AI大模型学习
方向一:AI大模型学习的理论基础
正则化技术在机器学习和深度学习中是避免模型过拟合的关键方法。过拟合发生在模型对训练数据学得太好,以至于它失去了泛化到未见数据上的能力。简而言之,正则化就是在模型训练过程中添加某种形式的约束或惩罚,以防止模型变得过于复杂或“记忆”训练数据。
L1和L2正则化
L1和L2正则化是最常见的正则化形式,它们通过向损失函数添加一个正则项来工作,这个正则项与模型权重的L1范数或L2范数成正比。
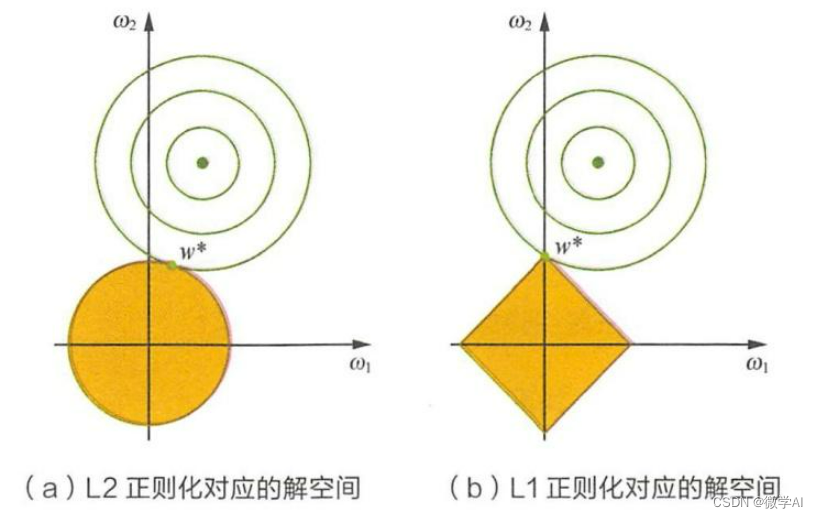
L1正则化(Lasso正则化):L1正则化向损失函数添加的是权重的绝对值之和。它可以导致模型的一些权重变为0,从而实现特征的稀疏表示。这种特性使得L1正则化成为一种有效的特征选择方法,特别是在特征数量远大于样本数量的情况下。
损失函数=原始损失函数+
L2正则化(岭回归):L2正则化向损失函数添加的是权重的平方和。它会惩罚权重的大值,但不会将它们完全降至零。L2正则化有助于处理模型权重的共线性问题,提高模型的稳定性。
损失函数=原始损失函数+


























![P8681 [蓝桥杯 2019 省 AB] 完全二叉树的权值](https://img-blog.csdnimg.cn/img_convert/bd3b8e18b984e0f3c67cedba463df392.png)
