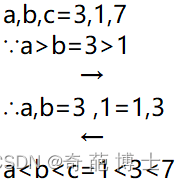1.知识点&&小问题
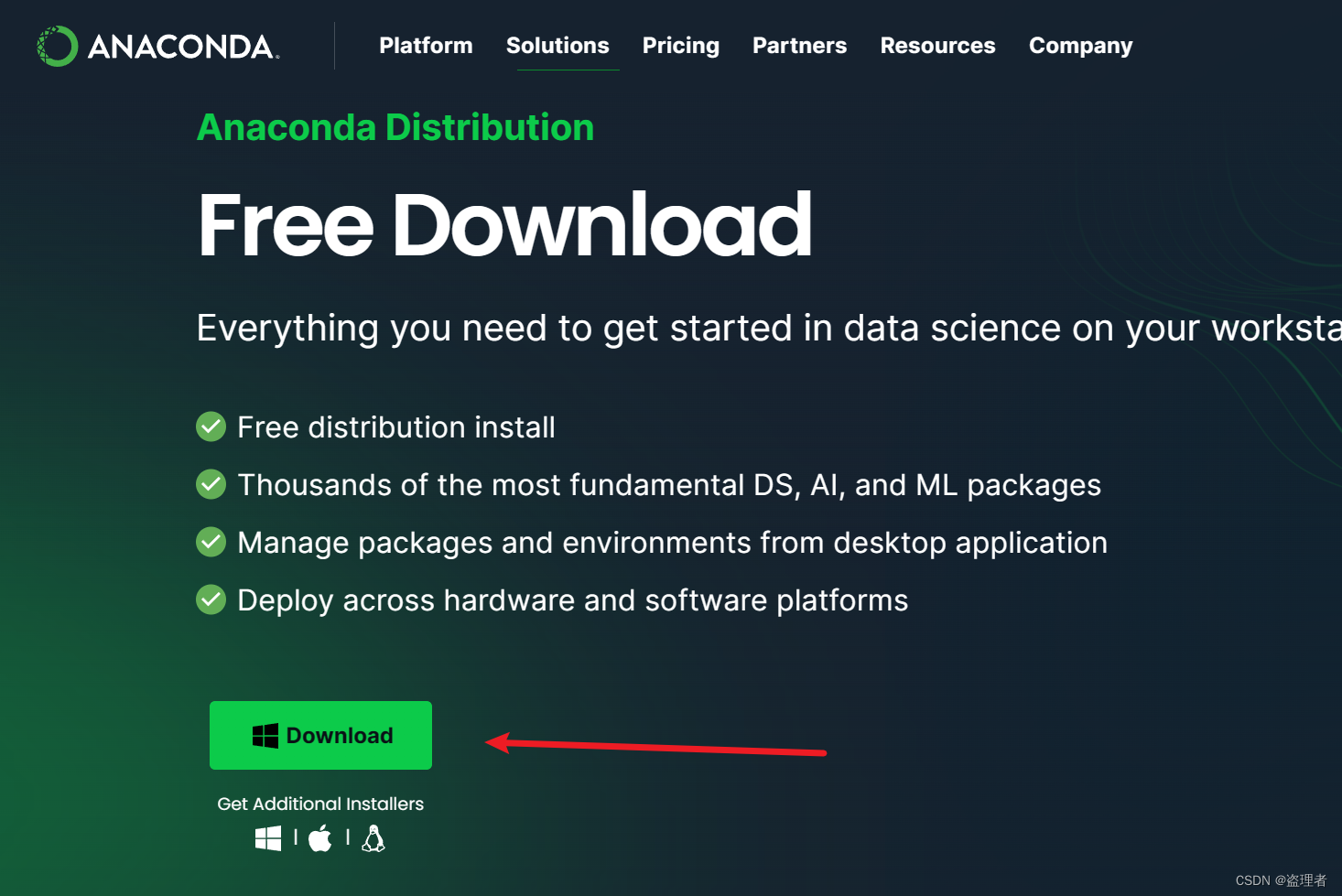
参考视频:最详细的 Windows 下 PyTorch 入门深度学习环境安装与配置 CPU GPU 版 | 土堆教程
1.Pytorch和TensorFlow都是python的包/库。
2.为什么使用Anaconda?Anaconda的优势是有虚拟环境。
3.计算机底层对于Python语言:
Python语法–>Python Interpreter解释器–>计算机
4.深入学习与GPU显卡:
GPU–>CUDA driver驱动–>CUDA Runtime–> Pytorch/TensorFlow–>计算机应用
5.CUDA版本:
驱动版本要高于Runtime版本
6.conda建立虚拟环境:
conda create -n 虚拟环境名字 python=3.8 -c 镜像
清华镜像:https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
7.conda删除虚拟环境:
condaremove –n 虚拟环境名字--all
8.通道channels:
condaconfig --add channels 通道地址
condaconfig --remove channels 通道地址
按照优先级来查找,查看配置文件中的优先级:
conda config --show
conda config --get
不推荐乱加channels,需要加的时候-c
9.确定显卡算力
CUDA:https://en.wikipedia.org/wiki/CUDA
1060显卡对应算力为6.1,CUDA SDK版本8.0以后都可以
10.在Anaconda虚拟环境中,conda install和pip install有什么区别?
conda 可以管理 pip 安装的包,但不推荐混合使用,因为这可能导致依赖性问题。如果你使用 conda 创建了一个虚拟环境,最好是先用 conda 安装尽可能多的包,然后再用 pip 安装那些在 conda 中不可用的包。
去这里找:
C:\path\to\conda\envs\<虚拟环境名称>\Lib\site-packages\
11.conda安装了OpenCV后Python无法找到
conda install opencv默认安装的最新版本4.6.0,但是import cv2无法找到。
原因:换个版本,推荐用pip install opencv-python
后面又遇到cmd中可以识别cv2,但是pycharm中找不到,将cv2,这个文件夹中虚拟环境中的Lib/site_package中复制到Lib下。
(很傻逼的问题,浪费一上午)
2.安装pytorch
先确定CUDA driver版本:11.7
nvidia-smi
nvcc -V
conda install pytorch==1.13.0 torchvision==0.14.0 torchaudio==0.13.0 pytorch-cuda=11.7 -c pytorch -c nvidia
不行的话,添加国内镜像:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/win-64/
在pycharm中检查编译器来源,确保是来源于torch下的Python3.8
3.项目中的包安装情况分析
配置pycharm中虚拟环境后,项目中提示找不到包,
通常是:
1.conda install 包名,
2.pip install 包名,
3.如果还是找不到包,百度搜索是不是通道不对,网络问题加镜像,
4.如果有requirements.txt,直接pip install一整个。
4.安装jupyter
一个实时交互的Python脚本工具
安装Anaconda的时候base环境会安装好Jupyter,但是需要再torch虚拟环境中安装。
conda install nb_conda
5.Python深度学习两大法宝
dir()查看功能名称, help()查看功能
6.数据集
(1)建立对应标签文件
# 建立标签对应文件
import os
root_dir = "dataset/train"
target_dir = "bees_image"
img_name = os.listdir(os.path.join(root_dir, target_dir)) # list类型
label = target_dir.split("_")[0] # 写入文件的值
out_dir = "bees_label"
for i in img_name:
file_name = i.split('.jpg')[0]
with open(os.path.join(root_dir, out_dir, "{}.txt".format(file_name)),"w")as f:
f.write(label)
(2)建立Dataset类
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, item):
img_name = self.img_path[item]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
# D:\code\learn_torch\pythonProject\dataset\train\ants\0013035.jpg
img = Image.open(img_item_path)
label = self.label_dir
return img, label # 得到某一张图片和其标签类型
def __len__(self):
return len(self.img_path) # 标签下数据集长度
root_dir = "D:\\code\\learn_torch\\pythonProject\\dataset\\train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)
train_dataset = ants_dataset + bees_dataset # 相加是Dataset类内置功能
# image, label = ants_dataset[0]
print(len(ants_dataset))
print(len(bees_dataset))
print(len(train_dataset))
image, label = train_dataset[124]
image.show()
(3)tensorboard模块
在PyTorch中,有一个工具叫做 torch.utils.tensorboard,它提供了与ensorFlow的TensorBoard相同的可视化功能可以可视化你的模型的训练过程、网络结构、参数分布等。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
# 导入图片
image_path = "data/train/ants_image/6743948_2b8c096dda.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("img_test", img_array,2, dataformats='HWC')
writer.close()
tips:add_image提供单张图片的接收,而add_images提供多batch_size的接收。
(4)transforms模块
在PyTorch中,transforms模块提供了一系列用于数据预处理和数据增强的功能。它可以帮助您对输入数据进行各种转换,以准备数据用于训练神经网络模型。
以下是transforms模块的常见用途和功能:
- 数据预处理:transforms模块提供了各种常见的数据预处理操作,例如调整大小、剪裁、旋转、翻转、标准化等。这些操作可用于对输入图像或数据进行预处理,以使其适应模型的输入要求。
- 数据增强:transforms模块还提供了各种数据增强操作,例如随机裁剪、随机翻转、随机旋转、颜色抖动等。这些操作可以通过对训练数据进行随机变换来增加样本的多样性,从而提高模型的泛化能力。
- 转换为Tensor:transforms模块还包括将数据转换为PyTorch
Tensor对象的功能。这对于将输入数据转换为可以输入到PyTorch模型的张量非常有用。 - 多个转换的组合:transforms模块允许您将多个转换操作组合在一起,形成一个转换管道。您可以按照特定的顺序应用这些转换来对数据进行预处理和增强。
from PIL import Image
from torchvision import transforms
import cv2
from torch.utils.tensorboard import SummaryWriter
## 三种类型
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
print(type(img))
cv_img =cv2.imread(img_path)
print(type(cv_img))
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
print(type(tensor_img))
writer = SummaryWriter("logs")
writer.add_image("Tensor_img", tensor_img)
writer.close()
踩坑:新版的tensorboard参数:tensorboard --logdir “logs”
下面是各个transforms的工具使用,transforms类大都含有魔法函数call,可以将声明的实例化对象直接作为函数传参调用。
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img_path = "data/train/bees_image/16838648_415acd9e3f.jpg"
img = Image.open(img_path)
print(type(img))
# ToTensor
trans_tensor = transforms.ToTensor()
trans_tensor_img = trans_tensor(img)
writer.add_image("Tensor", trans_tensor_img)
print(type(trans_tensor_img))
# PILToTensor
trans_PIL= transforms.PILToTensor()
trans_PIL_img = trans_PIL(img)
print(type(trans_PIL_img))
# Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5])
img_norm = trans_norm(trans_tensor_img)
# writer.add_image("Normalize", img_norm)
print(img_norm[0][0][0])
# Resize
print(img.size)
trans_resize = transforms.Resize((100,100))
img_resize = trans_resize(img)
print(img_resize.size)
img_resize = trans_tensor(img_resize)
writer.add_image("resize", img_resize)
# Compose
trans_compose = transforms.Compose([trans_resize, trans_tensor])
img_compose = trans_compose(img)
writer.add_image("compose", img_compose)
# randomcrop 随机裁剪
trans_randomcrop = transforms.RandomCrop(100)
trans_compose2 = transforms.Compose([trans_randomcrop, trans_tensor])
for i in range(10):
img_randomcrop = trans_compose2(img)
writer.add_image("random_crop", img_randomcrop, i)
writer.close()
(5)结合CIFAR10 Dataset的transforms使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
# PIL to ToTensor
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=False, transform=dataset_transform, download=True)
# print(test_set[0])
# print(train_set.classes)d
# img, target = test_set[0]
# print(img)
# print(target)
# img.show()
#
writer = SummaryWriter("logs")
for i in range(10):
img, target = train_set[i]
writer.add_image("train_set", img, i)
writer.close()
(6)dataloader类:如何&怎样拿数据
作用:封装数据集并提供批量处理、打乱数据、并行加载等。
- 批量加载:机器学习模型通常在训练期间不会一次处理整个数据集,而是将数据集分成小批量(batches)。DataLoader
可以自动地将数据集分成指定大小的批次,每个批次可以并行地通过模型进行训练。 - 数据打乱:为了使模型训练更加稳健,通常需要在每个epoch开始时打乱数据。DataLoader
提供了一个简单的方式来在每个epoch自动打乱数据集。 - 并行数据加载:通过使用Python的 multiprocessing,DataLoader
能够在训练过程中并行加载数据,这样可以显著减少数据加载的时间,特别是在处理大型数据集和复杂的预处理过程时。 - 自定义数据抽样:DataLoader 允许使用自定义的 Sampler 或 BatchSampler
来控制数据的抽样过程,这在处理不均衡数据集或其他特殊需求时特别有用。 - 自动管理数据集迭代:DataLoader 与 PyTorch 的 Dataset
类联动,可以自动地进行数据集迭代,并在一个epoch完成后重置,为下一个epoch做好准备。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 获得CIFA10数据集,直接拿到ToTensor格式的
test_dataset = torchvision.datasets.CIFAR10(root="./CIFAR10_dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
writer = SummaryWriter("logs")
step = 0
for data in test_loader:
img, target = data
# print(img.shape)
# print(target)
writer.add_images("64_batch_size", img, step)
step = step + 1
writer.close()
7.神经网络nn
(1)卷积操作
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
卷积操作示意图:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
import torch
import torch.nn.functional as F
input = torch.tensor(([1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]))
kernel = torch.tensor(([1,2,1],
[0,1,0],
[2,1,0]))
print(input.shape)
input = torch.reshape(input, (1,1,5,5))
kernel = torch.reshape(kernel, (1,1,3,3))
output1 = F.conv2d(input, kernel, stride=1)
print(output1)
outout2 = F.conv2d(input, kernel, stride=2)
print(outout2)
torch.reshape(input, (1, 1, 5, 5)) 将 input 张量重新形状为一个具有 (1, 1, 5, 5) 形状的新张量。这里的形状参数 (1, 1, 5, 5) 表示:
- 第一个 1 表示批次大小(batch size),意味着这个张量中只有一个数据样本。
- 第二个 1 表示通道数(channel),意味着数据样本只有一个颜色通道(例如,灰度图)。
- 第三个和第四个数字 5 和 5 表示图像的高度和宽度,意味着数据样本是一个 5x5 的图像。
张量:实际为多维数组,例如三维张量表示图片信息,将图片转换成计算机可以看懂的三维数组形式。
以3维张量为例:对于单个图像,3维张量通常有形状(C, H, W),其中 C 表示颜色通道数(如RGB图像中的3),H 表示图像的高度,W 表示图像的宽度。
conv2d(input, kernel, stride=1)
stride 的参数设置为1,意味着横向和纵向移动都为1。
参数padding:填充作用,一般填充为0

# 接上面
outout3 = F.conv2d(input, kernel, stride=1, padding=1)
print(outout3)
##(2)卷积代码:
import torch
## 多个卷积核
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="CIFAR10_dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, target = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# # torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1,3,30,30))
writer.add_images("output", output, step)
step = step + 1
writer.close()
这一步是为了保证输出,因为传入参数要为三通道格式,多余的加入了一个批次的batch_size中,所以8×*8变成了16×8
output = torch.reshape(output, (-1,3,30,30))

具体参数查看官网:https://pytorch.org/docs/1.8.1/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
以下图为例:第一步为了保证不丢失边缘部分,肯定是做了padding填充


(2)最大池化
池化=下采样,步长默认为卷积核size,最大池化不改变通道数(卷积可能改变)

torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size为卷积核size,不做说明就是默认移动步长
当 ceil_mode=True 时,则允许滑动窗口越界,如图所示即使不满9个数也针对包含的部分进行操作。
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="CIFAR10_dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, target = data
writer.add_images("input", imgs, step)
output = tudui(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
(3)总结:卷积和最大池化
卷积是会对通道数产生影响,而最大池化类似于下采样,不会产生通道数的变化。
卷积:卷积每生成一个卷积核,输出结果都会多一个通道数。卷积核的数量决定了输出特征图的通道数。比如:你希望从一个3通道的输入图像生成一个6通道的输出特征图,你可以在卷积层中设置6个卷积核。
最大池化:“打马赛克”;放缩下采样。最大池化操作不改变通道数,因此输出特征图的通道数与输入特征图的通道数相同。