《白话强化学习与python》笔记——第五章时间分差
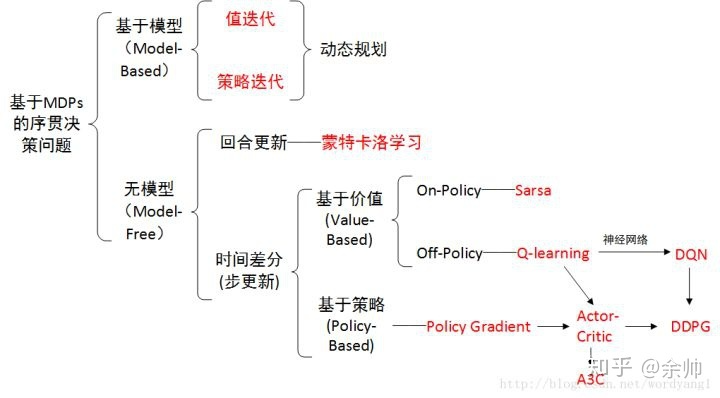
时间差分是一种用来估计一个策略的价值函数的方法,它结合了蒙特卡洛和动态规划算法的思想。时序差分方法和蒙特卡洛的相似之处在于可以从样本数据中学习,不需要事先知道环境;和动态规划的相似之处在于根据贝尔曼方程的思想,利用后续状态的价值估计来更新当前状态的价值估计。
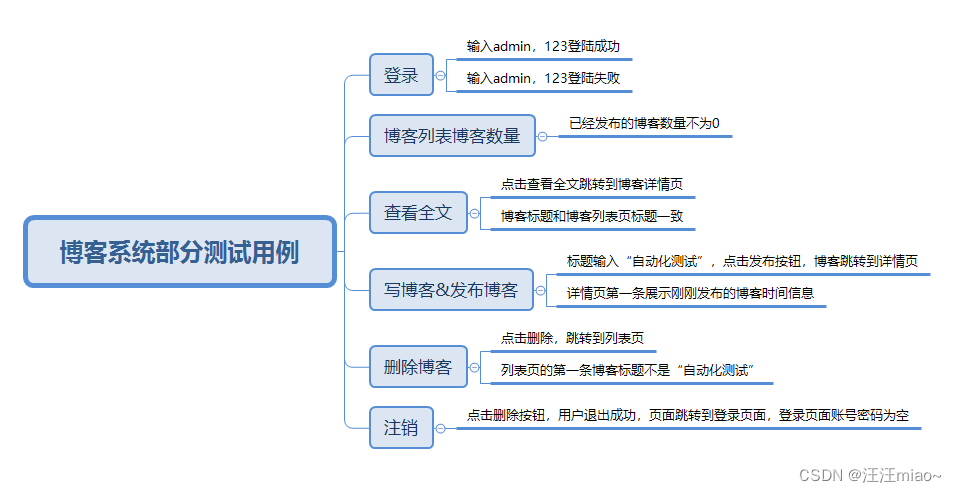
Sarsa 算法
在SARSA算法的眼中(或者说计算逻辑中)在状态S下,要想把动作A的估值 Q(S,A)计算准确,需要研究
S→A→R→S’→A’
这个序列,并对这个序列中的估值进行调整,从而达到使贝乐曼方程收敛的目的。
Sarsa 的具体算法如下:

基本概念: SARSA代表状态(State)、行动(Action)、奖励(Reward)、下一个状态(Next State)和动作(Action)。它是一种基于值函数的强化学习方法,与Q学习(Q-learning)相似,但在某些关键方面有所不同。
更新规则: 在SARSA算法中,智能体在每一步都会根据当前的状态、所采取的行动以及转移到的下一个状态来更新其Q值。不同于Q学习,在SARSA中,用于更新Q值的动作就是实际采取的动作,即在策略更新。
策略评估: SARSA算法通过迭代的方式更新Q值,从而逐步优化策略以获得最大的累积奖励。它允许智能体学习到给定状态下执行特定行动的预期回报。
探索与利用:在实施SARSA算法时,智能体需要在探索环境(尝试不同的行动)和利用当前知识(选择已知的最佳行动)之间找到平衡。
算法稳定性: 由于SARSA算法采用的是在策略更新,因此它通常比Q学习更加稳定,但可能收敛速度较慢。
实际应用: SARSA算法适用于那些对实时反馈和决策调整要求较高的场景,如机器人控制或实时游戏。
变体: 存在一种称为SARSA(λ)的变体,其中λ是衰减因子,用于权衡过去经验对未来预测的影响,这有助于算法更好地处理部分可观察的环境。
多步sarsa算法:
多步 Sarsa 算法
算法原理:
多步Sarsa算法是在传统Sarsa算法的基础上发展而来的。在传统Sarsa中,Q值的更新是基于一步时序差分(TD)学习的,即只考虑当前状态和下一步状态之间的奖励和价值差异。而在多步Sarsa中,Q值的更新会考虑到多个时间步骤后的状态和奖励。
更新规则:
在多步Sarsa算法中,更新公式包括了折扣因子γ和衰退因子λ。具体来说,更新目标变成了n步TD的目标,即考虑了从当前状态开始的n步内所获得的所有奖励及其对未来状态值函数的影响。
执行过程:
在执行多步Sarsa算法时,对于经历的状态对(s, a, r, s’, a’),会根据上述更新规则进行Q值更新。对于未经历的状态动作对,则保持其Q值不变。
与Sarsa的区别:
传统的Sarsa算法每次更新只考虑单步转移的结果,而多步Sarsa通过考虑多步的回报信息,可以更全面地评估一个策略的长期效果。这种多步更新机制使得学习过程可能更加稳定,并有助于更快地收敛到最优策略。
实际应用:
多步Sarsa算法适用于需要长期规划和决策的场景,如复杂的游戏环境、机器人导航等,在这些场景中,考虑未来的多个步骤可能会带来更好的决策结果。
Q-learning算法
值迭代方法: Q-learning属于值迭代的强化学习算法。它更新一个动作值函数,也称为Q值,用来表示在特定状态下采取特定行动所能获得的预期回报。
Q值表: 在Q-learning中,状态与动作的组合被存储在一个叫做Q值表的数据结构中。这个表会随着时间的推移而不断更新,直到收敛到最优策略。
探索与利用: Q-learning算法在探索环境(尝试不同的行动)和利用已有知识(选择已知的最佳行动)之间进行权衡。这种权衡通常通过一个超参数ε(epsilon)来控制,它决定了智能体选择随机探索的概率。
奖励机制:智能体的行动会根据环境给予的奖励来进行调整。环境会根据智能体的动作反馈相应的回报(reward),而这些回报会被用来更新Q值表。
超参数的选择: Q-learning的性能受到几个超参数的影响,包括折扣因子γ(决定未来奖励的当前价值)、探索率ε(影响探索与利用的平衡)以及学习率α(决定Q值更新的步长)。合理选择这些超参数对于算法的有效学习至关重要。
应用场景: Q-learning算法适用于离散的状态空间和动作空间,它可以应用于多种问题,如游戏、路径规划、资源管理等。
局限性: 尽管Q-learning有很多优点,但它也有局限性,例如在面对大规模状态空间或连续状态空间时可能不太适用。此外,它需要足够多的迭代次数才能保证收敛到最优策略。
实现工具: Q-learning算法可以利用各种工具和库来实现,比如Numpy和OpenAI的Gym库,这些工具为算法的实现提供了便利的环境和支持。
On-Policy 和 Of-Policy
On-Policy: 指的是行为策略(智能体实际执行的策略)和目标策略(用于更新价值函数或Q值的策略)是同一个策略。这意味着在学习过程中,智能体根据当前策略探索环境并收集数据,然后使用这些数据来更新同一个策略的参数。换句话说,智能体的学习和行动是基于同一策略进行的。
Off-Policy: 指的是行为策略和目标策略不是同一个策略。在这种情况下,智能体在一种策略指导下进行探索和行动,但会将收集到的数据用于另一种策略的学习。这使得算法能够利用其他策略产生的数据,甚至是过去的经验或由其他智能体提供的数据来学习。
On-Line学习和Of-Line学习
在线学习(Online Learning)和离线学习(Offline Learning)是机器学习中的两种主要学习范式,它们在数据处理方式、应用场景和优缺点上各有特色。
数据处理方式: 在线学习是一种实时的学习方式,它逐个处理数据点并即时更新模型权重。这种方式允许模型随着新数据的到来而不断进化,适用于数据流不断变化的场景。相比之下,离线学习通常指的是使用一批固定的历史数据进行训练,在所有数据都处理完毕后才更新模型。这要求所有训练数据在学习开始前都是可用的。
应用场景: 在线学习适用于那些需要快速适应新趋势和变化的实时系统,例如股市交易、在线广告优化等场景。离线学习则常用于可以承受一定延迟的场合,比如电子邮件过滤、图像识别等,这些任务可以先积累数据再批量处理。
优点: 在线学习能够及时反映数据的最新变化,并且可以在数据量巨大无法一次性加载到内存中时仍然有效工作。而离线学习的优点在于可以进行大批量的数据操作,通常会得到更为稳定和准确的模型。
缺点: 在线学习可能因为单次更新的错误而累积误差,导致模型稳定性不如离线学习。离线学习的缺点在于它对新数据的适应性不如在线学习,每当有新数据时都需要重新训练模型。