一、 LLMs微调
微调(Fine-tuning)是指在一个已经训练好的神经网络模型基础上,使用额外的数据集或调整超参数,以实现特定任务的训练过程。在微调中,通常会固定预训练模型的大部分参数,只调整最后几层或特定层的参数,以适应新的任务或数据。这种方法通常可以加快模型的收敛速度,提高模型在特定任务上的表现。
(1)Adapter Tuning
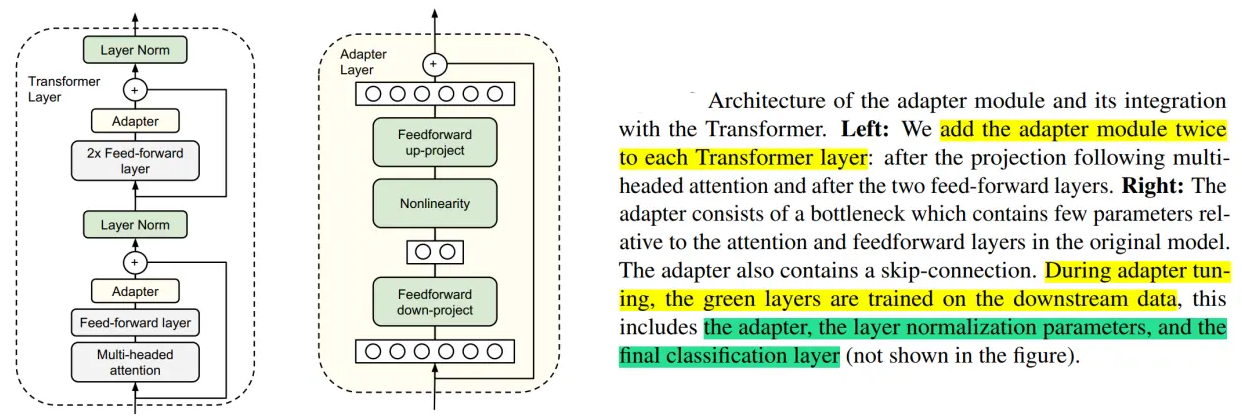
Adapter Tuning是一种在预训练模型上进行微调的方法,它通过添加轻量级的适配器模块来保留预训练模型的大部分参数,同时只微调适配器模块的参数。适配器模块通常是一个小的神经网络层,用于在不破坏预训练模型的情况下对其进行调整以适应特定任务。这种方法相对于直接微调整个预训练模型来说更加高效,因为适配器模块的参数数量很少,所以可以在保留预训练模型参数的同时快速适应新任务。Adapter Tuning可以帮助节省计算资源,加快训练速度,并且在一些任务上取得了很好的效果。

模型结构如上图左侧所示, 微调时冻结预训练模型的主体,由Adapter模块学习特定下游任务的知识。其中,Adapter模块结构如上图右侧所示,包含两个前馈层和一个中间层,第一个前馈层和中间层起到一个降维的作用,后一个前馈层和中间层起到升维的作用。
Adapter调优的参数量大约为LM参数的3.6%。
(2) Prefix Tuning
Prefix Tuning是一种用于微调通用预训练语言模型以适应特定任务的技术。在传统的微调方法中,我们会直接将任务文本作为输入传递给预训练模型,并通过调整整个模型的参数来适应任务。然而,Prefix Tuning采用一种不同的方法,它在输入序列的前面添加一个特定的前缀,以引导模型生成特定的输出。
具体来说,当使用Prefix Tuning时,首先需要设计一个适当的前缀,这个前缀通常包含与任务相关的信息,比如问题描述、指令等。然后,在输入序列前面添加这个前缀,形成一个带有任务相关信息的完整输入序列。接着,将这个带有前缀的序列输入给预训练模型进行生成,模型会在生成时考虑到前缀中的任务提示信息,从而生成与任务相关的输出。
在训练过程中,Prefix Tuning通过最小化任务目标序列与生成序列之间的距离来调整模型的参数,使得模型可以更好地适应特定任务。这种方法可以提高模型在特定任务上的性能,同时避免了重新训练整个模型的需求,从而节省了大量的计算资源和时间。
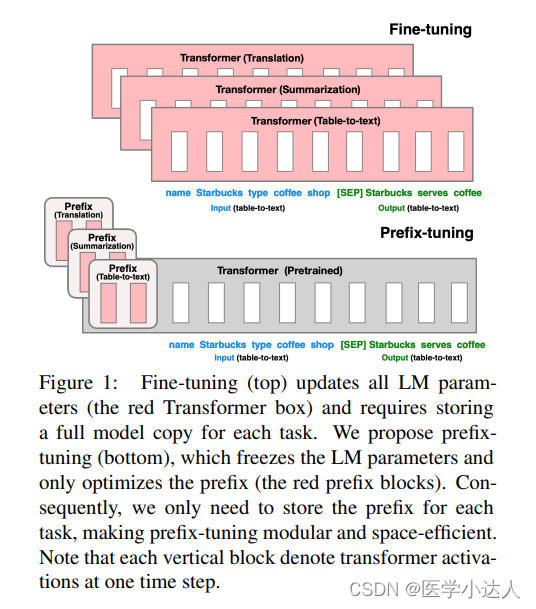
实验结果表明:
(1)在完整的数据集上,Prefix-Tunning和Fine-Tuning在table-to-text上的结果是comparable的,而在summarization任务上,prefix-tuning的效果略有下降。但在low-data settings和unseen topics的情况下,Prefix-Tuning的效果更佳。
(2)与Adapter-Tuning相比,Trefix-Tuning在相同的表现下只需调节更少的参数量。
(3)不同的前缀长度有不一样的性能表现,在一定程度上长度越长,prefix的效果越明显,但也可能出现降低的问题。实验表明,prefix长度对推理速度影响不大,因为prefix上的attention是并行计算的。
Prefix Tuning参数规模约为LM模型整体规模的0.1%。
(3)Prompt Tuning
Prompt Tuning(提示微调)是一种用于微调预训练语言模型的技术,它专注于通过设计和修改提示文本来改善模型在特定任务上的性能。在传统的微调方法中,我们直接将任务文本作为输入传递给预训练模型,并通过调整模型的参数来适应任务。但是,Prompt Tuning采用了一种不同的策略:通过精心设计的提示文本来设置任务的起始点,以引导模型生成更准确和相关的输出。
Prompt Tuning的关键思想是在输入序列的开头添加一个提示文本。这个提示文本可以包含问题描述、类别信息、指令或任何对任务有帮助的文本片段。这个提示文本的设计需要充分考虑任务特定的上下文和领域知识,以引导模型产生合适的回答或输出。
在训练过程中,Prompt Tuning使用了自监督学习的方法。首先,通过生成模型的预测输出,可以根据提示文本和一些部分观察到的目标答案来操作和生成伪造的监督信号。然后,通过最大化这些伪造信号的似然性,微调模型的参数。这个过程可以在大规模的未标注数据上进行,而不需要人工标注的成本。通过Prompt Tuning,可以在不重新训练整个模型的情况下,通过微调提示文本来提高模型的性能和适应特定任务。这种方法在多种自然语言处理任务中取得了显著的成功,包括问答系统、摘要生成、文本分类等。

- Prompt 长度影响:模型参数达到一定量级时,Prompt 长度为1也能达到不错的效果,Prompt 长度为20就能达到极好效果。
- Prompt初始化方式影响:Random Uniform 方式明显弱于其他两种,但是当模型参数达到一定量级,这种差异也不复存在。
- 预训练的方式:LM Adaptation 的方式效果好,但是当模型达到一定规模,差异又几乎没有了。
- 微调步数影响:模型参数较小时,步数越多,效果越好。同样随着模型参数达到一定规模,zero shot 也能取得不错效果。
- 当参数达到100亿规模与全参数微调方式效果无异。
(4)P-Tuning -v1
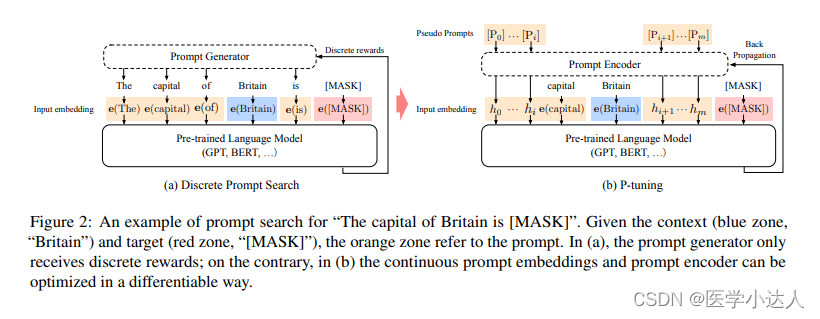
P-Tuning 提出将 Prompt 转换为可以学习的 Embedding 层,只是考虑到直接对 Embedding 参数进行优化会存在这样两个挑战:
- Discretenes: 对输入正常语料的 Embedding 层已经经过预训练,而如果直接对输入的 prompt embedding进行随机初始化训练,容易陷入局部最优。
- Association:没法捕捉到 prompt embedding 之间的相关关系。
作者在这里提出用 MLP + LSTM 的方式来对 prompt embedding 进行一层处理:
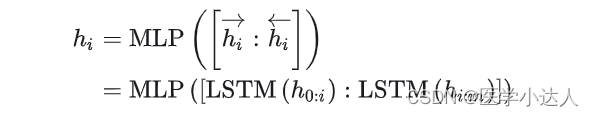
P-tuning 依然是固定 LLM 参数,利用多层感知机和 LSTM 对 Prompt 进行编码,编码之后与其他向量进行拼接之后正常输入 LLM。注意,训练之后只保留 Prompt 编码之后的向量即可,无需保留编码器。
(5) P-Tuning v2
P-Tuning v2是Prompt-Tuning的改进版本,是一种用于微调预训练语言模型的方法。该方法由OpenAI提出,旨在提高模型在特定任务上的性能。
P-Tuning v2的核心创新是引入了一个自适应的Prompt Encoder,通过对输入样本进行编码,并生成动态提示,从而使模型能够根据不同任务的需求自动调整提示语。这种自适应的方法消除了人工设计和微调提示文本的需要,提高了模型在各种任务中的适应性和性能。相比 Prompt Tuning 和 P-tuning 的方法, P-tuning v2 方法在多层加入了 Prompts tokens 作为输入,带来两个方面的好处:带来更多可学习的参数(从 P-tuning 和 Prompt Tuning 的0.1%增加到0.1%-3%),同时也足够 parameter-efficient;加入到更深层结构中的 Prompt 能给模型预测带来更直接的影响。
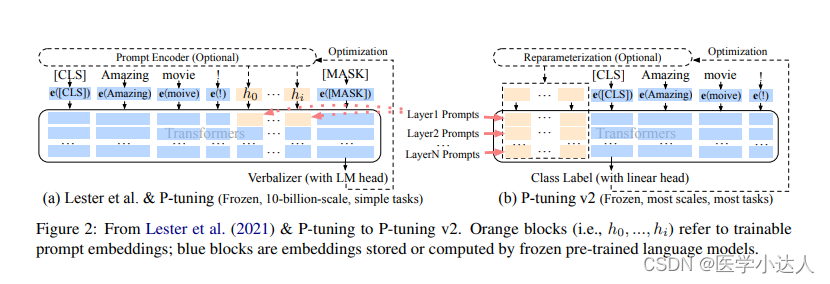
具体而言,P-Tuning v2包含以下关键步骤:
自适应Prompt生成:模型通过Prompt Encoder对输入样本进行编码,结合任务信息生成动态的提示。这样,模型能够根据不同的输入样本自动调整提示,提高了模型的灵活性和泛化能力。
微调:生成的动态提示被输入到模型中,模型在训练过程中根据提示指导进行微调,以适应特定任务的要求。这有助于提高模型在该任务上的性能表现。
高效性:相较于传统的Prompt-Tuning方法,P-Tuning v2减少了对提示文本的手动设计工作,提高了效率。模型能够更快地适应不同任务,并表现出更好的性能。
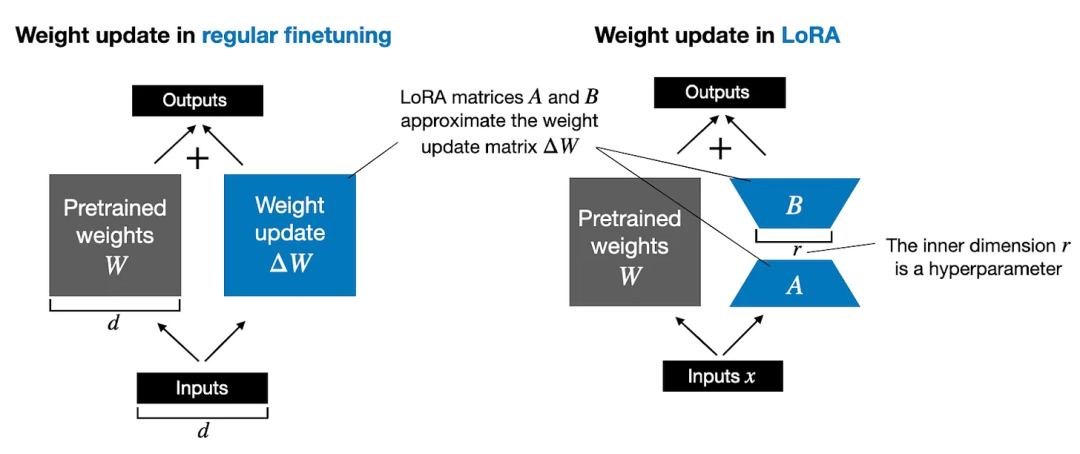
(6) LoRA(Low-Rank Adaptation)

LoRA(Low-Rank Adaptation)是一种用于模型微调的技术,旨在通过将低秩矩阵附加到预训练模型的嵌入矩阵中,来提高模型在特定任务上的性能。这种方法主要用于在大规模语言模型(如BERT、GPT等)上进行微调,以适应特定任务的需求。
在LoRA微调中,预训练的模型架构保持不变,但会添加一个额外的低秩矩阵参数层用于微调。这个低秩矩阵通常是一个小型的矩阵,其目的是在不增加过多参数的情况下,提供更多与微调任务相关的信息。通过在微调过程中同时训练嵌入矩阵和低秩矩阵,LoRA能够更好地适应特定任务的特征。
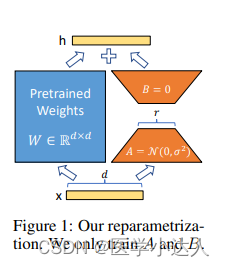
LoRA微调的优势在于可以在保持预训练模型参数不变的情况下,针对特定任务进行快速有效的微调。这种方法可以提高模型的性能并加速微调过程,尤其适用于任务数据集相对较小的情况下。
(7) 其他方法:AdaLoRA
AdaLoRA(Adaptive Low-Rank Adaptation)是LoRA(Low-Rank Adaptation)的一个改进版本,旨在进一步优化模型微调过程,以更好地适应特定任务。在AdaLoRA中,与传统的LoRA不同,它引入了自适应机制来动态地调整低秩矩阵的大小和结构,以使模型在微调过程中更加灵活和高效。这种自适应机制可以根据微调任务的需求,自动确定最佳的低秩矩阵参数,以更好地解决特定任务的挑战。具体来说,AdaLoRA通过引入自适应的稀疏正交约束来调整低秩矩阵的结构,以提高模型的泛化能力和表达能力。这种方法能够在微调过程中更好地平衡模型的复杂性和性能,从而更好地适应不同的任务需求
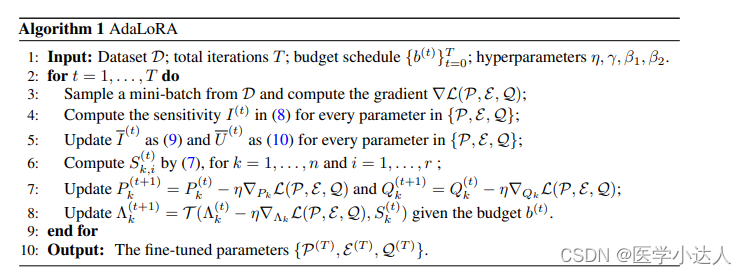
具体做法如下:调整增量矩分配。AdaLoRA将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。以奇异值分解的形式对增量更新进行参数化,并根据重要性指标裁剪掉不重要的奇异值,同时保留奇异向量。由于对一个大矩阵进行精确SVD分解的计算消耗非常大,这种方法通过减少它们的参数预算来加速计算,同时,保留未来恢复的可能性并稳定训练。
二、LLMs微调实践(chatglm3为例)
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
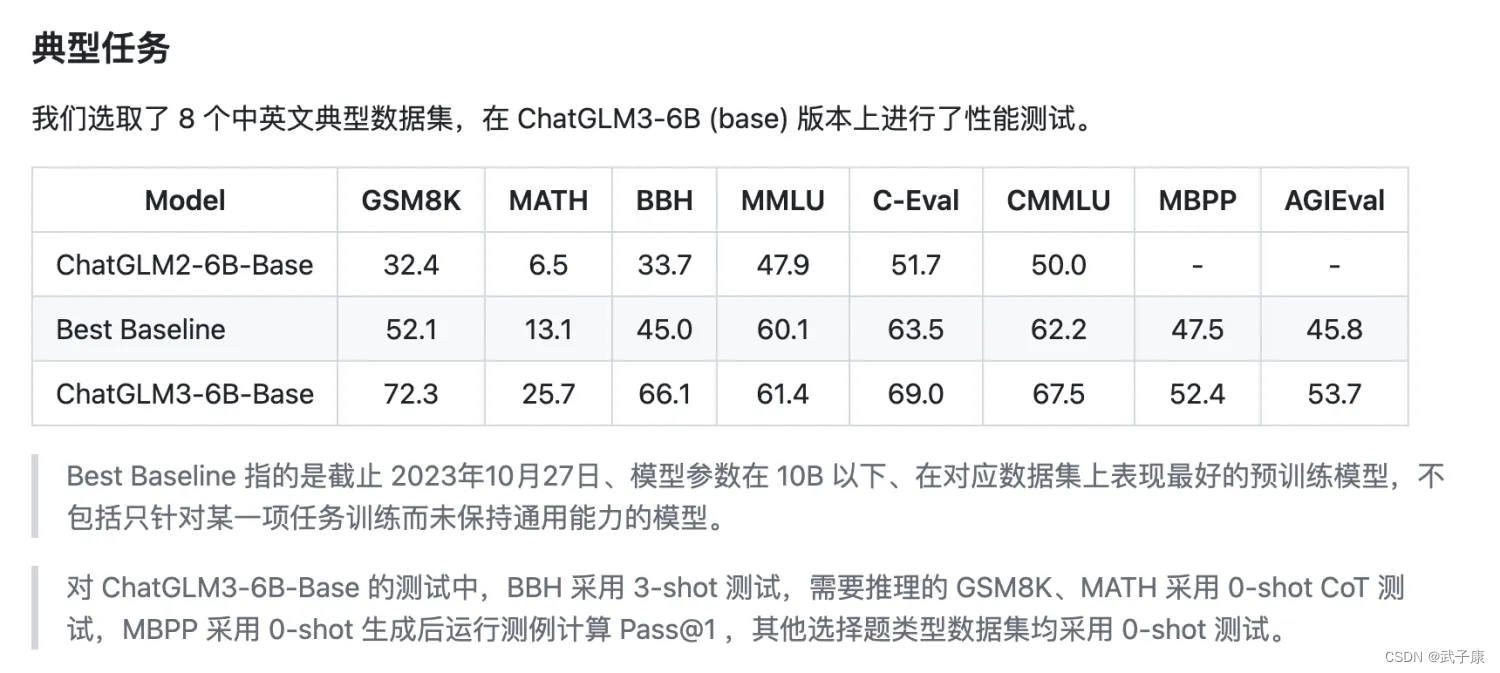
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。

环境安装
首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3然后使用 pip 安装依赖:
pip install -r requirements.txt
transformers库版本应该4.30.2以及以上的版本 ,torch库版本应为 2.0 及以上的版本,以获得最佳的推理性能。- 为了保证
torch的版本正确,请严格按照 官方文档 的说明安装。 gradio库版本应该为3.x的版本。
注意哦:
transformers版本如果较低,很可能出现模型的参数加载不全(甚至不支持模型),如果参数加载不全虽然不影响推理,但是很影响推理效果哦
本目录提供 ChatGLM3-6B 模型的微调示例,包括全量微调和 P-Tuning v2。格式上,提供多轮对话微调样例和输入输出格式微调样例。
如果将模型下载到了本地,本文和代码中的 THUDM/chatglm3-6b 字段均应替换为相应地址以从本地加载模型。
运行示例需要 python>=3.9,除基础的 torch 依赖外,示例代码运行还需要依赖
pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed多轮对话格式
多轮对话微调示例采用 ChatGLM3 对话格式约定,对不同角色添加不同 loss_mask 从而在一遍计算中为多轮回复计算 loss。
数据格式和预处理
对于数据文件,样例采用如下格式
如果您仅希望微调模型的对话能力,而非工具能力,您应该按照以下格式整理数据。
[
{
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]请注意,这种方法在微调的step较多的情况下会影响到模型的工具调用功能
如果您希望微调模型的对话和工具能力,您应该按照以下格式整理数据。
[
{
"tools": [
// available tools, format is not restricted
],
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant thought to text>"
},
{
"role": "tool",
"name": "<name of the tool to be called",
"parameters": {
"<parameter_name>": "<parameter_value>"
},
"observation": "<observation>"
// don't have to be string
},
{
"role": "assistant",
"content": "<assistant response to observation>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]关于工具描述的 system prompt 无需手动插入,预处理时会将
tools字段使用json.dumps(..., ensure_ascii=False)格式化后插入为首条 system prompt。每种角色可以附带一个
bool类型的loss字段,表示该字段所预测的内容是否参与loss计算。若没有该字段,样例实现中默认对system,user不计算loss,其余角色则计算loss。tool并不是 ChatGLM3 中的原生角色,这里的tool在预处理阶段将被自动转化为一个具有工具调用metadata的assistant角色(默认计算loss)和一个表示工具返回值的observation角色(不计算loss)。目前暂未实现
Code interpreter的微调任务。system角色为可选角色,但若存在system角色,其必须出现在user角色之前,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次system角色。
作为示例,我们使用 ToolAlpaca 数据集来进行微调。首先,克隆 ToolAlpaca 数据集,并使用
./scripts/format_tool_alpaca.py --path "ToolAlpaca/data/train_data.json"将数据集处理成上述格式。在这里,我们有意将工具处理成了了 list[str] 这样的自然语言形式,以观察模型在微调前后对工具定义的理解能力。
微调模型
以下脚本提供了微调模型的参考方式。
./scripts/finetune_ds_multiturn.sh # 全量微调
./scripts/finetune_pt_multiturn.sh # P-Tuning v2 微调部署
我们更新了 ChatGLM3 的综合 Demo,使其可以部署微调后的模型 checkpoint。
对于全量微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="path to finetuned model checkpoint" TOKENIZER_PATH="THUDM/chatglm3-6b" streamlit run main.py对于 P-Tuning v2 微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="THUDM/chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py输入输出格式
对于输入-输出格式,样例采用如下输入格式
[
{
"prompt": "<prompt text>",
"response": "<response text>"
}
// ...
]
预处理时,不会拼接任何角色标识符。作为示例,我们使用 AdvertiseGen 数据集来进行微调。从 Google Drive 或者 Tsinghua Cloud 下载处理好的 AdvertiseGen 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"来下载和将数据集处理成上述格式。
微调模型
以下脚本提供了微调模型的参考方式。
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调推理验证
对于输入输出格式的微调,可使用 inference.py 进行基本的推理验证。
python inference.py \
--pt-checkpoint "path to p-tuning checkpoint" \
--model THUDM/chatglm3-6b python inference.py \
--tokenizer THUDM/chatglm3-6b \
--model "path to finetuned model checkpoint" 提示
微调代码在开始训练前,会先打印首条训练数据的预处理信息,显示为如下:
Sanity Check >>>>>>>>>>>>>
'[gMASK]': 64790 -> -100
'sop': 64792 -> -100
'<|system|>': 64794 -> -100
'': 30910 -> -100
'\n': 13 -> -100
'Answer': 20115 -> -100
'the': 267 -> -100
'following': 1762 -> -100
...
'know': 683 -> -100
'the': 267 -> -100
'response': 3010 -> -100
'details': 3296 -> -100
'.': 30930 -> -100
'<|assistant|>': 64796 -> -100
'': 30910 -> 30910
'\n': 13 -> 13
'I': 307 -> 307
'need': 720 -> 720
'to': 289 -> 289
'use': 792 -> 792
...
<<<<<<<<<<<<< Sanity Check字样,每行依次表示一个 detokenized string, token_id 和 target_id。可在日志中查看这部分的 loss_mask 是否符合预期。若不符合,可能需要调整代码或数据。
参考显存用量:

参数解释:
PRE_SEQ_LEN=128 ---这是一个环境变量,代表序列的预设长度为128
LR=2e-2 ---代表学习率为0.02
NUM_GPUS=1 ---使用GPU的数量,为1
MAX_SOURCE_LEN=1024 ---输入序列的最大长度
MAX_TARGET_LEN=128 ---目标序列的最大长度
DEV_BATCH_SIZE=1 ---每个batch样本数量
GRAD_ACCUMULARION_STEPS=32 ---在进行一次参数更新之前,要进行的梯度累积步骤的数量
MAX_STEP=1000 ---训练步数的最大数量,一个batch一次
SAVE_INTERVAL=500 ---保存模型检查点的步数间隔
假设2000条数据
epoch计算:数据划分为batch:2000 /(DEV_BATCH_SIZE * GRAD_ACCUMULARION_STEPS * NUM_GPUS) = 62.5
epoch = 1000/62.5 = 16
所以epoch为16
基础模型推理代码:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
###你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
###微调模型代码:finetune.py
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for sequence to sequence.
"""
# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
# Adapted from
import logging
import os
import sys
import torch
import json
import transformers
from transformers import (
AutoConfig,
AutoModel,
AutoTokenizer,
DataCollatorForSeq2Seq,
HfArgumentParser,
Seq2SeqTrainingArguments,
set_seed,
)
from trainer import PrefixTrainer
from arguments import ModelArguments, DataTrainingArguments
from preprocess_utils import sanity_check, MultiTurnDataset, InputOutputDataset
logger = logging.getLogger(__name__)
def main():
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Load pretrained model and tokenizer
config = AutoConfig.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
config.pre_seq_len = model_args.pre_seq_len
config.prefix_projection = model_args.prefix_projection
tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, trust_remote_code=True)
if model_args.ptuning_checkpoint is not None:
model = AutoModel.from_pretrained(model_args.model_name_or_path, config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(model_args.ptuning_checkpoint, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
else:
model = AutoModel.from_pretrained(model_args.model_name_or_path, config=config, trust_remote_code=True)
if model_args.quantization_bit is not None:
print(f"Quantized to {model_args.quantization_bit} bit")
model = model.quantize(model_args.quantization_bit)
if model_args.pre_seq_len is not None:
# P-tuning v2
model = model.half()
model.transformer.prefix_encoder.float()
else:
# Finetune
model = model.float()
with open(data_args.train_file, "r", encoding="utf-8") as f:
if data_args.train_file.endswith(".json"):
train_data = json.load(f)
elif data_args.train_file.endswith(".jsonl"):
train_data = [json.loads(line) for line in f]
if data_args.train_format == "multi-turn":
train_dataset = MultiTurnDataset(
train_data,
tokenizer,
data_args.max_seq_length,
)
elif data_args.train_format == "input-output":
train_dataset = InputOutputDataset(
train_data,
tokenizer,
data_args.max_source_length,
data_args.max_target_length,
)
else:
raise ValueError(f"Unknown train format: {data_args.train_format}")
if training_args.local_rank < 1:
sanity_check(train_dataset[0]['input_ids'], train_dataset[0]['labels'], tokenizer)
# Data collator
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=-100,
pad_to_multiple_of=None,
padding=False
)
# Initialize our Trainer
trainer = PrefixTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
save_changed=model_args.pre_seq_len is not None
)
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
trainer.save_state()
if __name__ == "__main__":
main()微调模型推理代码:inference.py
import argparse
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
import os
parser = argparse.ArgumentParser()
parser.add_argument("--pt-checkpoint", type=str, default=None, help="The checkpoint path")
parser.add_argument("--model", type=str, default=None, help="main model weights")
parser.add_argument("--tokenizer", type=str, default=None, help="main model weights")
parser.add_argument("--pt-pre-seq-len", type=int, default=128, help="The pre-seq-len used in p-tuning")
parser.add_argument("--device", type=str, default="cuda")
parser.add_argument("--max-new-tokens", type=int, default=128)
args = parser.parse_args()
if args.tokenizer is None:
args.tokenizer = args.model
if args.pt_checkpoint:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer, trust_remote_code=True)
config = AutoConfig.from_pretrained(args.model, trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained(args.model, config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(args.pt_checkpoint, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
else:
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer, trust_remote_code=True)
model = AutoModel.from_pretrained(args.model, trust_remote_code=True)
model = model.to(args.device)
while True:
prompt = input("Prompt:")
inputs = tokenizer(prompt, return_tensors="pt")
inputs = inputs.to(args.device)
response = model.generate(input_ids=inputs["input_ids"], max_length=inputs["input_ids"].shape[-1] + args.max_new_tokens)
response = response[0, inputs["input_ids"].shape[-1]:]
print("Response:", tokenizer.decode(response, skip_special_tokens=True))参考文章:
大模型高效微调综述下: DiffPruning、BitFit、LoRa、AdaLoRA、MAM Adapters、UniPELT-CSDN博客
大模型微调技术(Adapter-Tuning、Prefix-Tuning、Prompt-Tuning(P-Tuning)、P-Tuning v2、LoRA)_nlp_渣渣崔-GitCode 开源社区