关于
情绪检测,是脑科学研究中的一个常见和热门的方向。在进行情绪检测的分类中,真实数据不足,经常导致情绪检测模型的性能不佳。因此,对数据进行增强,成为了一个提升下游任务的重要的手段。本项目通过DCGAN模型实现脑电信号的扩充。
图片来源:https://www.medicalnewstoday.com/articles/seizure-eeg
工具


数据

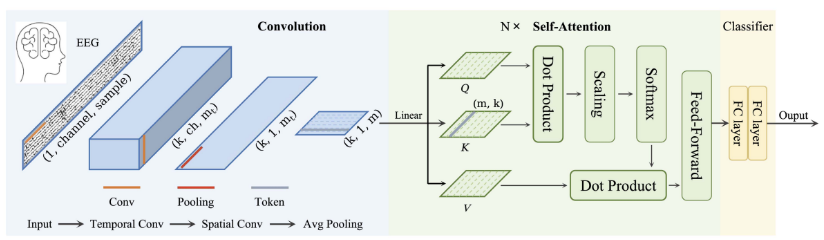
方法实现
DCGAN速递:https://arxiv.org/abs/1511.06434

数据加载和预处理
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.preprocessing import StandardScaler
from tensorflow.keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import SGD
from sklearn.metrics import accuracy_score
from model_DCGAN import DCGAN
from tensorflow.keras.optimizers import Adam, SGD, RMSprop
from sklearn.utils import shuffle
from sklearn.ensemble import GradientBoostingClassifier
use_feature_reduction = True
tf.keras.backend.clear_session()
df=pd.read_csv('dataset/emotions.csv')
encode = ({'NEUTRAL': 0, 'POSITIVE': 1, 'NEGATIVE': 2} )
#new dataset with replaced values
df_encoded = df.replace(encode)
print(df_encoded.head())
print(df_encoded['label'].value_counts()),
x=df_encoded.drop(["label"] ,axis=1)
y = df_encoded.loc[:,'label'].values
scaler = StandardScaler()
scaler.fit(x)
x = scaler.transform(x)
y = to_categorical(y)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 4)
if use_feature_reduction:
# Feature reduction part
est = GradientBoostingClassifier(n_estimators=10, learning_rate=0.1, random_state=0).fit(x_train,
y_train.argmax(-1))
# Obtain feature importance results from Gradient Boosting Regressor
feature_importance = est.feature_importances_
epsilon_feature = 1e-2
x_train = x_train[:, feature_importance > epsilon_feature]
x_test = x_test[:, feature_importance > epsilon_feature]设置DCGAN优化器
# setup optimzers
gen_optim = Adam(1e-4, beta_1=0.5)
disc_optim = RMSprop(5e-4)
训练GAN生成类别0脑电数据
# generate samples for class 0
generator_class = 0
dcgan = DCGAN(gen_optim, disc_optim, noise_dim=100, dropout=0.3, input_dim=x_train.shape[2])
x_train_class_0 = x_train[y_train[:,generator_class]==1,:]
loss_history_class_0, acc_history_class_0, grads_history_class_0 = dcgan.train(x_train_class_0, epochs=100)
print("Class 0 fake samples are generating")
generator_class_0 = dcgan.generator
generated_samples_class_0, _ = dcgan.generate_fake_data(N=len(x_train_class_0))
训练GAN生成类别1脑电数据
# generate samples for class 1
generator_class = 1
dcgan = DCGAN(gen_optim, disc_optim, noise_dim=100, dropout=0.3, input_dim=x_train.shape[2])
x_train_class_1 = x_train[y_train[:,generator_class]==1,:]
loss_history_class_1, acc_history_class_1, grads_history_class_1 = dcgan.train(x_train_class_1, epochs=100)
print("Class 1 fake samples are generating")
generator_class_1 = dcgan.generator
generated_samples_class_1, _ = dcgan.generate_fake_data(N=len(x_train_class_1))训练GAN生成类别2脑电数据
# generate samples for class 2
generator_class = 2
dcgan = DCGAN(gen_optim, disc_optim, noise_dim=100, dropout=0.3, input_dim=x_train.shape[2])
x_train_class_2 = x_train[y_train[:,generator_class]==1,:]
loss_history_class_2, acc_history_class_2, grads_history_class_2 = dcgan.train(x_train_class_2,epochs=100)
print("Class 2 fake samples are generating")
generator_class_2 = dcgan.generator
generated_samples_class_2, _ = dcgan.generate_fake_data(N=len(x_train_class_2))合成数据融入真实训练数据集
generated_samples = np.concatenate((generated_samples_class_0,
generated_samples_class_1,
generated_samples_class_2),axis=0)
generated_y =np.concatenate((np.zeros((len(x_train_class_0),),dtype=np.int32),
np.ones((len(x_train_class_1),),dtype=np.int32),
2 * np.ones((len(x_train_class_2),),dtype=np.int32)),axis=0)
generated_y = to_categorical(generated_y)
x_train_all = np.concatenate((x_train,generated_samples),axis=0)
y_train_all = np.concatenate((y_train,generated_y), axis=0)
#shuffle training data
x_train_all, y_train_all = shuffle(x_train_all,y_train_all)基于数据增强的LSTM模型情绪检测
model = Sequential()
model.add(LSTM(64, input_shape=(1,x_train_all.shape[2]),activation="relu",return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(32,activation="sigmoid"))
model.add(Dropout(0.2))
model.add(Dense(3, activation='sigmoid'))
model.compile(loss = 'categorical_crossentropy', optimizer = "adam", metrics = ['accuracy'])
model.summary()
history = model.fit(x_train_all, y_train_all, epochs = 250, validation_data= (x_test, y_test))
score, acc = model.evaluate(x_test, y_test)
pred = model.predict(x_test)
predict_classes = np.argmax(pred,axis=1)
expected_classes = np.argmax(y_test,axis=1)
print(expected_classes.shape)
print(predict_classes.shape)
correct = accuracy_score(expected_classes,predict_classes)
print(f"Test Accuracy: {correct}")
已附DCGAN模型
相关项目和代码问题,欢迎沟通交流。





















![P8681 [蓝桥杯 2019 省 AB] 完全二叉树的权值](https://img-blog.csdnimg.cn/img_convert/bd3b8e18b984e0f3c67cedba463df392.png)