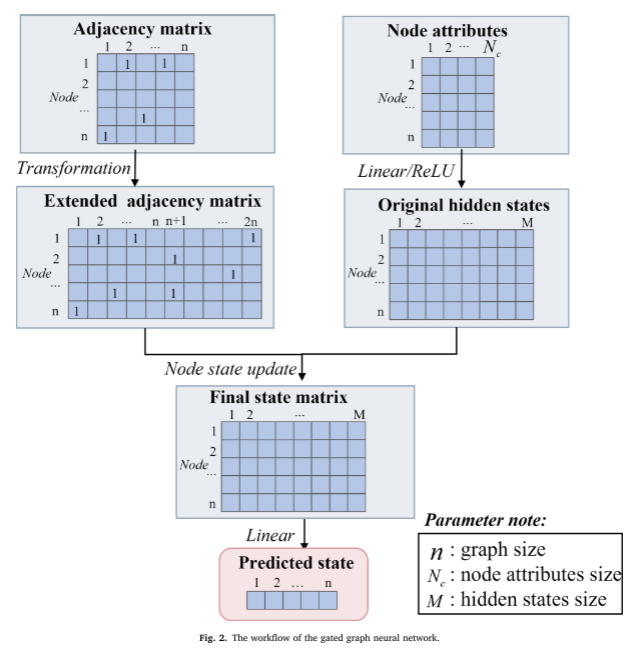
文章目录
week32 TAD
摘要
本文主要讨论时间序列的噪声检测。首先本文简要介绍了时间序列噪声的种类。其次本文展示了题为Towards a Rigorous Evaluation of Time-series Anomaly Detection的论文主要内容。该文从理论和实验上解释了点调整(PA)方案可能高估检测性能,从而导致错误的估计排名。该文指出,在禁止PA的情况下,未经训练的模型能获得与现有方法相当的检测性能。根据发现,提出了新的基线模型和评估方案。
Abstract
This article focuses on noise detection for time series. First, this paper briefly introduces the types of time series noise. Secondly, this paper presents the main content of the paper entitled Towards a Rigorous Evaluation of Time-series Anomaly Detection. This paper theoretically and experimentally reveal that the PA protocol has a great possibility of overestimating the detection performance, enhence, it may lead to wrong estimate rank. This paper points by showing that an untrained model obtains comparable detection perfortmance to the existing methods even when PA is forbidden. Based on the findig in this paper, it proposes a new baseline and an evaluation protocol.
一、时序噪声检测

二、文献阅读
1. 题目
题目:Towards a Rigorous Evaluation of Time-series Anomaly Detection
作者:Siwon Kim, Kukjin Choi, Hyun-Soo Choi, Byunghan Lee, Sungroh Yoonhttps://arxiv.org/search/cs?searchtype=author&query=Wang,+C)
链接:https://arxiv.org/abs/2109.05257
发布:AAAI 2022
2. abstract
近年来,时间序列异常的研究在相关数据集上取得了较高的F1分数。但大多研究基于点调整的评估方案。该文从理论和实验上解释了点调整(PA)方案可能高估检测性能,从而导致错误的估计排名。该文指出,在禁止PA的情况下,未经训练的模型能获得与现有方法相当的检测性能。根据发现,提出了新的基线和评估方案。
In recent years, proposed studies on time-series anomaly detection (TAD) report high F1 scores on benchmark TAD datasets. However, most studies apply a peculiar evaluation protocol called point adjustment (PA) before scoring. This paper theoretically and experimentally reveal that the PA protocol has a great possibility of overestimating the detection performance, enhence, it may lead to wrong estimate rank. This paper pointed by showing that an untrained model obtains comparable detection perfortmance to the existing methods even when PA is forbidden. Based on the findig in this paper, it proposes a new baseline and an evaluation protocol.
3. 问题与模型阐述
3.1 TAD评估中的陷阱
3.1.1 问题描述
首先,将在时间 T 期间从 N 个传感器观测到的时间序列信号表示为 X = x 1 , . . . , x T , x t ∈ R N X = {x_1, ..., x_T}, x_t ∈ \mathcal{R}^N X=x1,...,xT,xt∈RN。作为传统方法,它被归一化并分成一系列步长为 1 的窗口 W = w 1 , . . . , w T − τ + 1 W = {w_1, ...,w_{T−\tau+1}} W=w1,...,wT−τ+1,其中 w t = x t , . . . , x t + τ − 1 w_t = {x_t, ..., x_{t+τ−1}} wt=xt,...,xt+τ−1 和 τ \tau τ 是窗口大小。仅针对测试数据集给出了地面实况二进制标签 y t ∈ { 0 , 1 } y_t ∈ \{0, 1\} yt∈{0,1},指示信号是异常 (1) 还是非异常 (0)。 TAD 的目标是预测测试数据集中所有窗口的异常标签 y ^ t \hat y_t y^t。通过将异常分数 A ( w t ) A(w_t) A(wt) 与 TAD 阈值 δ \delta δ 进行比较来获得标签,如下所示:
y ^ t = { 1 , if A ( w t ) > δ 0 , otherwise (1) \hat y_t= \begin{cases} 1,\quad \text{if}\ A(w_t)>\delta\\ 0,\quad \text{otherwise} \end{cases} \tag{1} y^t={1,if A(wt)>δ0,otherwise(1)
A ( w t ) A(w_t) A(wt) 的一个示例是原始输入与其重构版本之间的均方误差 (MSE),其定义如下:
A ( w t ) = MSE ( w t , w ^ t ) = 1 τ ∣ ∣ w t − w ^ t ∣ ∣ 2 (2) A(w_t)=\text{MSE}(w_t,\hat w_t)=\frac{1}{\tau}||w_t-\hat w_t||_2 \tag{2} A(wt)=MSE(wt,w^t)=τ1∣∣wt−w^t∣∣2(2)
其中 w ^ t = f θ ( w t ) \hat w_t = f_\theta (w_t) w^t=fθ(wt) 表示用 θ \theta θ 参数化的重建模型 f θ f_θ fθ 的输出。标记后,评估的精度 §、召回率 ® 和 F1 分数计算如下:

其中 TP、FP 和 FN 分别表示真阳性、假阳性和假阴性的数量。
TAD 测试数据集可能包含持续几个时间步长的多个异常片段。将 S 表示为 M 个异常段的集合;即, S = S 1 , . . . , S M S = {S_1, ..., S_M} S=S1,...,SM,其中 S m = t s m , . . . , t e m S_m = {t^m_s , ..., t^m_e } Sm=tsm,...,tem; t s m and t e m t^m_s\ \text{and}\ t^m_e tsm and tem 分别表示 S m S_m Sm的开始和结束时间。如果异常分数在 S m S_m Sm 中至少一次高于 δ,则 PA 将所有 t ∈ S m t ∈ S_m t∈Sm 的 y ^ t \hat y_t y^t 调整为 1。对于 PA,式1的标记方案修改如下:
y ^ t = { 1 , if A ( w t ) > δ or t ∈ S m and ∃ t ′ ∈ S m A ( w t ′ ) > δ 0 , otherwise (4) \hat y_t= \begin{cases} 1,\quad \begin{aligned} \text{if}\ A(w_t)>\delta\\ \text{or}\ t\in S_m\ \text{and}\ \exist_{t'\in S_m}A(w_{t'})>\delta \end{aligned}\\ 0,\quad \text{otherwise} \end{cases} \tag{4} y^t=⎩
⎨
⎧1,if A(wt)>δor t∈Sm and ∃t′∈SmA(wt′)>δ0,otherwise(4)
F1 PA \text{F1}_{\text{PA}} F1PA表示使用调整后的标签计算的 F1 分数。
3.1.2 具有高 F1PA 的随机异常分数
在本节中,证明 PA 协议高估了检测能力。
从式3的P和R的抽象分析开始。如上图所示,在数学上证明随机生成的 A ( w t ) A(w_t) A(wt) 可以实现接近 1 的高 F1PA 值。 由于F1分数是P和R的调和平均值,因此它还取决于TP、FN和FP。如式4所示,PA在保持FP的同时增加TP并减少FN。因此,在PA之后,P、R以及F1分数只会增加。
接下来,证明 F 1 P A F1_{PA} F1PA 可以轻松接近 1。首先,将 R 重新表述为条件概率,如下所示:
R = P r ( y ^ t = 1 ∣ y t = 1 ) = P r ( y ^ t = 1 ∣ t ∈ S ) = 1 − P r ( y ^ t = 0 ∣ t ∈ S ) (5) \begin{aligned} R &= Pr(\hat y_t=1|y_t=1)\\ &=Pr(\hat y_t=1|t\in S)\\ &=1-Pr(\hat y_t=0|t\in S) \end{aligned} \tag{5} R=Pr(y^t=1∣yt=1)=Pr(y^t=1∣t∈S)=1−Pr(y^t=0∣t∈S)(5)
假设 A ( w t ) A(w_t) A(wt) 是从均匀分布 U(0, 1) 中得出的使用 0 ≤ δ ′ ≤ 1 0 ≤ δ' ≤ 1 0≤δ′≤1 来表示该假设的 TAD 阈值。如果仅存在一个异常段,即 S = { { t s , . . . , t e } } S = \{\{t_s, ..., t_e\}\} S={{ts,...,te}}, P A PA PA后的R可表示如下,参照式4有:
R = 1 − P r ( ∀ t ′ ∈ S , A ( w t ′ < δ ′ ) < δ ′ ∣ t ∈ S ) = 1 − ∏ t ′ ∈ S P r ( A ( w t ′ ) < δ ′ ∣ t ∈ S ) = 1 − 1 γ ⋅ ∏ t ′ ∈ S P r ( A ( w t ′ ) < δ ′ ) = 1 − 1 γ ⋅ δ ′ ( t e − t s ) (6) \begin{aligned}\ R&=1-Pr(\forall t'\in S,A(w_{t'}<\delta')<\delta'|t\in S)\\ &=1-\prod_{t'\in S}Pr(A(w_{t'})<\delta'|t\in S)\\ &=1-\frac{1}{\gamma}\cdot \prod_{t'\in S}Pr(A(w_{t'})<\delta')\\ &=1-\frac{1}{\gamma}\cdot\delta'^{(t_e-t_s)} \end{aligned} \tag{6} R=1−Pr(∀t′∈S,A(wt′<δ′)<δ′∣t∈S)=1−t′∈S∏Pr(A(wt′)<δ′∣t∈S)=1−γ1⋅t′∈S∏Pr(A(wt′)<δ′)=1−γ1⋅δ′(te−ts)(6)
其中 γ = P r ( t ∈ S ) γ = Pr(t ∈ S) γ=Pr(t∈S) 是测试数据集异常率, P r ( A ( w t ′ ) < δ ′ ) = ∫ 0 δ ′ 1 = δ ′ Pr(A(w_{t'})<\delta')=\int^{\delta'}_01=\delta' Pr(A(wt′)<δ′)=∫0δ′1=δ′
P = P r ( y t = 1 ∣ y ^ t = 1 ) = R ⋅ P r ( y t = 1 ) P r ( y ^ t = 1 ) = R ⋅ γ P r ( y ^ t = 1 , y t = 1 ) + P r ( y ^ t = 1 , y t = 0 ) = γ − δ ′ ( t e − t s ) ( γ − δ ′ ( t e − t s ) ) + ( 1 − δ ′ ) (7) \begin{aligned} P&=Pr(y_t=1|\hat y_t=1)=R\cdot\frac{Pr(y_t=1)}{Pr(\hat y_t=1)}\\ &=R\cdot\frac{\gamma}{Pr(\hat y_t=1,y_t=1)+Pr(\hat y_t=1,y_t=0)}\\ &=\frac{\gamma-\delta'^{(t_e-t_s)}}{(\gamma-\delta'^{(t_e-t_s)})+(1-\delta')} \end{aligned} \tag{7} P=Pr(yt=1∣y^t=1)=R⋅Pr(y^t=1)Pr(yt=1)=R⋅Pr(y^t=1,yt=1)+Pr(y^t=1,yt=0)γ=(γ−δ′(te−ts))+(1−δ′)γ−δ′(te−ts)(7)
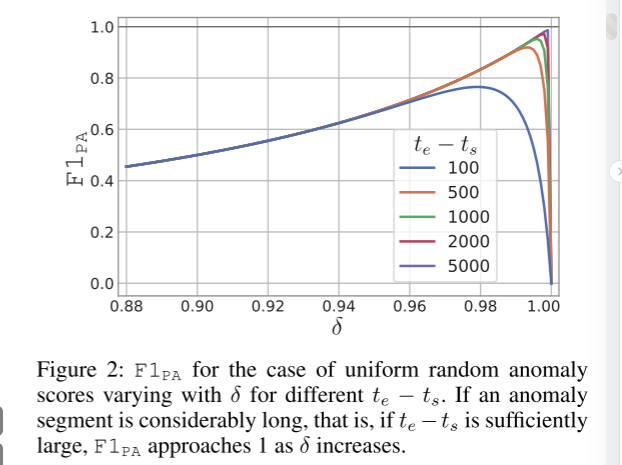
更通用的证明请参阅附录。数据集的异常率 γ 通常在 0 到 0.2 之间; te − ts 也由数据集决定,在基准数据集中一般范围为 100 到 5,000。下图描绘了当 γ 固定为 0.05 时,F1PA 在不同 t−ts 下随 δ’ 的变化。如图所示,除了异常段长度较短的情况外,通过改变δ‘,总是可以得到接近1的F1PA。
3.1.3 具有较高 F1 的未经训练的模型
该部分表明,从未经训练的模型获得的异常分数在一定程度上具有一定的参考价值。深度神经网络通常使用从高斯分布 N 0 , σ 2 N 0,σ^2 N0,σ2 中抽取的随机权重进行初始化,其中 σ 通常远小于 1。未经训练,模型的输出接近于零,因为它们也遵循零-平均高斯分布。基于重建或基于预测的方法的异常分数通常定义为输入和输出之间的欧几里得距离,在上述情况下,该距离与输入窗口的值成正比:
A ( w t ) = ∣ ∣ w t η ∣ ∣ 2 ≈ ∣ ∣ w t ∣ ∣ 2 where η = f θ a n d θ ∼ N ( 0 , σ 2 ) (8) A(w_t)=||w_t\eta||_2\approx||w_t||_2\\ \text{where}\ \eta=f_{\theta}\ and\ \theta\sim N(0,\sigma^2) \tag{8} A(wt)=∣∣wtη∣∣2≈∣∣wt∣∣2where η=fθ and θ∼N(0,σ2)(8)
在点异常的情况下,特定传感器值突然增加。这导致 ∣ ∣ w t ∣ ∣ 2 ||w_t||_2 ∣∣wt∣∣2 比正常窗口更大,这直接与 GT 异常的高 A ( w t ) A(w_t) A(wt) 有关。
3.2 对 TAD 进行严格评估
3.2.1 TAD 的新基线
该部分将建立一个新的基线,其中 F1 是根据具有简单架构的随机初始化重建模型(例如包含单层 LSTM 的未经训练的自动编码器)的预测来测量的。或者,异常分数可以定义为输入本身,这是式8的极端情况。 当无论输入如何,模型始终输出零。如果新 TAD 模型的性能未超过此基线,则应重新检查模型的有效性。
3.2.2 新的评估方案 PA%K
前文证明了 PA 有很大可能高估检测性能。没有PA的F1可以立即解决高估问题。然而,根据测试数据的分布,F1 可能会意外地低估检测能力。
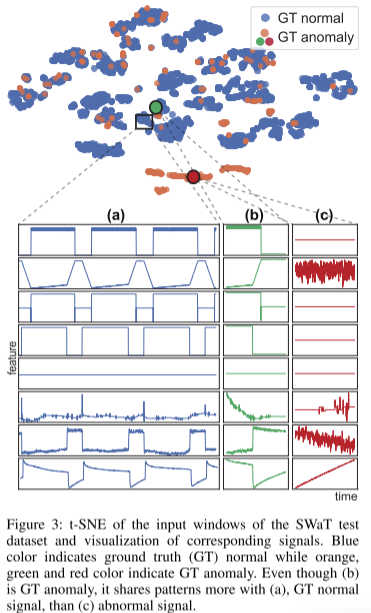
使用 t 分布随机邻域嵌入 (t-SNE)进一步研究了这个问题,如下图所示。t-SNE 由安全水处理 (SWaT) 的测试数据集生成。蓝色和橙色分别表示正常和异常样本。大多数异常形成一个远离正常数据分布的独特簇。然而,一些异常窗口比异常窗口更接近正常数据。 (b) 和 © 分别描绘了与绿点和红点对应的信号的可视化。尽管两个样本都被注释为 GT 异常,但 (b) 与 (a) 的正常数据共享的模式多于 ©。仅因为模型无法检测到 (b) 等信号就得出模型性能不足的结论,可能会导致检测能力被低估。
因此,提出了一种替代评估协议PA%K,它可以减轻F1PA的高估效应和F1低估的可能性。请注意,不建议取代现有的 TAD 指标,而是与它们一起使用。 PA%K 的思想是,仅当 Sm 中正确检测到的异常数量与其长度的比率超过 PA%K 阈值 K 时,才将 PA 应用于 Sm。PA%K 修改了式4如下:
y ^ t = { 1 , if A ( w t ) > δ or t ∈ S m and ∣ { t ′ ∣ t ′ ∈ S m , A ( w t ′ > δ } ∣ ∣ S m ∣ > K 0 , otherwise \hat y_t= \begin{cases} 1, \begin{aligned} \text{if}\ A(w_t)>\delta\ \text{or}\\ t\in S_m\ \text{and}\frac{|\{t'|t'\in S_m,A(w_{t'}>\delta\}|}{|S_m|}>K \end{aligned}\\ 0,\text{otherwise} \end{cases} y^t=⎩
⎨
⎧1,if A(wt)>δ ort∈Sm and∣Sm∣∣{t′∣t′∈Sm,A(wt′>δ}∣>K0,otherwise
其中 ∣ ⋅ ∣ |\cdot| ∣⋅∣表示 Sm 的大小(即 t e m − t s m t^m_e −t^m_s tem−tsm ),K 可以根据先验知识在 0 到 100 之间手动选择。例如,如果测试集标签可靠,则允许更大的K。若要消除对 K 的依赖性,则测量 K 从 0 增加到 100 所获得的 F1PA%K 曲线下面积。
4. 文献解读
4.1 Introduction
PA协议是基于一个异常时期的单个警告的强度足以使得系统恢复。下文中采用了PA协议的F1分数称PAF1,未采用称F1。
该文指出PA很有可能高估模型性能。典型的 TAD 模型会生成一个异常分数,告知输入异常的程度,并在该分数高于阈值时预测异常。
使用 PA,随机生成的异常分数的预测与训练有素的模型的预测变得相同,如下图所示。
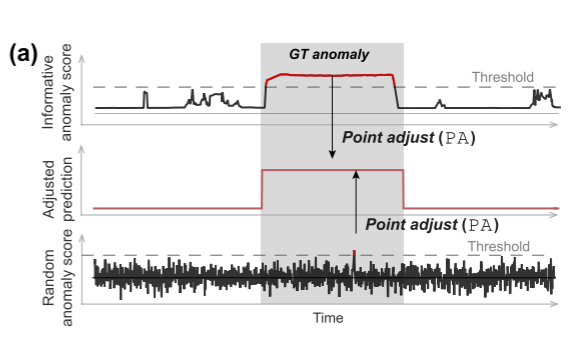
黑色实线显示两种不同的异常分数;上面的线显示了训练有素的模型的信息分数,而下面的线是随机生成的。阴影区域和虚线分别表示真实值 (GT) 异常段和 TAD 阈值。从上向下分别是信息较为丰富的情况、PA处理后情况、噪声曲线。第一种情况有较长一段时间为GT异常,而噪声情况仅有一个点为噪声情况。但当实行PA协议之后,预测难度增高。如果随机异常分数可以产生与熟练检测模型一样高的 F1PA,则很难得出 F1PA 较高的模型比其他模型表现更好的结论。
实验结果表明,随机异常分数可以推翻大多数最先进的 TAD 方法如下图,其中Random score为随机分数。
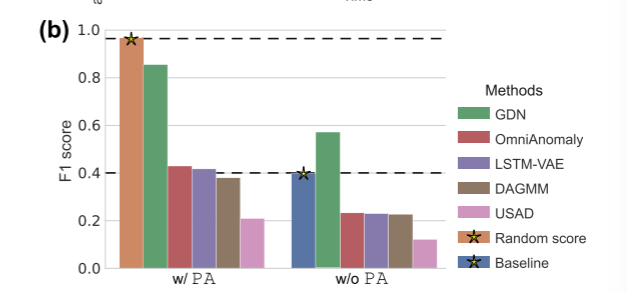
根据观察,现有的 TAD 方法似乎并没有比本文提出的基线获得显着的改进。此外,有几种方法未能超过它。图上图右侧总结了对基准数据集之一的观察结果。
该文提出了当前声称带来重大改进的 TAD 方法是否得到了正确评估的问题,并首次为 TAD 的严格评估提出了方向。
4.2 创新点
- 该文证明 PA,一种特殊的 TAD 评估协议,大大高估了现有方法的检测性能。
- 该文表明,如果没有 PA,现有方法相对于基线没有(或大多不显着)改进。
- 根据研究结果,提出了新的基线和评估方案,用于严格评估 TAD。
4.3 实验过程
4.3.1 实验数据集
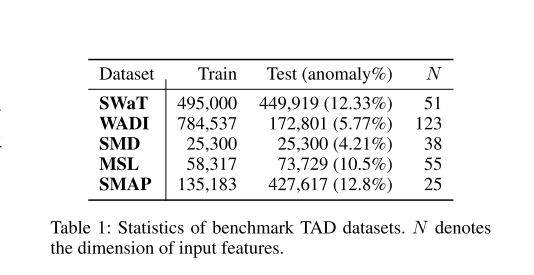
在本节中,我们将介绍五个最广泛使用的 TAD 基准数据集,如下所示:
安全水处理 (SWaT):SWaT 数据集是在 11 天内从小型水处理测试台收集的包括 51 个传感器(Mathur 和 Tippenhauer 2016)。在过去 4 天内,使用不同的攻击方法注入了 41 个异常,而在前 7 天内仅生成正常数据。
配水测试台 (WADI):WADI 数据集是从一个精简的城市配水系统获取的,该系统有 123 个传感器和执行器,运行了 16 天。前 14 天仅收集到正常数据,其余两天出现异常。测试数据集共有 15 个异常片段。
服务器机器数据集(SMD):SMD 数据集是从 28 台服务器机器和 38 个传感器收集了 10 天;前5天只出现正常数据,后5天间歇性注入异常数据。 SMD 数据集的结果是每台机器 28 个不同模型的平均值。
火星科学实验室(MSL)和土壤湿度主动被动(SMAP):MSL和SMAP数据集是从NASA的航天器收集的真实世界数据集。这些是来自航天器监测系统事件意外异常 (ISA) 报告的异常数据。与其他数据集不同,训练数据中包含未标记的异常,这使得训练变得困难。
统计数据总结于下表中。
4.3.2 评估方式
下面,介绍了最近提出的 7 种代表性 TAD 方法以及上文中研究的 3 个例证。
USAD代表无监督异常检测,它在两阶段训练方案下训练由一个共享编码器和两个独立解码器组成的两个自动编码器:自动编码器训练阶段和对抗性训练阶段。
DAGMM表示深度自动编码高斯混合模型,它采用自动编码器生成表示向量并将其馈送到高斯混合模型。它使用估计的样本能量作为重建误差;高能量表明高度异常。
LSTM-VAE代表一种基于 LSTM 的变分自动编码器,采用变分推理进行重建。
OmniAnomaly应用 VAE 将时间序列信号建模为随机表示,如果给定输入的重建可能性低于阈值,则可以预测异常。它还将各个特征的重建概率定义为归因分数,并量化其可解释性。
MSCRED表示一种多尺度卷积循环编码器-解码器,由卷积 LSTM 组成,用于重建表征多个系统级别的输入矩阵,而不是输入本身。
THOC表示时间分层一类网络,它是多层扩张循环神经网络和分层深度支持向量数据描述。
GDN表示一个图偏差网络,它学习传感器关系图以检测异常与学习模式的偏差。
上文中的例证
- 随机异常得分。 F1 分数是用从均匀分布 U 中随机生成的异常分数来测量的,即 A ( w t ) ∼ U ( 0 , 1 ) A(w_t) ∼ U(0, 1) A(wt)∼U(0,1)。
- 输入本身作为异常分数表示假设 f θ ( w t ) = 0 f_θ(w_t) = 0 fθ(wt)=0 的情况,而不管 w t w_t wt。这相当于式8的极端情况。 因此, A ( w t ) = ∣ ∣ w t ∣ ∣ 2 A(w_t)=||w_t||_2 A(wt)=∣∣wt∣∣2。
- 随机模型的异常得分对应于式8,其中 η 表示随机模型的小输出。参数从高斯分布 N ( 0 , 0.02 ) N(0, 0.02) N(0,0.02) 初始化后固定。
4.3.3 F1PA与F1之间的相关性
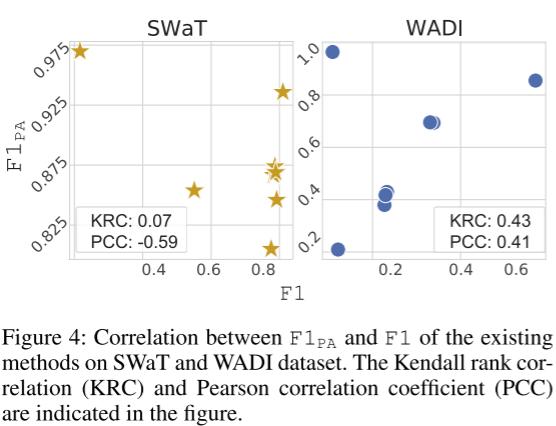
F1是最保守的检测性能指标。因此,如果F1PA可靠地代表了检测能力,那么它至少应该与F1有一定的相关性。上图绘制了 SWaT 和 WADI 的 F1PA 和 F1,如 USAD、DAGMM、LSTMVAE、OmniAnomaly 和 GDN 的初始研究报告。该图还包括例证 1-3 的结果。值得注意的是,鉴于只有一部分数据集和方法同时报告了 F1PA 和 F1,仅绘制了它们。对于 SWaT,皮尔逊相关系数 (PCC) 和肯德尔等级相关系数 (KRC) 分别为 -0.59 和 0.07。对于 WADI,PCC 和 KRC 分别为 0.41 和 0.43。然而,这些数字不足以保证相关性的存在,也不足以确认仅使用 F1PA 比较方法的优越性可能存在对检测性能评估不当的风险。
4.3.4 比较结果
在这里,将 AD 方法的结果与例证 1-3 进行比较。
- 对于例证 1 和 2,异常分数是直接生成的,没有模型推理。
- 对于例证 3,采用了最简单的带有 LSTM 层的编码器-解码器架构。
例证 2 和 3 的窗口大小 τ 设置为 120。对于包含随机性的实验,例如例证 1 和 3,使用 5 个不同的种子重复实验并报告平均值。对于现有方法,使用初始论文中报告的最佳数字并正式复制结果;如果没有可用的分数,会参考官方提供的代码进行复制。请注意,没有应用任何预处理,例如早期时间步骤删除或下采样。之前的论文中没有提供MSL、SMAP、SMD的F1;因此它们都被复制了。值得注意的是,在论文建议的范围内搜索最佳超参数,并且没有应用下采样。所有阈值均来自那些产生最佳分数的阈值。附录中提供了实施的更多细节。结果如下表所示。再现结果标记为 †。粗体和下划线数字分别表示最好和第二好的结果。
向上箭头 (↑) 显示以下情况的结果:
(1) F1PA 高于情况 1
(2) F1 高于例证 2 或 3(以较大者为准)
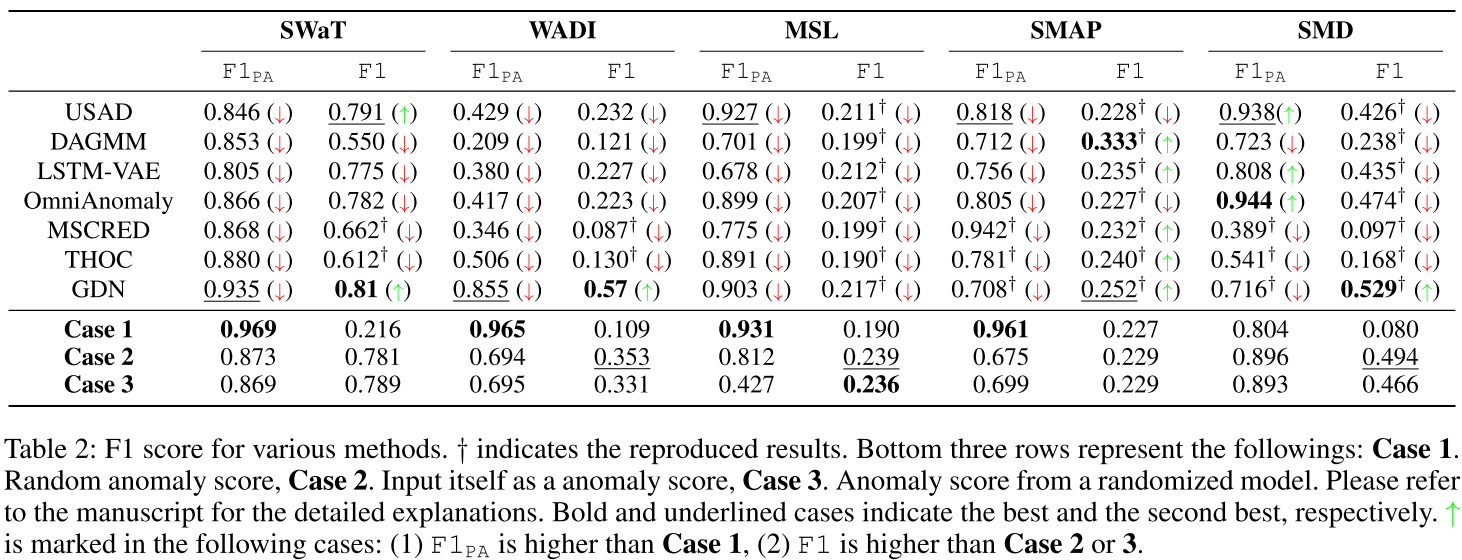
例证1,即随机生成异常分数,该方法显然无法检测异常,因为没有反应输入中的异常情况。
当应用PA协议时,例证1产生了最高的F1PA,远远超出SMD之外的现有方法。
SMD案例1的F1低于其他数据集的F1,并且已有方法超越它。这可能归因于 SMD 测试数据集的组成。
从而得出结论,PA 的高估效应取决于测试数据集的分布,并且异常段越短,其效应就越不明显。
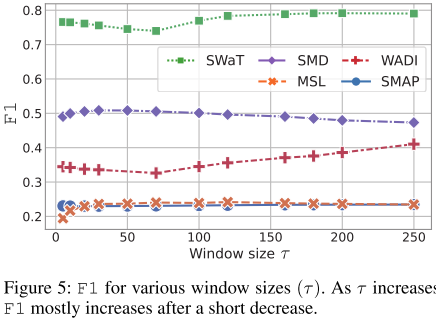
在所有数据集中,现有方法的 F1 大多不如例证 2 和情况 3,这意味着当前提出的方法相对于基线可能取得了边际甚至没有进步。只有 GDN 始终超过所有数据集的基线。例证2和3的F1取决于输入窗口的长度。随着窗口更长,F1 基线变得更大。在例证 2 中尝试了从 1 到 250 的各种窗口长度,并在上图中描述了结果。对于 SWaT、WADI 和 SMAP,随着 τ 的增加,F1 在短暂减少后开始增加。发生这种增加的原因是较长的窗口更有可能包含更多的异常点,从而导致窗口的异常得分较高。如果 τ 变得太大,F1 就会饱和或降级,这可能是因为过去只包含正常信号的窗口意外地包含了异常信号。
4.3.5 PA%K 方案的效果
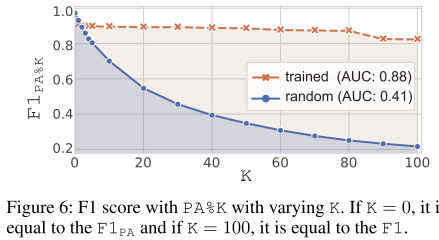
为了检查 PA%K 如何减轻 PA 的高估效应和 F1 的低估趋势,可以观察到 F1PA%K 随不同 PA%K 阈值 K 的变化而变化。下图显示了案例 1 中 SWaT 的 F1PA%K 和经过充分训练的编码器 -当K从0到100以10为增量变化时,解码器中的F1PA%K值K = 0和K = 100分别等于原始F1PA和F1。无论 K 的值如何,训练有素的模型的 F1PA%K 预计都会显示恒定的结果。相应地,训练有素的编码器-解码器(橙色)的 F1PA%K 显示出一致的高 F1PA%K。相反,当 K 增加时,例证 1(蓝色)的 F1PA%K 迅速下降。我们还建议测量曲线下面积 (AUC),以减少对 K 的依赖性。在这种情况下,经过训练的编码器-解码器和例证 1 的 AUC 分别为 0.88 和 0.41;这表明 PA%K 可以清楚地区分前者和后者,无论 K 是多少。
4.4 结论
该文首次证明应用 PA 会严重高估 TAD 模型的能力,这可能无法反映真实的建模性能。该文还提出了 TAD 的新基线,并表明只有少数方法在这方面取得了重大进展。为了减轻对 PA 的高估,提出了一种新的 PA%K 协议,该协议可以应用于现有指标。最后,提出了对 TAD 方法进行严格评估的几个方向,包括基线选择。
小结
本周主要了解了时序噪声的种类以及各种噪声的定义,从而在此基础上阅读论文。论文主要围绕PA协议的有效性展开,其指出PA协议可能高估模型的有效性,且通过展示经PA协议处理的纯噪声的F1分数要优于大部分时序噪声检测模型。最后该文该出了新的基线模型以及评估方法。
参考文献
[1] Siwon Kim, Kukjin Choi, Hyun-Soo Choi, Byunghan Lee, Sungroh Yoonhttps://arxiv.org/search/cs?searchtype=author&query=Wang,+C): Towards a Rigorous Evaluation of Time-series Anomaly Detection.[J].arXiv:2109.05257v2

























![[机器学习]练习汉明距离](https://img-blog.csdnimg.cn/direct/fc6a8608bb694ea8933c8005e3e4e44f.png)