1、安装requests库
(1)直接win+R输入cmd进入命令行界面,执行命令:pip install requests
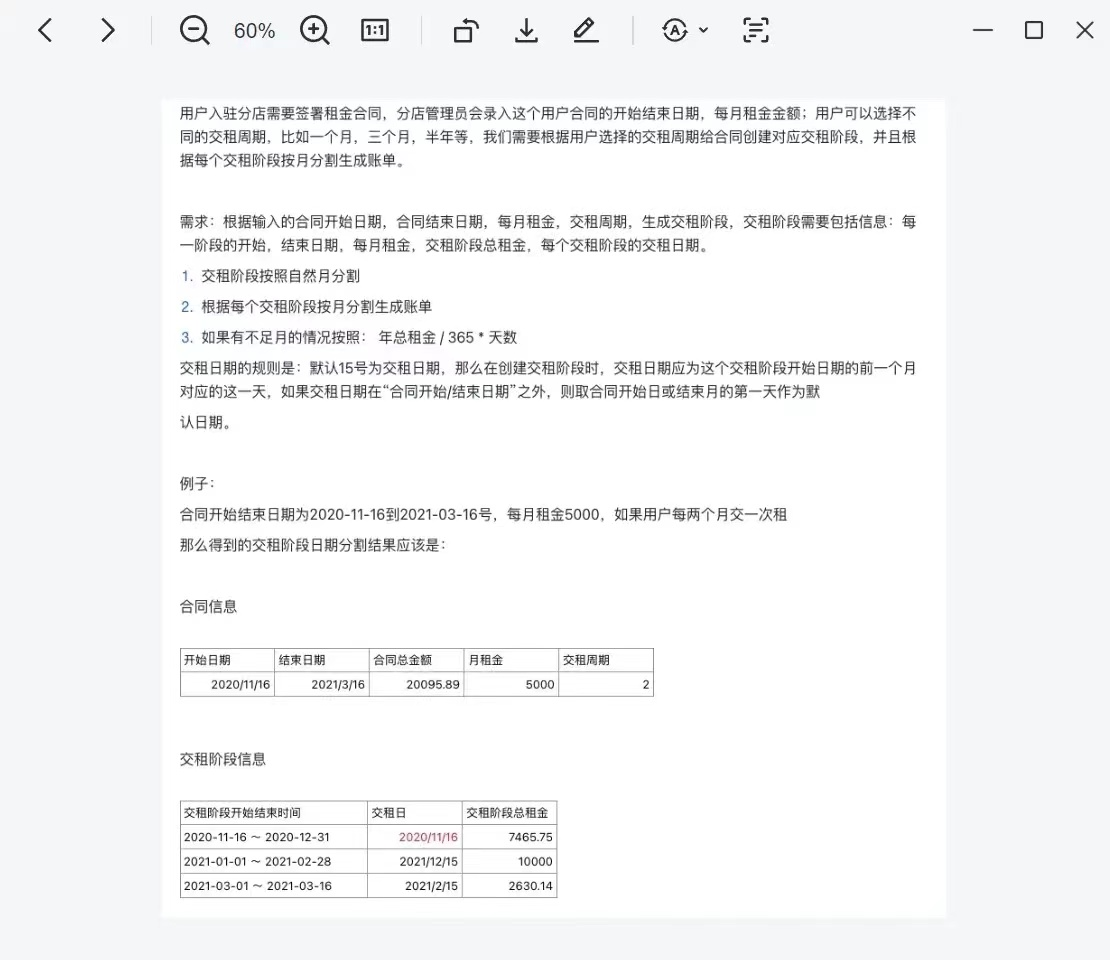
(2)再Pycharm中,’File’-’Settings’-’Python interpreter’-’+’-搜索’requests’-’install package’下载,如下图所示
2、实例:爬虫提取百度热搜的前十条,并写入一个文件中。代码如下:
import requests
import re # 导入库
url = "https://top.baidu.com/board?platform=pc&sa=pcindex_entry"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWeb"
"Kit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36"} # 创建变量
response = requests.get(url, headers=headers).text # 发送get请求
most_searched_hashtags = re.findall(r',"indexUrl":"","query":"(.*?)","rawUrl"', response) # 正则表达式提取内容成一个列表
with open(r'D:\pythonn\pythonProject\240202package\hot1.txt', mode='a+', encoding='utf-8') as file: # 创建一个文件hot1.txt,打开文件追加内容
for i in range(10): # 循环10次
print("热搜榜第{}:{}".format(i, most_searched_hashtags[i])) # 输出前10条热搜内容
file.write("热搜榜第{}:{}\n".format(i, most_searched_hashtags[i])) # 将输出热搜内容追加写入hot1.txt文件中若要更细了解requests,re库和文件读写操作可以借鉴:【Pyhton中requests库、re库、文件读写的了解】-CSDN博客
3、输出结果如下:





















![【洛谷 P8695】[蓝桥杯 2019 国 AC] 轨道炮 题解(映射+模拟+暴力枚举+桶排序)](https://img-blog.csdnimg.cn/direct/80a460261d8045a1be53c602862ec9c3.png)
![[StartingPoint][Tier0]Preignition](https://img-blog.csdnimg.cn/img_convert/d8717aa6f26501ccc02a6203fb50b011.jpeg)