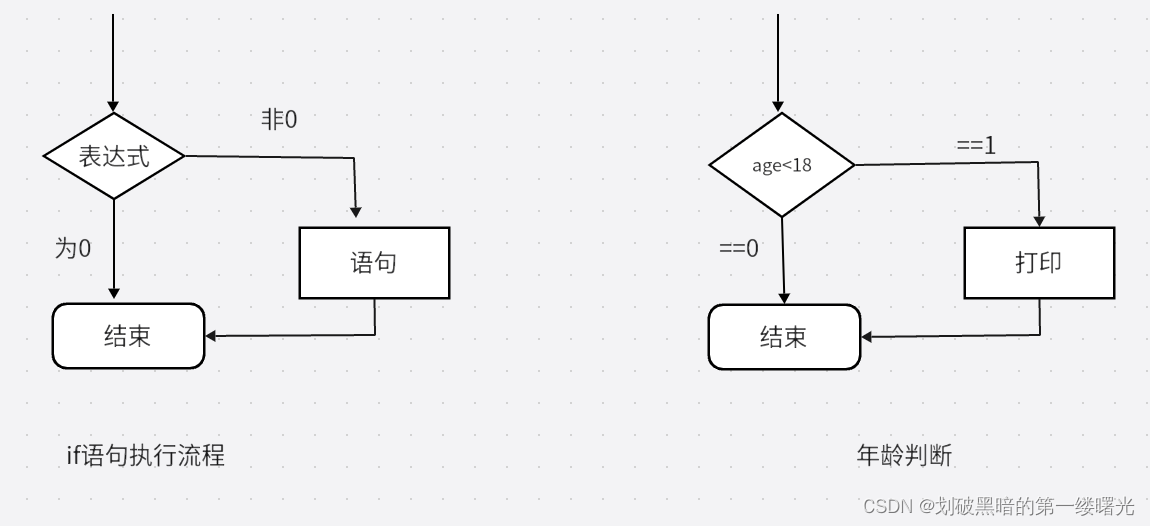
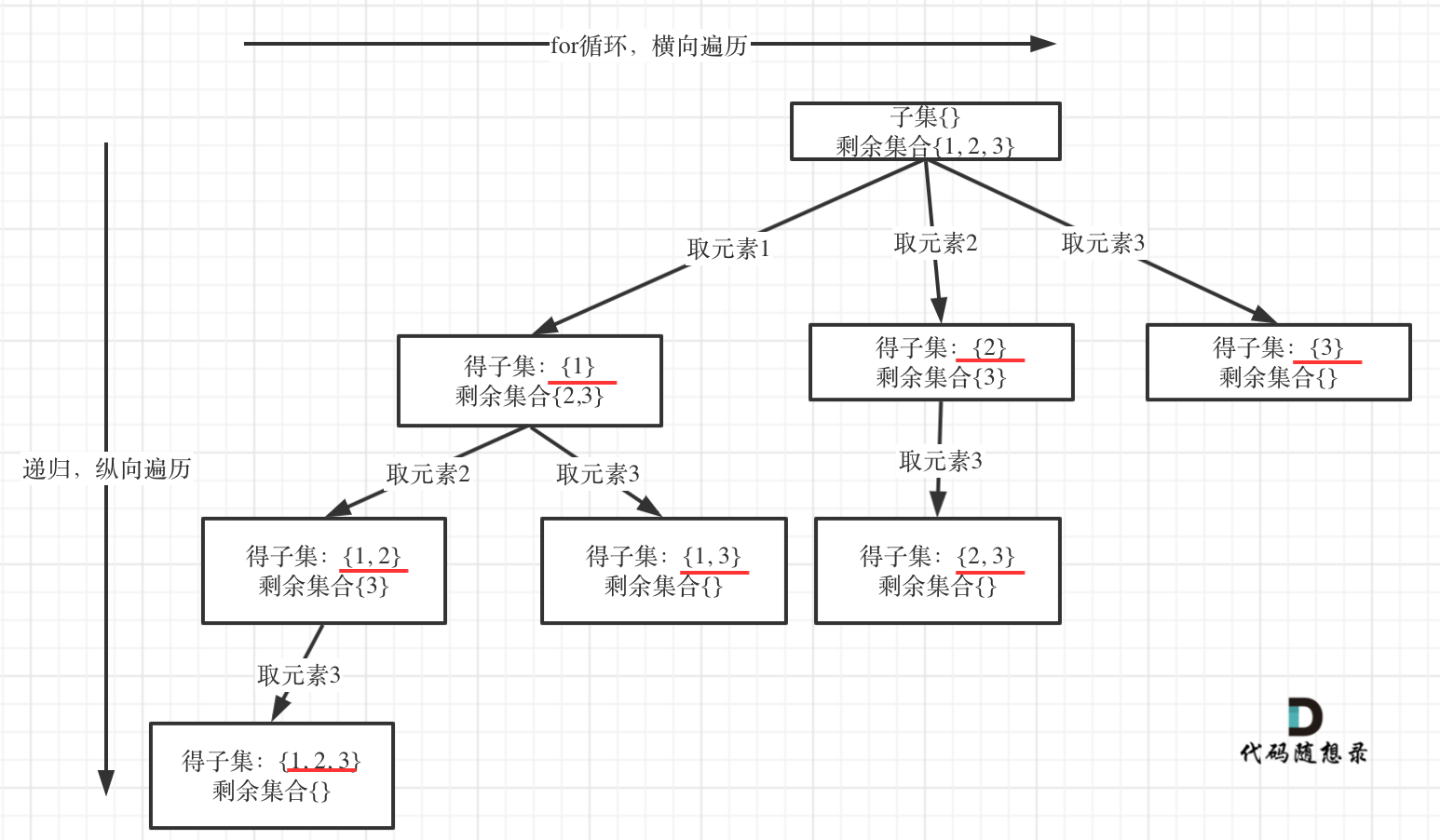
笔记(1)中是关于点云配准方向的,(2)和(3)(4)(5)中是点云变化检测和点云分割的,实际上我认为这两种任务的差别不大。都是密集的分类任务,主要是在变化检测中的双时相输入如何好的融合以及融合后映射到特征空间中。由于点云变化检测的论文较少,中间也看了不少的图像变化检测的论文。
DC3DCD-2023-IJPRS
DC3DCD: unsupervised learning for multiclass 3D point cloud change detection-Arxiv-2023
一种通过encoder-decoder,利用k-means进行聚类得到的标签反过来指导网络进行特征提取和变化检测,对于最终提取的特征还是通过k-means得到最终的结果。
基于DeepCluster的思想进行的无监督学习。而DeepCluster的基本思想是这样的,首先利用随机初始化的网络对于样本进行特征提取,一个分支对于提取的特征利用聚类算法得到伪标签,另一个分支利用分类层得到分类结果,使用伪标签对这些分类结果进行损失并驯良网络参数,注意由于k-means聚类结果的类别可能发生改变,因此分类层在每个epoch中都要重新初始化,这就意味着该epoch生成的伪标签是在下一个epoch中进行使用的。否则每次batchsize进行更新后都要重新初始化分类层,就会导致分类结果不理想从而导致特征提取网络不理想。
由于Conv本身就是提取特征的网络,即使是随机初始化,也能提取相对有效的特征,使得网络初始化的情况下就比随机分类的效果好,因此聚类算法能够得到不差的结果,然后训练网络,网络提取,不断迭代使网络的提取特征的能力不断增强。
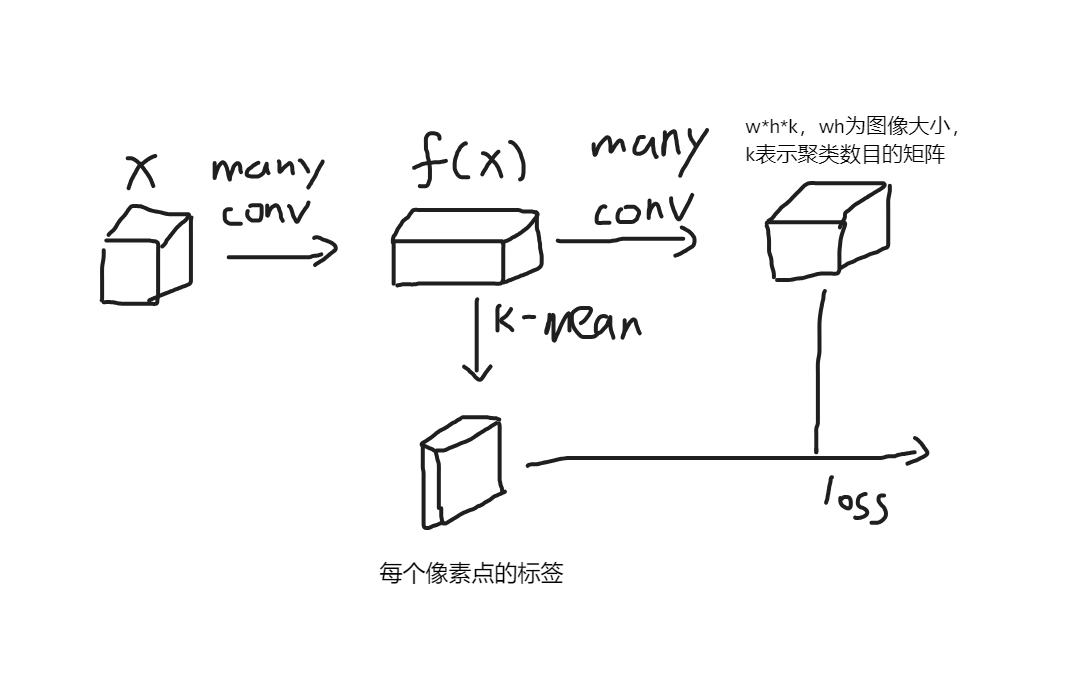
训练的一些trick:避免空簇(出现空簇的时候,将最多样本类别的样本分一半至空簇类别中)、基于类别的均匀分布(就是说最后每个类别样本采样数量要一样)对样本进行采样防止由于某个类别的样本过多导致网络专注于该类别。
网络架构
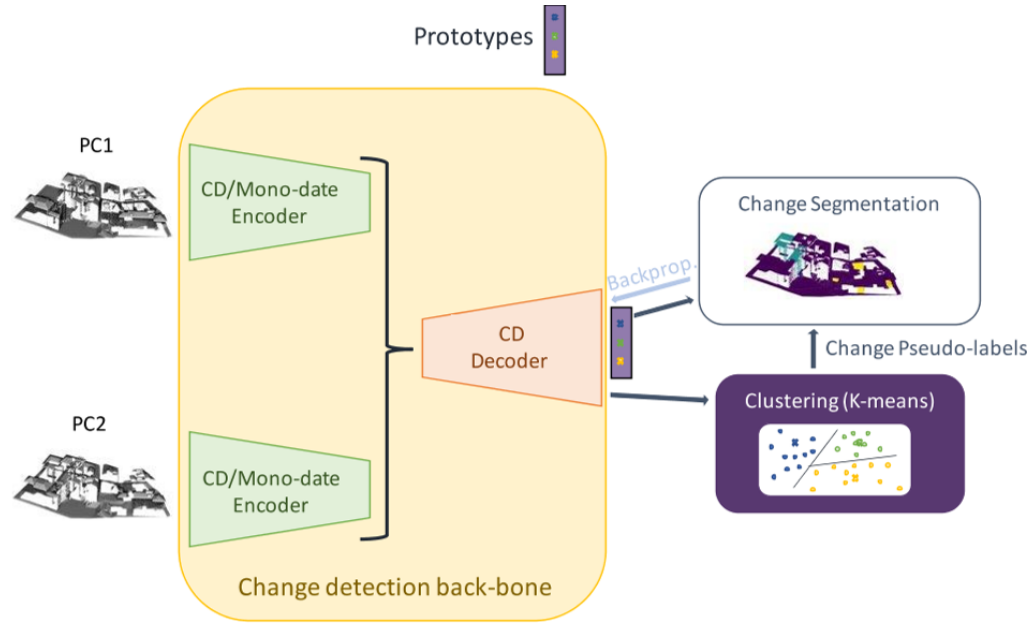
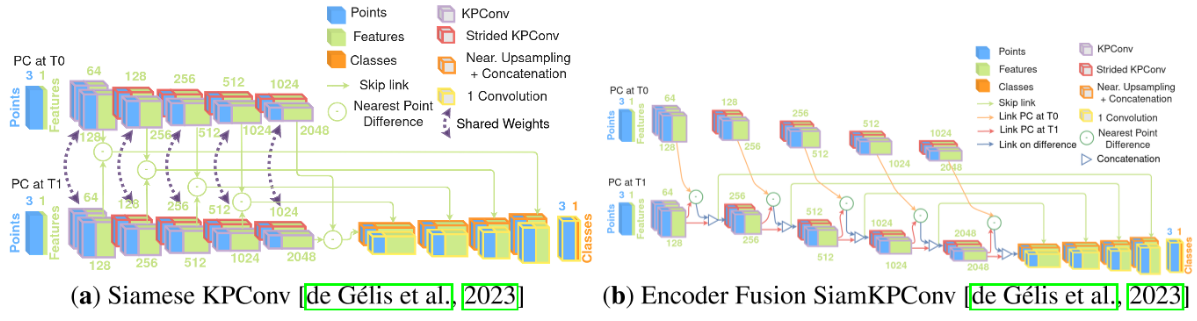
利用encoder-decoder提取点云特征N*D,对于提取的特征通过一个原型层(替代了以前的每个epoch随机初始化的全连接层,这里的原型层用上一个epoch中产生的聚类结果的中心点),得到了各个点的特征对于各个类别上一个epoch中的聚类中心点的相似度N*K,对于这个相似度使用k-means进行聚类,得到的聚类结果N*1对相似度进行更新。这样相比于1代的为了防止类不同需要随机初始化来说能够更加稳定的进行网络更新。这个原型层的参数在训练中是固定的,只在聚类步骤后进行更新。back-bone使用了Encoder Fusion SiamKPConv,同时考虑到仅仅输入点云坐标导致空间的搜索空间过大,以至于性能不够优秀,本文提出了拼接一些点云中的常用特征用于丰富特征的表达能力,使用了Tran在基于随机森林的变化检测方法中的特征[点分布特征(法线,领域点的分布信息),高度信息(垂直轴上的点等级,领域内的垂直方向最大高差,相对于本地数字地形模型的归一化高度(该点相对于地面模型的高度)),变化信息(当前点在两个点云中领域的点数的比例)]
实验方法
在实验的过程中,由于类不平衡的问题,本文采取了基于类别的采样,首先随机采样圆柱型的点云样本后,从点云样本中根据之前的epoch产生的伪标签进行采样,得到平衡的样本数量,同时在计算损失函数的时候对于不同的样本进行加权损失。
对于数据,还有数据增强的操作,将圆柱形的点云进行随机角度的装换即可。
对于K标注的选择,本文选择数量较多的K进行类别的划分,这样能够保证最终由人工进行选择的时候是将K个标签变为K‘个标签,达到最好的效果 K’<K,
数据集
Urb3DCD-V2和AHN-CD,由于AHN-CD数据集中存在标注不准确的问题,所以这个数据集的测试集仅用于定性评估。AHN-CD数据集还包括一个手动标注的测试集的子集,将用于定量评估和质量分数的报告和比较。对于Urb3DCD-V2数据集,子采样率(dl0)设置为1米,圆柱体半径为50米。对于AHN-CD数据集,由于两个数据集的密度不同,dl0设置为0.5米,圆柱体半径为20米。具体的内容在上面的SSL-DCVA中进行了详细的介绍。
标签K的选择
最终设置在K=1000,可以确保稳定的训练和合理的过度分割。太小的值可能无法反映所有不同类型的更改(因此不允许用户选择感兴趣的更改),而过大的值则会导致较高的训练和注释时间。实际数据集AHN-CD也将使用相同的值。
实验设置
动量为0.98的随机梯度下降法来最小化逐点NLL损失,batchsize=10,初始学习率为0.001,设置指数递减。聚类的此时根据实验发现每个epoch中进行重新聚类得到伪标签比多个epoch进行重新聚类得到伪标签的效果更好,多个epoch重新聚类得到伪标签容易在非最优的局部最小值收敛。共55个epoch,每个epoch中3000个圆柱对。
对比的方法
基于监督学习的Siamese KPConv和Encoder Fusion SiamKPConv,DSM-Siamese,DSM-FC-EF,RF,基于弱监督学习的k-means
与监督学习的方法比较的调整
由于监督学习需要标注数据,因此在进行DC3DCD网络训练时,对于每一个patch提供了1000个真实点云标签(一个patch大约3000个点),但是由于监督学习需要所有点的标注,因此对于训练集和验证集,有监督的方法只在7个类别之一为中心提取的14个圆柱体上进行训练,也就是说弱监督的方法可能有50个圆柱,但是有监督的方法只有14个圆柱,以便于最终的真实标签数据是一样多的。
评价指标
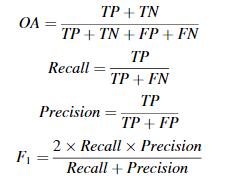
聚类质量:标准互化信息NMI
N M I ( Y , Y C ) = I ( Y , Y C ) H ( Y ) H ( Y C ) H ( Y ) = − ∑ i N p i l o g 2 p i I ( Y , Y C ) = H ( Y ) − H ( Y ∣ Y C ) NMI(Y,Y_C)=\frac{I(Y,Y_C)}{\sqrt{H(Y)H(Y_C)}}\\H(Y)=-\sum_i^N{p_ilog_2p_i}\\I(Y,Y_C)=H(Y)-H(Y|Y_C) NMI(Y,YC)=H(Y)H(YC)I(Y,YC)H(Y)=−∑iNpilog2piI(Y,YC)=H(Y)−H(Y∣YC)
Y表示真实标签中i类别的概率,Y_C表示伪标签中i类别的概率,如果 NMI 等于 0,则两个聚类是完全独立的。相反,如果 NMI 等于 1,则两个聚类之间存在完美的相关性,即其中一个是从另一个聚类确定性可预测的。
实验结果
对DC3DCD的训练过程的评估
NMI,主要用于训练时进行DC3DCD的评估
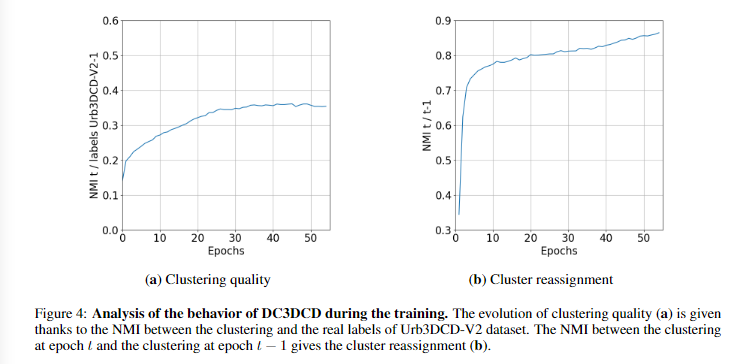
左图是和真实标签的NMI,右边是和上一次聚类结果的NMI。
随着训练的进行,聚类结果趋向于更接近真实类别,这表明模型在学习和适应真实数据的结构。在训练的后期(约30-40个训练周期后),聚类质量似乎趋于稳定。训练结束时,NMI大约是0.35,这虽然远离完美相关(NMI=1),但已显示出明显的进步。
图4b评估了从一个训练周期到下一个周期聚类重新分配的次数,这是通过计算两个连续周期之间聚类的NMI来衡量的。在最初的几个训练周期中,聚类发生了显著的变化,但训练很快收敛到相对稳定的聚类(NMI > 0.8)。
在训练的过程中,通过伪聚类分布的熵来判断其纯度。
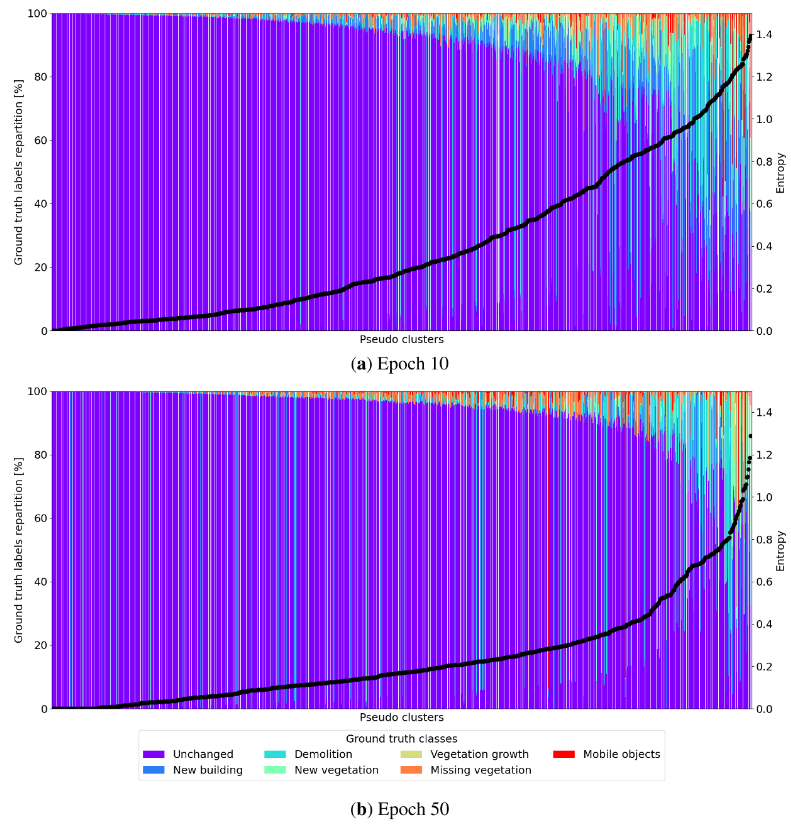
第10个和第50个训练周期的伪聚类分布。伪聚类按熵值升序排列。
从第10个到第50个训练周期,可以看到明显的改善。第50个周期的熵曲线下面积(图5中的虚线点)比第10个周期的小(平均熵值从0.39降至0.24),意味着整体熵值降低。80%的伪聚类具有大于或等于93%的“纯度水平”。这些结果证实了作者提出的用户引导策略的相关性,即在评估过程中,自动将伪聚类映射到占多数的真实类别。
模拟数据集Urb3DCD的结果
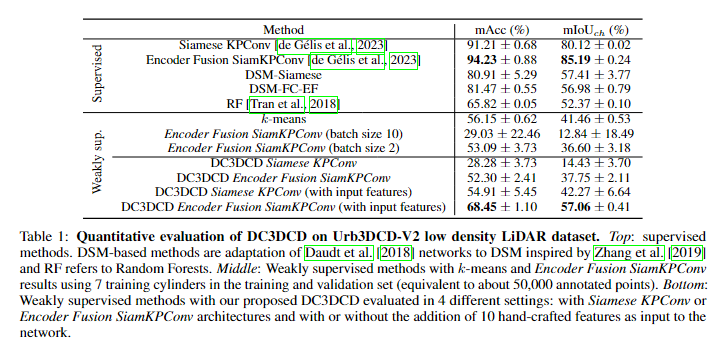
分析DC3DCD方法在不使用手工特征时的表现发现,无论是使用Siamese KPConv还是Encoder Fusion SiamKPConv骨干网络,其结果都相对较低。相比于使用相同手工特征的k-means算法(如Tran et al. [2018]中提出的RF方法),DC3DCD的这两种配置提供了较差的结果。Encoder Fusion SiamKPConv的表现明显优于Siamese KPConv。特别是,在mIoUch(平均交并比)指标上,Encoder Fusion SiamKPConv比Siamese KPConv高出约1.5倍。在监督学习环境中,Encoder Fusion SiamKPConv相比Siamese KPConv提升了5个mIoUch点。而在无监督学习环境中,选择合适的架构似乎更加关键。
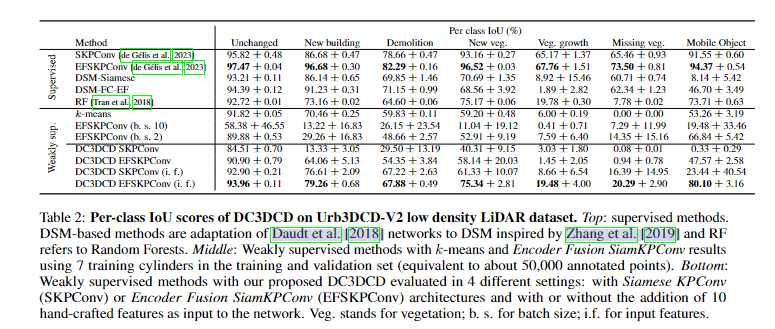
然后,当将手工制作的特征添加到网络的输入时,结果大大提高(cf.表 1 的最后两行)。虽然具有 Siamese KPConv 架构和手工特征的 DC3DCD 提供了与 k-means 算法相当的结果,但 DC3DCD 提供了手工制作的特征和编码器融合 SiamKPConv 架构的有趣结果。事实上,在这种配置中,与 k-means 相比,mIoUch 提高了 15 分以上。此外,具有这种配置的 DC3DCD 优于完全监督的 RF,并提供了与在 3D PC s 的 2.5D 光栅化上训练的完全监督深度架构相当的结果。因此,提供手工制作的特征是无监督设置中的重要一步。一种可能的解释是,由于大量可能的局部最小值,无监督版本很难训练。添加手工制作的特征可能有助于初始化更接近全局最小值。
鉴于所需的注释工作量较高(约 50,000 个注释点),弱监督设置中的编码器 Fusion SiamKPConv 提供了相当低的结果。批量大小为 10 的结果不稳定。这可以解释为每个 epoch 只看到一个批次,并使用与批量大小为 2 相同的学习率调度器。因此,这种训练更容易陷入局部最小值。
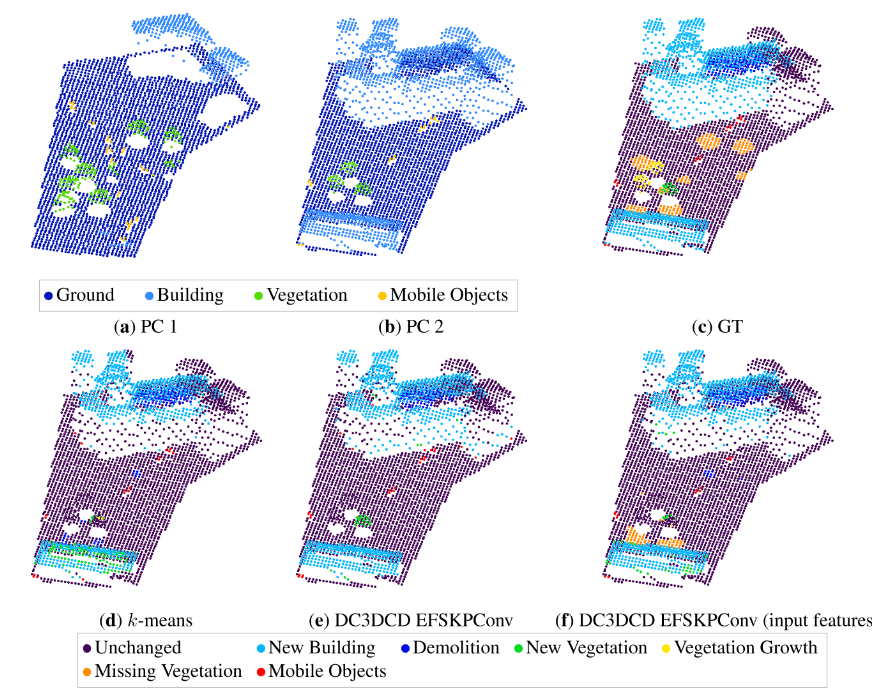
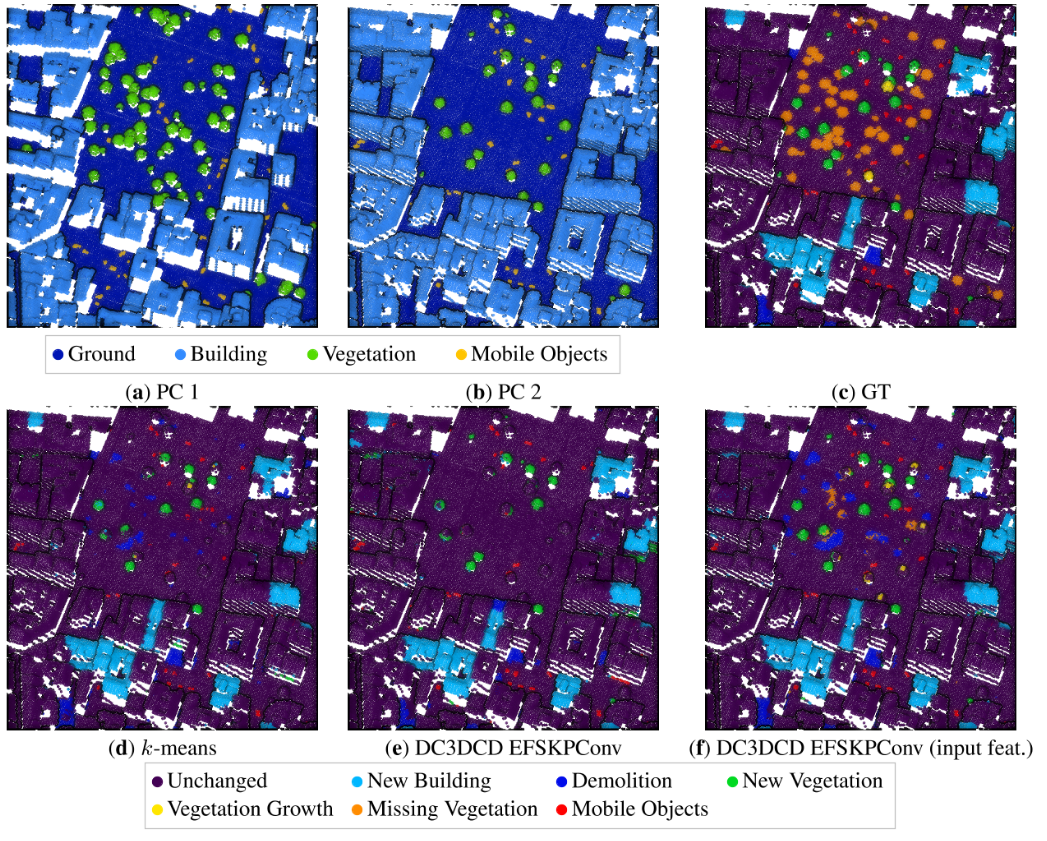
在图7中可以看到,主要的变化(如新建筑或拆除)似乎被k-means和两种DC3DCD配置都相当好地捕捉到了。但在更细致的分析中,一些误分类现象可以在新建筑立面(图6)或植被上观察到。对于新建筑立面,DC3DCD相对于k-means有所改进,但仍然不是完美的。k-means技术与RF方法有相同的倾向,将小型新建筑和新植被混淆,可能是因为它们的高度相似。如表2所示,DC3DCD方法在植被生长和缺失植被的检测上存在主要困难。这在监督学习环境中已经是最难的类别之一。缺失植被几乎总是被带有手工输入特征和Encoder Fusion SiamKPConv架构的DC3DCD方法误分类为拆除。而对于k-means方法,缺失植被的预测更加困难,没有手工输入特征的DC3DCD方法甚至从未预测出缺失植被。令人惊讶的是,移动对象的检测表现相对较好,尤其是对于带有手工输入特征和Encoder Fusion SiamKPConv架构的DC3DCD方法。
真实数据集AHN-CD的结果

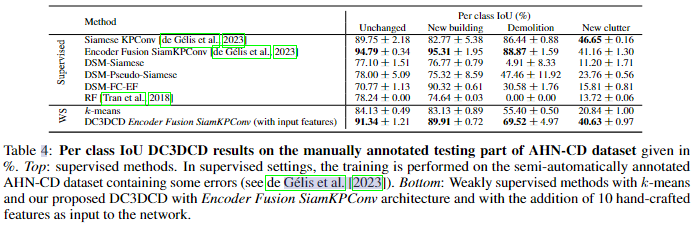
对于真实的AHN-CD数据集,手动注释测试集的定量结果如表3所示,每类结果如表4所示。为了比较,我们还提供了监督方法的结果。然而,我们记得它们是在包含几个基本真理错误的半自动注释的AHN-CD数据集上训练的。这解释了与使用手动注释集(如DC3DCD方法)映射到实际类的k-means相比,RF的结果较低。通过模拟数据集,我们可以看到DC3DCD提供了比k-means算法更好的结果。
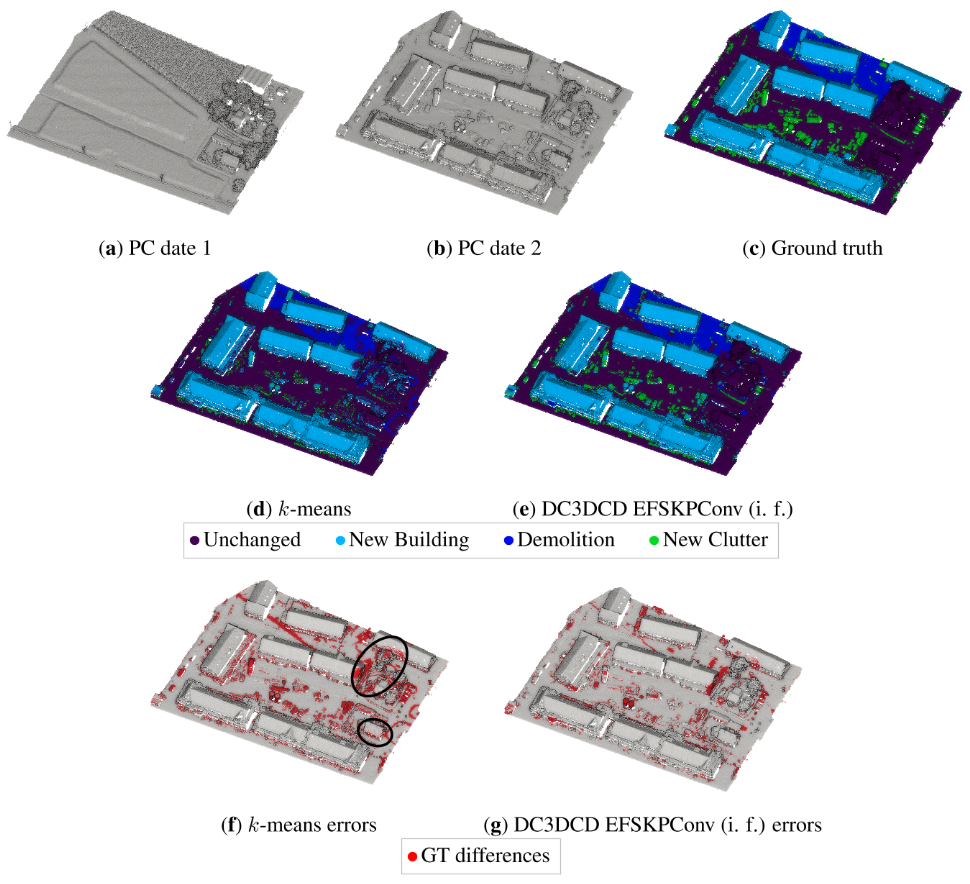
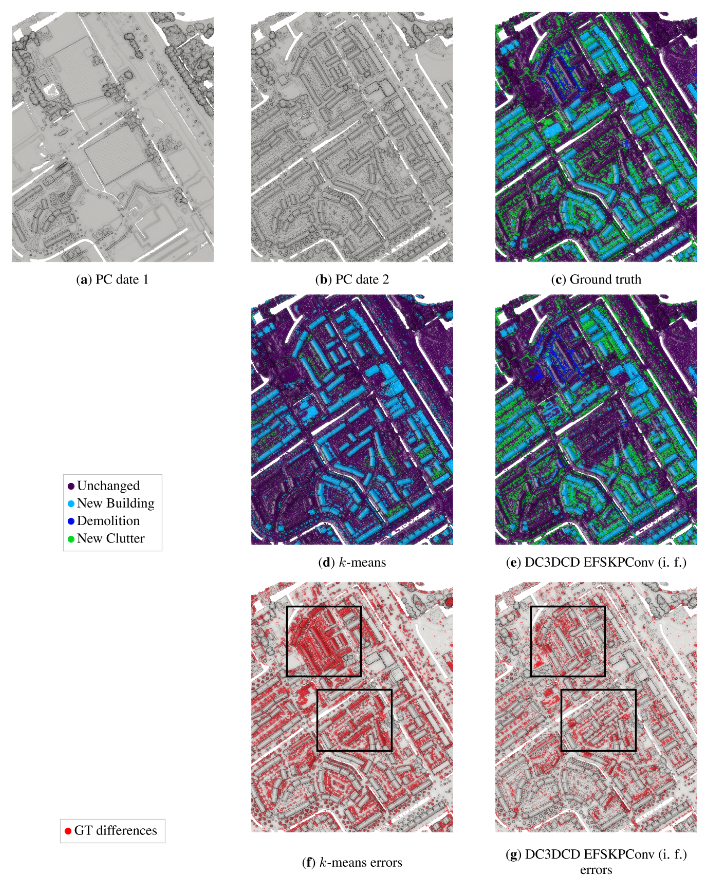
图8显示了两种方法的主要更改都可以很好地检索到。然而,在k-means结果中,诸如卡车之类的较大的杂波类对象与建筑物混在一起。在未改变的植被和未改变的建筑立面中也有很多分类错误(见图8f中感兴趣的区域)。就DC3DCD而言,未变化的植被被分类得很好。在一些“新杂乱”对象中可以看到一些错误。我们记得这个类是许多对象的混合,从植被到汽车或花园棚,当然解释了为什么它的分类得分较低。图9显示了一个更大的AHN-CD测试块上的补充结果。在de gsamis et al.[2023]中详细描述的半自动过程给出了基本事实。对于k-means方法和DC3DCD,到真实类的映射是使用这个基本真理执行的。在这个例子中可以看到,大多数“新杂波”类对象被省略或与新建筑类混在一起,拆除类也被k-means算法完全省略了(图9d)。在图9e中的DC3DCD结果中,杂波类似乎得到了更好的检索,尽管它并不完美,这意味着与基本事实的主要差异(图9g)。在图9中黑色矩形所描述的感兴趣的区域中,我们观察到DC3DCD似乎比k-means更好地适应用户上下文(即,根据用户定义的基本事实),尽管DC3DCD和k-means都执行了相同的基于真值的映射步骤,DC3DCD在处理建筑类别时似乎表现更好。在这里,建筑在真值中并未被标记为新建,DC3DCD的结果与此一致,而k-means则相反。在这块测试区域上,如果与真值进行比较,DC3DCD在平均交并比(mIoU)上获得了55.91%的得分,而k-means只有24.63%的得分。
结果分析
网络架构和输入特性的重要性
我们在结果部分看到,选择主干架构和添加手工制作的特征作为输入以及3D点坐标是至关重要的。这与DeepCluster的原始出版物一致,其中作者提供了图像梯度作为输入以获得有趣的结果。这些在无监督环境下的结果也强调了关于在特征差异上应用卷积的必要性的结论。为了解释这一点,让我们注意到,无监督环境在很大程度上是一个不受约束的问题。虽然注释允许抵消体系结构的弱点,但对于无监督设置来说,这确实不再可能。因此,选择一种架构,通过在多个尺度上从两个输入中提取特征差异的卷积,更专门地提取与变化相关的特征,并添加精心设计的手工制作的特征,允许将网络的训练引导到相关的最小值,从而导致可靠的变化分割。
使用对比学习改进DC3DCD
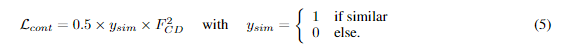
F_CD表示输出特征的L2正则化项,y_sim表示如果是未变化区域未1,变化区域为0,目的是强制使未变化区域的输出特征为0。
本文在均值深度聚类损失的基础上加上了对比损失进行实验,定量结果如下图
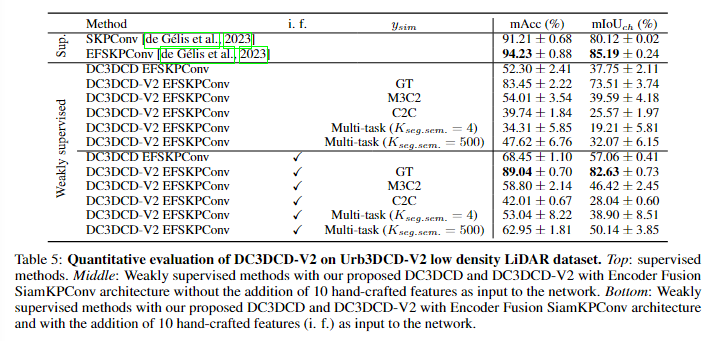
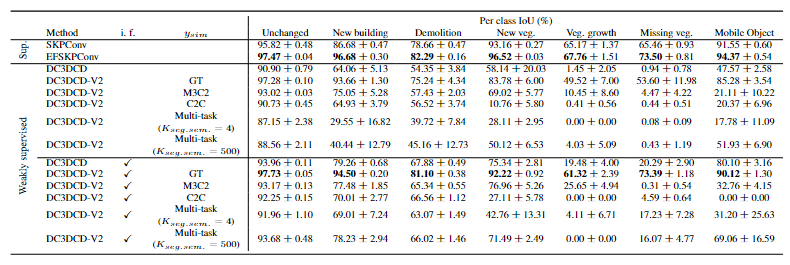
DC3DCD 在使用 Urb3DCD-V2-1 数据集上手工制作的特征的情况下达到了 73.51% 的 mIoU 和 82.63% 的 mIoU。我们记得在这个数据集上和完全监督的设置中,Siamese KPConv 和 Encoder Fusion SiamKPConv 网络分别获得了 80.12% 和 85.19% 的 mIoU。因此,对比部分的添加允许满足完全监督的结果(在ydata可知的理想情况下)。
我认为取得这么好效果的原始是在于使用了ysim这个真实已知的标注数据了,那么无监督学习其实只是在change类中再继续细分各种类别,因此才能够有这么好的效果。
因此本文又测试了使用其他无监督方法(M3C2/C2C)进行粗略预测ysim然后进行使用,但是使用M3C2确定的ysim,仅使得不使用手工特征的DC3DCD方法提高了2个百分点。当在训练中添加对比项时,如果使用手工输入特征,结果反而变差。使用基于M3C2的
ysim 时,获得的平均交并比(mIoUch)仅为46.42%。
我认为可能是错误的ysim导致一些原本能够正确区分的点反而被误导了。
本文还提出了使用多任务学习框架进行对比学习。
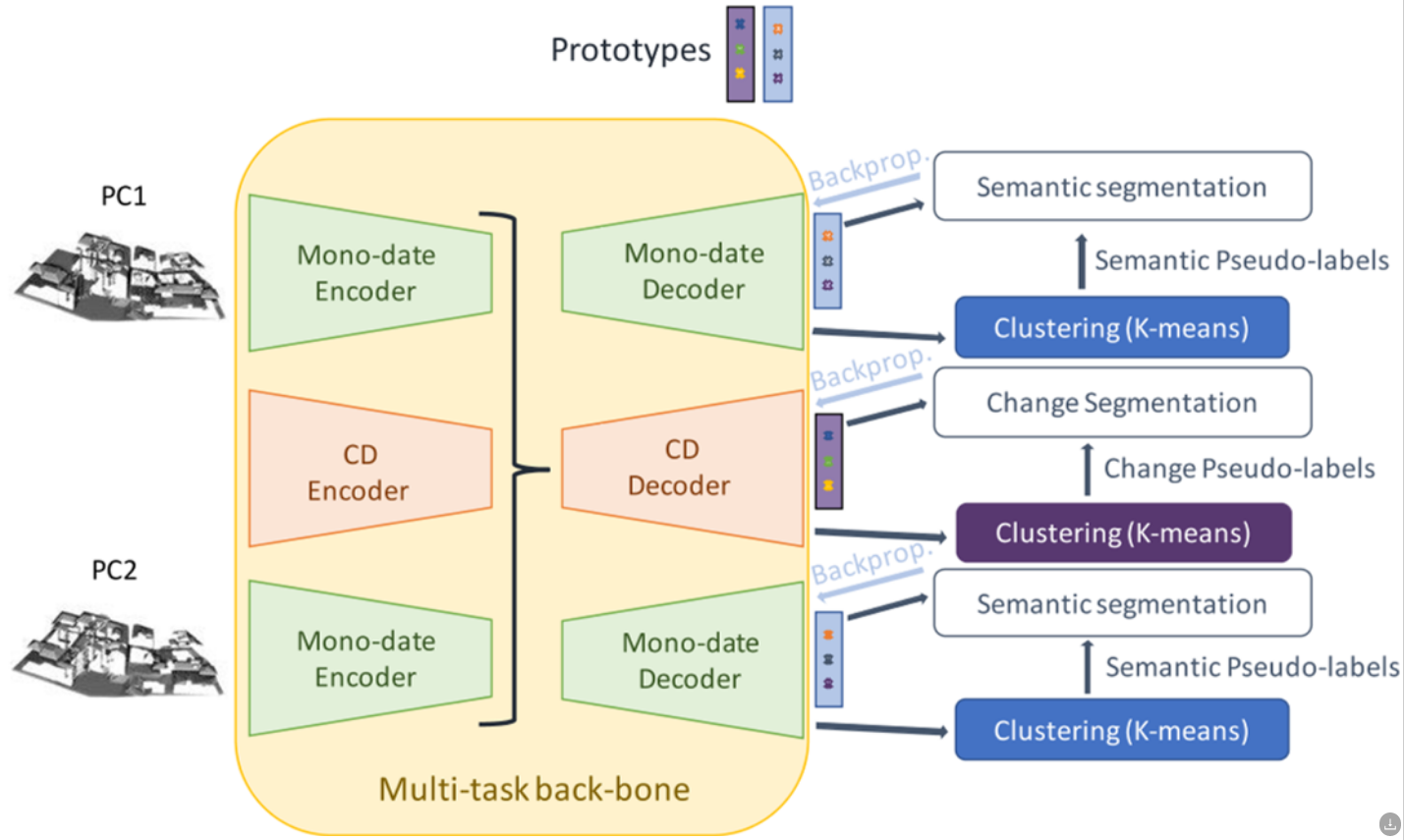
添加了一个单日期解码器模块,用于将提取的单日期点云特征解码,然后将解码后的特征类似于CD Decoder聚类训练啥的,训练完成后再测试阶段,首先进行单日期的特征提取,然后对二期点云进行最近邻特征差值计算,然后利用K-mean进行二值变化检测,然后将结果ysim提供给CD decoder。结果有所提升,但是还是不如直接进行的DC3DCD,因此,从最近的单日期特征差异点计算相似性似乎不适合。本文认为有两个原因,①最近的点比较差异在在遮挡部分和密集城市区域可能并不适用,②法预测了500个不同的单日期语义类别,远超真实类别数量,且没有保证在特征空间中语义上相近的两个聚类也相近,导致特征差异可能非常大。最后尝试在4个单日期特征聚类类别的情况下进行,但是结果更差了。
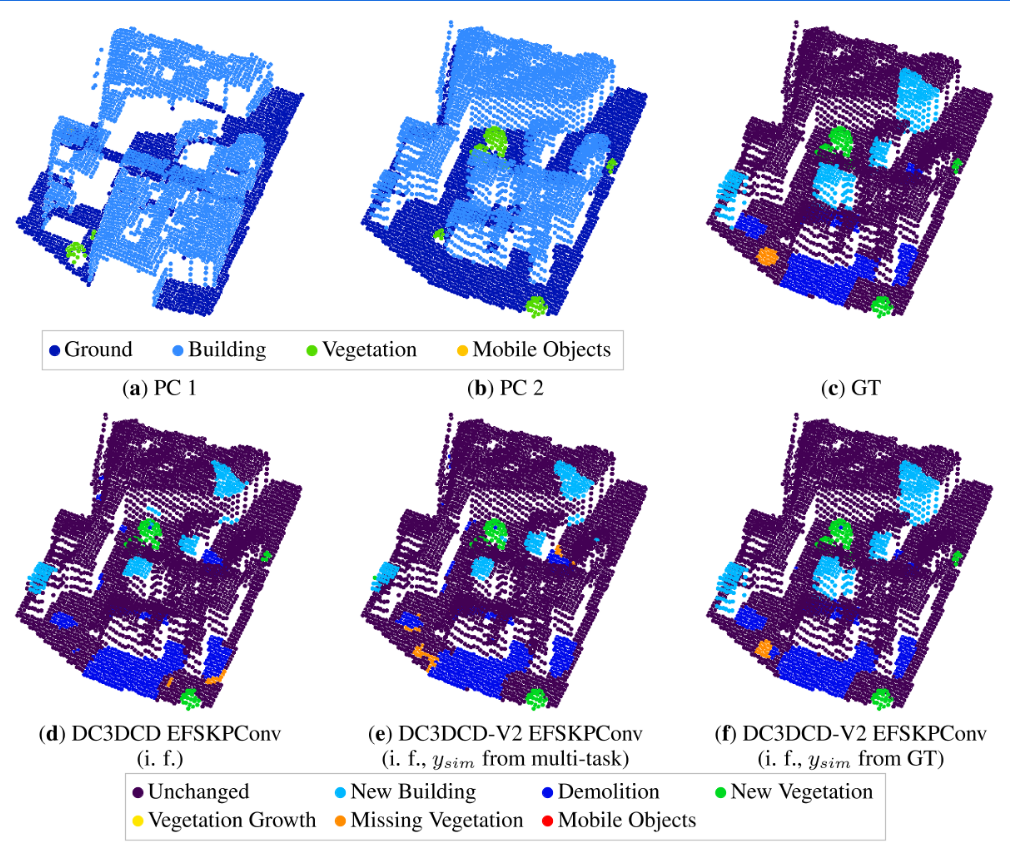
多任务的定性分析,当相似度来自于二元变化基础真值时,视觉结果与多元变化基础真值非常相似(图7h和11f)。多任务学习的定性结果相当令人鼓舞。令人惊讶的是,“消失的植被”的边界似乎恢复得很好,但中心仍然与拆迁混淆。所有这些实验都旨在评估对比损失的潜力,以改进我们的无监督结果。基于ground truth发布的相似ysim的结果非常有希望,因为它们达到了与完全监督网络相当的结果。然而,该方法高度依赖于二进制变化注释的质量,并且在二进制注释准确性一般的情况下,它会恶化DC3DCD结果。在我们看来,这些第一个透视图实验鼓励在保留有趣结果的同时限制注释工作。
FCCDN-2022-IJPRS
FCCDN:Feature constraint network for VHR image change detection-2021-IJPRS
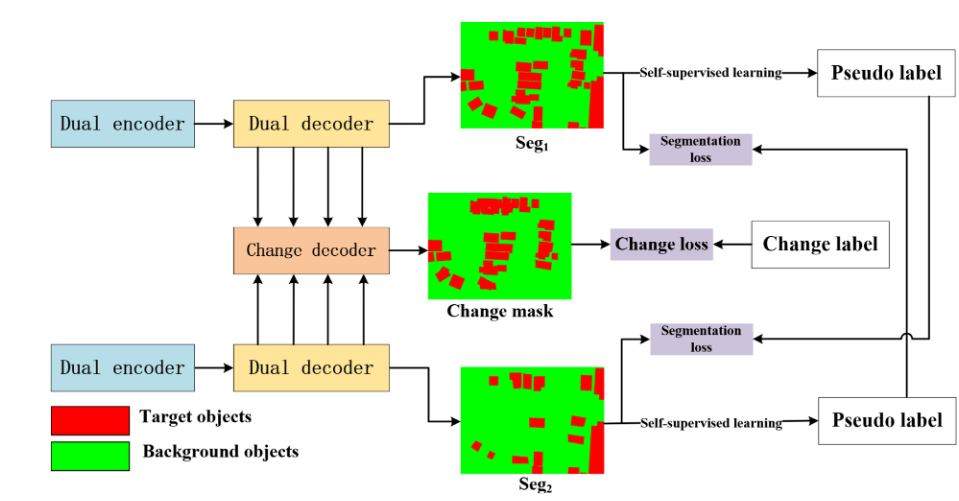
一种产生双时相语义分割图用于监督双时相特征提取并用于变化检测的网络架构。
提出的原因
①多数网络只关注特征提取和融合过程,忽略了变化检测任务的一些隐式约束,如双时相特征之间的关系
②大多数方法通过融合编码特征生成变化特征,这些低级特征可能会导致噪声推断
③双时相特征之间的特征不匹配问题,特别是当双时相图像中未改变的目标在特征空间上差异很大时,仍然缺乏有效的解决方案。(这个问题我觉得可以采样结合特征一致性的自注意力机制,可以让相似的特征倾向于提取相似的特用于加强表示,而不相似的特征提取自身用于分化表达)
网络架构
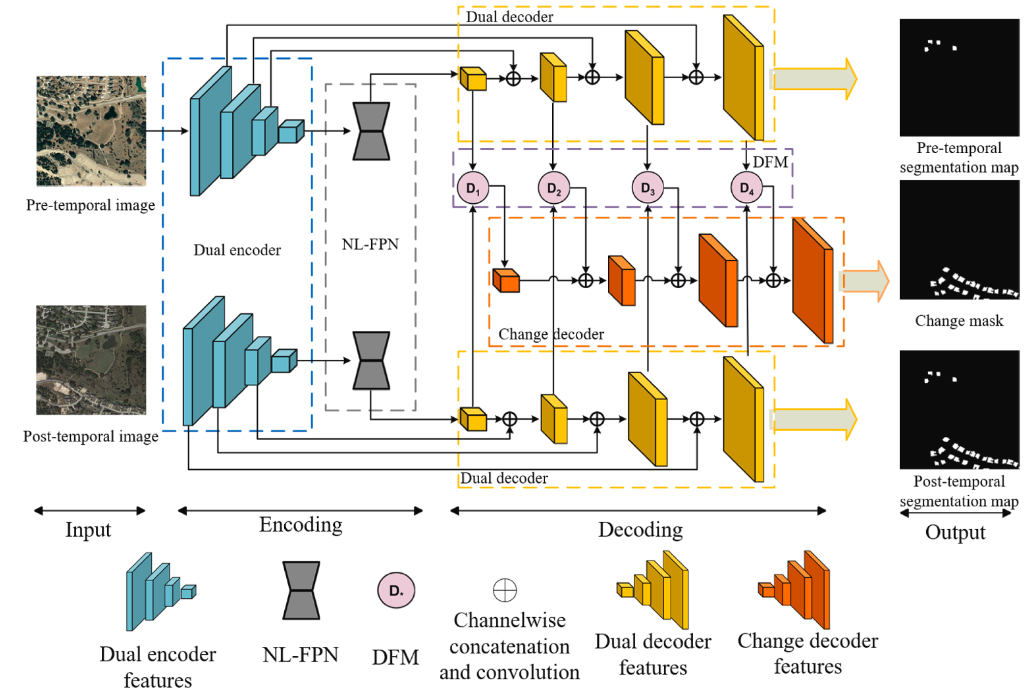
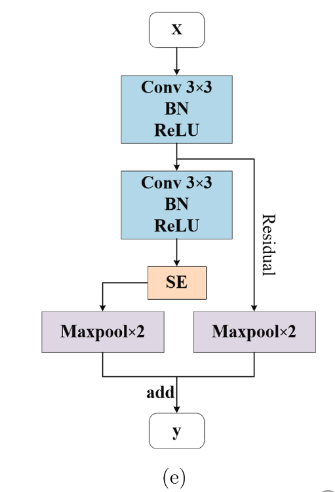
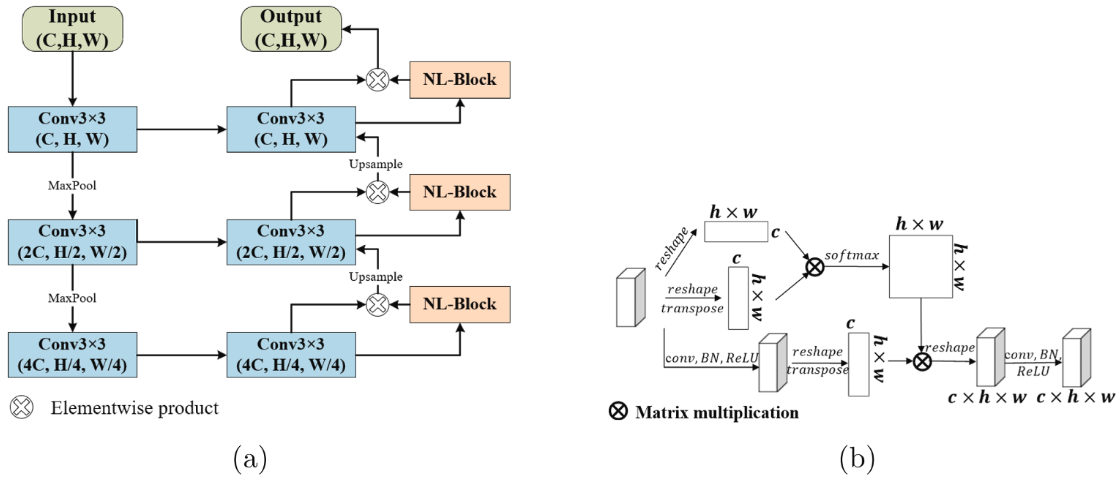
输入双时相图像,通过双分支结构提取特征,具体结构如(e),SE模块就是按照通道池化后,得到通道的加权,然后通过NL-FPN,利用伪transform结构构建非局部特征如下图。得到了建立了长程依赖关系后的特征进入解码阶段。
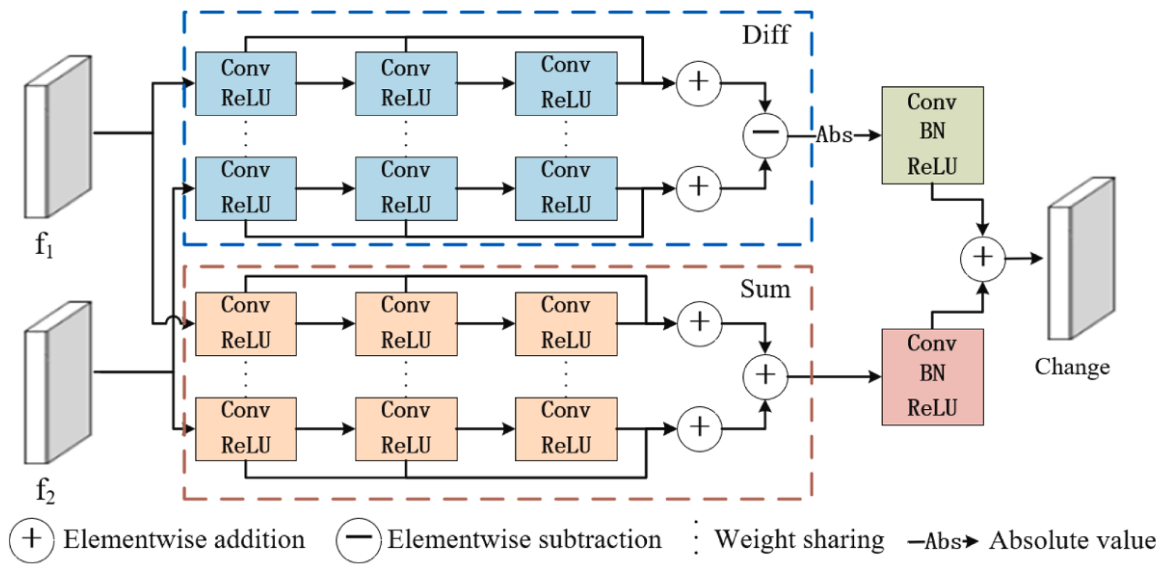
在解码的过程中,分为两种,一个是单时相解码的,一个是变化解码分支的,特征分支的就是正常的语义分割的网络架构,而变化解码分支的则如下图,一个diff分支用于生成变化特征,而Sum分支用于增强边缘信息。
本文中假设的都是在类间进行的变化检测,而不类内的,类内的使用语义分割的分支可能无法得到加强。对于二分类的变化检测,解码分支的训练SSL策略为判断为不变区域的就用另一分支的该区域的概率作为伪标签,如果是改变区域的就使用另一分支的该区域的相反作为伪标签,对于多分类的变化检测来说,变化区域就直接使用经典的语义分割架构,对于不变区域还是相同的方法。
实验方法
数据集
LEVIR-CD:本文中采用了两种裁剪策略,一种是将样本裁剪成256 × 256的小块,每边有128像素的重叠。另一种是将样本裁剪成512 × 512的较大块,每边有256像素的重叠。
WHU:之前有过详细介绍
SECOND:是一个多类别变化检测数据集,包括六个地物类别:非植被地表、树木、低植被、水体、建筑物和操场。该数据集提供了时序语义分割标签,用于表示变化区域中的地物类别。时序图像中的变化对象使用上述类别进行注释(在图中用不同颜色可视化),而未发生变化的对象被标记为背景(在图中用黑色可视化)。数据集包含2968个样本,每个样本的大小为512 × 512像素。
对比的方法
在LEVIR-CD数据集上,主要与STANet(Chen和Shi,2020)、BiT S4(Chen等,2021)、FracTAL ResNet(Diakogiannis等,2021)、CEECNetV1(Diakogiannis等,2021)、CEECNetV2(Diakogiannis等,2021)等进行比较。STANet是一个具有时空注意模块的孪生网络,用于生成更具辨别性的特征。BiT S4使用双时序图像变压器(BiT)来建模时空领域内的上下文信息。FracTAL ResNet、CEECNetV1和CEECNetV2是使用分形Tanimoto相似度度量构建注意模块和损失函数的孪生网络。这些都是最近提出的方法,并且使用相同的测试集进行评估。作者直接使用了它们在论文中提出的性能结果。
在WHU数据集上,选择了FC-EF(Daudt等,2018)、FCSima-diff(Daudt等,2018)、FC-Sima-conc(Daudt等,2018)、BiDataNet(Papadomanolaki等,2019)、BiT S4(Chen等,2021)、CDNet(Alcantarilla等,2018)、UNet++MSOF(Peng等,2019)、DASNet(Chen等,2020)、DDCNN(Peng等,2020)、IFN(Zhang等,2020)等作为比较方法。在这些方法中,FC-EF、FC-Sima-diff、FC-Sima-conc和CDNet是用于变化检测任务的经典全卷积网络。UNet++MSOF和DDCNN将配准的图像对连接到改进的UNet++网络中。BiDataNet是一种类似UNet的变化检测网络,它在跳跃连接中使用了完全卷积的长短时记忆(LSTM)(Hochreiter和Schmidhuber,1997)模块。DASNet和IFN是带有双注意模块的孪生网络,以学习更具辨别性的特征。所有上述基准方法都是基于DDCNN提出的划分方法进行测试的。
在SECOND数据集中使用了和WHU一样的基准方法。
实验设置
训练阶段
数据增强和预处理:
预处理就是归一化,数据增强伪①随机翻转(概率为0.5)②随机旋转(概率为0.3)③变换图像的HSV(概率为0.3)④放大/缩小图像(概率为0.3)⑤添加高斯噪声(概率为0.3)
batchsize在LEVIR-CD为16,WHU为64,SECOND为14,二类别的损失函数为BCE+骰子系数损失,多类别的选择CE+骰子系数,以上说的损失函数均为两个分支各自的。具体权重为1:0.2:0.2,adamW,初始学习率为0.002,权重衰减为0.001,通过观察验证集的F1分数在10个epoch内是否增加来调整学习率。如果没有增加,学习率降低0.3倍。本文发现,当学习率调整三次以上时,模型几乎收敛。因此,本文在学习率即将调整第四次时结束训练过程。由于模型在前30个历元远未收敛,我们直到第30个历元才用验证集验证模型。预训练模型对于提高模型的鲁棒性和不确定性至关重要(Hendrycks等人,2019),特别是对于使用小训练集进行训练。因此,在WHU数据集的实验中,我们使用在LEVIR-CD数据集上训练的权值初始化FCCDN的编码器。我们在图12中绘制了基线(FCS)和FCCDN在验证集上的性能。我们用红色表示FCCDN曲线,用灰色表示基线曲线。从图12可以看出,FCCDN在不超过220次epoch后就可以获得良好的性能。为了在测试集上进一步验证我们的模型,我们将具有最高验证精度的权重保存为测试的检查点。
测试阶段
简单的推理,验证集中最高F1分数的模型用于测试,不使用测试时间增强或多模型集成。
评价指标
IoU,F1,pre,rec
实验结果
消融实验
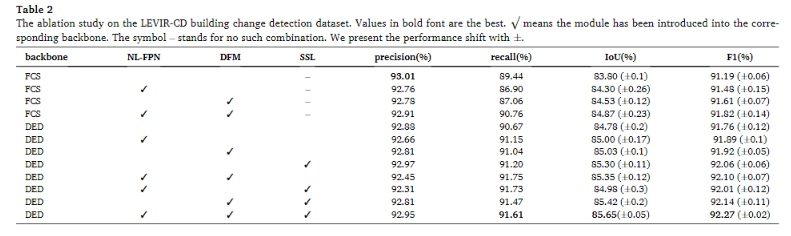
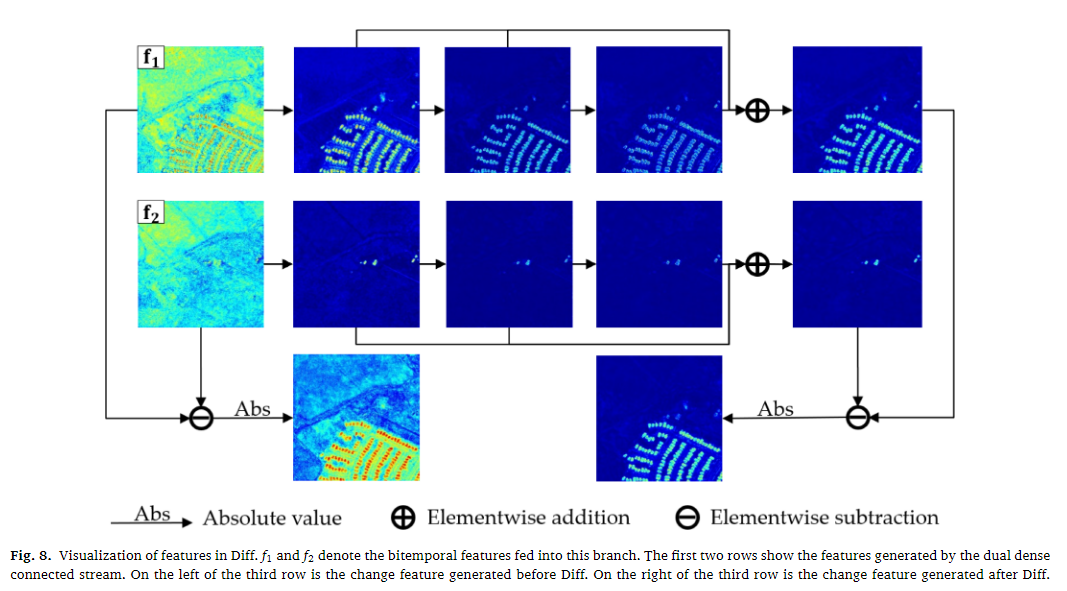
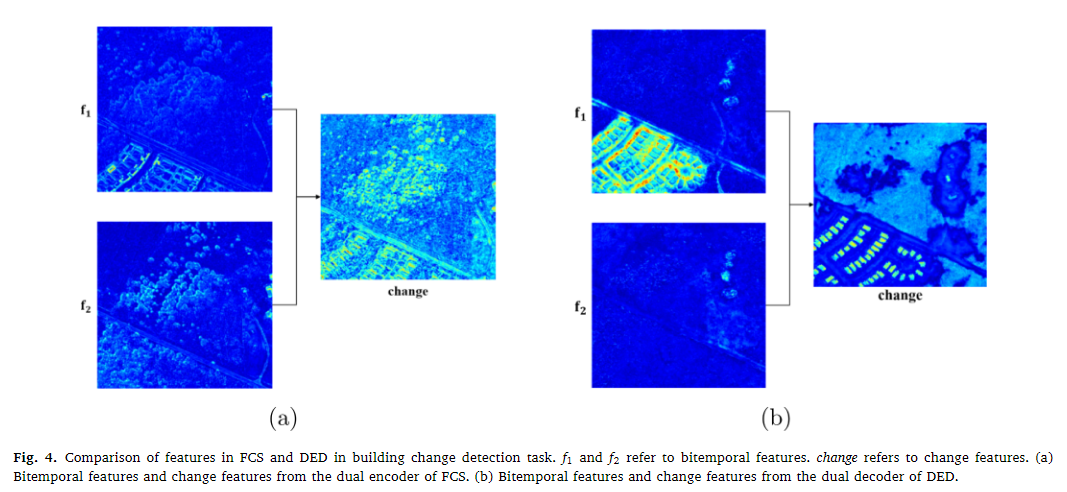
①FCS和DED的主干架构的比较
FCS有着最高的准确率,但是召回率较低,这意味着FCS更希望通过较低的召回率来保证自身的高准确率,而DED则在IoU方面取得了较大的进步,可视化结果如下图,可以看到,由DED主干网络取得的结果有着较为清晰的边界线和连续的区域。
②NL-FPN模块的消融
将NL-FPN用在FCS和DED主干网络中,都是在encoder和decoder中间进行的操作。性能展示在第二行和第六行,FCS中尽管pre和rec都下降了,但是在F1和IoU都有小幅度的提升。对于DED中pre下降了,其他的同样上升。可视化结果如下,同样有着可以看见的热力图聚集改善效果。

③DFM模块的消融
在FCS和DED都有着更好的效果,而且相比于NL-FPN来说,DFM有着更好的效果。相比于普通的直接做像素的相减的效果如下图,同样有着改善,将背景环境中的变化噪音给去除了。
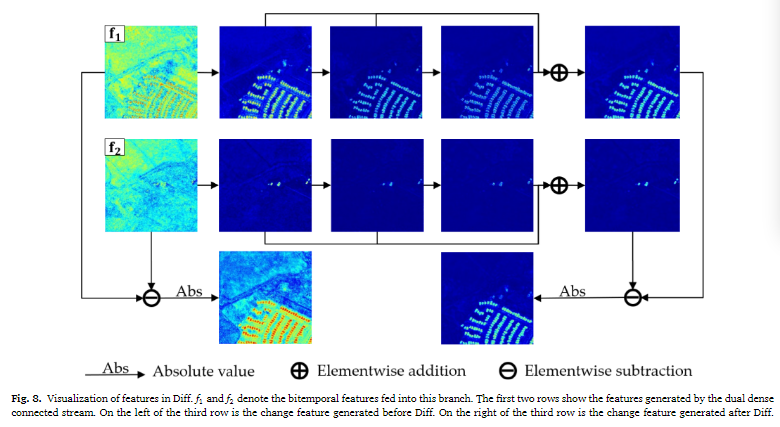
④基于SSL的特征约束策略
只使用了DED主干进行测试,在各方面都是有着提升的,而且相比于前两个模块都是有着更好的性能结果。
最终是在DED的架构下,在各种结构都使用的情况下,pre位于第二,Rec、IoU、F1都有着最好的性能。
LEVIR-CD数据集
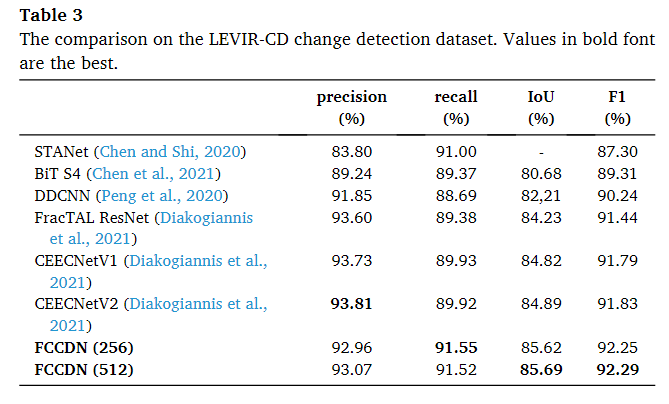
FCCDN除了pre以外,都有着最优的性能,可视化结果如下

如图13所示,FCCDDN在测试集上表现出色。几乎所有更改都准确地找到。我们需要注意建筑物边缘仍然存在一些显着差异,尤其是在第一行和第四行。这些差异主要是由建筑物的阴影引起的。很难识别确切的边界,因为一些边隐藏在阴影中。
WHU数据集
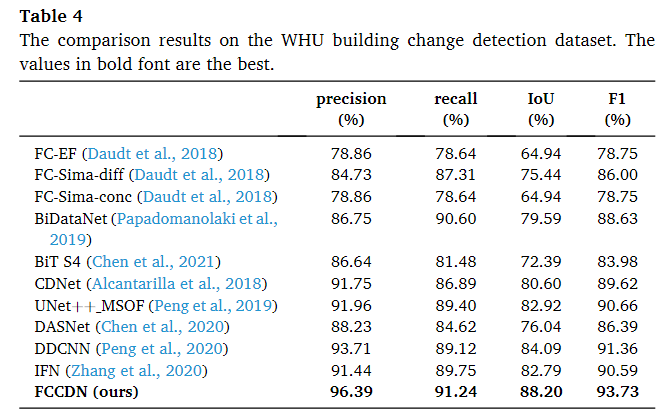
以极大的优势完成了最优的性能,在pre上优于第二5%,Rec同样有2%,IoU 4%,F1 2%,可视化结果如下图。

如图所示,FCCDDN在测试集上取得了良好的性能,优于比较方法。除了几个领域之外,大多数更改都得到了很好的识别。在第二行和第三行的顶部,我们的结果和比较结果都包含一些不正确的决定。这是可以理解的,因为很难识别图像边缘的建筑物。具有较大切片的推理可以表现得更好。在最后一行的中心,FCCDDN 的结果存在伪变化。然而,由于后时间图像中的建筑正在建设中,该领域的建筑变化确实存在。在最后一行的底部,FCCDDN 和比较架构都错过了很小的变化。这似乎是该数据集中的一个常见问题,也在 (Diakogiannis et al., 2021) 中提到。
SECOND数据集
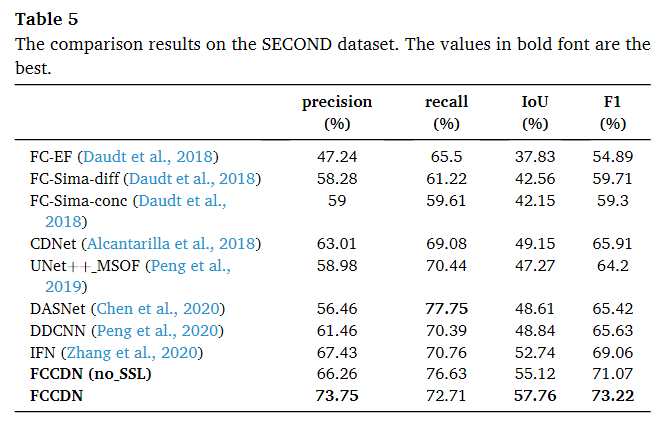
FCCDDN 在测试集上获得了最好的 IoU (57.76%) 和 F1 分数 (73.22%)。即使没有 SSL,FCCDDN 在 F1 分数中仍然优于其他测试方法,至少高出 2%。表 5 的最后两行表明,SSL 在 F1 分数中可以显着提高网络的性能,超过 2%。需要注意的是,虽然 DASNet 表现最好(77.75%),但其精度较低,引入了大量的伪变化。(见图 15)。可视化结果如下。
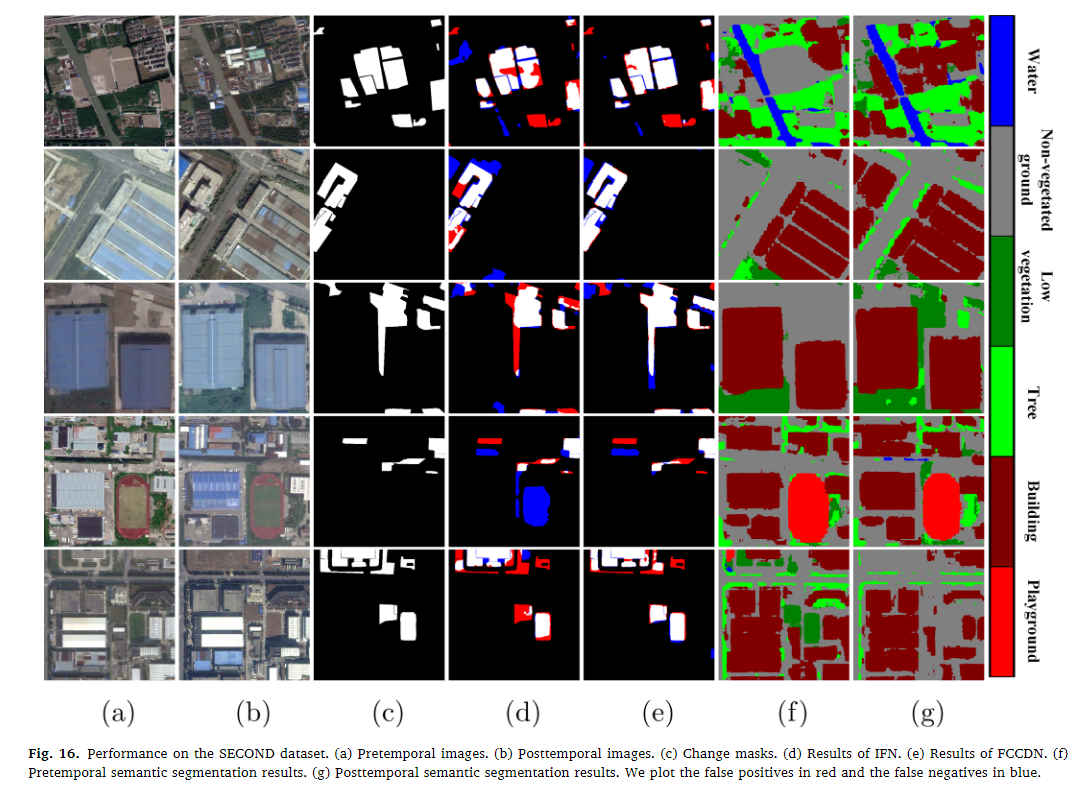
从图中我们可以得出结论,FCCDDN 在寻找变化区域和细化变化边界方面都优于比较方法。由于树木和低植被的变化,仍然存在一些错误分类。即使使用人眼也很难识别这些变化。我们将双时态语义分割结果可视化在最后两列中。在分割图中,大多数双时像素都被准确地分配给不同的类别。分割结果可以进一步证明 SSL 可以帮助网络提取更好的双时特征。
效率测试
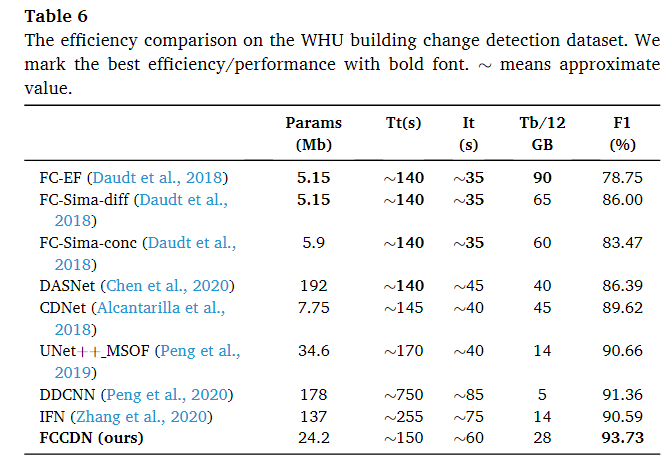
模型参数、训练时间、12GB内存的训练批量大小和batchsize=1的时候的推断时间。
在WHU数据集上评估了我们的模型效率,其实现细节与第4.3.2节中提到的相同。为了更好地展示FCCDDN的效率,我们还测试了几种现有的变化检测方法的效率(Daudt等人,2018;Chen等人,2020;Alcantarilla等人,2018;Peng等人,2019;Peng等人,2020;Zhang等人,2020)。表 6 显示了效率测试的比较结果。从表中我们可以看出,FCCDDN 在竞争效率下获得了最好的 F1 分数。
基于SSL的策略与对比损失策略的比较
由于基于 SSL 和对比损失策略都用于以无监督的方式约束特征学习,因此在本小节中介绍了这两种方法之间的差异。主要区别在于基于 SSL 的策略使用更严格的约束。对于对比损失策略,网络需要学习判别特征。未更改的特征被拉在一起,更改的特征被推开。然而,双时相图像中的地面物体没有区别。与对比损失策略相比,基于 SSL 的策略引入了额外的约束,将双时间特征分配给不同的语义类。通过对额外的语义分割分支的监督,通过比较双时间特征可以很容易地获得改变的特征和不变的特征。
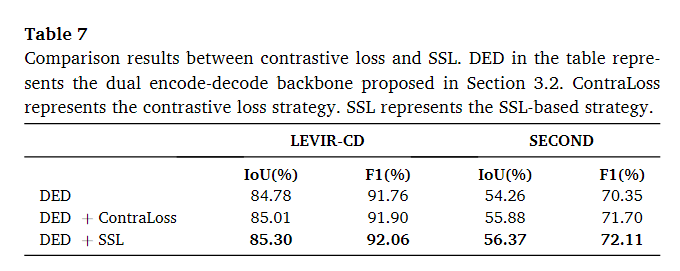
本文在 LEVIR-CD 数据集和 SECON 数据集上测试对比损失策略和基于 SSL 的策略。使用均方误差作为对比损失策略的距离度量。比较结果如表7所示。从表中可以了解到对比损失策略和基于SSL的策略都可以提高模型的性能。与对比损失策略相比,基于 SSL 的策略表现更好。在 LEVIR-CD 数据集上,SSL 在 IoU 方面优于对比损失策略,在 F1 分数方面优于 0.16%。在 SECOND 数据集上,SSL 在 IoU 方面的表现优于对比损失策略,在 F1 分数方面高出 0.49%。
局限性
①尽管引入了SSL的策略,但是在多类别以及change decoder分支仍然需要大量的标注数据,而对于变化检测来说,这种数据集是较难收集的。
②在类内的变化检测中,SSL策略的帮助可能不起作用(这点在DC3DCD中使用k=1000个分类来找类内的变化,然后后期人工将多余的分类进行融合得到最终的多类变化检测情况)。
CLNet-2021-IJPRS
CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery-2021-IJPRS
一种前期融合并通过卷积步幅进行多层级和多尺度特征融合的图像二值变化检测的网络。
提出的原因
①变化检测可以看成是对后期点云/图像进行密集分类问题,因此可以在语义分割任务的基础上做类似的架构布置,但是相比于单图像密集像素分类又有所区别,需要涉及到不同时间点的两幅图像进行
②变化检测中输入的特征在相同的地理位置会由于时间的推移而发生变化,也就是不发生改变的区域,也可能因为天气/光照等其他的原因带来特征的变化(这种情况在点云情况下有所改善),因此需要更加强大的网络结构准确的提取只和需要检测目标相关的特征(有时候一些语义的改变但是由于这种记录可能不被需要,所以在变化检测中放过了这种改变,这种就需要比天气这种更强大的网络了),用于变化检测。
网络架构
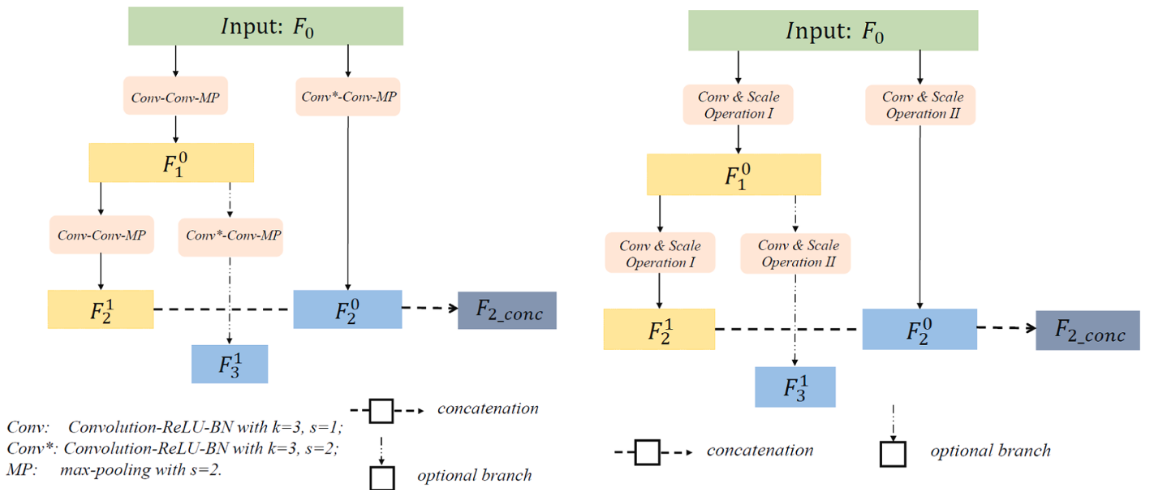
CLB模块中分为两个分支,对于CLB的两个分支,左分支采用了两个正常的Conv然后做步幅为2的最大池化,右侧做一个步幅为2的Conv和正常的Conv然后做步幅为2的最大池化,对于左分支的输出再次使用刚刚的两个分支,将左左分支和右分支进行拼接作为具有多级特征和多尺度特征聚合的特征,左右输出相当于具有更高语义的特征。

对于整体的网络架构,采用UNet作为主干架构,encoder中使用了两个CLB,其中第一次CLB1中输出的拼接特征再次使用CLB2,然后CLB2中的左特征和CLB1中的左右特征拼接作为输出,而CLB2产生的左右特征就舍弃了,拼接特征作为主干让网络继续,使用了一个MLP提取特征后和刚刚再次拼接的特征的左分支进行拼接,然后上采样卷积,将结果和第二次拼接的结果再次拼接后进行上采用卷积,然后和第一次结果拼接狗进行上采用卷积,然后和初始的左分支拼接后再做上采样卷积得到最终结果。
本文的损失函数就是加权二值交叉熵损失函数+λ骰子系数。
实验方法
数据集
VHR数据集:这个数据集包含从Google Earth收集的11对超高分辨率(VHR)遥感图像对,专注于检测所有对象的变化。这个数据集特别关注由于季节性辐射差异和不同分辨率造成的挑战,其中季节性辐射差异引起的变化(如不同季节的树木变化)不被视为“变化”,而汽车的出现或消失则被视为重要的变化。
LEVIR-CD数据集和WHU Building数据集(之前介绍过)
实验设置
adam优化器,β1=0.9,β2=0.999,加权α默认设置为0.5,λ为0.5,
对比的方法
UNet、DeepLabv3 (Liang-Chieh Chen et al., 2017)、CDNet (Alcantarilla et al., 2018)、FC-EF, FC-Siam-conc, FC-Siam-diff (R.C. Daudt et al., 2018a, 2018b)、FCN-PP (Lei et al., 2019)、UNet + ASPP、Peng et al. (2019),说实话对比的方法属实有点拉了感觉。
评价指标
acc,pre,rec,F1
实验结果
对于VHR图像
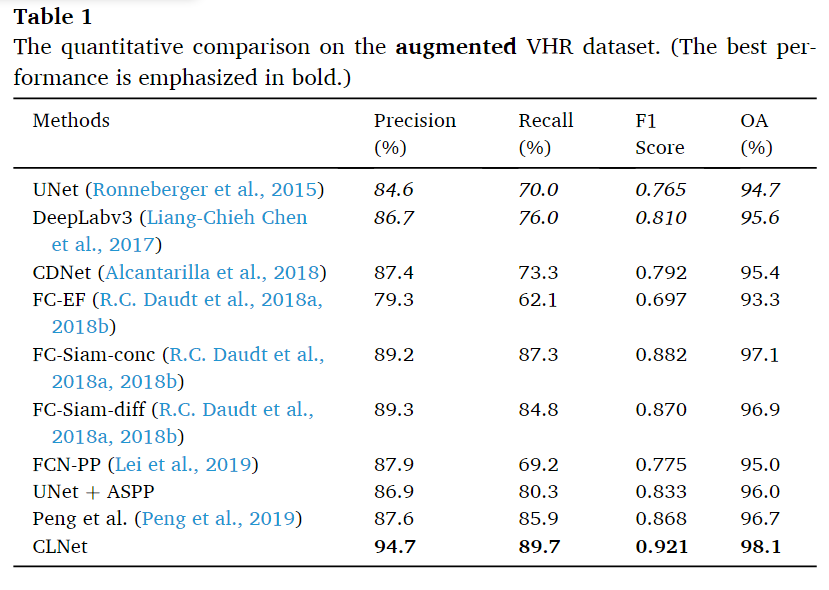
从表中法线,本文提出的方法在各个指标上都达到了最优的性能,并且相对于之前的方法有大幅度的提升。
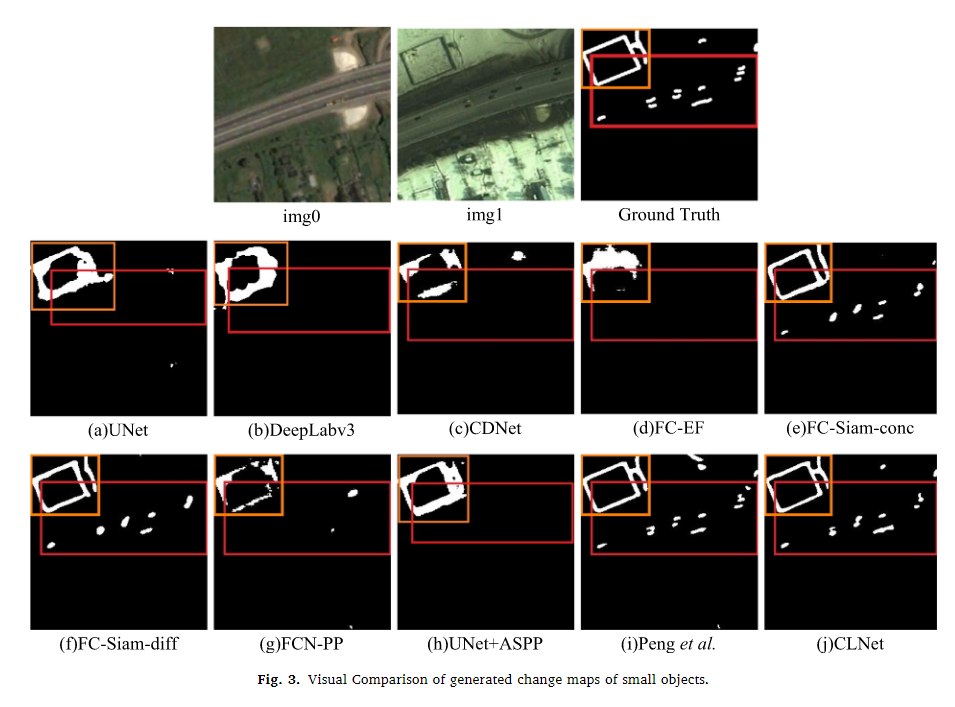

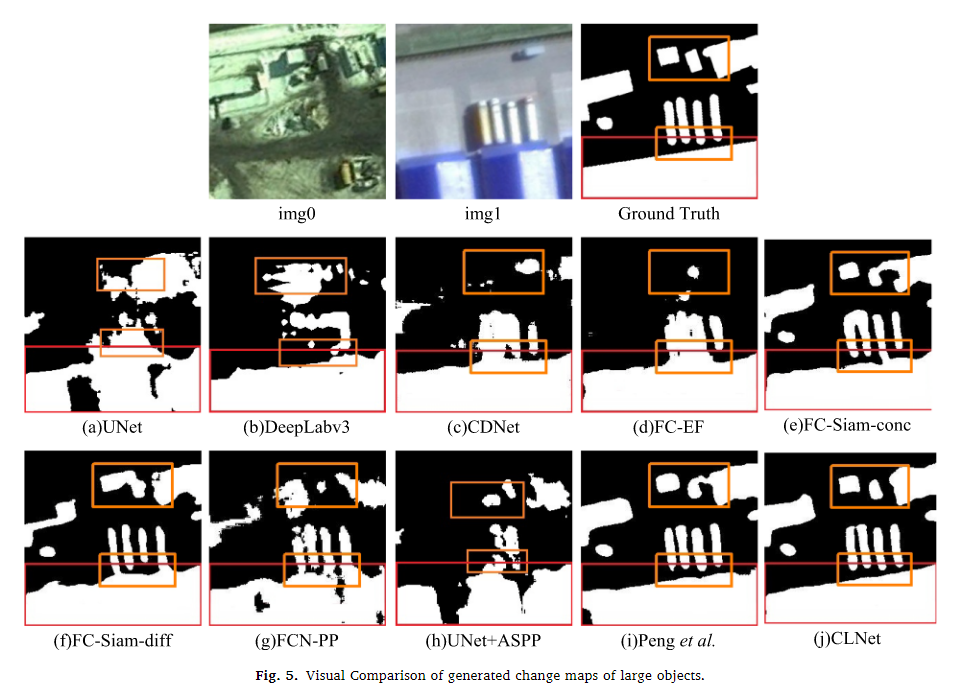

从图3-6的四种场景(小物体变化、细长物体变化、大物体变化和复杂场景变化)下的可视化结果中,CLNet和Peng等人(2019年)的方法能够检测到几乎所有小物体的变化(见红框内的变化图)。在橙色框内,CLNet和Peng等人的变化图与真实变化图几乎相同。CLNet成功检测到红框内的细节变化,并生成的变化图与真实情况最为相似,尽管在橙色框内有少量误报。其他方法在细长道路变化检测方面的效果较差。CLNet和Peng等人的方法比其他方法获得了更好的变化图。CLNet保留了更清晰的边界,在变化区域内没有产生不可解释的空洞(与其他方法相比,见图5中的红框)。CLNet有效区分了变化区域之间未变化的区域(见图5中的橙色框)。
LEVIR-CD数据集
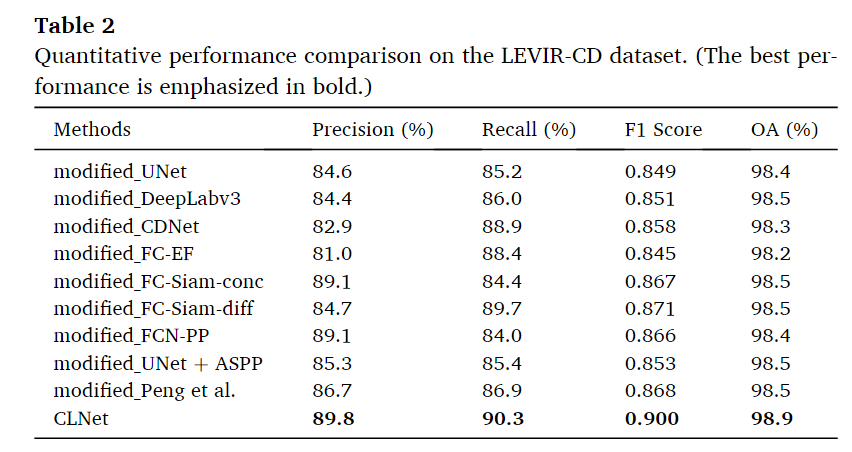
与改进后的方法结果相比,本文提出的CLNet在levirr - cd数据集上的准确率(89.8%)、召回率(90.3%)、F1 Score(0.900)和OA(98.9%)均达到最佳,验证了其检测微小变化的卓越能力,进一步体现了其鲁棒性


从LEVIR-CD数据集的测试集中选择两组变化图,对CLNet的性能进行定性评价。如图7和图8所示,与其他方法相比,CLNet获得了更好的视觉效果,误检和误检都更少(见橙色框)。此外,CLNet检测到的变化区域具有清晰的边界,而其他方法(即FC-Siam-conc, FC-Siam-diff, Peng等)往往将更多未变化的像素错误地分类为变化像素,从而获得不准确的建筑边界(见红框)。
WHU数据集
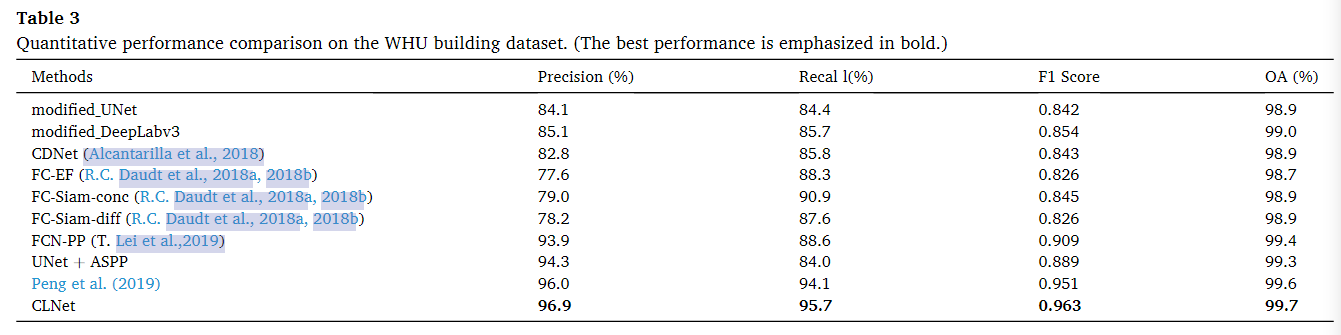
表3列出了WHU Building数据集的变更检测结果。可以看出,本文提出的CLNet在准确率(96.9%)、召回率(95.7%)、F1 Score(0.963)和OA(99.7%)方面仍然取得了最好的性能。需要注意的是,CLNet的召回率远高于所比较的方法(与Peng et al.(2019)的结果相比为1.6%,这是第二好的结果),这表明CLNet在变化不大的情况下检测到更多的变化区域。


从WHU Building数据集的测试集中选择两组获得的变更图,对CLNet的性能进行定性评估。如图9和图10所示,CLNet通过生成与地面真实情况最相似的变化图,获得了比其他方法更好的变化检测结果。图9显示了CLNet获得更清晰的建筑边界(图9)和发现真实变化(即忽略场景中不相关的汽车的出现/消失)的能力。从图10可以看出,CLNet可以很好地保留变化对象的实际形状,生成更精确的变化图。
消融实验
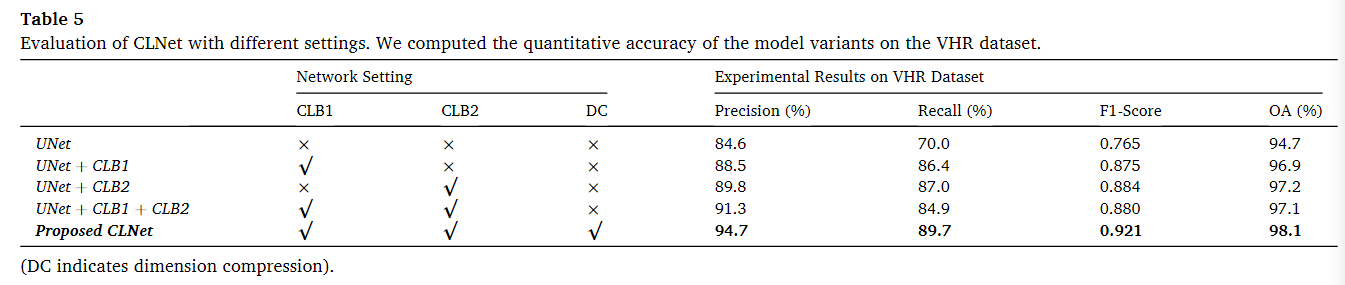
实验结果表明,所提出的CLB模块显著提高了变化检测的准确性,特别是在召回率(recall)指标上(例如,UNet与UNet + CLB1的比较)。CLB模块增强了场景理解能力,并能捕捉场景中更多的变化信息。当将CLB1和CLB2结合时,精确度略有提升(例如,相对于UNet + CLB2提高了1.5%),但召回率有所下降(下降了2.1%)。这种变化可能是由于引入了过多的高层次特征,因为CLB模块相比单分支网络引入了更多的高层次特征。
结论
本文提到的CLB通过卷积的步幅,将不同层级的特征和不同尺度的特征进行拼接达到了多层级和多尺度融合的目的,多层级融合可以用于使模型能够同时考虑到图像的局部细节和全局语义,从而提升特征的表征能力,主要是在语义上的补充。多尺度特征融合主要是提升对不同大小的事物的识别提取的鲁棒性,能够让模型适应大小不同的变化检测情况,对不同尺度的任何变化更加敏感。有利于变化检测图中边缘的完整性。
目前的经典的多尺度特征融合的方法:①inception block:通过不同大小的卷积层提取特征然后拼接,②PPM:通过不同的卷积层提取特征后,得到不同大小的特征图,通过上采样还原到原来大小然后拼接,③ASPP Block通过同一个卷积但是不同的扩展大小得到特征然后拼接,④CLB。
HRTNet-2021-IJPRS
High-resolution triplet network with dynamic multiscale feature for change detection on satellite image-2021-IJPRS
一种三元并行流提取双时相特征图像并利用差异图像进行特征增强,同时使用动态卷积Inception进行多尺度融合的图像二值变化检测网络。
提出的原因
①随着遥感图像分辨率的不断提高,没有充分利用高分辨率图像所包含的丰富信息。这导致CD方法无法灵敏地区分角度、气候和日照等伪变化。
②由CNN学习的高分辨率遥感图像的变化图中的边缘信息通常不理想。与低分辨率遥感图像不同,高分辨率图像的变化区域通常包含更多的边缘信息,应加以利用。(多层次多尺度)
③包含在双时间遥感图像中的时间信息没有被利用,如果被利用,这将有利于CD的性能。(引入了初始差异图)
动态卷积
相比于普通卷积的每层只使用固定的权重来说,动态卷积会根据输入来动态调整权重,首先动态卷积是由多个普通卷积进行加权得到的,而权重是由输入图进行全局平均池化,然后利用MLP生成的,因此动态卷积能够通过输入图进行卷积层的参数的改变。
网络架构
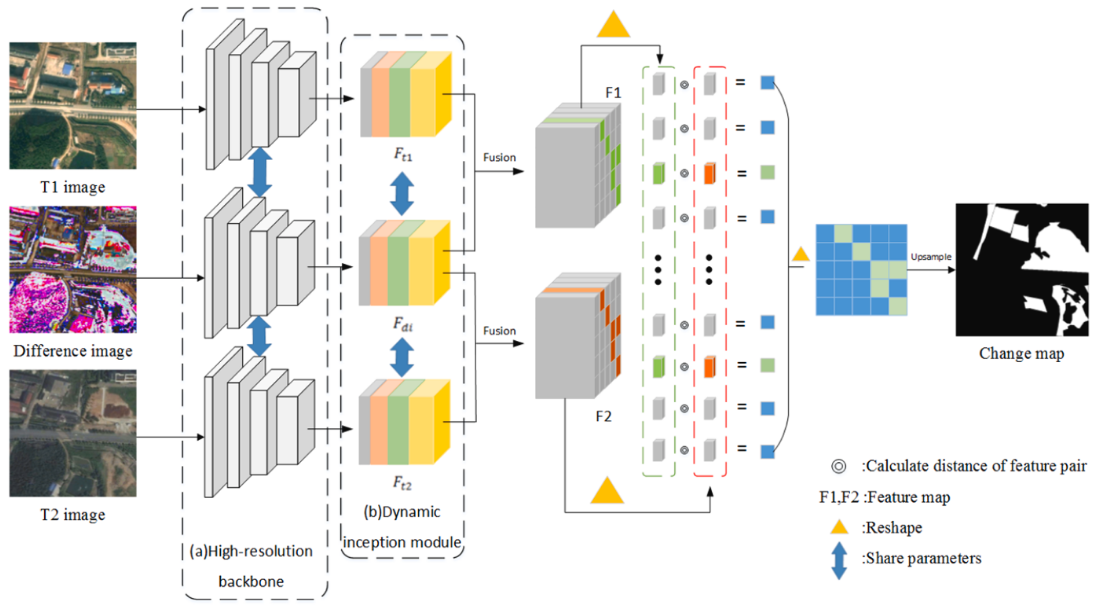
首先通过原始图像生成像素差异图,然后将三幅图像输入到网络中进行特征提取,提取到了特征后,对特征进行使用动态卷积的Inception,得到了多尺度的特征,然后将双时相特征分别和差异图特征相乘然后加上自己(resnet),比较生成的双时相特征的对应位置的特征距离。然后利用阈值进行最终的变化检测图的生成。
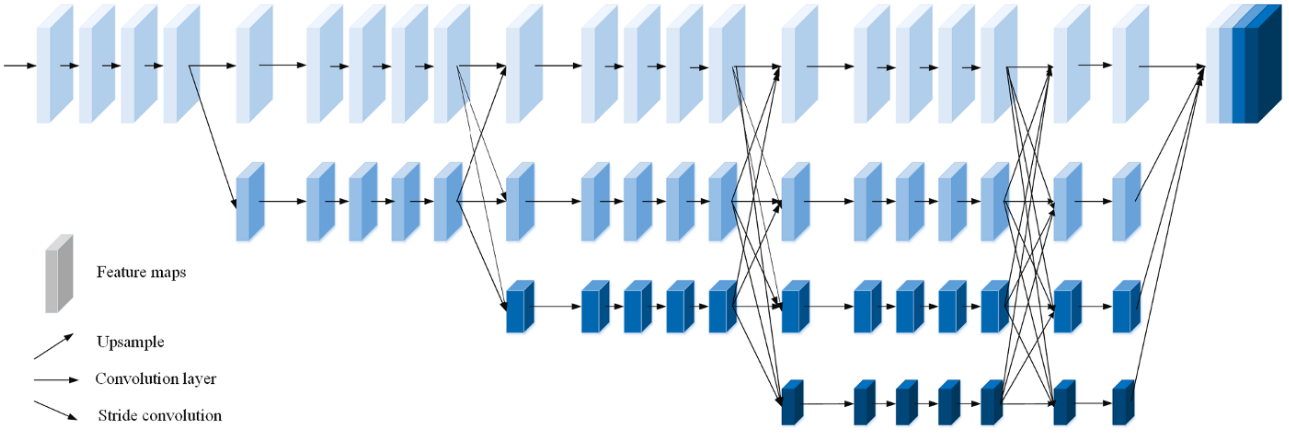
特征提取的网络结构如上,也是为了产生多尺度的一个特征融合,同时还有多层级(跳跃连接)的一个融合。
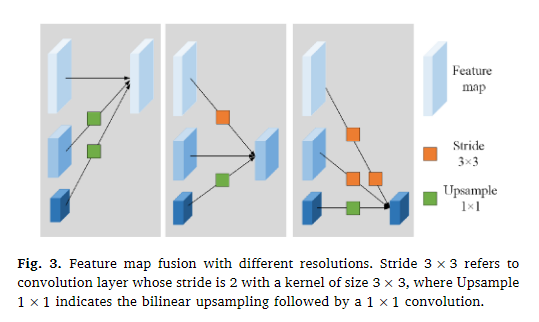
实验方法
数据集
由(Lebedev等人,2018)发布:该数据集的原始图像由11对多源遥感图像组成,分辨率从每像素3厘米到100厘米不等。(Ji et al.,2018)对原始数据进行处理,生成了一个由10000个256×256遥感图像对组成的训练集和一个由3000个256×256.遥感图像对构成的测试集。
(由商汤科技(SenseTime)在2020年举办的人工智能遥感解释竞赛提供的遥感CD数据集):包含2,968对512×512像素的双时相遥感图像。分辨率范围:从每米0.5米到3米。训练集和测试集按照8:2的比例划分,遵循文献中的常见做法。
LEVIR-CD
评价指标
rec,pre,F1,OA
实验设置
adam,初始学习率为1e-4,衰减率为5e-5,整个模型训练了60个epoch,相比的其他基线方法训练了100个epoch
对比的方法
FC-EF(全卷积早期融合(FC-EF),在通过网络之前将两个时间图像连接起来,将它们视为六通道图像。融合后的图像被“编码解码”,以获得变化图的映射输入)、FC-Sima-conc(Siamese 最终利用拼接进行后期融合)、FC-Sima-diff(后期使用差值的绝对值进行融合)、UNet++MSOF(彭等人受UNet++的启发提出了一种端到端的架构(Zhou et al.,2018),该架构将两个时间图像连接起来作为网络的输入,并使用UNet++来学习视觉特征表示。同时,它采用了多输出融合(MSOF)技术来进一步改善空间细节。)、IFN(前面看过这篇文章)、DASNet(Chen等人提出了一种用于CD的双注意全卷积连体网络(DASNet),能够学习双时间图像特征,并具有加权双边缘对比损失,以提高变化检测的性能。请注意,在列别捷夫数据集上,DASNet代表了最先进的性能(SOTA))、STANet(Chen等人提出了CD的时空注意神经网络(STANet),该网络使用暹罗FCN提取具有自注意模块的双时态图像特征图,以生成更多的判别特征。度量模块也被用来获得变化图)。
实验结果
Lebedev数据集
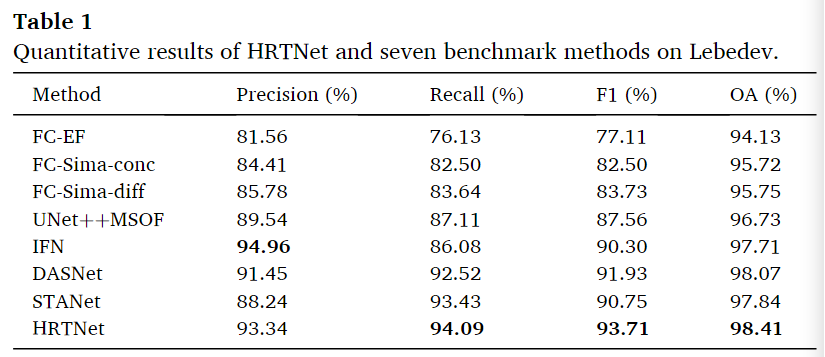
从表1中可以看出,HRTNet的整体性能最好,召回率(94.09%)、F1得分(93.71%)和OA(98.41%)均最高。这是因为通过所提出的方法学习的高分辨率深层特征更具代表性,使用动态初始模块获得了丰富的特征信息。在召回率最高的情况下,并没有损失多少的精确度(排名第二)。而且这种精确度第二的原因还有可能是IFN中对于不平衡类的损失函数使用了加权损失函数导致的。可视化结果如下图。
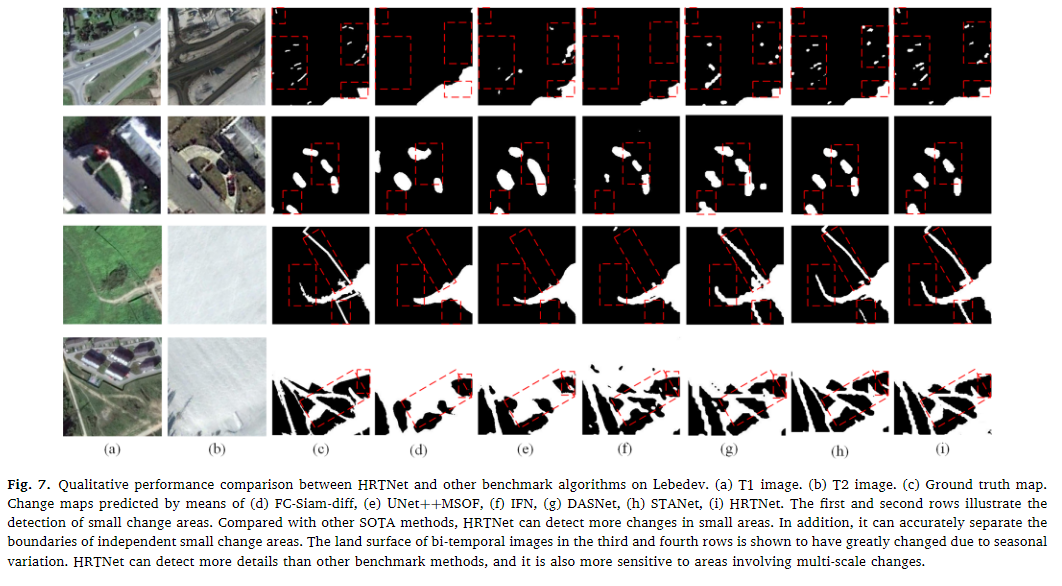
在不同条件下的定性分析如下图

从第一列可以看到在对于小面积的变化检测方面,HRTNet是能够很好的检测到的,而且对于土地表面几乎完全发生改变的情况(二三列),依然能够很好的检测出变化区域和非变化区域,这种覆盖在雪地中的小规模和极大规模的变化都能够较好的找到说明了模型对于不关心的变化的适应性是极强的。从第四列也可以看到,对于树影这种伪变化也能很好的区分,而对于最后一列可以看到两个图像是极其模糊的,加入了大量的噪声进行一个干扰,但是HRTNet仍然取得了很好的变化检测图。HRTNet能够识别不同规模的变化区域,同时减少伪变化和噪声的影响。
SenseTime数据集
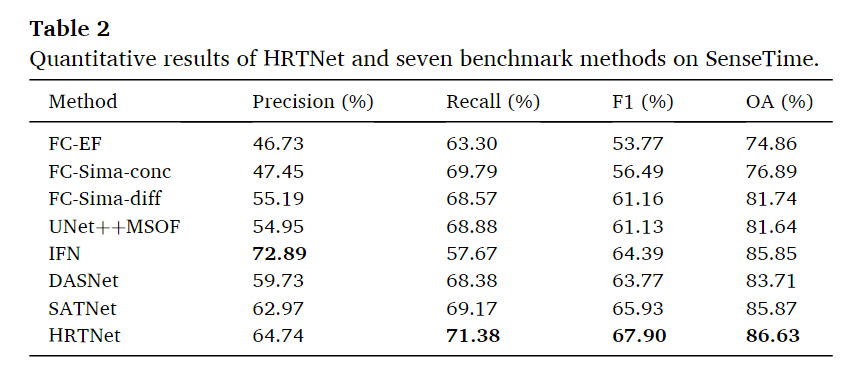
同样也是在除了Pre的指标上均达到了最优的性能。对于其他的方法FC-EF(一种早期融合方法)的整体表现最差,具有最低的精确度、召回率、F1分数和整体准确率。FC-Sima-conc(基于后期融合的方法)相较于FC-EF有所改进,特别是在召回率和F1分数方面。这是因为FC-Sima-conc通过跳跃连接提供单一图像的深层特征来帮助重建原始图像,保持变化图的边界连续性。FCsima-diff探索双时相特征中包含的差异信息,因此比FC-Sima-conc取得了更好的结果。UNet++ MSOF(也是一种早期融合方法)在不同语义层面融合变化图,每个评估指标都优于FC-EF。IFN由于融合了深度特征和差异特征,并使用注意力模块,因此在精确度上表现最好。但是,由于算法对双时相图像上的噪声和伪变化不敏感,因此其召回率较低。定性比较结果如下图。

LEVIR-CD数据集
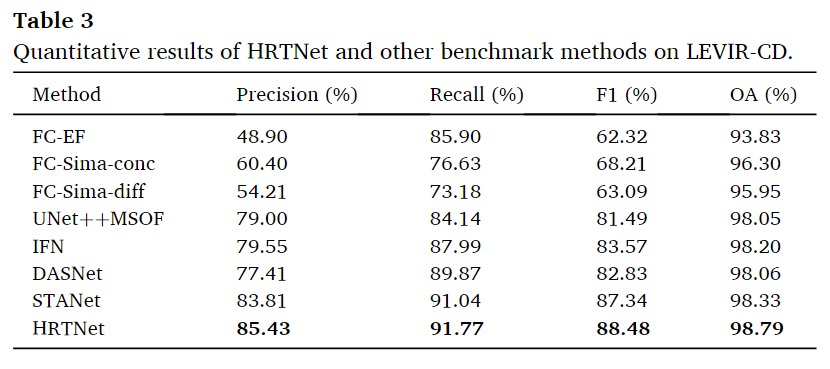
在LEVIR-CD数据集上,HRTNet的性能最佳。HRTNet在以下指标上取得了最高值:精确度(Precision,85.43%)、召回率(Recall,91.77%)、F1分数(88.48%)和整体准确率(OA,98.79%)。STANet和HRTNet都是基于度量学习的方法,它们在变化检测(CD)任务上的表现优于其他方法。度量学习是一种通过优化距离或相似度度量来提升模型性能的方法。
定性比较结果如下图,可以看到,HRTNet更加的善于预测建筑物的边缘信息,这也说明了差分图在网络中起到了强化边缘的作用。

消融实验
三个图像并行输入的结构
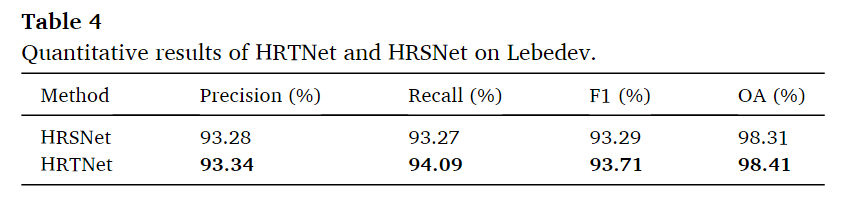
HRSNet为去除了差异图作为输入的网络,可以看到,在各方面都有一些下降,这表明了通过引入时间信息,通过学习这些信息的特征,增强了模型对双时相图像的伪变化和噪声的鲁棒性,召回率有着中等幅度的上升。

从可视化结果可以看到,相比于HRSNet,HRTNet能够更加有效的检测出伪变化和消除噪声带来的影响。

在推理时间方面,一张256*256的图片,HRTNet比HRSNet的时间慢了一点点,这是由于DI在进行动态Inception时需要学习特征。这种略微增加的计算程璧使得F1分数性能提高是值得的。
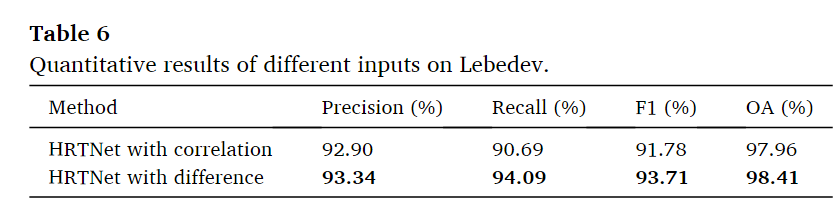
除了这种DI进行三元并行输入的情况,还尝试了将两个图像拼接起来作为第三元并行输入。结果如上图,最终的结果相比于DI作为第三元输入有着较大的差距,本文认为DI能够直接引导网络学习双时相图像之间的差异,导致的HRTNet的性能更加,而且相关性图像是一个6通道的图像,不能够完全共享网络参数,导致成本增加,我认为这其实就是说一个网络架构的期望,设置DI的话就是告诉网络我要从这个方向去寻找最优解,而直接拼接的话就相当于没有任何的先验知识了,这样会带来效果的降低以及推理时间的消耗(训练阶段的时间)。这种期望的方向也就是一些手工特征作为输入的原因。
动态卷积的Inception层
包含/不包含了DIM层的HRSNet/HRTNet
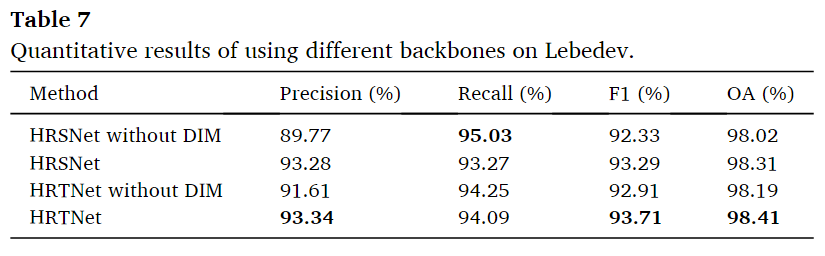
可以看到两种网络下加入了DIM层都会带来Recall的下降,但是其他的方面都能够展现出更优越的性能。本文认为可能是DIM引入了更多的特征信息,在提高精度的同时引入了少量冗余,导致了对变化图的一些应该预测的地方不敢预测。最终召回率降低。可视化结果如下图。

可以看到对于不同的变化的边界都有着改善,这是引入多尺度信息所带来的。从图中第三行和第四行图像可以看出,使用DIM的模型可以更好地学习物体的特征,减少了错误的检测,同时避免了检测区域出现“空心”现象。这种空心的情况本文中没有解释,我认为可能是没有DIM,模型缺乏捕捉内部细节的能力,DIM处理多尺度的特征信息,有助于模型更全面的理解对象的整体结构和内部细节,这个可能是在特征提取中,将小尺度的特征图直接通过插值到原来大小导致的。
局限性
①提出的模型只能在同一场景下进行训练和测试,泛化能力较弱。这是可以理解的,想想在这种雪地完全覆盖的情况下仍然能够正确的发现变化检测图,这种性能显然是要单独训练,不好转移到其他的情况下的。
②监督学习的样本问题。老生常谈的一个问题了。
ChangeMask-2022-IJPRS
一种利用Encoder提取特征,然后利用时间-空间卷积核进行特征强化后利用对称函数得到变化特征,并利用共享decoder进行双时态语义分割以及二值变化检测,同构进行结合得到多值变化检测的网络。
提出的原因
①由于现有PCC(后分类的方法)的方法无法利用时间依赖性,导致在对象边缘遭受伪变化的问题和误报的问题(对于每一个像素点是彼此独立的进行比较的)。
②目前的方法中对于特征融合的时候没有考虑时间的对称性,也就是直接拼接或者取差异的方法。
③相比于之前通过将双时相特征融合进行多值变化检测的O(n^2)的分类空间,太过复杂,因此提出这种双分支语义分割,然后直接通过语义分割结果结合二值变化检测图进行分类的网络,只有O(n)的分类空间。
网络架构
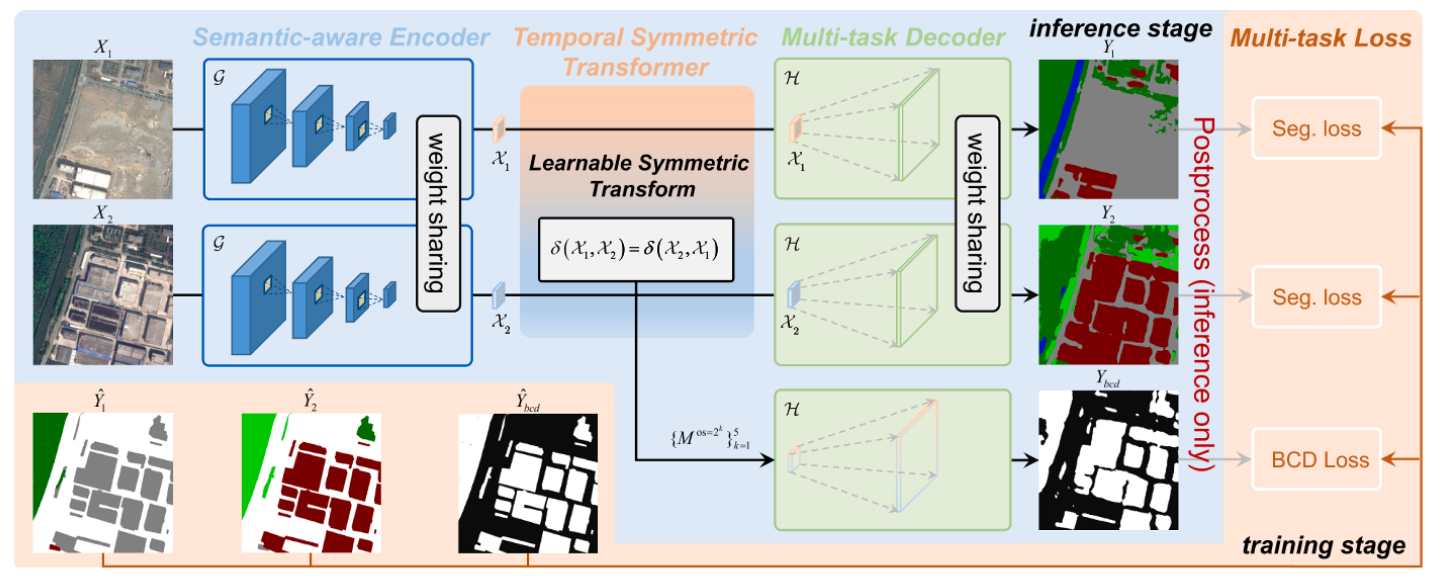
首先通过现有的EfficientNet进行双时相图像特征的提取,然后简单的UNet的解码器对双时相特征进行还原输出进行双时相的图像语义分割任务,同时从双时相特征中生成时间对称且利用时间点分割开的卷积获得具有时间依赖性的特征使用同样的UNet解码器用于二值变化检测图的生成。然后直接用二值变化检测图去遮盖在双时相语义分割图上,就能够得到多值变化检测的结果了。
实验方法
数据集
SECOND:之前介绍过了
Hi-UCD:高空间分辨率的多时相遥感图像数据,在爱沙尼亚的城市区域,图像大小为1024*1024,0.1米,共764对图像,包括了9个 大类,水体、草地、建筑、温室、道路、桥梁、裸土、林地和其他,可能的土地类别变化组合有81种互变加上1种无变化,总共82种,训练数据:300对 验证数据:59对,测试数据:300对 三者空间上互不重叠
评价指标
BCD:OA,IoU,F1,AUC;
SCD:SeK,Kappa,Overall Score,Overall Score = 0.3⋅IoU + 0.7⋅SeK。
还有一个用于衡量神经网络计算复杂度的指标,Madds(Multiply-adds),一次前向传播中所有乘法和加法操作的总数。
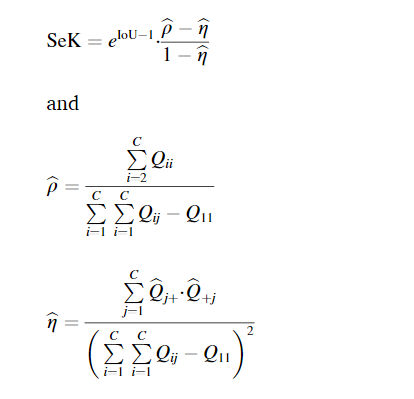
实验设置
SGD,动量为0.9,对于参数正则化设为0.0001,15k次迭代,EfficientNet在VGG16数据集上进行预训练,随机将图像裁剪为256*256大小并利用翻转旋转和随机颜色都懂作为数据增强,初始学习率为0.03,衰减因子为0.9的“poly”学习率策略,也就是学习率=(1-迭代次数/总迭代次数)^0.9的方式进行衰减。
对比的方法
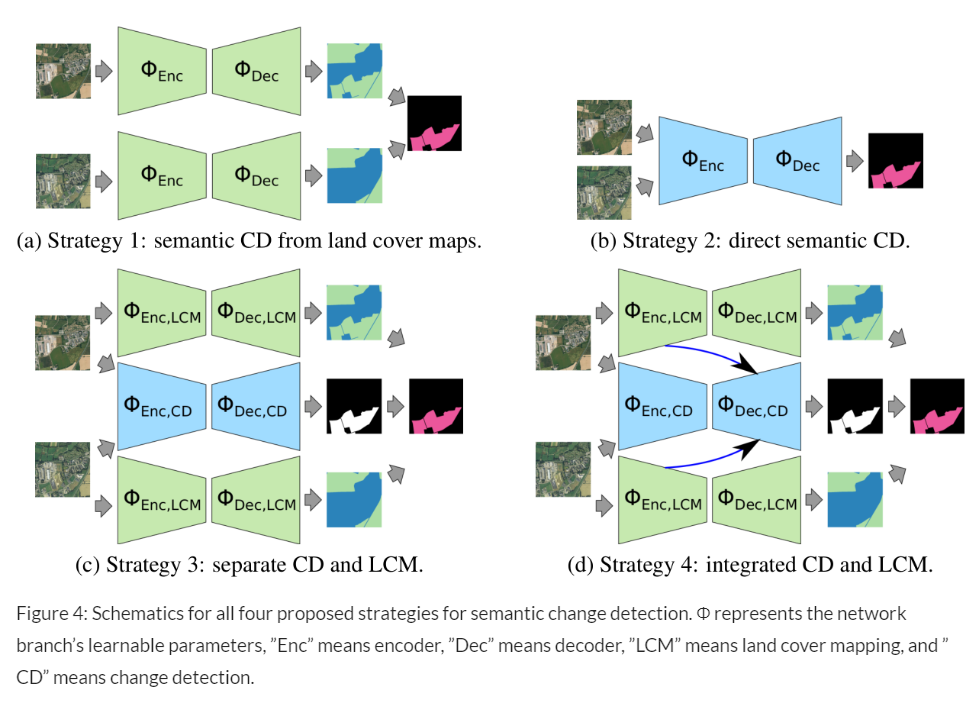
FC-EF、FC-Siam-Conc、FC-Siam-Diff、UNet++、IFN、HRSCD1/2/3/4(这是由Daudt提出的一种后分类方法PCC,总体采用了UNet的架构,分别对双时相图像以及差分图像进行Encoder-Decoder,然后双时相特征用于语义分割,差分图像用于二值变化检测,然后结合,1代表着不用差分图像,2表示不用双时相图像,3表示都用,4表示都用的同时将双时相中的encoder也跳跃连接到差分图像的decoder中)
实验结果
SECOND数据集
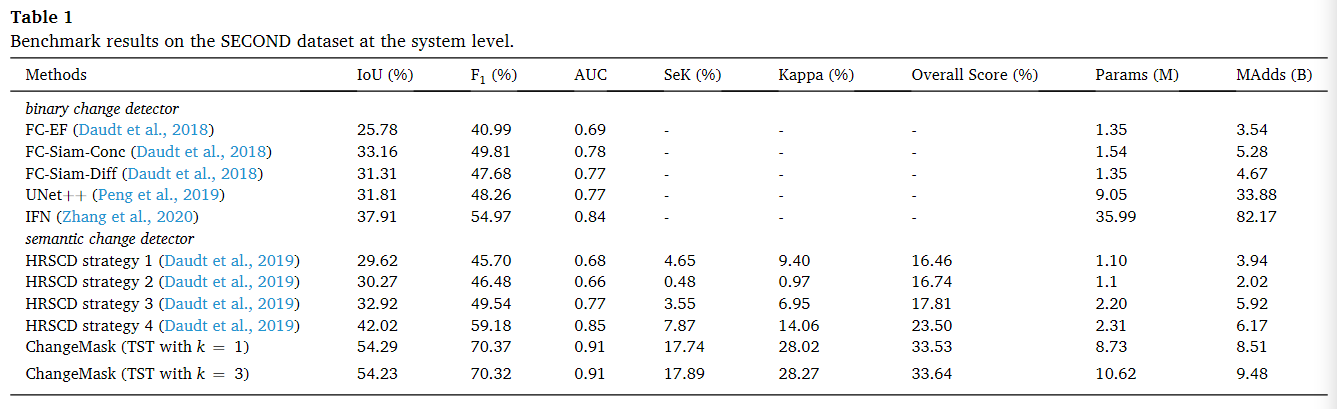
HRSCD策略1-3不能有效地从语义监督中获益。由于HRSCD策略1忽略了时间依赖性,HRSCD策略2存在二次型分类空间,而HRSCD策略3缺少语义-时间特征融合。这两个都是影响变更检测性能的关键因素。HRSCD策略4考虑了这三个因素,从而从多任务监督中获得了积极的收益。ChangeMask也对这些关键因素进行了建模,并进一步引入了语义感知编码器和时间对称表示,在系统级别上显著优于HRSCD策略4。同时,ChangeMask具有较高的精度,并且其计算的开销为8.51MAdds,能够接受。
可视化结果如下

可以看到在所有的可视化结果中,相比于HRSCD4,ChangeMask都能够产生更加清晰和准确的二进制变化图,更好的捕捉到建筑边缘的变化,同时在多值变化检测方面同样有着更好的表现,例如能够区分树木的增长和植被的增长,而HRSCD策略4在这方面可能会混淆。
Hi-UCD数据集
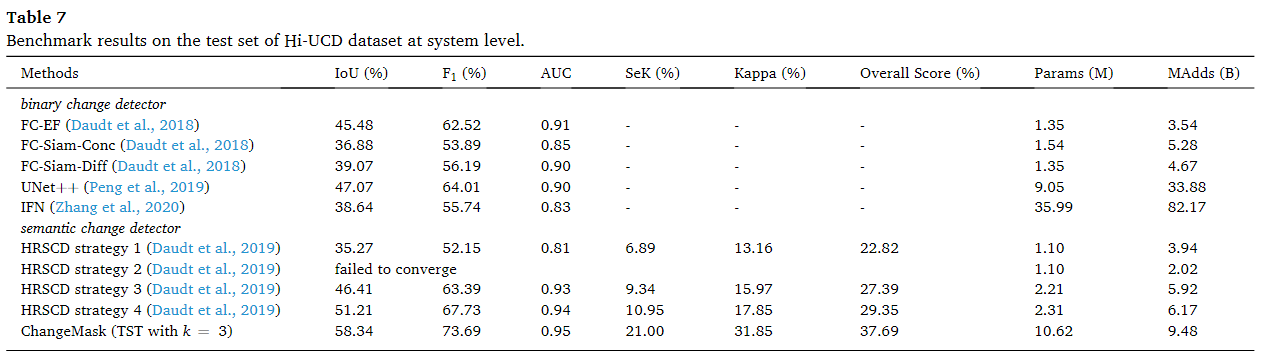
和SECOND数据集有着一样的趋势结果,1-3无法从语义监督中受益,而HRSCD4比ChangeMask弱。而且Hi-UCD有着82个变化空间,因此相对于多时间分类的策略PCC,这种大分类空间确实会存在导致分类困难的情况发生,因此保持着O(n)的分类空间复杂度是十分有必要的。
可视化结果如下。
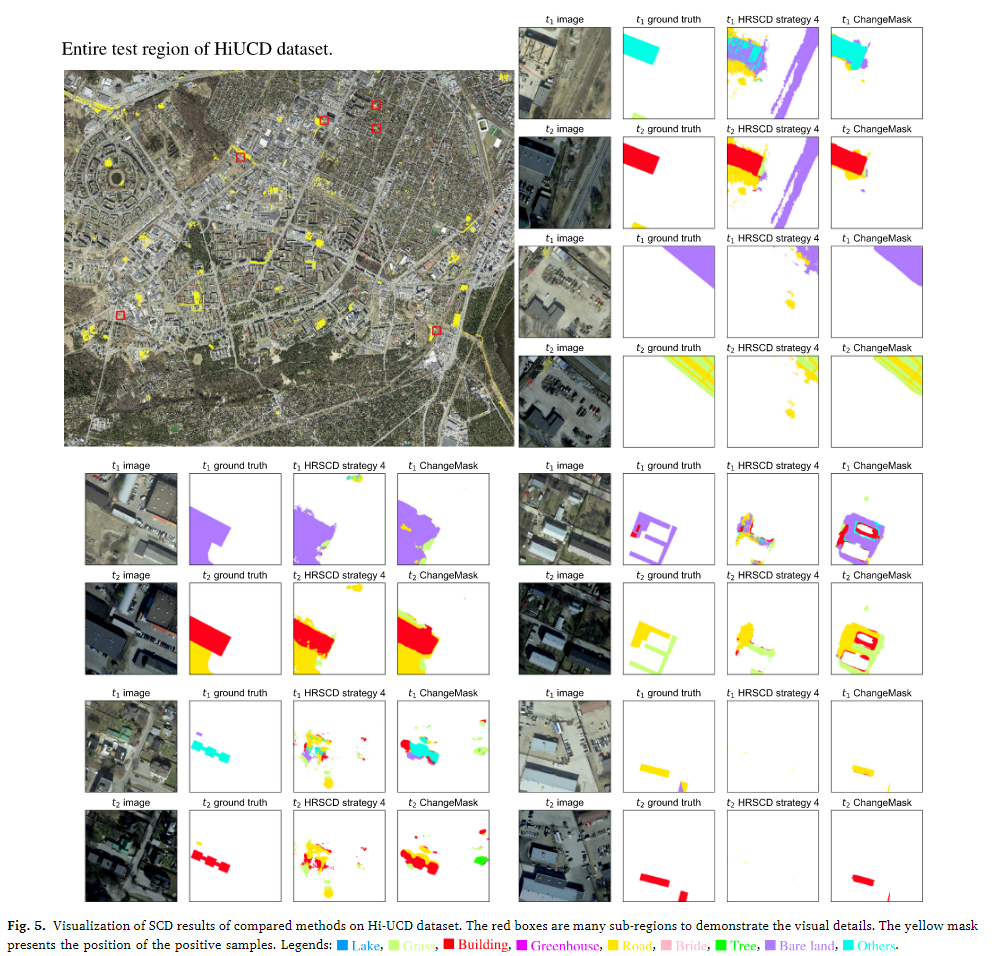
6个微观结果
从微观层面的可视化结果可以看到,相比于次优的HRSCD4来说,当双时态图像的色差较大时,ChangeMask的误报的情况较少,对于更好的语义变化检测器来说,保持语义变化的一致性是非常重要的。这意味着变化检测结果应当与实际发生的语义变化相吻合,避免误报和虚假变化。HRSCD策略4分别独立编码语义特征和变化特征,这使得它难以保持语义变化的一致性。因此,它更容易产生虚假变化。ChangeMask具有语义感知编码器,它保证了语义特征和更改特征之间的因果关系。此外,这种因果关系带来了额外的正则化,以减少训练过程中过度拟合的风险。通过这种方式,ChangeMask可以获得更多语义更改一致的结果。
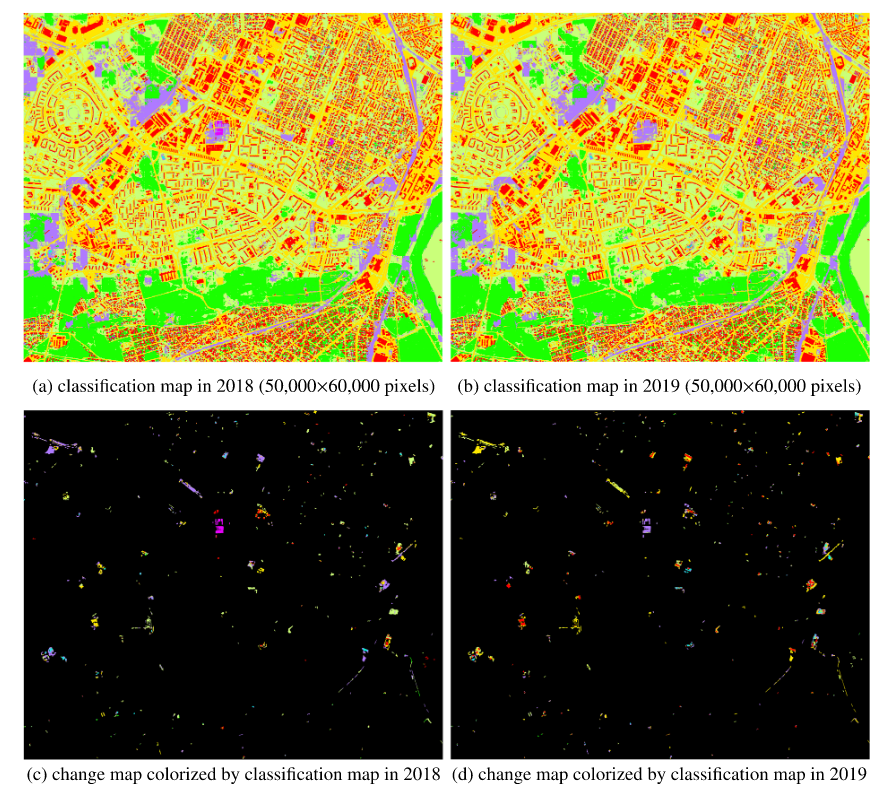
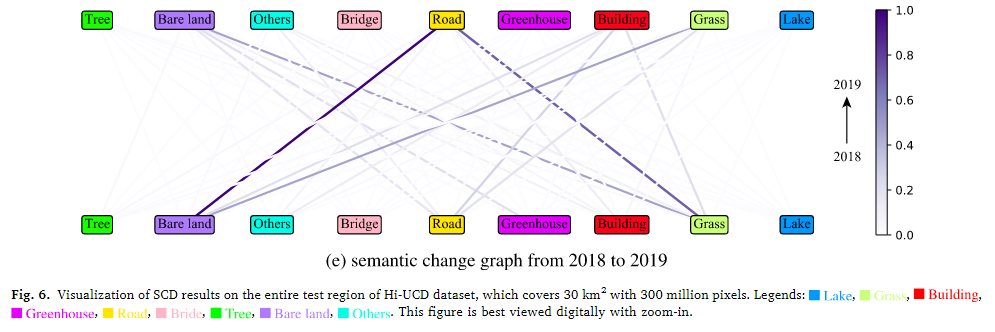
全局结果展示
构建了一个语义变化图(图6 (e)),展示了2018年到2019年期间该区域的主要语义变化。在这个图中,更深的线表示更高的变化率,从而揭示了哪些类型的变化最为显著。观察到该区域最主要的变化是从裸土变成道路,其次是从草地变成道路。这些变化暗示该地区可能正在快速发展。其他显著的变化包括从草地变成裸土和从其他类别变成建筑物。这表明该地区未来可能人口增加。
消融实验
语义感知编码器的消融
在HRSCD4中,可以看做是一种并行编码器(也就是之前说的DI也单独的作为一个分支导致的),对于变化表示和语义表示都是利用encoder提取的,而在ChangeMask中则是级联的编码器,首先通过编码器得到语义特征,然后再利用语义特征融合得到变化表示。
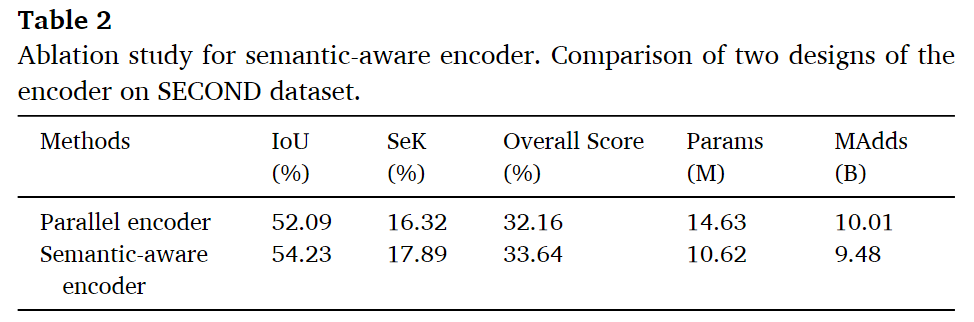
语义感知编码器比并行编码器的性能高2.14%IoU和1.57%
时间差异特征

相比于不对称的拼接的方法,手工设计的简单的方法还是无法进行比较,在IoU上都不如不对称的拼接的方法(这种事先拼接然后进行简一些神经层),对于|x1-x2|有着更好的SeK,本文认为,时间差(|x1 x2|)将语义特征投射到对称度量空间中,从而迫使这些特征嵌入层减少类内曼哈顿距离并扩大类间曼哈顿距离。这可以看作是将隐式度量学习应用于语义特征学习,从而使语义特征具有更强的辨别能力(Hoffer and Ailon, 2015)。而对于拼接的方法,时间级联保留了所有原始信息,并将时间差分表示学习的责任转移到后续的卷积中,使其专注于二值变化检测。然而,这些后续的卷积会对连接的语义特征通道进行重组,从而破坏语义表示,从而影响SCD的性能。但是在度量学习中,对于度量的选择非常敏感,就比如|x1-x2|的度量和(x1-x2)^2的度量,两种不同的距离会导致较大的差异,本文将 (x1-x2)^ 2展开x1^2+* x2^2 - 2x1x2,这两部分都是对称的,因此本文顺便也把这两种情况用于消融实验,结果发现x1x2得到了53.18% IoU和17.36% SeK,而x1^2 + x2^2只有38.05% IoU和6.91% SeK,所以本文猜测二次函数会造成非常稀疏的特征嵌入,不利于表示能力。我们使用相应的线性函数:x1 +x2作为时间差分表示。正如预期的那样,x1 +x2在SCD上实现了52.94%的IoU和17.49%的SeK,优于其他比较对称的函数。然而,这些手工制作的对称转换不能胜过BCD上的临时连接。这是因为卷积层之后的时间连接更普遍,它可以学习变化表示(也就是这种x1+x2的情况就是定义了一个期望,表示变化可能就是这样的,而拼接后进行卷积相当于自己先进行了学习,学习怎么样进行变化表示),而不是预先定义变化表示。TST中使用了拼接的方式,然后进行双时相隔开的卷积,这种双时相隔开的方式也是一种预期,告诉网络,我现在这两个时间点中的图像的通道不应该随意组合,应该关注自己方面的,这也是一种期望的表达,但是干预并不强,如果通道自由组合更好,最终还是会自由组合,就类似于Resnet一样,我告诉你这里可能直接过去会更好,但是具体由你自己学习。在1*1的卷积上达到了最好的性能,这种性能通过参数以及计算时间的检验确定是受益于网络模型而不是网络复杂度。
注意这里提到的是σ(x1, x2),后面提到逐点相加和相乘的是δ(σ(x1, x2), σ(x2, x1))
卷积核大小k的消融
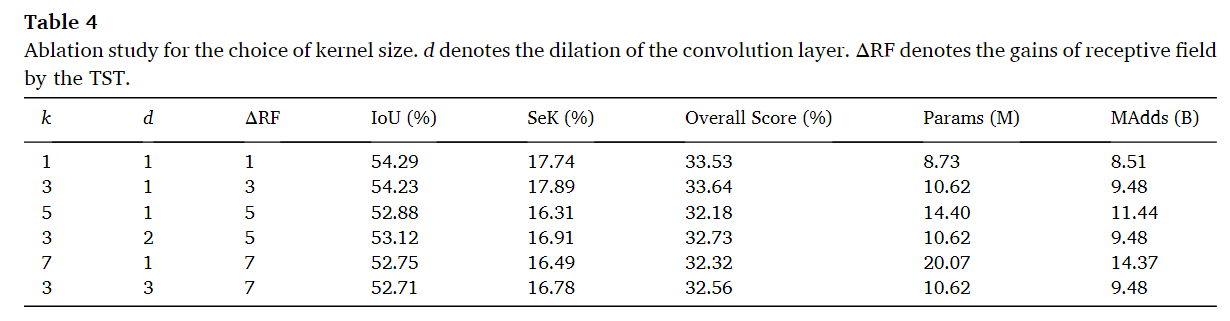
通过消融实验可以看到,随着k增加呈现上升下降趋势,在k=3时性能最好,不过相比于1并没有太大的差别。对于膨胀卷积的d来说,随着d增加呈现下降趋势,这说明了引入更多的空间邻域来决定语义变化是不合理的。这意味着仅依靠空间上更远的邻域并不能有效提高变化检测的准确性。然而使用膨胀卷积替代大核心卷积时,可以观察到一致的性能提升,这暗示模块中过多的参数可能导致过拟合,这可能是性能下降的主要原因。
对称融合的消融

逐点相加的IoU略高于相乘,其他的略低于相乘。差别不大,这种对称融合的方式不会引入额外的参数,意味着这是完全可以确定是通过网络的结构得到的收益,实验结果表明,不同的对称函数在BCD和SCD上有类似的性能表现。这暗示了对称融合对于BCD和SCD都很重要,而具体采用何种形式的对称函数则不是决定性因素。
多任务的消融
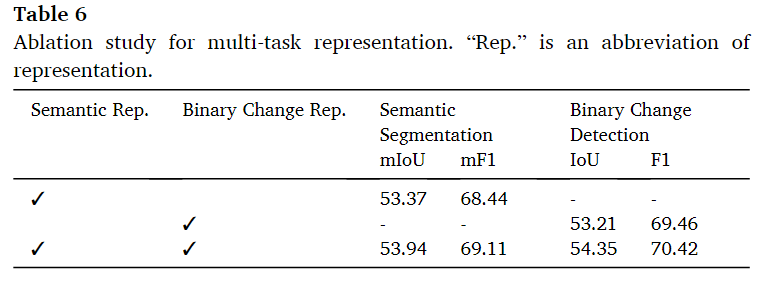
表6展示了ChangeMask在使用不同表示时的结果。发现使用二值变化表示(binary change representation)可以提高语义分割的准确度,具体表现为0.57%的平均交并比(mIoU)提升。同时,使用语义表示(semantic representation)也可以提高二进制变化检测(BCD)的准确度,体现为1.14%的交并比(IoU)提升。这些结果表明,在ChangeMask网络设计中,变化表示和语义表示可以相互帮助,提升模型在两个不同任务(语义分割和变化检测)上的表现。这种相互帮助的现象说明了在变化检测任务中,理解图像的语义内容(如物体类别、场景组成)和识别时间上的变化(如场景中哪些部分发生了变化)是相互关联和互补的。
DPFL-Nets-2022-ITTNLS
DPFL-Nets: Deep Pyramid Feature Learning Networks for Multiscale Change Detection-2022-ITTNLS
用于进行异构的图像变化检测的方法
①基于回归的方法,将一个图像转换到另一个结构下的图像,然后利用差值等进行比较。
②基于PCC的方法,将两个图像进行语义分割,然后比较语义分割中每一个点的情况。
③基于特征比较的方法,将两幅图像映射到一个公共的空间,然后进行比较。
网络架构
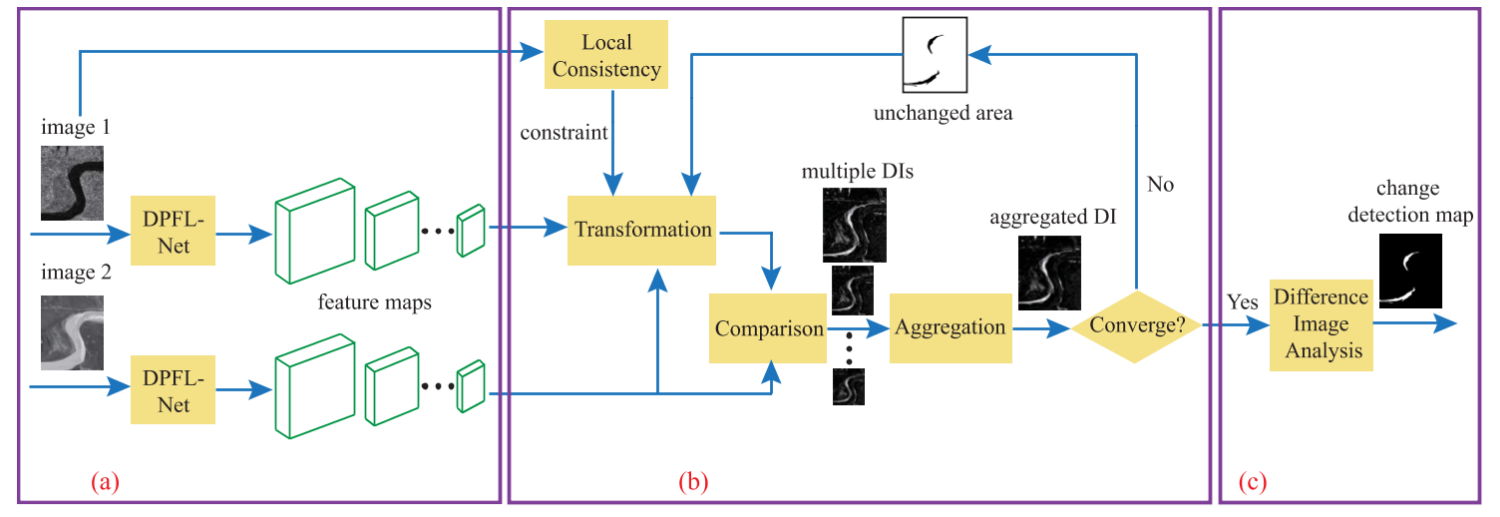
首先通过DPFL-Net提取多尺度的特征图。每个分支有着不同的权重,DPFL-Net的初始权重由DAE(噪声自编码,也就是对噪声具有鲁棒性的重建方式进行训练)得到,然后固定图像1分支的权重,对于初始权重的网络提取的特征,通过距离阈值得到伪标签,然后利用伪标签使图像2分支的网络权重训练慢慢将不变区域的提取的特征在多尺度上都和图像1分支的特征靠近,同时还需要通过局部一致性和空间域对图像2分支进行约束(本文认为通过像素点的值和空间距离能够把AE中独立的像素点彼此联立起来,我认为这个一方面可以把原来一个地表中一部分分类正确但是有一部分分类错误的中错误的给拉回来,因为一开始产生的P如果没有这种约束,他可能只会把对的分类的更对,但是对错的可能就没有感觉,而这种就是给对的一个要求,你要把错的也尝试拉到对的里面,同时还有一个正则化约束就是变化的点不能太多),然后将两个分支的不同尺度的特征求得各尺度下的DI,然后聚合到原图尺度,对于这个DI通过OTus阈值去进行标签的划分,可以直接输出,也可以继续迭代找到更优解(那么就将标签下采样到各个尺度去)。
实验方法
子分支
DPFL-Net1:去除了多尺度,只引入了局部一致性的正则化项
DPFL-Net2:有两个尺度的金字塔特征,每个尺度依次变换,两个DIS进行聚合
DPFL-Net3:3/4个尺度的金字塔特征,然后进行变换,然后聚合。
评价指标
Kappa(KC),Pre、ROC、AUC
实验设置
第一阶段的子网络结构,四个卷积层,核大小为3,滤波器有20个,第二第三阶段子网络结构,首先是最大池化层,然后分别有三个核两个卷积层。
预训练和训练DPFL-Net中学习率分别为0.001和0.0001,直到损失函数稳定停止迭代。对于合成孔径雷达使用基于视数L的散斑噪声vSAR进行污染,光学图像通过标准差为0.05的高斯噪声污染。在局部一致性中,空间域中的标准差为1,范围域中的标准差为0.1.
对比方法
同质
GKI(一种阈值算法)、PCANet(使用PCA滤波器作为卷积层(之前看过一个KPCA的))、D_RFLICM、AM_HPT、CA_AE( 基于深度神经网络的无监督变化检测算法)和 SCCN。
异质
PCC(先语义分割,然后对每个像素的类别进行比较)、AM_HPT、CA_AE、MCD、FPMSMCD 和 SCCN。
数据集以及实验结果
同质
Farmland
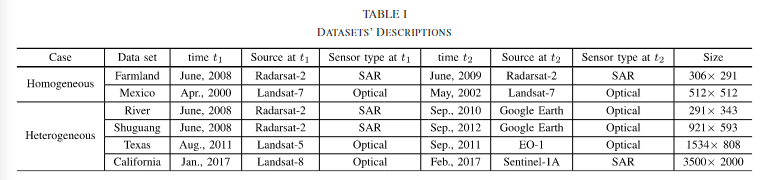
包含两幅SAR图像,2009.06和2008.06,2009年的图像只有单试图,受到了更高水平的散斑噪声污染,这使得变化检测更加复杂。

可视化结果如上图,线性 SVM 用于训练基于 PCANet 提取的特征的变化检测模型。对于 D_RFICM,网络的最后一层输出变化或不变类的像素标签。从图 6 可以看出,D_RFICM 和 DPFL-Net-3 产生高质量的变化检测图。
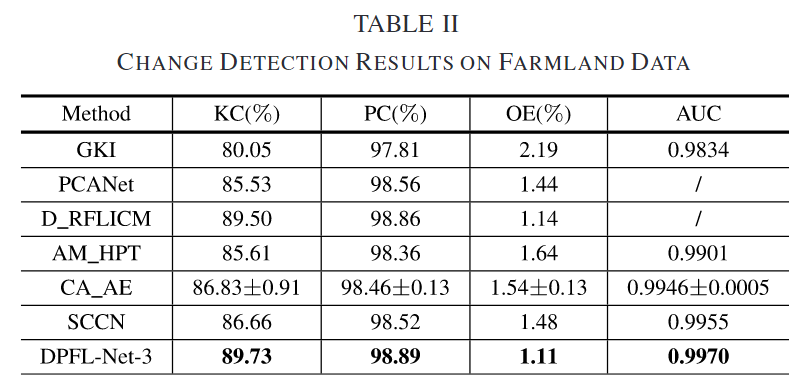
定量结果如上表,DPFL-Net-3 在 AUC 上获得了 0.9970 的大值,表明生成了高质量的 DI。DI 可以很容易地将更改的区域与未更改的区域区分开来。对于变化检测图,DPFL-Net-3 的 KC 为 89.73%,OE 为 1.11%。
Mexico
墨西哥数据集由城市墨西哥获取的两张光学图像组成,空间分辨率为 30 m。它们分别从 ETM+ 传感器的 4 波段收集
可视化结果如下图

如 Fig. 8(b) 所示,由 DPFL-Net-3 生成的差异图像(DI)的 ROC 曲线接近左上角,说明其能够有效区分变化和未变化类别。Fig. 7(d)-(j) 展示了 Mexico 数据集的混淆图(confusion maps)。GKI 由于使用了简单的手工特征,结果较差。D_RFLICM、SCCN 和 DPFL-Net-3 利用深度神经网络提取的数据驱动特征获得了更好的结果。AM_HPT 也在 Mexico 数据集上取得了良好的结果,这得益于其在选择可靠的未变化像素进行回归方面的显著能力。
定量分析结果如下
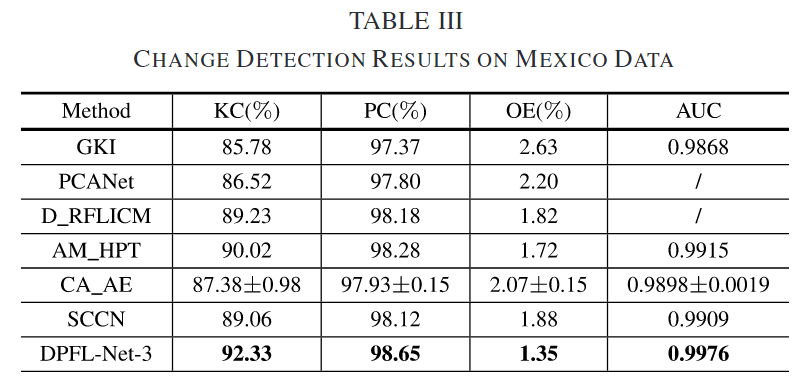
DPFL-Net-3 学习了一系列层次化特征,包含不同层次的上下文信息,因此在 Kappa 系数(KC)上达到了最佳结果(92.33%),总误差(OE)为 1.35%。
异质数据集
River
它由一个 SAR 图像和一个光学图像组成,如图 9(a) 和 (b) 所示。空间分辨率为 8 m。它们覆盖了黄河河口的同一区域。一般来说,谷歌地球的图像是从卫星或飞机检索的,包括Landsat-7、QuickBird、IKONOS和BlueSky。图 9© 显示了相应的参考图像。观察到的变化主要是由洪水引起的。与同质情况不同,异构情况下的变化检测是困难的,因为图像外观存在较大差异。例如,图9(a)中的暗区表示SAR图像中的水,而图9(b)中的亮区也是光学图像中的水。
可视化结果如下图
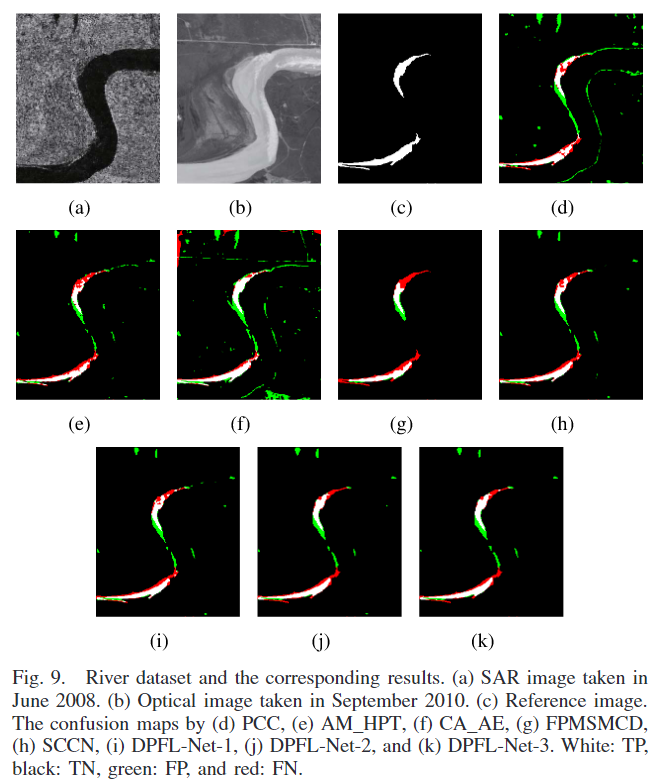
FPMSMCD 和 DPFL-Net-3 在 River 数据集上获得了最佳的变化检测结果。FPMSMCD 生成了更少的假阳性(FP),而 DPFL-Net-3 则获得了更少的假阴性(FN),也就意味着FPMSMCD的准确率会比较高,而DPFL-Net3的召回率高。
定量分析结果如下
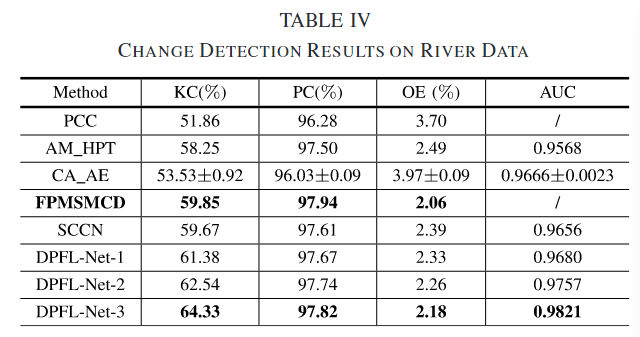
与 SCCN 相比,由于引入了局部一致性,DPFL-Net-1 获得了更好的结果。DPFL-Net-3 在整合不同尺度的上下文信息后,提高了变化检测结果,从而证明了所提出方法的有效性。
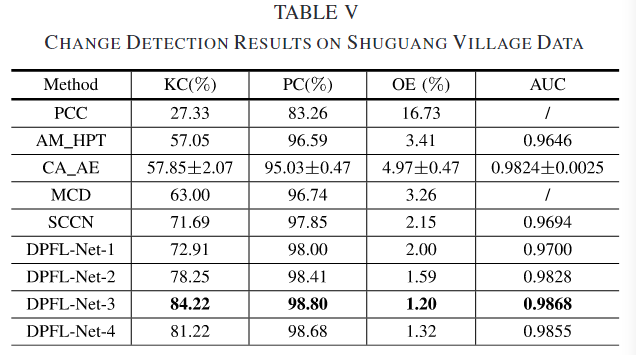
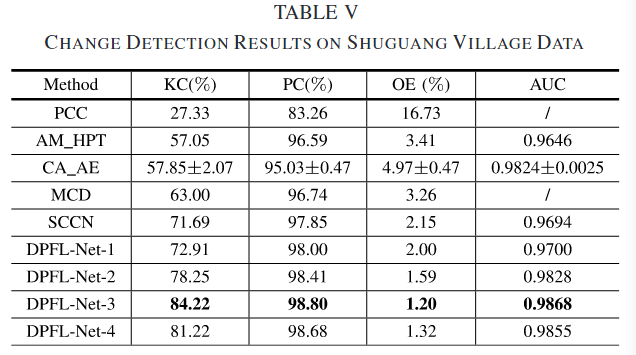
Shuguang Village
包括一个 C 波段 SAR 图像和一个光学图像,分别如图 10(a) 和 (b) 所示。对齐并共同配准这两个图像,共享相同的空间分辨率为 8 m。图 10© 中的参考图像显示了中国东英城乡村土地覆盖变化。
可视化结果如下图

从图10可以看出,所提出的DPFL-Net-3在FPs和FNs较少的情况下产生了最好的变化检测图。然而,DPFL-Net-4 的变化检测结果比 DPFL-Net-3 差一点。原因是在低分辨率第四阶段学习到的特征图使农田和建筑物的边界模糊,导致物体周围有更多的 FN。与其他数据集相比,Shuguang 数据集很复杂,因为图 10(b) 中有更多的土地覆盖。因此,所提出的变化检测方法显着提高了上下文信息在区分不同的土地覆盖方面发挥着重要作用。通过PCC,变化检测的混淆矩阵如图10(d)所示。由于来自两个分类图的大量累积误差,PCC 的结果很差。
在DPFL-Net3中不同分辨率的DI图像如下图
第一阶段的高分辨率DI包含更精确的空间信息,导致变化和未变化区域之间的清晰边界。然而,第一阶段的DI中存在更多噪声,产生了许多错误检测的变化像素。在第二和第三阶段的DIs中,由于上下文信息,未变化区域和图像噪声都被抑制。最终的DI包含精确的空间信息但噪声较少,变化和未变化类别之间的对比度也增加了。这意味着多尺度的DIs被聚合成一个具有强分离性的增强DI。这种方法是有效的。
定量分析结果如下
Texas
由两个多光谱图像1组成,大小为1534 × 808。事件前的图像由Landsat-5 TM获取,在2011年8月7个通道,EO-1 ALI(地球观测的高级陆地成像仪)于2011年9月10个通道。两个多光谱图像的大部分通道的空间分辨率为30米(TM传感器的波段6为120米)。该数据集用于检测德克萨斯托县森林火灾引起的变化区域,如图12所示。由于这两个多光谱图像不能直接比较,因此它们之间的变化检测任务属于异构情况。
可视化结果如下图
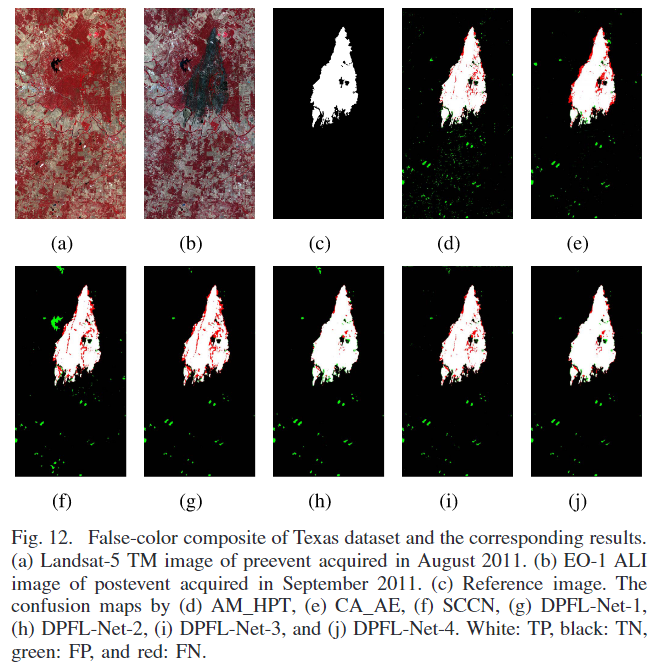
由于金字塔特征包含许多上下文信息和语义,因此所提出的方法 (S ≥ 2) 显着降低了 FP 和 FN。
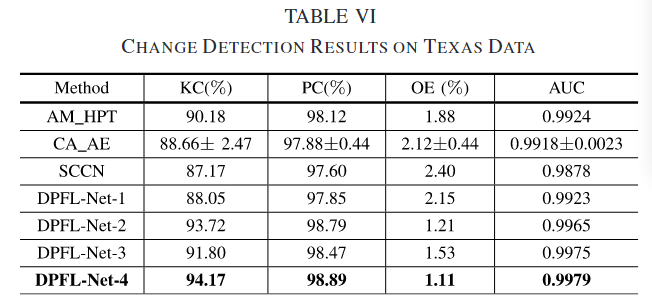
观察到 DPFL-Net-4 的 KC 为 94.17%,OE 为 1.11%。
California
由一个多光谱图像 2 和两个 SAR 图像组成。3 前者由 2017 年 1 月 5 日的 Landsat-8 获取,包括图 13(a) 所示的 11 个通道。在本文中,我们仅使用来自 OLI(Operational Land Imager)的八个波段,除了“cirrus”波段。大多数波段的空间分辨率为 30 m(全色波段除外,它是 15 m)。后者由Sentinel-1A于2017年2月18日捕获,其中包括VV和VH极化的两幅图像[如图13(b)所示]。多光谱图像和两个 SAR 图像覆盖了加州尤巴县和萨特县萨克拉门县的同一区域。图13©的变化是由洪水引起的
可视化结果如下图

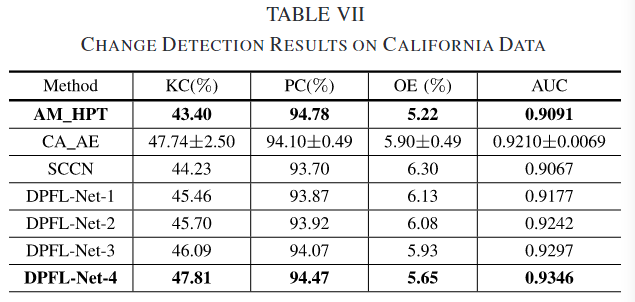
由于德克萨斯州和加利福尼亚州的数据集包含不同类型的土地覆盖,以完全无监督的方式产生两个满意的图像分类地图是不可行的。为了避免大量的累积误差,没有对这两个数据集进行PCC。对于这个数据集,有一些小而孤立的变化区域使得变化检测更具挑战性。在实验中使用的所有方法中,AM_HPT在加利福尼亚数据集上的PC值最好,为94.78%,DPFL-Net-4的KC值最好,为47.81%,如表7所示。但是,仍然存在大量的FPs和fn。尽管DPFL-Net-4提取了金字塔特征,但它无法提取更抽象的对象级别表示,而这对于在这样一个具有挑战性的数据集上获得更好的变化检测图至关重要。
消融实验
关于三个参数的消融实验,λ(差异图像的分割阈值),γ(局部一致性的权重),S(阶段数量,也就是多少种尺度)
λ消融实验
在实验中,为了研究 λ 的影响,只使用了 DPFL-Net 的一个阶段(S = 1),并且没有应用局部一致性(γ = 0)。实验中 λ 的取值范围从0.05变化到0.25。在 Fig. 14 中,展示了六个数据集在不同 λ 值下的 AUC(曲线下面积)值。
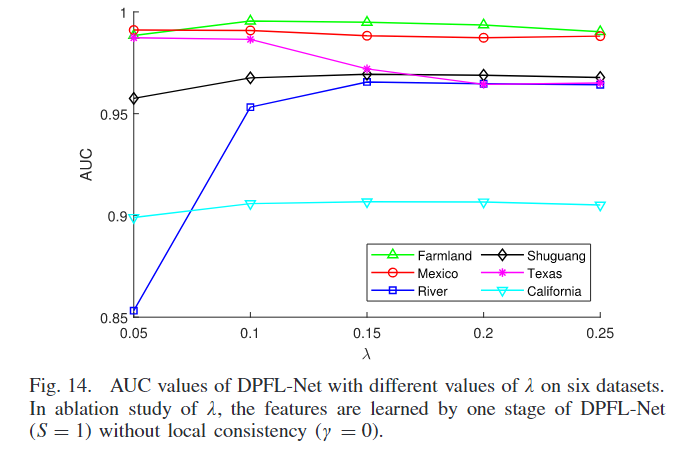
当 λ 太小时,用于训练网络的未变化像素较少,DPFL-Net 容易对少量未变化像素过拟合。例如,在 River 数据集上,λ = 0.05 时生成了较差的差异图像(AUC 约 0.85)。当 λ 太大时,可能会选取过多的变化像素,干扰特征转换过程。例如,在 Farmland 数据集上,当 λ 设为0.2和0.25时,AUC值显著下降。在同质情况下(如 Farmland、Mexico 和 Texas 数据集),较小的 λ 可以得到较大的 AUC 值。在异质情况下(包括一个光学图像和一个 SAR 图像的数据集,如 River、Shuguang 和 California),选取了相对较大的 λ(设为0.15)。由于异质情况下两幅输入图像之间的差异通常比同质情况更大,因此较大的 λ 更适合异质情况,特别是在包含SAR图像和光学图像的输入时。
γ的消融实验
在消融实验中,DPFL-Net 只使用一个阶段(S = 1),并且预训练该阶段。γ 的取值范围从 0.05 到 0.40,以 0.05 为间隔。
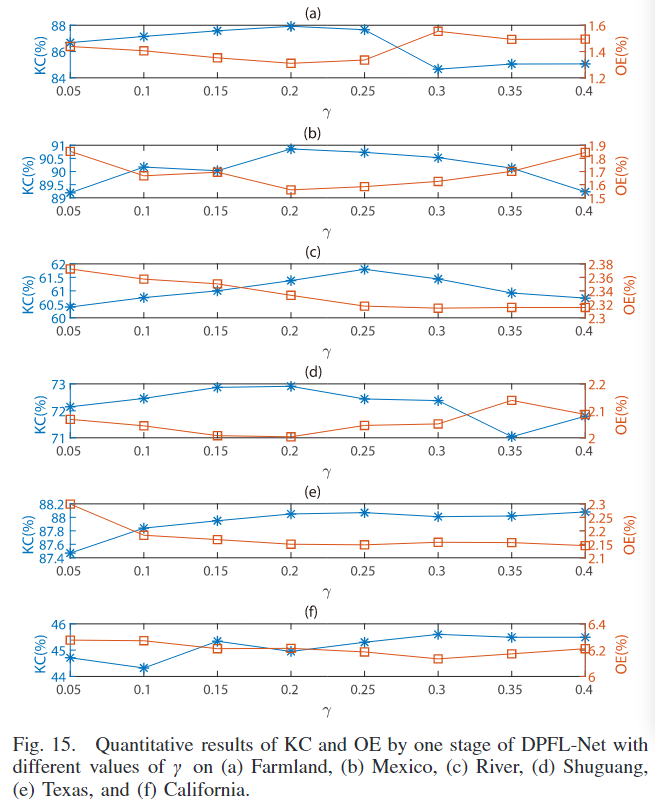
不同 γ 值下的定量变化检测结果(Kappa 系数(KC)和总误差(OE))在 Fig. 15 中展示。在 Farmland 和 Mexico 数据集上,当 γ 设为 0.2 时,DPFL-Net-1 取得最佳结果。在 River 数据集上,DPFL-Net-1 在 γ = 0.25 时表现最佳。在 Shuguang 数据集上,γ 设为 0.15 和 0.2 时,KC 和 OE 的差异较小。在 Texas 数据集上,γ 为 0.2 和 0.25 时,DPFL-Net-1 取得类似的变化检测结果。在 California 数据集上,γ 设为 0.3 时,DPFL-Net-1 表现最佳。
当 γ 值较小时,局部一致性对特征转换过程的影响较小,与没有局部一致性时相比,变化检测结果的提升有限。但是,当 γ 值过大时,可能导致对局部一致性的过度偏重,妨碍金字塔特征在未变化区域的匹配,从而降低性能(如 Farmland 数据集)。因此,对于大多数数据集,实验中将 γ 设为 0.2。
S的消融实验
为了评估低分辨率特征对变化检测结果的影响,进行了 DPFL-Net 在一、二、三、四个阶段的定量比较。考虑到输入图像的大小,DPFL-Net-4 在 Shuguang、Texas 和 California 数据集上进行了实验。
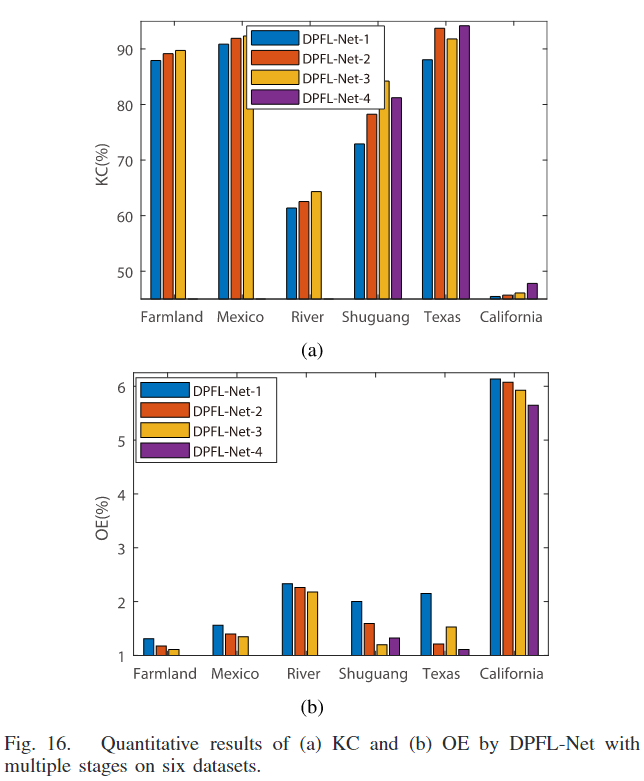
图 16 展示了 DPFL-Net 在不同阶段下 Kappa 系数(KC)和总误差(OE)的变化。通常情况下,随着阶段数的增加,DPFL-Net 的变化检测结果得到改善。在 Shuguang 数据集上(参见 Table V),DPFL-Net-1 的 KC 为 72.91%,通过 DPFL-Net-2 提高到了 78.25%。使用三个阶段的 DPFL-Net 预训练时,获得了最佳的变化检测结果,KC 为 84.22%,OE 为 1.2%。然而,DPFL-Net-4 的结果略差于 DPFL-Net-3,原因是丢失了一些物体精确的边界信息。在 Texas 数据集上(参见图 8 和 Table VI),随着阶段数从 1 增加到 4,AUC 值有所提高。但是 DPFL-Net-2 获得了比 DPFL-Net-3 更好的变化检测图,具有更高的 KC 和 PC。经过详细分析发现,基于 DPFL-Net-3 的 DI 自动计算的阈值与 DPFL-Net-2 的显著不同。在 California 数据集上,DPFL-Net-4 比 DPFL-Net-1、DPFL-Net-2 和 DPFL-Net-3 有更少的假阳性(FPs)。实验结果证明,在大多数情况下,低分辨率特征中引入的上下文信息有助于区分变化和未变化类别。
预训练的影响
预训练后,该方法对不变类的概率映射p的初始化不敏感,DPFL-Net-3对每个数据集运行10次,AUC值如图17所示。当 Ps,u 在0到1之间随机初始化时,AUC值变化很小。
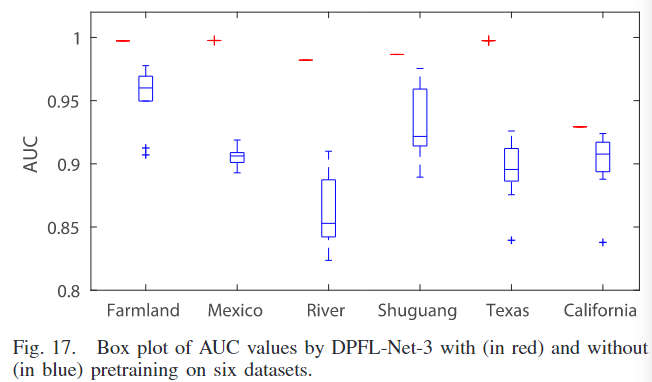
图 17 还报告了 DPFL-Net-3 在没有预训练和经过预训练后的性能对比。如果 DPFL-Net-3 没有经过预训练,金字塔特征不能很好地表示输入图像,也难以区分不同的土地覆盖类型。结果是,特征转换变得困难,提出的变化检测方法的整体性能下降。在没有预训练的情况下,DPFL-Net-3 在 Farmland 和 Mexico 数据集上的 AUC 值相对较大且更稳定,与其他数据集相比,十次运行的结果差异较小。这表明在异质情况下的变化检测比同质情况更困难和具有挑战性。
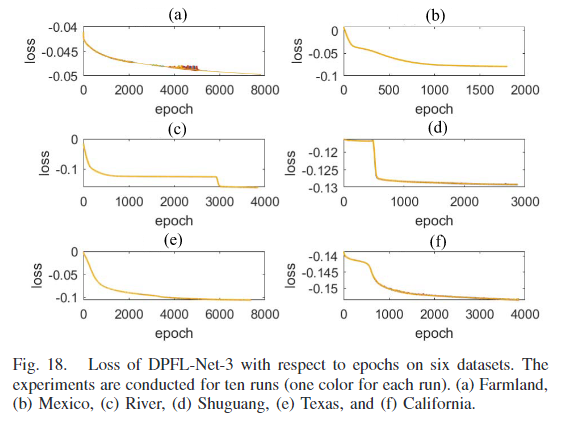
图 18 报告了 DPFL-Net-3 在不同数据集上随着训练周期的变化而平均损失(所有像素的平均损失)。实验进行了十次运行。经过一定数量的训练周期后,损失函数趋于稳定。观察到损失函数对未变化类别的概率图 Ps,u 的初始化不敏感。在包含一个或两个SAR图像的数据集上,由于散斑噪声的影响,损失函数在十次运行中显示出一些小的波动。
P2V-CD-2022-ITIP
Transition_Is_a_Process_Pair-to-Video_Change_Detection_Networks_for_Very_High_Resolution_Remote_Sensing_Images-ITIP-2022
提出的原因
①过去的融合的方法仅仅是通道拼接或者是点对差异,这些操作本文认为不足以充分考虑到时间维度,这也是现有方法无法准确定位实际变化并大幅抑制伪变化的原因之一。
②并没有充分关注空间和时间域的耦合所带来的挑战,空间代表着图像中的物体和景观的布局和结构,时间代表着季节性变化等,在单流方法中,使用的是一个联合的单一路径结构来处理图像,这意味着空间和时间特征在整个编码-解码过程中被同时考虑。这种方法的问题是它可能无法充分区分或优化这两种特征,因为它们在整个处理过程中都被紧密结合。而在双流方法中,空间特征和时间特征被分开处理:编码器主要处理空间特征,而解码器则同时处理空间和时间特征。这种方法的挑战在于解码器在处理时需要同时考虑两种类型的数据,这可能使得模型难以集中精力优化任一特征,特别是在识别和处理时间特征时可能遇到困难。
③如果直接将视频理解的架构用于变化检测任务,则会带来大量的计算,因此本文中将时间和空间的处理解耦,在空间中的网络架构(简单的二维卷积)用于高分辨率图像,而视频理解的架构(三维卷积)则用于降采样后的图像序列,这样达到降低计算量但是却不影响性能的目的。
网络架构
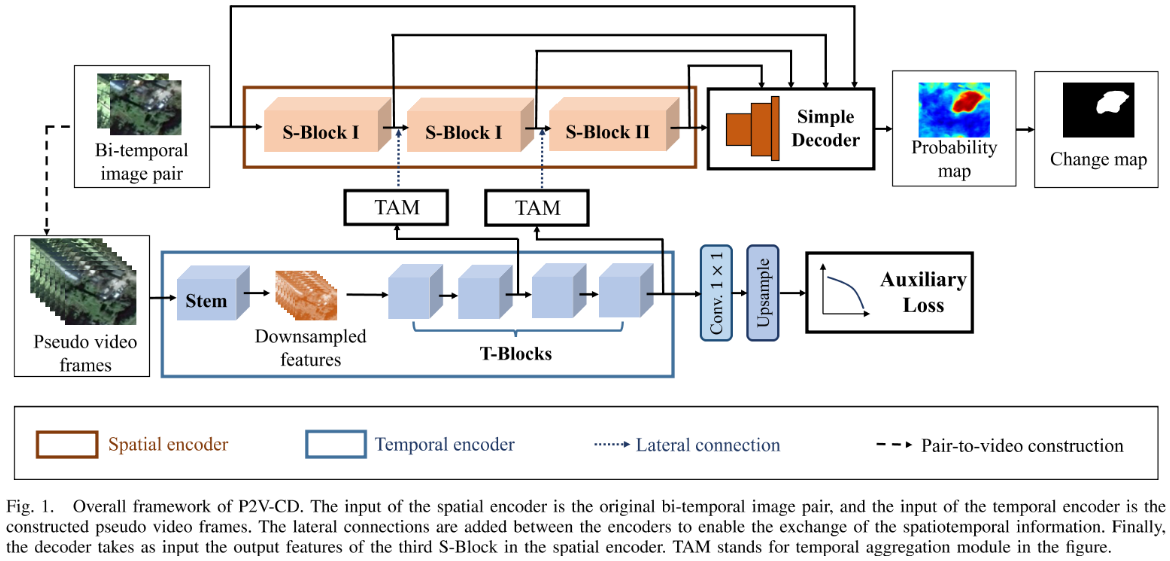
本文采用双分支解耦空间/时间并在后期重新融合进行变化检测的方法,

在空间分支中,首先将双时相图像拼接,然后经过三个S-Block(其中最后包括了步幅为2的最大池化)下采样提取空间特征,然后decoder还原进行变化检测。
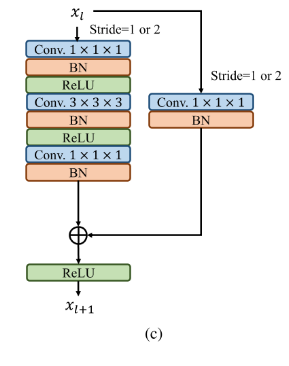
在时间分支中,首先本文将时间上的变化认为成视频理解问题,然后通过时间线性插值的方法,补充成了N帧的时间维度的图片序列,对于这个序列首先进行空间上步幅为4的卷积进行一个下采样,这样能够降低计算复杂度的同时能够让网络更加专注时间的变化,然后通过4个T-Block,T-Block中又使用了瓶颈结构去进行一个计算上的节约,在第三个T-Block再次进行一个时间空间中步幅均为2的下采样。
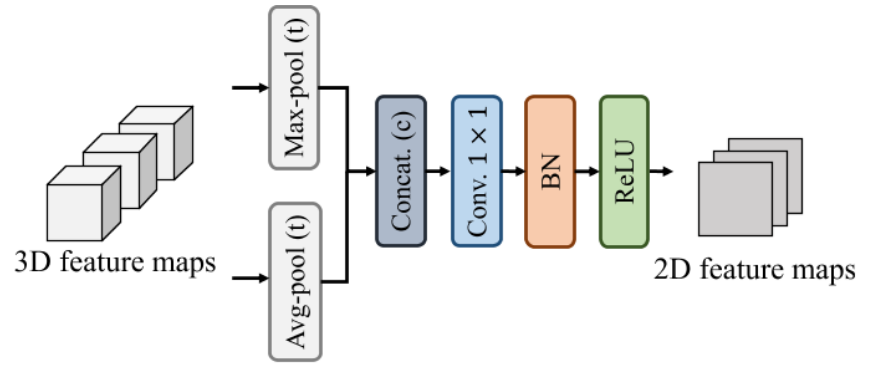
在横向融合中,考虑到从3D-4D的困难性,选择了从时间到空间的转变,首先对时间进行时间维度的两种池化然后拼接,接着一个空间的1*1卷积,进行通道数量的变化,得到了[C,H’,W’],空间尺度和空间分支的尺度不同,因此进行上采样然后和空间分支特征进行拼接。
实验方法
数据集
SVCD:谷歌地球获得的11个配准后的遥感图像对,分辨率在每像素3cm到100cm,随机裁剪和旋转后产生了16000对256*256的片段,10000用于训练,3000用于验证,3000用于测试,每个生成的片段对中至少包含一个更改的像素,只有对象 的语义类别发生改变时,才是发生变化类,未考虑场景中的季节性变化。
LEVIR-CD:介绍过
WHU:介绍过
评价指标
Pre,Rec,F1
实验设置
batchsize = 8,adam,帧数N的构建为8,,中间层的损失函数权重为0.4,加权二值交叉熵中变化和伪变化等重。学习率中,SVCD初始为0.0004,260k次收敛,LEVIR-CD初始为0.002,220k次收敛,WHU初始为0.0004,160k次收敛。衰减分别为70个epoch降低10%,60个epoch降低20%,105个epoch降低20%。
对比的方法
FC-EF/FC-Siam-Conc/FC-Siam-diff、CDNet、STANet、BIT、L-UNet、IFN、SNUNet
STANet是一种融合了时空注意机制的后期融合方法,可增强双时相图像深层特征的识别能力。
BIT采用定制的CNN与一对变压器编码器和解码器相结合,有效地解决了CD问题。
L-UNet是典型的卷积和循环方法,其中全卷积LSTM块被装备在深度神经网络中进行端到端训练。
IFN之前看过,
实验结果
SVCD
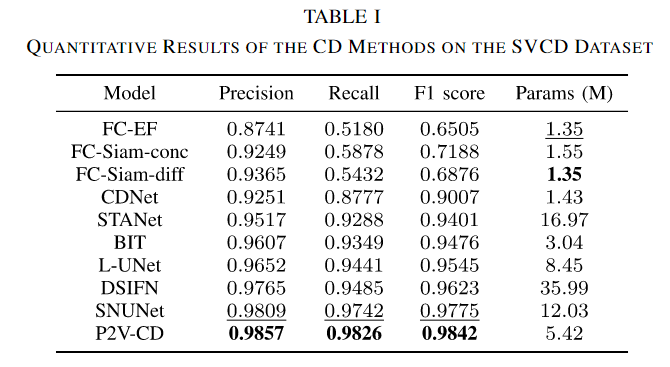
尽管FC-EF、FC-Siam-conc、FC-Siam-diff和CDNet具有占用更小内存的优势,但就所有三个指标而言,它们的结果是最差的。基于注意力的方法BIT比其对应的方法STANet显示出全面的优势。在此数据集上,基于rnn的方法LUNet在精度和召回率方面优于基于注意力的方法。SNUNet和DSIFN分别获得第二和第三高的F1分数,说明它们在抵抗季节变化引起的伪变化方面具有优势。最后,我们提出的P2V-CD方法获得了最佳的综合性能,精度为0.9857,召回率为0.9826,F1得分为0.9842。值得注意的是,P2V-CD模型的参数数量适中(5.42 M),明显小于DSIFN(总数35.99 M,可训练参数21.28 M)和SNUNet (12.03 M)。

图4给出了CD方法的感知比较。显然,除P2V-CD外,所有方法的结果中都存在大量的误分类改变像元。特别是,在CDNet、STANet和DSIFN的结果中,有一个明显的建筑物部分缺失。此外,在CDNet、STANet和BIT的结果中也缺少足迹。一般来说,P2V-CD的变化图具有最理想的视觉效果,它看起来最接近地面真相。
LEVIR-CD
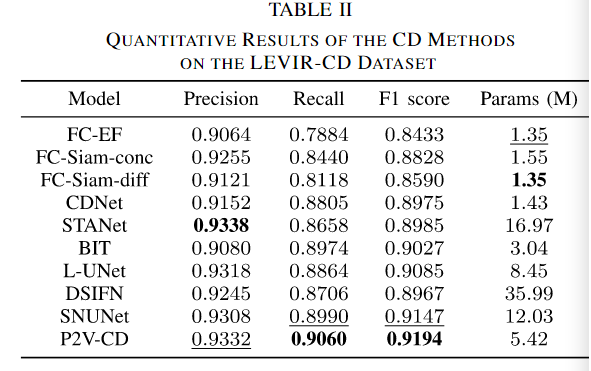
从表2来看,FC-EF、FC-Siam-conc和FC-Siam-diff的检测结果也是最不令人满意的。DSIFN的F1得分与CDNet相当(差值在0.001以内),但DSIFN的准确率相对较高,召回率较低。此外,从CDNet的结果到STANet的结果,仅观察到边际性能增益。这是因为STANet没有在准确率和召回率之间保持合理的平衡。在所有方法中,STANet的精密度最高,为0.9338,召回率较低,仅为0.8658。在该数据集上,L-UNet和BIT是两种有竞争力的方法,F1得分都在0.90以上。SNUNet还通过在召回和F1得分指标中获得第二好的结果显示出突出的性能。我们的方法P2V-CD在LEVIR-CD数据集上保持了优异的性能,召回率为0.9060,F1得分最高为0.9194。

图5所示的定性结果提供了更直观的CD方法比较。我们观察到,大多数比较CD方法在建筑密集地区存在虚假变化或漏检。相比之下,提出的P2V-CD方法即使使用高度不平衡的训练集训练,也能精确地检测到小型建筑物的施工。为了全面分析,我们在图5的最后一行也展示了一个P2V-CD没有达到令人满意的视觉效果的案例。在这种情况下,场景比前两种情况更复杂,并且所有方法的结果都存在误分类像素,包括所提出的P2V-CD。这表明该方法处理更复杂场景的能力有待进一步增强。
WHU
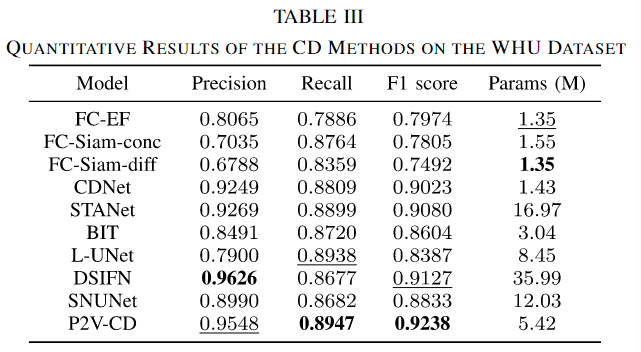
从表III中,FC-EF、FC-Siam-conc和FC-Siam-diff并没有被观察到优于其他方法。CDNet的查准率和查全率均优于前三种方法,但其F1得分仍比STANet低0.0057。我们还观察到,L-UNet和BIT虽然在另外两个数据集上获得了很高的评价分数,但却无法再现良好的性能。从较低的精度可以合理地推断,它们的检测结果中存在相当多的遗漏。我们认为这两种方法对样本量更敏感,因此当在较小的WHU数据集上训练时,它们更容易遭受过拟合。尽管使用最大的模型尺寸,DSIFN在预训练编码器的帮助下防止过拟合。在该数据集上达到了最高的精度0.9626,第二高的F1得分0.9127。相比之下,同样具有丰富网络参数的SNUNet方法在该数据集上无法与小得多的CDNet模型竞争。我们提出的P2V-CD方法在F1得分上具有绝对优势,与其他方法相比至少领先0.0110分。

假警报是CDNet和DSIFN结果中的一个主要问题,如图6所示。此外,STANet和SNUNet会导致误检和漏检。对于BIT和L-UNet,变化图上的观察结果与表III中先前的观察结果一致,因为结果中存在广泛的FN区域。L-UNet方法也不能有效地消除其变化图中的误检像素。在所有方法中,P2V-CD方法的视觉效果最好。P2V-CD不仅能以更完整的边界圈定变化区域,还能显著抑制检测结果中的伪变化。
总的来说,P2V-CD的持续良好性能表明它对于通用CD和构建CD都是一种引人注目的方法。我们的方法对于数据集中大量存在的负样本或相对较小的样本量也更具鲁棒性。我们认为,正是时间的显式建模和时空解耦设计,促使P2V-CD模型有效地利用有效的时间线索,以更高的精度定位变化区域。
消融实验
组件的消融
为了评估每个组件对整体性能的影响,本文中拆除了8个分支,
①P2V-NoTE(移除了时间编码器和侧向连接,形成单流架构)
②P2V-NoSE(移除空间编码器,增加了两个T-Blocks,将TAMs的输出直接与对应的解码器块连接,形成单流架构)
③P2V-2Donly(时间编码器中所有3D卷积换为2D,每个2D卷积在所有视频中共享)
④P2V-2DOnlyFlat(所有帧在通道数进行连接)
⑤P2V-LateFusion(移除侧向连接,直接将两个编码器的输出拼接作为解码器的输入)
⑥P2V-learnL(利用学习的策略从双时相像对构建伪视频帧,在时间维度上操作的卷积核,核大小为1,共N个这样的卷积核就能产生N帧的图像序列)
⑦O2V-LearnNL(利用两个交错的非线性激活卷积层来产生视频,就是在之前的单个卷积的基础上加入了非线性激活层然后再加一层卷积层)
⑧P2V-NoDS(去除了中间层的损失函数)
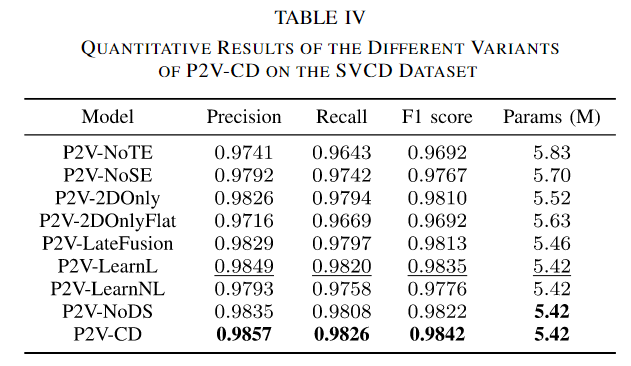
在消融的过程中,失去了时间编码器的P2V-NoTE得到了最差劲的结果,具有最低的rec和F1,这表明了时间编码器在网络中是最重要的;而去除了空间编码器的NoSE也会导致检测精度的大幅下降,用2D卷积代替3D卷积(在各个图像中独立使用),F1下降了0.0032,证实了在时序编码器中使用3D卷积的优越性,如果3D特征坍塌为2D卷积(此时拼接在了一起则是完全的将时间维度给丢弃了),可以观测到性能的进一步下降了0.0118。P2V-2DOnly和P2V-2DOnlyFlat之间的性能差距表明TAM的重要性,因为在时间编码器中采用2D卷积时,TAM主要提供时间聚合能力。从P2V-LearnL和P2V-LearnL的结果中,使用更高级的基于学习的时间插值策略并没有提高CD模型的性能。采用简单线性策略的模型在所有指标上都表现更好。相比之下,我们发现我们尝试过的最复杂的插值策略,即基于非线性学习的策略,对检测精度产生了负面影响。我们还观察到,缺乏深度监管导致所有三个指标的业绩显著下降。
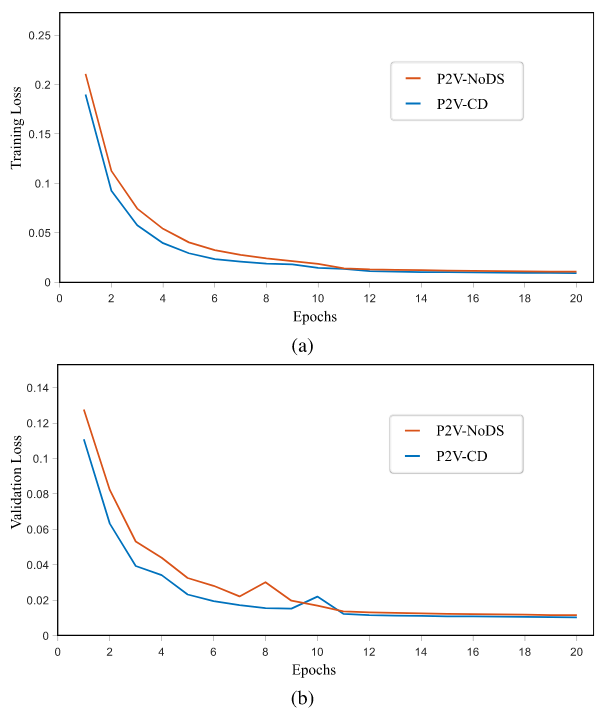
通过绘制的损失曲线,可以看出,深度监督成功地加速了网络参数的收敛,提高了检测精度。
帧数的消融
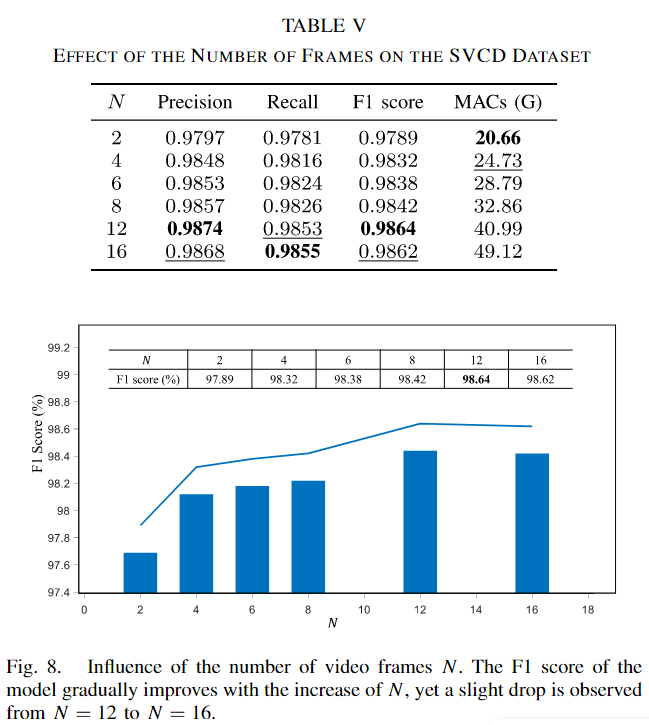
随着N的增加,F1分数逐渐提高。这是预期的结果,因为伪视频中帧数越多,模型从更多的数据和更细的时间分辨率中获得有关变化的更多有用知识。但是,F1分数的增加不是单调的,从N为12增加到16时出现了小幅的性能下降。本文认为这种下降可能归因于数据饱和,这可能由两个原因解释:一是CD模型能够有效学习的数据量有上限,通常由模型容量决定;二是过大的N值会降低真实数据(即原始双时相图像)在构建的伪视频帧序列中的比例,使得CD模型更容易过拟合伪视频的特定构建模式。表V还显示,当N设置为较大值时,乘累加操作(MACs)激增。这种迅速增加的计算开销阻碍了长伪视频帧序列的使用。虽然构建具有更多帧的视频显着有利于检测性能,但这并不是导致P2V-CD竞争结果的唯一因素。为了证明这一点,一个基本的事实是,即使只有两帧,P2V-CD也能够保持与P2VNoTE相比的优越性能(F1分数为0.9789比0.9692)。也就是说并不是单纯由于时间帧的增加为唯一因素导致的结果的优越,即使不构建其他的时间帧,也能在双时相图像帧的情况下达到更好的效果,说明了主要原因来自于时间分支的构建。
特征可视化证明
时间编码器特征
可视化了第二个和第四个T-Block中的逐帧特征,展示在图9中。使用了文献[56]提出的技术来生成可视化结果。

对P2V-CD的两个变体进行了比较:P2V-2DOnly(仅使用2D卷积的变体)和完整模型。从图9中可以看出,P2V-2DOnly的特征比P2V-CD的特征信息含量要少。在P2V-2DOnly中,第二个T-Block的第二到第六帧输出特征和第四个T-Block的最后三帧输出特征表现出较低的空间变异性。
为了定量的得到特征的信息内容,本文计算了测试集中每个案例的特征图像熵值,发现对于P2V-CD,第二个T-Block的输出特征的熵值为4.1445,第四个T-Block的输出特征的熵值为4.1005;而对于P2V-2DOnly,第二个T-Block的对应熵值为3.7550,第四个T-Block的对应熵值为3.3291,这支持了本文的思想,即通过明确考虑时间交互,时间编码器能够有效地利用更丰富的信息源,而不仅仅是进行简单的比较-对比操作。
空间编码器特征
可视化了空间编码器中第一个S-Block和第三个S-Block的输出特征。比较的是P2V-CD和P2V-NoTE

图10可以看出,对于较浅的层,即第一个s块,P2V-CD比P2V-NoTE描绘的空间细节更精细;对于更深一层,即第三个s块,P2V-CD的特征映射更好地突出了groundtruth标签中出现的重要语义对象。
为了进行定量分析,我们建议使用总变差(TV)度量来衡量精细纹理的保存程度,并使用特征图和真实图像之间的Pearson积矩相关系数(PCC)来衡量语义信息的数量。TV值越高,图像中的小空间结构保存越好,PCC值越高,特征与目标变化图的关系越密切。
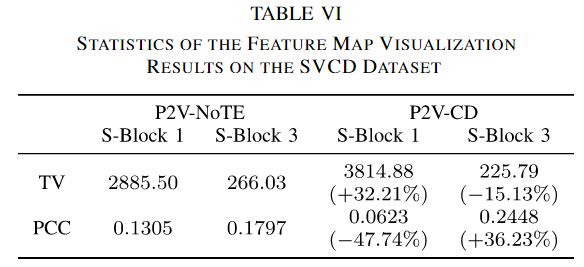
其中我们也给出了从P2V-NoTE到完整模型的TV和PCC的相对变化。表VI的结果与图10一致:对于第一个S-Block, P2V-CD的特征TV值高出32.21%,但PCC仅为P2VNoTE的一半;在第三个S-Block中,P2V-CD的TV值比P2V-NoTE低15.13%,但PCC高36.23%。本文是这样认为的,P2V-CD中的空间编码器最初更加关注空间上下文,因此第一S-Block提取的特征较少关注时间相关的变化,与真实标签的PCC较低。随着时间特征通过侧向连接的融合,融合特征获得了更多的变化信息,空间编码器的第三S-Block因而产生了更多语义特征。对于P2V-NoTE模型,时空耦合贯穿整个编码过程,因此网络必须同时关注空间和时间。结果是,较浅层提取的特征未能捕获更多的空间细节,较深层提取的特征与真实变化图的相关性较低。基于上述分析,可以得出结论:P2V-CD成功地在功能上解耦了CD任务的空间和时间方面。
计算时间

DSIFN和SNUNet获得了高F1分数,但它们需要大量的计算。
L-UNet、STANet、BIT和CDNet的计算开销适中,但未能达到最佳性能。FC-Siam-conc、FC-Siam-diff和FC-EF使用最少的计算资源,但它们的检测准确性远远落后于其他方法。与这些方法相比,P2V-CD在F1分数方面超越了所有对手,同时并没有因巨大的计算复杂度而受到阻碍。图11中绘制了F1分数与MACs的散点图,可直观看出不同方法在准确性和计算成本之间的关系。
在不同的视频帧N的情况下的计算复杂度,两条曲线都显示了MACs与N之间的线性关系,但斜率不同。随着输入图像数量的增加,L-UNet的MACs呈陡峭上升趋势。相比之下,P2V-CD的MACs增长更为温和,尽管在N=2时起点较高。在N=16的情况下,P2V-CD的MACs为49.12 GMACs,不到L-UNet的117.47 GMACs的一半。使用3D CNN而非RNN的另一个好处是,3D卷积能以并行方式处理数据,这大大加快了变化检测模型的训练和推理速度。