引言
在当今数字化时代,数据的爆炸式增长使得人们面临着海量信息的处理和利用问题。在这样的背景下,知识图谱作为一种强大的知识表示和管理工具,正逐渐成为解决复杂问题和构建智能应用的关键技术之一。本文将深入探讨知识图谱的概念、重要性、应用领域以及构建和挑战,旨在为读者提供全面的了解和认识。
简述知识图谱的概念
知识图谱是一种语义网络,以图形结构的形式表示知识之间的关系,其中包括实体、关系和属性。它不仅仅是一个数据存储工具,更是对世界知识的抽象和形式化表达,可以帮助计算机理解和处理人类语言和行为。
知识图谱的重要性和应用领域
知识图谱的重要性在于它能够整合各种异构数据源,并从中提取出有意义的知识。在应用领域上,知识图谱被广泛应用于企业知识管理、智能推荐系统、社交网络分析、医疗健康领域以及智能助手和问答系统等方面。
本文目的和结构概览
本文旨在全面介绍知识图谱的概念、技术要点、应用案例以及构建和面临的挑战。首先,我们将在第一部分简要介绍知识图谱的基本概念和历史演变;接着,第二部分将深入探讨知识图谱的技术要点,包括知识抽取、表示、融合、推理以及更新与维护;第三部分将通过具体的应用案例展示知识图谱在不同领域的应用;最后,第四部分将讨论构建知识图谱的步骤和面临的挑战,以及对未来发展趋势的展望。通过本文的阅读,读者将能够全面了解知识图谱的核心概念、技术原理和实际应用,为构建智能应用提供有力的参考和指导。
第一部分:知识图谱简介
什么是知识图谱
定义和核心概念
知识图谱是一种语义网络,它以图形结构的形式表达了各种实体之间的关系,包括人、地点、事物等,以及这些实体之间的属性。这种表示使得计算机可以更好地理解和处理人类语言和行为,从而为构建智能应用提供了基础。
在知识图谱中,实体代表着现实世界中的事物,关系表示了实体之间的连接,而属性则描述了实体的特征。通过这种方式,知识图谱不仅仅是对数据的简单存储,更是对知识的抽象和形式化表达。
知识图谱与传统数据库的区别
与传统数据库相比,知识图谱具有更丰富的语义信息。传统数据库通常只存储数据,而知识图谱除了存储数据外,还存储了数据之间的语义关系。这使得知识图谱能够更好地支持数据的查询、推理和分析,从而为智能应用的构建提供了更大的灵活性和功能性。
知识图谱的历史
从语义网到知识图谱的演变
知识图谱的概念源于语义网(Semantic Web),这是万维网的一个扩展,旨在使网络中的数据更容易被机器理解和处理。随着语义网的发展,知识图谱逐渐成为了一个独立的概念,并在学术界和工业界得到了广泛的关注和应用。
关键技术的发展里程碑
知识图谱的发展离不开一系列关键技术的进步,包括知识抽取、表示、融合、推理等。其中,RDF(Resource Description Framework)和OWL(Web Ontology Language)标准的制定和推广,推动了知识图谱的发展,成为了知识图谱表示的重要基础。
知识图谱的组成
实体、关系、属性
知识图谱的基本组成包括实体、关系和属性。实体代表了现实世界中的事物,关系表示了实体之间的连接,而属性则描述了实体的特征。这三者共同构成了知识图谱的基本结构,为知识的组织和管理提供了基础。
本体论(Ontologies)
本体论是知识图谱中的重要概念,它定义了一组共享的概念和关系,用于描述特定领域的知识。本体论不仅可以帮助理解和解释知识,还可以为知识的标准化和共享提供支持。
三元组(Triplets)
在知识图谱中,数据以三元组的形式表示,即“主体-谓词-客体”。主体和客体分别表示两个实体,谓词表示它们之间的关系。这种简单而灵活的表示方式使得知识图谱能够轻松地扩展和修改,适应不同的应用场景。
知识图谱的历史
- 从语义网到知识图谱的演变
- 关键技术的发展里程碑
知识图谱的组成
- 实体、关系、属性
- 本体论(Ontologies)
- 三元组(Triplets)
第二部分:知识图谱的技术要点
知识抽取
数据源和抽取方法
知识图谱的建立需要从多种数据源中提取信息。这些数据源可以是结构化的数据库、半结构化的文本数据,甚至是非结构化的网页内容。常用的抽取方法包括基于规则的抽取、基于统计的抽取和基于机器学习的抽取。
实体识别
实体识别是指从文本中识别出代表现实世界中具体实体的词语或短语。这需要利用自然语言处理技术,例如命名实体识别和词性标注,以及基于模式匹配或机器学习的方法。
关系抽取
关系抽取是指从文本中抽取出不同实体之间的关系。这可以通过语言模式匹配、基于规则的方法或者机器学习技术来实现。关系抽取的结果通常表示为三元组形式,用于构建知识图谱的表示。
知识表示
知识表示方法
知识图谱的表示是指将抽取出的知识表示为计算机可以理解和处理的形式。常用的表示方法包括基于图的表示、基于逻辑的表示和基于语义的表示。
图数据库
图数据库是一种专门用于存储和查询图数据的数据库系统。它通过存储实体、关系和属性的方式来表示知识图谱,并提供了高效的图查询和分析功能。
RDF & OWL标准
RDF(Resource Description Framework)和OWL(Web Ontology Language)是知识图谱表示的两种重要标准。RDF用于表示图数据的结构,而OWL用于表示图数据的语义。
知识融合
实体对齐
实体对齐是指将不同数据源中表示同一实体的数据进行匹配和整合。这通常涉及到实体名称的匹配、实体属性的对比和相似性计算等步骤。
知识去重
知识去重是指在知识图谱构建过程中,对重复或冗余的知识进行识别和消除。这可以通过比较实体属性的相似性,或者利用机器学习算法来实现。
质量评估
质量评估是指对知识图谱的完整性、准确性和一致性进行评估和监控。这包括对知识抽取和整合过程的质量进行评估,以及对知识图谱的实际应用效果进行评估。
知识推理
推理机制
推理机制是指利用已有的知识来推导出新的知识的过程。这可以通过逻辑推理、规则推理或者统计推理等方法来实现。
规则引擎
规则引擎是一种用于执行和管理规则的软件系统。在知识图谱中,规则引擎常用于执行与实体和关系相关的逻辑规则,从而推导出新的知识。
机器学习在知识推理中的应用
机器学习技术可以通过对大量已有知识的学习,从而自动发现和推理出新的知识。在知识图谱中,机器学习技术常用于关系预测、实体分类等任务中。
第三部分:知识图谱的应用案例
企业级知识图谱
企业知识管理
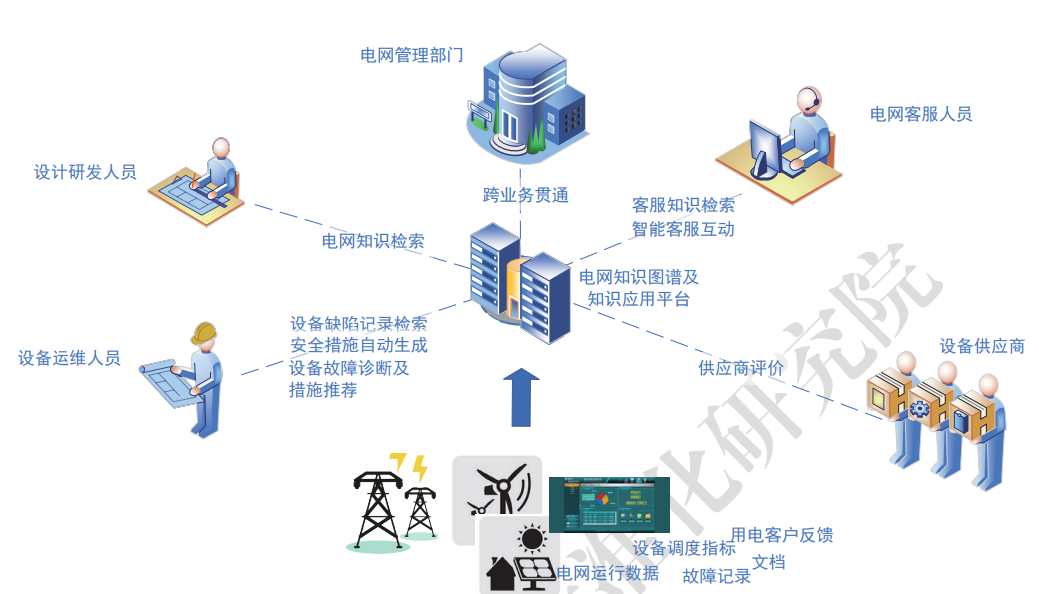
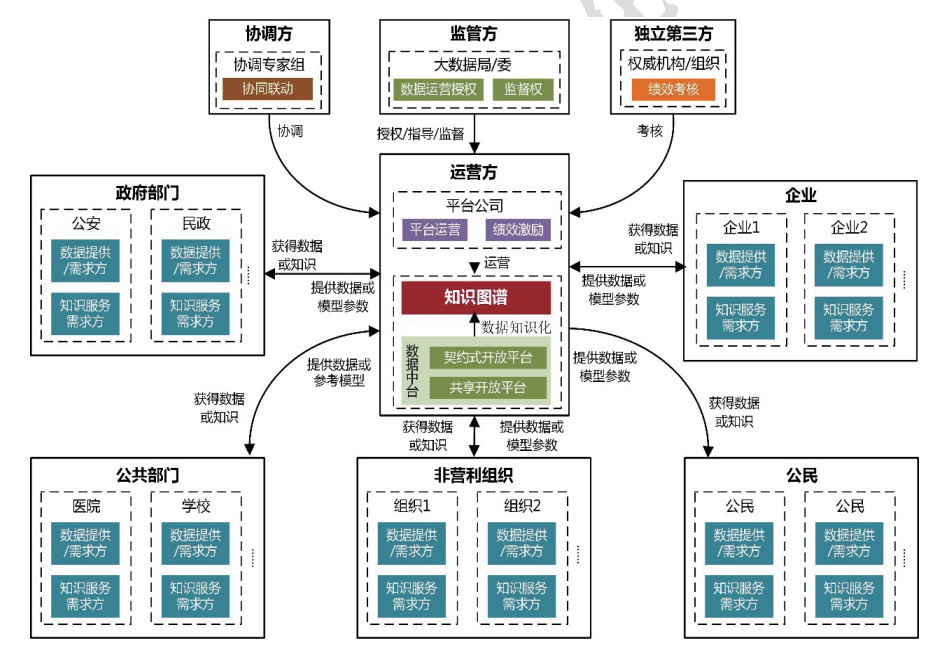
企业内部存在大量的知识资产,包括文档、数据、经验等。通过构建企业级知识图谱,可以将这些知识资产进行整合和管理,实现知识的共享和传承。企业可以利用知识图谱技术建立企业内部的知识库,提高员工的工作效率和决策水平。
智能推荐系统
基于用户的行为和偏好,企业可以利用知识图谱技术构建智能推荐系统,为用户提供个性化的服务和产品推荐。通过分析用户的历史行为和关联关系,系统可以自动学习用户的兴趣和需求,从而提高推荐的准确性和效果。
社交网络知识图谱
社交网络分析
社交网络中存在大量的用户行为数据,包括用户之间的关注关系、互动行为等。通过构建社交网络知识图谱,可以对用户之间的关系网络进行分析和挖掘,发现潜在的社交圈子和影响力节点,为社交网络营销和用户推荐提供依据。
个性化内容分发
基于用户的兴趣和偏好,社交网络可以利用知识图谱技术实现个性化的内容分发。通过分析用户的行为和关系,系统可以为用户推荐感兴趣的内容和话题,提高用户对平台的粘性和活跃度。
医疗健康知识图谱
疾病诊断支持
医疗健康领域存在大量的医学知识和临床数据,通过构建医疗健康知识图谱,可以帮助医生进行疾病诊断和治疗决策。系统可以从海量的医学文献和临床案例中提取知识,为医生提供诊断支持和治疗建议。
药物发现
基于药物的化学结构和生物活性,医疗健康知识图谱可以帮助研究人员进行药物发现和设计。系统可以分析药物之间的关系和作用机制,预测新的药物候选物,并为药物研发提供指导和支持。
智能助手和问答系统
语音助手
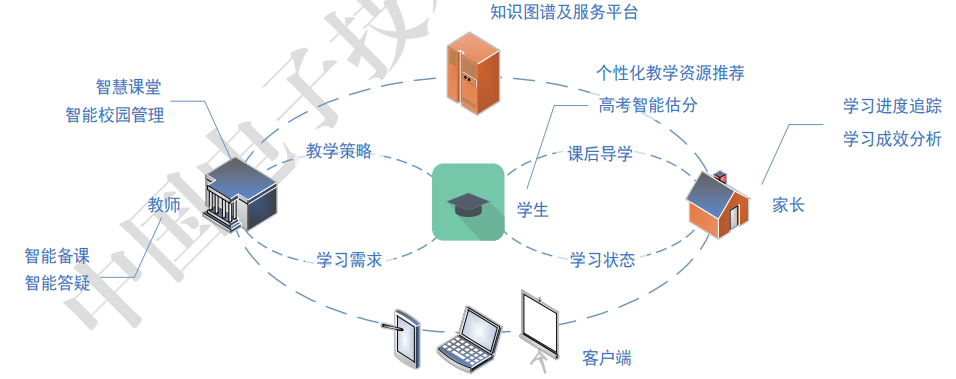
语音助手是一种智能交互系统,可以通过语音命令和语音识别技术实现用户与计算机的交互。通过构建知识图谱,语音助手可以理解用户的意图和需求,为用户提供个性化的服务和回答。
智能问答
基于知识图谱的智能问答系统可以通过分析用户的问题和知识库中的信息,为用户提供准确和及时的答案。系统可以利用知识图谱中的实体和关系,结合自然语言处理技术,实现对复杂问题的理解和回答。
第四部分:知识图谱的构建与挑战
构建知识图谱的步骤
规划和设计
构建知识图谱的第一步是进行规划和设计。在这个阶段,需要明确知识图谱的应用场景和需求,定义实体、关系和属性,确定知识图谱的范围和目标。同时,还需要考虑知识图谱的架构和数据模型,选择合适的技术工具和平台。
数据采集与处理
数据采集是构建知识图谱的关键步骤之一。在这个阶段,需要从各种数据源中收集数据,包括结构化数据、半结构化数据和非结构化数据。然后,对采集到的数据进行清洗、抽取和转换,以便后续的知识表示和存储。
知识整合与存储
知识整合与存储是构建知识图谱的最后一步。在这个阶段,需要将采集到的数据整合成统一的知识图谱模型,并将其存储到合适的数据库中。常用的数据库包括图数据库、关系数据库和文档数据库等。同时,还需要设计和实现知识图谱的查询和检索接口,以支持用户对知识图谱的查询和分析。
面临的挑战
数据质量和一致性
构建知识图谱面临的主要挑战之一是数据质量和一致性问题。由于数据源的多样性和数据质量的不确定性,采集到的数据可能存在错误、缺失和冗余等问题,这会影响到知识图谱的准确性和可信度。因此,需要采用有效的数据清洗和质量评估方法,提高数据的质量和一致性。
可扩展性和性能
随着知识图谱规模的不断增大,系统的可扩展性和性能成为另一个重要的挑战。大规模知识图谱的构建和查询需要处理海量的数据和复杂的查询请求,这对系统的存储和计算能力提出了很高的要求。因此,需要采用分布式存储和计算技术,优化系统架构和算法,提高系统的可扩展性和性能。
安全性和隐私保护
知识图谱中包含大量的敏感信息和个人数据,如企业的商业机密和用户的个人偏好。因此,保护知识图谱的安全性和隐私成为构建过程中的重要问题。需要采用有效的数据加密和访问控制技术,确保知识图谱的安全性和隐私保护,防止未经授权的访问和数据泄露。
结语
知识图谱作为构建智能应用的重要技术基础,在信息时代发挥着越来越重要的作用。通过对知识图谱的全面介绍,我们可以清晰地理解其在不同领域的应用,以及其在推动智能化发展方面的巨大潜力。
总的来说,知识图谱不仅可以帮助企业更好地管理知识资源,提升工作效率,还可以为用户提供个性化、智能化的服务和体验。通过对知识图谱的构建和应用案例的深入探讨,我们可以看到它在企业级知识管理、社交网络分析、医疗健康领域以及智能助手和问答系统等方面的广泛应用。
然而,我们也要清醒地认识到,知识图谱的构建和应用过程中存在着诸多挑战,包括数据质量和一致性、可扩展性和性能、以及安全性和隐私保护等方面。面对这些挑战,我们需要不断地探索和创新,提出更加有效的解决方案,以推动知识图谱技术的进一步发展和应用。
随着人工智能和大数据技术的不断发展,相信知识图谱将会在未来发挥越来越重要的作用,为人类社会的进步和发展做出更大的贡献。让我们共同期待知识图谱技术在未来的发展,为构建智能化、智慧型的世界贡献力量。
参考文献
Bizer, C., Heath, T., & Berners-Lee, T. (2009). Linked data - the story so far. International Journal on Semantic Web and Information Systems (IJSWIS), 5(3), 1-22.
Chen, H., Wang, H., Zeng, D., & Tao, J. (2005). Bridging the semantic gap: A hybrid approach to retrieving semantically relevant scenes. International Journal on Semantic Web and Information Systems (IJSWIS), 1(2), 58-81.
Nickel, M., Murphy, K., Tresp, V., & Gabrilovich, E. (2016). A review of relational machine learning for knowledge graphs. Proceedings of the IEEE, 104(1), 11-33.
Shadbolt, N., Hall, W., & Berners-Lee, T. (2006). The semantic web revisited. IEEE Intelligent Systems, 21(3), 96-101.
Singh, P., & Singh, M. P. (2018). Applications of knowledge graphs: A comprehensive survey. Journal of Information Science, 44(6), 751-780.
Vrandečić, D., & Krötzsch, M. (2014). Wikidata: A free collaborative knowledgebase. Communications of the ACM, 57(10), 78-85.
Zeng, D., Li, Y. F., & Wang, F. Y. (2009). Knowledge representation, reasoning, and declarative problem-solving for cyber-physical systems. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 39(5), 528-546.
Zhou, M., Kusnadi, N., Vavilapalli, V. K., & Murthy, A. C. (2015). Apache Hadoop YARN: Yet another resource negotiator. Proceedings of the VLDB Endowment, 8(12), 1439-1450.
Zhang, S., Deng, H., & Wang, H. (2018). The current development of knowledge graph and its future trends. Journal of Software, 29(1), 208-226.
Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.