继续趟一条小路,可谓是充满了曲折,当然,必不可少的还是坑。
吐槽
看过的喷友,其实你看完以后,大概率也就是和我一起骂骂街,因为....我也的确没理清楚。
我也不知道做错了什么,就是运行不过去。然后。。。 也不知道做对了什么,看起来好像前进了一点点,但就是没有到达美丽的彼岸。握草
部署环境的时候,似乎是有点坑的。一方面是版本兼容问题。另外我今天还遇到了几个没看懂的坑,感觉就像九九八十一难之后又来到了天坑悬崖边。
环境
安装torch等等就不多说了,任意搜都可以。然后一测试,通了,OK
import torch
x = torch.rand(5,3)
print(x)
torch.cuda.is_available()测试
我是做了一个实体识别的测试。
# 测试推理和统计正确率
all_acc, all_recall = 0, 0
startRow = 0
read_row = 100
for i in range(startRow, len(txtLines)):
if i > startRow + read_row:
break
txt = txtLines[i]
print(i)
json_item = json.loads(txt)
labels = json_item['label']
t_dict = {}
for k in labels:
t_label_dict = labels[k]
t_dict[data[k]] = list(t_label_dict.keys())
ret = predict(json_item['text'], showMsg = False) # 就是运行聊天,得到聊天结果
#print("json_item['text'] = ", json_item['text'])
print('label: ', t_dict)
try:
ret_dict = json.loads(ret)
tKeys = list(ret_dict.keys())
for k in tKeys:
if ret_dict[k] in [ '未提供', '未知' , '无', '' ]:
ret_dict.pop(k)
print('识别结果', ret_dict)
acc, recall = evaluate(t_dict, ret_dict) # 就是我自己写了个简单的统计正确率和召回率
all_acc += acc
all_recall += recall
print('acc= %.2f, recall=%.2f, all_acc=%.2f, all_recall=%.2f'%(acc, recall, all_acc/(i-startRow+1), all_recall/(i-startRow+1)))
except Exception as e:
print(e)
和预想的其实不一样。因为虽然是大模型,但是他未必会给我返回我想要的实体类型。这一点就比较头大,需要自己处理。
比如 比较理想的情况下是这样,识别结果的类型都是我想要的。
label: {'组织机构': ['老挝家具协会'], '人名': ['育亭·维沙蓬'], '职位': ['会长']}
识别结果 {'地名': '老挝', '公司': '老挝家具协会', '人名': '育亭·维沙蓬', '职位': '会长'}
但是很多时候是下面这样:
label: {"人名":["吴湖帆", "吴待秋", "吴子深", "冯超然"]}
识别结果: {"name":["吴湖帆", "吴待秋", "吴子深", "冯超然"]}
或者是其他我不需要的类型名称,中英文也很随意。即使我在prompt里写上,“用中文”,效果仍然不能十分满意。
或许这也是微调的意义?
实体识别的具体内容可以参考这位网友的博客,计算机博士微调BaiChuan13B来做命名实体识别_baichuan max_new_tokens-CSDN博客
或者github (九零后,真年轻啊):torchkeras/examples/BaiChuan13B_NER——transformers.ipynb at master · lyhue1991/torchkeras · GitHub
但是到了后面,我的运行出错了。
求救
艰难的调试过后,运行到这个地方还是可以的,看起来得到了结果。实际上崩溃才刚开始
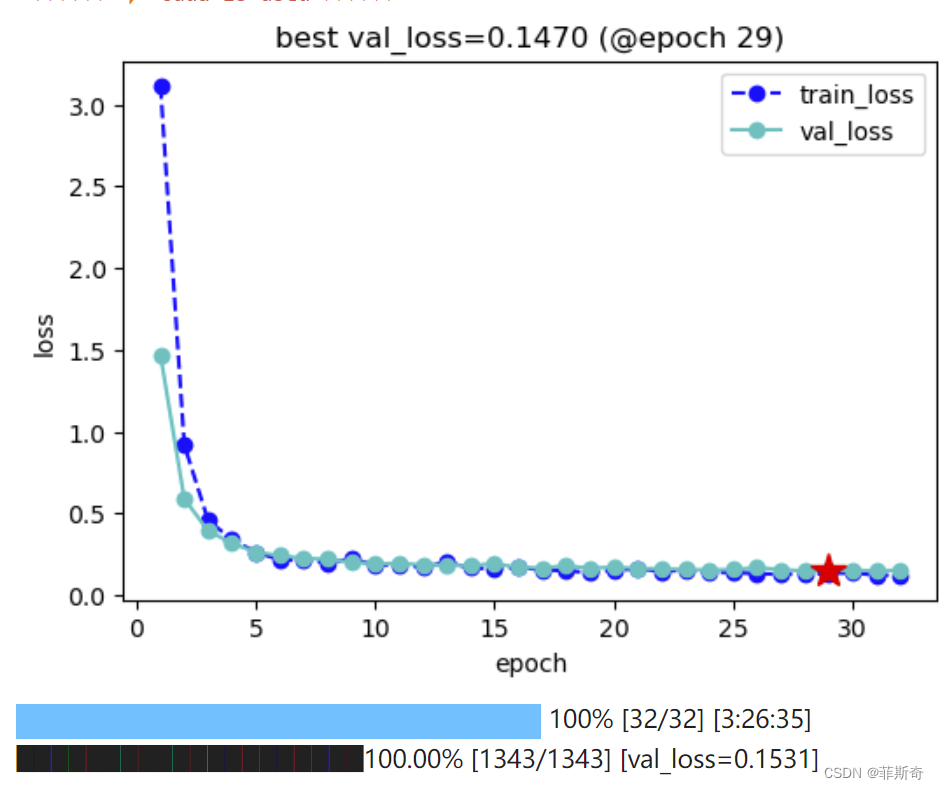
接下来的错误。。。我没搞明白
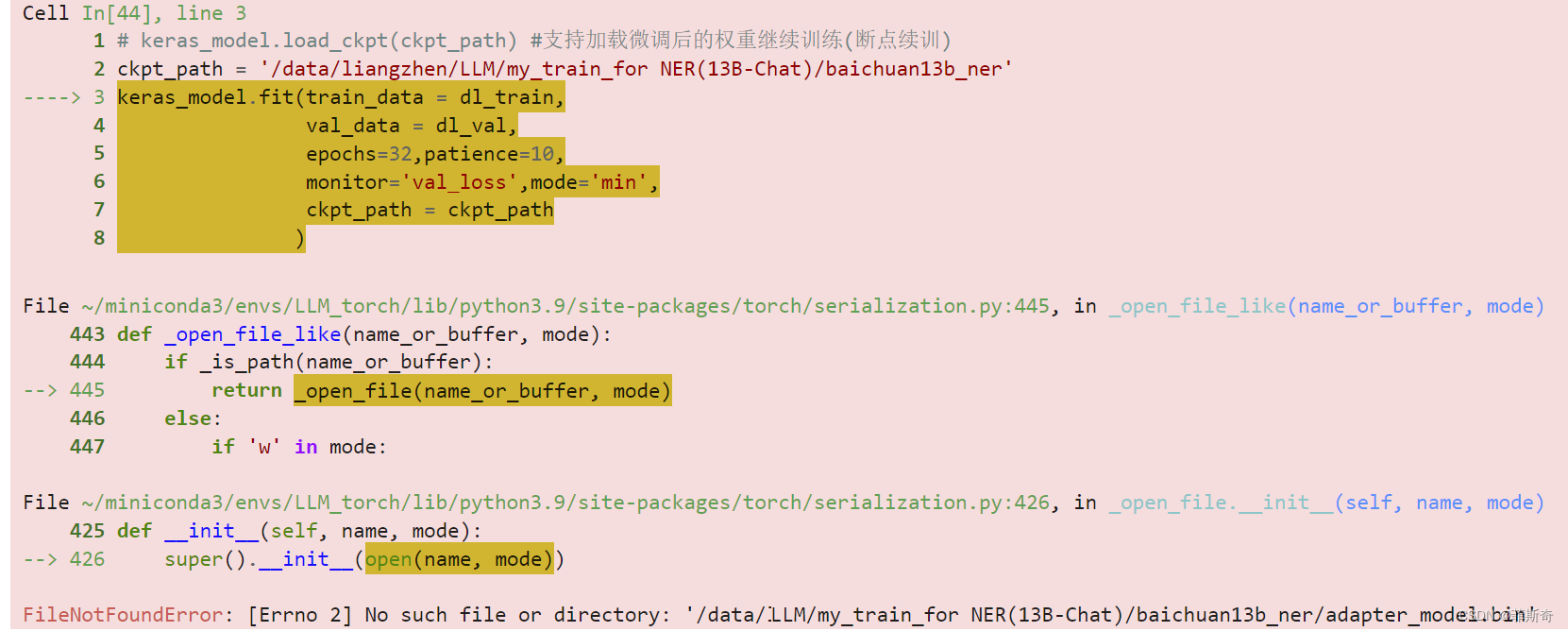
反正就这么错了,提示没有这个文件。关键是,我并没有搞明白从哪里生成这个文件
然后我还想要复现一下,重新训练一次,然后又错了。在Jupyter里,就重新执行了刚才的代码,结果刚刚执行了一次的代码,报错了
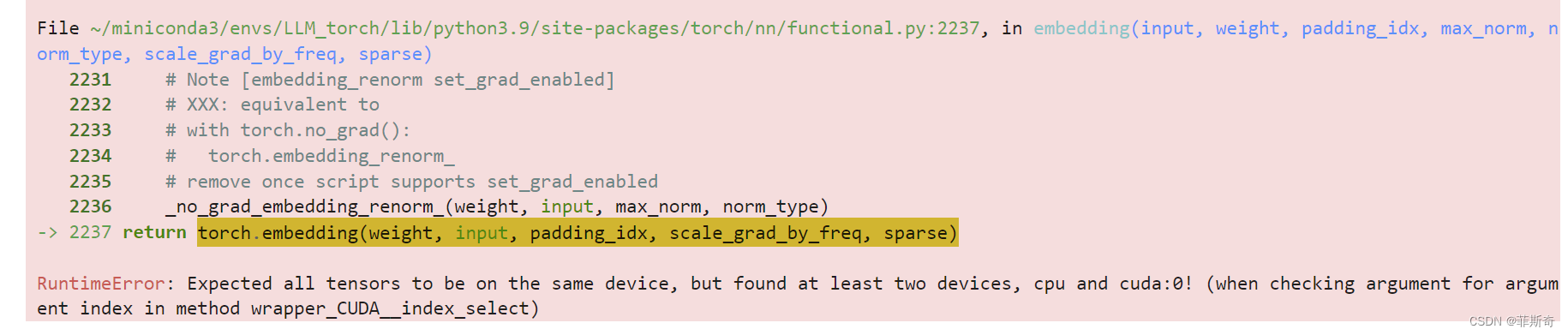
也就是说,数据、模型似乎转移了位置。
然后我回到上面,开始重新生成数据集、重新加载模型,发现仍然是这个错误。包括最开始的测试代码也已经不能运行了,都提示这个错误。
只能关闭重新开始,才能行。
然后往下我就不会了。。。。。
【不是每个博文都会有好结果的,看到这里,你是不是也感觉坑 ^_^】

























![[机器学习]练习汉明距离](https://img-blog.csdnimg.cn/direct/fc6a8608bb694ea8933c8005e3e4e44f.png)