回归预测模型。
转载自:https://mp.weixin.qq.com/s/7m2waIASOEg90NONgRpQFQ
一.线性模型
线性回归是一种线性模型,通过特征的线性组合来预测连续值标签。线性回归通过拟合系数 (可选择是否设置截距)的线性模型,以最小化真实值和预测值之间的残差平方和。
scikit-learn linear_models:
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.linear_model
普通最小二乘线性回归。
套索回归(Lasso)是一种使用 L1 先验作为正则化器进行训练的线性模型。
岭回归。岭回归是一种结合了 L2正则化项的最小二乘线性回归,适用于共线性数据的有偏估计回归。这是一种改良的最小二乘估计法,它放弃了最小二乘法的无偏性,以损失部分信息和降低精度为代价,使得回归系数更符合实际、更可靠。对于病态数据,其拟合能力强于最小二乘法。然而,它不具备特征选择的能力。
随机梯度下降回归。通过随机梯度下降(SGD)来最小化正则化经验损失。在每次采样时,都会估算损失梯度,随着学习率的下降,模型会相应地更新。正则化器是一种添加到损失函数中的惩罚项,它使用欧几里得平方准则 L2 或绝对准则 L1 或两者的组合(弹性网)将模型参数向零向量收缩。如果参数更新因正则因子而越过 0.0 值,更新将被截断为 0.0,以便学习稀疏模型并实现在线特征选择。
弹性网络回归(ElasticNet)是一种线性回归模型,它使用结合了 L1 和 L2 先验的正则化器。
最小角回归模型(Least Angle Regression,简称LAR)。最小角回归是一种适用于高维数据的回归算法。当预测变量(p)大于观察样本数(n)时,LAR可以解决线性回归问题。其核心思想是将预测目标依次分解为特征向量的线性组合,最终使得残差向量与所有特征均线性无关,从而最小化。在每一步中,LAR都会找到与目标最相关的特征。当多个特征具有相等的相关性时,LAR 不是沿着相同的特征继续进行,而是沿着特征之间角平分线的方向进行。LAR是前向梯度算法与前向选择算法的折中,可以产生分段线性结果的完整路径,这在模型的交叉验证中极为有用。
正交匹配追踪算法(Orthogonal Matching Pursuit,简称 OMP)。这是一种贪心的压缩感知恢复算法。OMP用于近似拟合一个带约束的线性模型,其中约束影响模型的非零系数。OMP是一种前向特征选择方法,可以近似一个固定非零元素的最优向量解,这与最小角回归类似。OMP的每一步选择都高度依赖于当前的残差,这是其基于贪心算法的特性。OMP 与匹配追踪(MP)相似,但相对于 MP更优,因为它可以在每次迭代中利用正交投影重新计算残差,从而对先前选择的字典元素进行重建。
贝叶斯 ARD 回归。ARD(Automatic Relevance Determination)自动相关性确定。该方法使用 ARD先验来拟合回归模型的权重,其中权重假设为高斯分布。同时,它会估计参数 lambda(权重分布的精度)和alpha(噪声分布的精度),这个估计过程是通过迭代程序(即证据最大化)来完成的。
贝叶斯岭回归。拟合一个贝叶斯岭模型。有关此实现的详细信息以及正则化参数 lambda(权重的精度)和alpha(噪声的精度)的优化
异常值鲁棒回归器 包括 Huber 回归、分位数回归、RANSAC 回归和 Theil-Sen 回归。
广义线性模型(GLM)用于回归预测,包括泊松分布、Tweedie 分布和 Gamma分布。这些模型不仅允许预测目标具有正态分布以外的误差分布,还可以处理非正态分布的因变量。此外,它们还可以通过链接函数将自变量和因变量联系在一起。值得一提的是,GLM 可以适用于多种类型的数据,如连续型数据、计数型数据和二分类数据等。
二.非线性模型
非线性回归是一种非线性模型,通过特征的非线性组合交互来预测连续值标签。在回归预测实践中,集成树模型是最常用的,因为它们具有适应异构数据、计算高效、泛化性能好和简单易用等优势。
数据竞赛三巨头:XGBoost、LightGBM、CatBoost(极端梯度提升机及其变体)
XGBoost 官方文档 https://xgboost.readthedocs.io/en/stable/
LightGBM 官方文档: https://lightgbm.readthedocs.io/en/stable/
CatBoost 官方文档:https://catboost.ai/
其他:
选择普通非线性回归的期望函数通常取决于我们对系统响应曲线的形状以及物理和化学属性行为的了解。可能的非线性函数包括但不限于多项式、指数、对数、S 形和渐近曲线。您需要指定一个既符合您已有的知识,又满足非线性回归假设的函数。尽管可以灵活地指定各种期望函数,但确定最适合数据的函数可能需要大量的精力。这通常需要进行额外的研究、利用专业领域知识以及进行试错分析。此外,非线性方程在确定每个预测变量对响应的影响时可能不如线性方程直观。
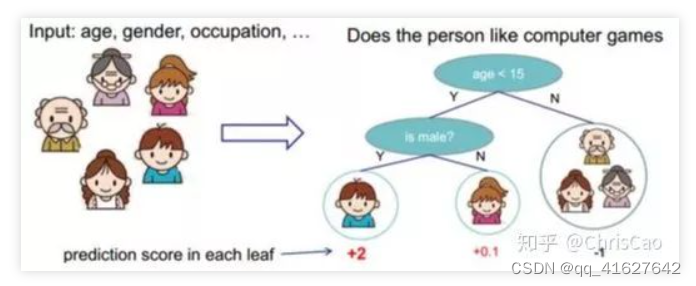
决策树回归。CART 决策树可以应用于回归预测。当进行预测时,新样本从根节点开始,根据其特征值在每个节点被分配到左子节点或右子节点,直至到达叶节点。这个叶节点中所有训练样本标签的平均值就是新样本的预测值。
支持向量机回归。支持向量机能够应用于回归预测任务,主要得益于其ε-不敏感损失函数和核函数技巧。这两个特性使得 SVR 能够处理线性和非线性问题,并防止过拟合,因此它是一种有效的回归预测模型。
KNN 回归。KNN 是一种基于实例的学习方法,也可以称为懒惰学习。其工作原理是:当有一个新的数据点需要预测时,KNN 会在已知的数据集中找出与这个新数据点最接近的 K 个点,然后根据这些邻居的属性来预测新数据点的属性。在分类任务中,KNN 通常会选择这些邻居中最常见的类别作为新数据点的类别。而在回归任务中,KNN 通常计算这些邻居的平均值或者中位数,并将这个值作为新数据点的预测值。
普通神经网络回归。多层感知器 MLP,将样本的特征矩阵映射到样本标签空间。开发流程:网络初始化后,进行前向计算,反向传播和优化(损失函数通常为均方误差 MSE),然后进行迭代训练。这种方法可以用于回归预测。
随机森林回归。随机森林是一种基于 Bagging 范式的集成学习算法,其关注降低方差。随机森林算法首先创建多个决策树,每棵树都在数据集的一个随机子集上进行训练。这种过程被称为自助采样(bootstrap sampling)。特征选择:在构建决策树的过程中,随机森林会在每个节点处从特征的随机子集中选择最优特征进行分割。这种方法增强了模型的多样性,从而降低了过拟合的风险。对于回归问题,最终的预测结果是所有决策树预测结果的平均值。
深度森林(DeepForest)回归 。周志华老师团队的一项工作 DeepForest,它是一种新颖的基于决策树的集成学习方法。深度森林主要由多粒度扫描和级联森林两个部分构成。其中,多粒度扫描通过滑动窗口技术获取多个特征子集,以增强级联森林的差异性。而级联森林则是通过级联方式将决策树组成的森林实现表征学习。深度森林继承了深度学习对样本特征属性的逐层处理机制,同时克服了深度学习参数依赖性强、训练开销大以及仅适用于大数据等缺点。
Extra trees 回归(Extra trees 是 Extremely randomized trees 的简称)。这是一种使用决策树的集成学习方法,它与随机森林类似,但速度更快。Extra trees 会创建许多决策树,但每棵树的采样都是随机的,可以设置是否有放回采样。每棵树还会从全部特征集中随机选择特定数量的特征。Extra trees 最重要也是最独特的特点是随机选择特征的分割值。该算法不是使用基尼值或熵值计算局部最优值来分割数据,而是随机选择一个分割值。这就使得树具有多样性和非相关性,能够有效抑制过拟合。
AdaBoost 回归。AdaBoost 是一种关注降低偏差的基于 Boosting 范式的集成学习算法。AdaBoost 回归的基本步骤包括:(1)初始化训练样本的权重。每个样本的初始权重都是相等的;(2)对于每一轮迭代:使用当前的样本权重来训练一个弱学习器(例如决策树),计算这个弱学习器的预测误差,根据预测误差来计算这个弱学习器的权重,更新样本的权重;(3)将所有弱学习器的预测结果进行加权求和,得到最终的预测结果。
基于直方图的梯度提升回归(HistGradientBoostingRegressor)。通过 scikit-learn 改进的基于直方图的梯度提升回归,在大型数据集(n_samples >= 10,000)上,该估计器比 GradientBoostingRegressor 快得多。该估计器本身支持缺失值(NaNs)。在训练过程中,树生长器在每个分裂点学习,并根据潜在增益决定缺失值的样本应该进入左子节点还是右子节点。在预测时,具有缺失值的样本将被相应地分配到左子节点或右子节点。如果在训练过程中对某个特征没有遇到缺失值,那么具有缺失值的样本将被映射到具有最多样本的子节点。这个算法的灵感来自于 LightGBM。
TabNet。TabNet是由 Google 发布的一种针对于表格数据(Tabular data)设计的深度神经网络,它通过类似加性模型的序列注意力机制实现了 instance-wise 的特征选择,并且通过 encoder-decoder 框架实现了自监督学习,可用于下游学习任务如回归预测。
交互网络上下文嵌入(Interaction Network Contextual Embedding,INCE)。INCE 是一种用于表格数据的深度学习模型,采用图神经网络(GNNs),更具体地说,使用交互网络进行上下文嵌入。编码器模型首先将每个表格数据集特征映射到潜在向量或嵌入中,然后解码器模型获取这些嵌入并用于解决监督学习任务。编码器模型由 Columnar 嵌入和 Contextual 嵌入两部分组成;解码器模型由一个针对解决回归任务调整过的多层感知机(MLP)组成。
Local Cascade Ensemble:在 Python 中增强了 Bagging 和 Boosting 的组合。该工具包实现了本地级联集成(LCE),这是一种新颖的机器学习方法,可进一步提高目前最先进的方法 Random Forest 和 XGBoost 的预测性能。LCE 结合了它们各自的优势,并采用了一种互补的多样化方法,以获得更好的泛化预测模型。LCE 与 scikit-learn兼容,因此可以与 scikit-learn pipeline 和模型选择工具进行交互。
门控加性树集成(Gated Additive Tree Ensemble, GATE)。GATE 是一种新颖的、高性能、参数效率和计算效率高的深度学习架构,适用于表格数据,即门控增加树集成(GATE)。GATE使用了灵感来自于 GRU 的 gating 机制作为内置特征选择机制的特征表示学习单元,并将其与一组可微分、非线性决策树集成在一起,通过简单的自注意力重新加权,从而实现对期望输出值的预测。
深度自动特征学习的门控自适应网络(Gated Adaptive Network for Deep Automated Learning of Features)是 GATE 的简化版本,并且比 GATE 更高效。GANDALF将GFLU作为主要学习单元,并在过程中引入了一些加速机制。由于超参数调整非常少,使其成为一个易于使用和调整的模型
值得注意的是,有一个用于对表格数据建模的深度学习模型的标准框架 - pytorch_tabularhttps://github.com/manujosephv/pytorch_tabular

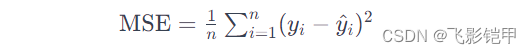























![[C#]OpenCvSharp使用HoughCircles霍夫圆检测算法找出圆位置并计数](https://img-blog.csdnimg.cn/direct/ba115db096aa461c8b13aa453312a5ed.jpeg)



![[Arduino学习] ESP8266读取DHT11数字温湿度传感器数据](https://img-blog.csdnimg.cn/img_convert/fed94fb76568ada8c24b60b46f993b00.png)