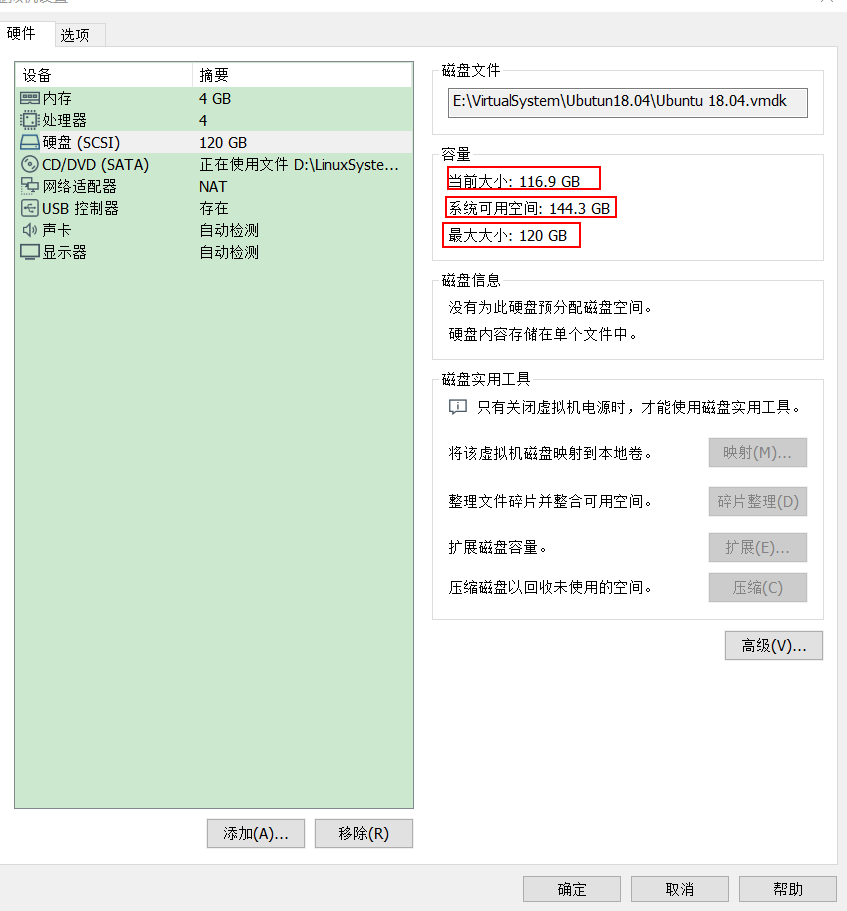
退休了,重操旧业,我计划重写《极限切割》这款排料软件,重中之重就是重写排料算法。因为计划把算法做成云服务形式,所以开发工具就选择 Rust 了。先说结论,Rust 写后台服务程序的确好用,免去很多可能的Bug,只要程序能编译过去,基本上就妥妥的没有啥问题。这对多线程并行算法来说还是很重要的。
零、先介绍一下问题的难点
这个算法应该说是相当复杂的。难点如下:
- 需要把算法分解成 n 个可以完全独立计算的子任务,数学算法的难度就不说了,重点说一下多线程处理面临的困难。子任务完成后需要把计算结果提交到一个任务中心做进一步处理。
- 计算过程中,允许客户端查询计算进度,并在计算完成后能取回计算结果。也就是说,云服务API的函数调用必须是异步的、非阻塞。
- 排料算法未来会面对很多定制需求,以满足各类切割设备的工艺要求,因此,我需要把算法分解成若干独立部分:
(1) 把受工艺影响比较大的排料图生成算法分离出来,如果有定制需求,将来单独升级这一部分;
(2) 排料优化算法框架分离出来,这个与切割工艺没啥关系,可以重复利用;
(3) 通用的数学优化算法框架独立出来,将来在类似的应用中重复利用。 - 上述的三个模型要融合在统一的多线程并行计算框架下工作,确保各类模块在多线程条件下数据和控制信号能安全第在线程间传递,而且不会死锁。
写的过程中,我上火了,身体差点出问题,后来注意到是写这个算法弄得有些过度疲劳所致,及时休息调理才恢复正常。
一、Arc 处理线程间共享数据很方便
1、Arc 的简单例子
Arc<T> 是一个线程安全的引用计数型智能指针,用于在 Rust 中共享数据。以下是一个简单的例子,演示如何使用 Arc<T> 向多个线程传递共享数据。
以下是一个简单的例子,演示如何使用 Arc 向多个线程传递共享数据。
use std::sync::Arc;
use std::thread;
fn main() {
// 创建一个 Arc 包装的 String 类型的共享数据
let shared_data = Arc::new(String::from("Hello, Arc!"));
// 克隆 Arc,以便在新线程中共享数据
let shared_data_clone = shared_data.clone();
// 创建一个新线程,该线程将打印出共享数据的值
let thread = thread::spawn(move || {
println!("The shared data in the new thread is: {}", shared_data_clone);
});
// 在主线程中打印出共享数据的值
println!("The shared data in the main thread is: {}", shared_data);
// 等待新线程完成
thread.join().unwrap();
}
在这个例子中,我们首先创建了一个 Arc<String> 类型的共享数据,并将其初始化为 "Hello, Arc!"。然后,我们克隆了这个 Arc,以便在新线程中使用它。注意,由于 Arc<T> 实现了 Clone trait,我们可以直接调用 .clone() 方法来克隆它。
接下来,我们创建了一个新线程,并将克隆的 Arc<String> 移动到新线程中。在新线程中,我们打印出共享字符串的值。同时,在主线程中,我们也打印出共享字符串的值。由于 Arc<String> 允许线程安全地共享数据,因此这两个打印操作不会相互干扰。
最后,我们使用 thread.join().unwrap(); 等待新线程完成执行。这样,我们就可以确保主线程在新线程完成之前不会退出,从而避免数据竞争或其他并发问题。
2、Arc 的工作原理
Rust 允许把变量传递给线程,由于所有权规则,一个变量只能传递给一个线程。我们没有办法把一个变量 x 传递个多个线程。
能不能把一个变量的引用或地址传递给多个线程,比如把 &x 传递给多个线程?Rust 不允许,因为多个线程同时访问一个变量,会导致不可预期的错误。
但是我们可以把 x 的拷贝传递给多个线程。比如 let x1 = x.clone();let x2 = x.clone();这样 x1、x2就可以传递给两个不同的线程。但这没啥卵用,因为 x1、x2 是两个没啥关系的变量,无法利用他们实现两个线程之间共享数据。
Arc<T> 这个数据类型巧妙地实现了 clone() 方法:
let x = Arc::new(data);
let x1 = x.clone();
let x2 = x.clone();
从语法上看,x1、x2是x的两个克隆的副本,应该没啥关系。但实际上,Arc 仅仅克隆了数据 data 的地址,因此 x1、x2 实际上是指向同一个变量的指针而已。但是 Rust 的编译器会认为 x1、x2 是 x 值的克隆副本。Arc 就这样瞒天过海,骗过了 Rust 的编译器。
Rc<T> 也有类似的功能,但不能在多线程之间传递,因为它没实现 Send 这个特性。
3. Arc<T> 线程安全和共享
Rust 的编译器允许 Arc<T> 类型的数据在多个线程间共享,主要归功于 Arc<T> 的内部设计和 Rust 的所有权系统。以下是几个关键点,解释了为什么 Arc<T> 是线程安全的,并且可以被多个线程共享:
引用计数:
Arc<T>使用引用计数来跟踪有多少个Arc指针指向同一个数据。每当创建一个新的Arc克隆时,计数会增加;每当一个Arc被丢弃(离开作用域或被显式地丢弃)时,计数会减少。当计数减少到零时,Arc所管理的数据会被释放。原子操作:为了确保在多线程环境中的线程安全性,
Arc<T>使用原子操作来更新引用计数。原子操作是不可中断的操作,即在执行过程中不会被其他线程干扰。这确保了即使多个线程同时尝试修改引用计数,也不会发生数据竞争或不一致的状态。共享而非可变:
Arc<T>提供了共享所有权的语义,但它并不允许直接修改其包含的数据(除非数据本身是可变的,并且使用了内部可变性模式,如Arc<Mutex<T>>)。这意味着多个线程可以同时读取Arc中的数据,但不能同时写入,从而避免了数据竞争。类型系统支持:Rust 的类型系统强制实施所有权和借用规则,这有助于在编译时捕获潜在的并发错误。通过使用
Arc<T>,程序员可以明确地表示数据应该在多个线程之间共享,并且编译器会确保这种共享是安全的。明确的线程间数据传递:在 Rust 中,线程之间的数据传递通常是明确的。当你将数据移动到新线程时,你需要使用某种形式的线程安全包装器(如
Arc、Mutex、RwLock等)。这有助于减少意外共享数据的风险,并使代码更易于理解和维护。
综上所述,Rust 编译器允许 Arc<T> 类型的数据在多个线程间共享,是因为 Arc 的设计确保了线程安全性,并且与 Rust 的所有权和类型系统紧密集成,从而在编译时提供了强大的并发安全性保证。
4. Arc<T> 对数据 T 进行了只读保护
Arc<T> 本身没有提供直接修改其内部数据 T 的 mut 类型访问接口。Arc<T> 主要是设计用来在多个所有者之间安全地共享不可变数据。
如果你想要修改 Arc<T> 内部的数据,你需要使用某种形式的内部可变性。最常见的方法是结合使用 Mutex<T>、RwLock<T> 或其他同步原语,这些原语可以提供安全的可变访问,同时防止数据竞争。
例如,Arc<Mutex<T>> 允许你通过锁定互斥锁来获取对内部数据 T 的可变访问。当你拥有锁时,你可以修改数据,而锁会确保同一时间只有一个线程能够修改数据。
简而言之,Arc<T> 提供了数据的共享所有权,但它本身不提供数据的可变访问。如果你需要可变访问,你必须使用额外的同步机制来实现。
5. 我在算法中用 Arc 在线程之间共享了算法的约束条件
因为问题的约束条件在计算过程中是不会修改的,于是我用 Arc<Question> 类型在线程间实现了只读共享。这个机制简单易用,非常推荐。
二、Mutex 的巧妙设计
Arc<T> 中的数据 T 是只读的。那么,想在线程中修改 T 的值怎么办?于是我们看到奇妙的 Mutex<T> 类型出现了。
1. Mutex 的一个简单例子
下面是一个简单的例子,演示了如何修改Mutex<T>中的变量。在这个例子中,我们将使用Mutex<i32>来在一个单线程环境中模拟锁定和修改数据的操作。虽然在单线程中使用Mutex并不常见(因为没有并发访问),但这个例子可以清楚地展示如何修改Mutex保护的数据。
use std::sync::Mutex;
fn main() {
// 创建一个 Mutex<i32>,它保护一个 i32 类型的变量
let mutex = Mutex::new(0);
// 锁定 Mutex 以获取可变访问权限
let mut locked_data = mutex.lock().unwrap();
// 修改 Mutex 保护的数据
*locked_data += 10;
// 锁定作用域结束,MutexGuard 被丢弃,锁被自动释放
// 再次锁定 Mutex 以验证数据已被修改
let locked_data = mutex.lock().unwrap();
// 打印修改后的数据
println!("The value protected by the mutex is: {}", *locked_data);
}
在这个例子中,我们首先创建了一个Mutex<i32>实例,它包裹了一个初始值为0的i32类型变量。然后,我们使用lock方法来获取Mutex的锁,并得到一个MutexGuard<i32>对象。MutexGuard提供了一个可变引用,允许我们修改被Mutex保护的数据。在这个例子中,我们将值增加了10。
当MutexGuard离开作用域时(在这个例子中,是在修改数据后的第一个花括号结束时),它会自动释放锁,这样其他尝试锁定Mutex的代码就可以获取锁了。
最后,我们再次锁定Mutex并打印出修改后的值,以验证数据确实已经被修改。
请注意,在实际的多线程环境中,你需要确保在使用Mutex时遵循正确的锁定和解锁模式,以避免死锁和其他并发问题。此外,在处理可能失败的操作时(例如锁定),你应该使用适当的错误处理机制,而不是简单地使用unwrap方法。
2. lock() 方法把只读变量变成了 mut 类型
上面的例子中,let mutex = ... 这个语法说明 mutex 是只读的。另外,lock() 方法的声明如下:
pub fn lock(&self) -> LockResult<MutexGuard<'_, T>>
fn lock(&self)... 这个声明方式也说明 lock()是不会修改 mutex 的值的。如果改成 fn lock(&mut self)... 肯定也是编译不过去的。
在Rust中,当我们声明一个变量为let mutex = Mutex::new(0);时,确实mutex本身是一个不可变的(只读的)绑定到Mutex<i32>值的变量。这意味着你不能将mutex重新绑定到另一个不同的Mutex实例上。但是,Mutex内部的数据(在这个例子中是i32类型的值)是可以被修改的,尽管mutex变量本身的绑定是不可变的。
这种修改是通过Mutex提供的内部可变性机制来实现的。Mutex是一个提供同步访问的容器,它允许在锁定的情况下安全地修改其内部数据。即使外部绑定mutex是不可变的,Mutex内部仍然有逻辑来管理对其内部数据的可变访问。
当你调用mutex.lock()方法时,你尝试获取Mutex的锁。如果成功,你会得到一个MutexGuard对象,它提供了一个可变引用(在Rust中通常是&mut T类型)到Mutex内部的数据。这个可变引用允许你在锁定期间修改数据。当MutexGuard离开作用域或被显式丢弃时,锁会被自动释放。
因此,尽管mutex是一个不可变绑定,但通过Mutex提供的锁定机制,你仍然可以安全地修改其内部的数据。这是Rust中内部可变性模式的一个例子,它允许在不改变外部不可变性的前提下修改数据。
3. 算法中的 Arc<Mutex<Task>>
算法的调度中心 Task 封装成Arc<Mutex<Task>>分发到工作线程中,线程在必要时可以向 Task 提交数据。
为了保证工作效率,一定需要优化每次访问 Task 的时间,不然的话会成为整个并行算法的瓶颈。测试表明,我的算法几乎看不到这一过程对并行计算造成的影响。
三、RwLock 很有用
1. RwLock 简介
RwLock,全称Read-Write Lock,即读写锁,是一种高效的线程同步机制。它允许多个线程同时读取共享数据,但只允许一个线程写入数据。这种锁的设计旨在提高并发性能,因为它可以避免读写操作之间的竞争。
在Rust中,RwLock是基于std::sync::RwLock结构体实现的。这个结构体包装了需要被保护的数据,并确保数据在多线程环境中的安全性。RwLock的使用非常灵活,它可以根据访问模式(读或写)来动态地调整锁定策略。
当多个线程需要读取共享数据时,它们可以同时获取读锁,而不会相互阻塞。这种并发读取的能力可以显著提高系统的吞吐量。然而,当某个线程需要写入数据时,它必须获取写锁。在获取写锁的过程中,其他所有尝试获取读锁或写锁的线程都将被阻塞,直到写锁被释放。
RwLock的内部实现原理涉及复杂的线程调度和同步机制,但幸运的是,Rust的标准库为我们提供了易于使用的接口。通过调用RwLock的read()和write()方法,我们可以方便地获取读锁和写锁。
需要注意的是,虽然RwLock可以提高并发性能,但它并不总是最佳的选择。在某些情况下,使用其他同步机制(如互斥锁或原子操作)可能更为合适。因此,在选择线程同步机制时,我们应该根据具体的应用场景和需求进行权衡。
总的来说,RwLock是一种强大的线程同步工具,它允许多个线程并发地读取共享数据,同时确保在写入数据时线程的安全性。在Rust中,我们可以利用std::sync::RwLock结构体来轻松地使用这种锁,并享受它带来的性能提升。
2. RwLock 用于广播消息很方便
在本算法中,我想通过 API 通知线程池中的所有工作线程停止计算,只需要简单地把一个 Arc<RwLock<bool>>: 变量分发给工作线程。当API 层把 bool 变量设置为 true时,工作线程查询到这个结果后则结束工作。
类似广播消息的机制,用 RwLock 实现很是方便。
小结
总体上看,Rust 在编写多线程并行算法时提供了强有力的保障,它的所有权机制确保了系统的安全、可靠和杜绝各类内存泄漏问题的发生。这是我用Rust编写的第二款软件,开发效率和易用性方面我觉得比之前用过的 C/C++、Delphi等都有明显的优势。有些用C++、Delphi写的程序,投放市场十几年还会有Bug出现,用Rust写的程序,只要编译过去,基本上就高枕无忧了!