Netty核心原理剖析与RPC实践6-10
06-粘包拆包问题:如何获取一个完整的网络包
本节课开始我们将学习 Netty 通信过程中的编解码技术。编解码技术这是实现网络通信的基础,让我们可以定义任何满足业务需求的应用层协议。在网络编程中,我们经常会使用各种网络传输协议,其中 TCP 是最常用的协议。我们首先需要了解的是 TCP 最基本的拆包/粘包问题以及常用的解决方案,才能更好地理解 Netty 的编解码框架。
为什么有拆包/粘包
TCP 传输协议是面向流的,没有数据包界限。客户端向服务端发送数据时,可能将一个完整的报文拆分成多个小报文进行发送,也可能将多个报文合并成一个大的报文进行发送。因此就有了拆包和粘包。
为什么会出现拆包/粘包现象呢?在网络通信的过程中,每次可以发送的数据包大小是受多种因素限制的,如 MTU 传输单元大小、MSS 最大分段大小、滑动窗口等。如果一次传输的网络包数据大小超过传输单元大小,那么我们的数据可能会拆分为多个数据包发送出去。如果每次请求的网络包数据都很小,一共请求了 10000 次,TCP 并不会分别发送 10000 次。因为 TCP 采用的 Nagle 算法对此作出了优化。如果你是一位网络新手,可能对这些概念并不非常清楚。那我们先了解下计算机网络中 MTU、MSS、Nagle 这些基础概念以及它们为什么会造成拆包/粘包问题。
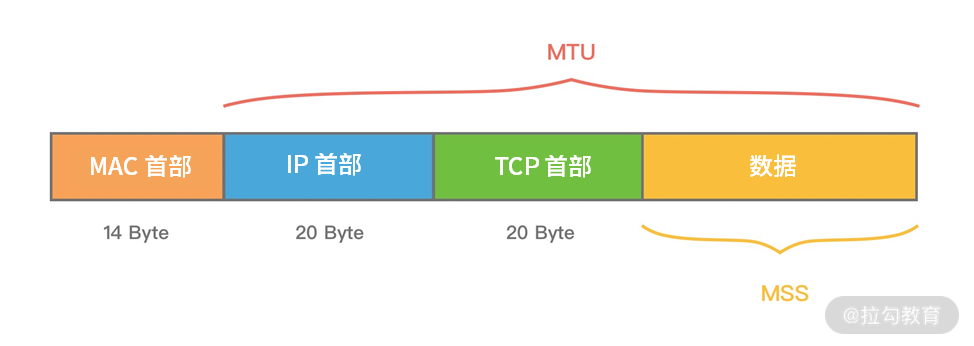
MTU 最大传输单元和 MSS 最大分段大小
MTU(Maxitum Transmission Unit) 是链路层一次最大传输数据的大小。MTU 一般来说大小为 1500 byte。MSS(Maximum Segement Size) 是指 TCP 最大报文段长度,它是传输层一次发送最大数据的大小。如下图所示,MTU 和 MSS 一般的计算关系为:MSS = MTU - IP 首部 - TCP首部,如果 MSS + TCP 首部 + IP 首部 > MTU,那么数据包将会被拆分为多个发送。这就是拆包现象。
滑动窗口
滑动窗口是 TCP 传输层用于流量控制的一种有效措施,也被称为通告窗口。滑动窗口是数据接收方设置的窗口大小,随后接收方会把窗口大小告诉发送方,以此限制发送方每次发送数据的大小,从而达到流量控制的目的。这样数据发送方不需要每发送一组数据就阻塞等待接收方确认,允许发送方同时发送多个数据分组,每次发送的数据都会被限制在窗口大小内。由此可见,滑动窗口可以大幅度提升网络吞吐量。
那么 TCP 报文是怎么确保数据包按次序到达且不丢数据呢?首先,所有的数据帧都是有编号的,TCP 并不会为每个报文段都回复 ACK 响应,它会对多个报文段回复一次 ACK。假设有三个报文段 A、B、C,发送方先发送了B、C,接收方则必须等待 A 报文段到达,如果一定时间内仍未等到 A 报文段,那么 B、C 也会被丢弃,发送方会发起重试。如果已接收到 A 报文段,那么将会回复发送方一次 ACK 确认。
Nagle 算法
Nagle 算法于 1984 年被福特航空和通信公司定义为 TCP/IP 拥塞控制方法。它主要用于解决频繁发送小数据包而带来的网络拥塞问题。试想如果每次需要发送的数据只有 1 字节,加上 20 个字节 IP Header 和 20 个字节 TCP Header,每次发送的数据包大小为 41 字节,但是只有 1 字节是有效信息,这就造成了非常大的浪费。Nagle 算法可以理解为批量发送,也是我们平时编程中经常用到的优化思路,它是在数据未得到确认之前先写入缓冲区,等待数据确认或者缓冲区积攒到一定大小再把数据包发送出去。
Linux 在默认情况下是开启 Nagle 算法的,在大量小数据包的场景下可以有效地降低网络开销。但如果你的业务场景每次发送的数据都需要获得及时响应,那么 Nagle 算法就不能满足你的需求了,因为 Nagle 算法会有一定的数据延迟。你可以通过 Linux 提供的 TCP_NODELAY 参数禁用 Nagle 算法。Netty 中为了使数据传输延迟最小化,就默认禁用了 Nagle 算法,这一点与 Linux 操作系统的默认行为是相反的。
拆包/粘包的解决方案

在客户端和服务端通信的过程中,服务端一次读到的数据大小是不确定的。如上图所示,拆包/粘包可能会出现以下五种情况:
- 服务端恰巧读到了两个完整的数据包 A 和 B,没有出现拆包/粘包问题;
- 服务端接收到 A 和 B 粘在一起的数据包,服务端需要解析出 A 和 B;
- 服务端收到完整的 A 和 B 的一部分数据包 B-1,服务端需要解析出完整的 A,并等待读取完整的 B 数据包;
- 服务端接收到 A 的一部分数据包 A-1,此时需要等待接收到完整的 A 数据包;
- 数据包 A 较大,服务端需要多次才可以接收完数据包 A。
由于拆包/粘包问题的存在,数据接收方很难界定数据包的边界在哪里,很难识别出一个完整的数据包。所以需要提供一种机制来识别数据包的界限,这也是解决拆包/粘包的唯一方法:定义应用层的通信协议。下面我们一起看下主流协议的解决方案。
消息长度固定
每个数据报文都需要一个固定的长度。当接收方累计读取到固定长度的报文后,就认为已经获得一个完整的消息。当发送方的数据小于固定长度时,则需要空位补齐。
+----+------+------+---+----+
| AB | CDEF | GHIJ | K | LM |
+----+------+------+---+----+
假设我们的固定长度为 4 字节,那么如上所示的 5 条数据一共需要发送 4 个报文:
+------+------+------+------+
| ABCD | EFGH | IJKL | M000 |
+------+------+------+------+
消息定长法使用非常简单,但是缺点也非常明显,无法很好设定固定长度的值,如果长度太大会造成字节浪费,长度太小又会影响消息传输,所以在一般情况下消息定长法不会被采用。
特定分隔符
既然接收方无法区分消息的边界,那么我们可以在每次发送报文的尾部加上特定分隔符,接收方就可以根据特殊分隔符进行消息拆分。以下报文根据特定分隔符 \n 按行解析,即可得到 AB、CDEF、GHIJ、K、LM 五条原始报文。
+-------------------------+
| AB\nCDEF\nGHIJ\nK\nLM\n |
+-------------------------+
由于在发送报文时尾部需要添加特定分隔符,所以对于分隔符的选择一定要避免和消息体中字符相同,以免冲突。否则可能出现错误的消息拆分。比较推荐的做法是将消息进行编码,例如 base64 编码,然后可以选择 64 个编码字符之外的字符作为特定分隔符。特定分隔符法在消息协议足够简单的场景下比较高效,例如大名鼎鼎的 Redis 在通信过程中采用的就是换行分隔符。
消息长度 + 消息内容
消息头 消息体
+--------+----------+
| Length | Content |
+--------+----------+
消息长度 + 消息内容是项目开发中最常用的一种协议,如上展示了该协议的基本格式。消息头中存放消息的总长度,例如使用 4 字节的 int 值记录消息的长度,消息体实际的二进制的字节数据。接收方在解析数据时,首先读取消息头的长度字段 Len,然后紧接着读取长度为 Len 的字节数据,该数据即判定为一个完整的数据报文。依然以上述提到的原始字节数据为例,使用该协议进行编码后的结果如下所示:
+-----+-------+-------+----+-----+
| 2AB | 4CDEF | 4GHIJ | 1K | 2LM |
+-----+-------+-------+----+-----+
消息长度 + 消息内容的使用方式非常灵活,且不会存在消息定长法和特定分隔符法的明显缺陷。当然在消息头中不仅只限于存放消息的长度,而且可以自定义其他必要的扩展字段,例如消息版本、算法类型等。
总结
本节课我们详细讨论了 TCP 中的拆包/粘包问题,以及如何通过应用层的通信协议来解决拆包/粘包问题。其中基于消息长度 + 消息内容的变长协议是项目开发中最常用的一种方法,需要我们重点掌握,例如开源中间件 Dubbo、RocketMQ 等都基于该方法自定义了自己的通信协议,下节课我们将一起学习如何设计高效、可扩展、易维护的自定义网络通信协议。
07 接头暗语:如何利用 Netty 实现自定义协议通信
既然是网络编程,自然离不开通信协议,应用层之间通信需要实现各种各样的网络协议。在项目开发的过程中,我们就需要去构建满足自己业务场景的应用层协议。在上节课中我们介绍了如何使用网络协议解决 TCP 拆包/粘包的底层问题,本节课我们将在此基础上继续讨论如何设计一个高效、可扩展、易维护的自定义通信协议,以及如何使用 Netty 实现自定义通信协议。
通信协议设计
所谓协议,就是通信双方事先商量好的接口暗语,在 TCP 网络编程中,发送方和接收方的数据包格式都是二进制,发送方将对象转化成二进制流发送给接收方,接收方获得二进制数据后需要知道如何解析成对象,所以协议是双方能够正常通信的基础。
目前市面上已经有不少通用的协议,例如 HTTP、HTTPS、JSON-RPC、FTP、IMAP、Protobuf 等。通用协议兼容性好,易于维护,各种异构系统之间可以实现无缝对接。如果在满足业务场景以及性能需求的前提下,推荐采用通用协议的方案。相比通用协议,自定义协议主要有以下优点。
- 极致性能:通用的通信协议考虑了很多兼容性的因素,必然在性能方面有所损失。
- 扩展性:自定义的协议相比通用协议更好扩展,可以更好地满足自己的业务需求。
- 安全性:通用协议是公开的,很多漏洞已经很多被黑客攻破。自定义协议更加安全,因为黑客需要先破解你的协议内容。
那么如何设计自定义的通信协议呢?这个答案见仁见智,但是设计通信协议有经验方法可循。结合实战经验我们一起看下一个完备的网络协议需要具备哪些基本要素。
1. 魔数
魔数是通信双方协商的一个暗号,通常采用固定的几个字节表示。魔数的作用是防止任何人随便向服务器的端口上发送数据。服务端在接收到数据时会解析出前几个固定字节的魔数,然后做正确性比对。如果和约定的魔数不匹配,则认为是非法数据,可以直接关闭连接或者采取其他措施以增强系统的安全防护。魔数的思想在压缩算法、Java Class 文件等场景中都有所体现,例如 Class 文件开头就存储了魔数 0xCAFEBABE,在加载 Class 文件时首先会验证魔数的正确性。
2. 协议版本号
随着业务需求的变化,协议可能需要对结构或字段进行改动,不同版本的协议对应的解析方法也是不同的。所以在生产级项目中强烈建议预留协议版本号这个字段。
3. 序列化算法
序列化算法字段表示数据发送方应该采用何种方法将请求的对象转化为二进制,以及如何再将二进制转化为对象,如 JSON、Hessian、Java 自带序列化等。
4. 报文类型
在不同的业务场景中,报文可能存在不同的类型。例如在 RPC 框架中有请求、响应、心跳等类型的报文,在 IM 即时通信的场景中有登陆、创建群聊、发送消息、接收消息、退出群聊等类型的报文。
5. 长度域字段
长度域字段代表请求数据的长度,接收方根据长度域字段获取一个完整的报文。
6. 请求数据
请求数据通常为序列化之后得到的二进制流,每种请求数据的内容是不一样的。
7. 状态
状态字段用于标识请求是否正常。一般由被调用方设置。例如一次 RPC 调用失败,状态字段可被服务提供方设置为异常状态。
8. 保留字段
保留字段是可选项,为了应对协议升级的可能性,可以预留若干字节的保留字段,以备不时之需。
通过以上协议基本要素的学习,我们可以得到一个较为通用的协议示例:
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
Netty 如何实现自定义通信协议
在学习完如何设计协议之后,我们又该如何在 Netty 中实现自定义的通信协议呢?其实 Netty 作为一个非常优秀的网络通信框架,已经为我们提供了非常丰富的编解码抽象基类,帮助我们更方便地基于这些抽象基类扩展实现自定义协议。
首先我们看下 Netty 中编解码器是如何分类的。
Netty 常用编码器类型:
- MessageToByteEncoder 对象编码成字节流;
- MessageToMessageEncoder 一种消息类型编码成另外一种消息类型。
Netty 常用解码器类型:
- ByteToMessageDecoder/ReplayingDecoder 将字节流解码为消息对象;
- MessageToMessageDecoder 将一种消息类型解码为另外一种消息类型。
编解码器可以分为一次解码器和二次解码器,一次解码器用于解决 TCP 拆包/粘包问题,按协议解析后得到的字节数据。如果你需要对解析后的字节数据做对象模型的转换,这时候便需要用到二次解码器,同理编码器的过程是反过来的。
- 一次编解码器:MessageToByteEncoder/ByteToMessageDecoder。
- 二次编解码器:MessageToMessageEncoder/MessageToMessageDecoder。
下面我们对 Netty 中常用的抽象编解码类进行详细的介绍。
抽象编码类
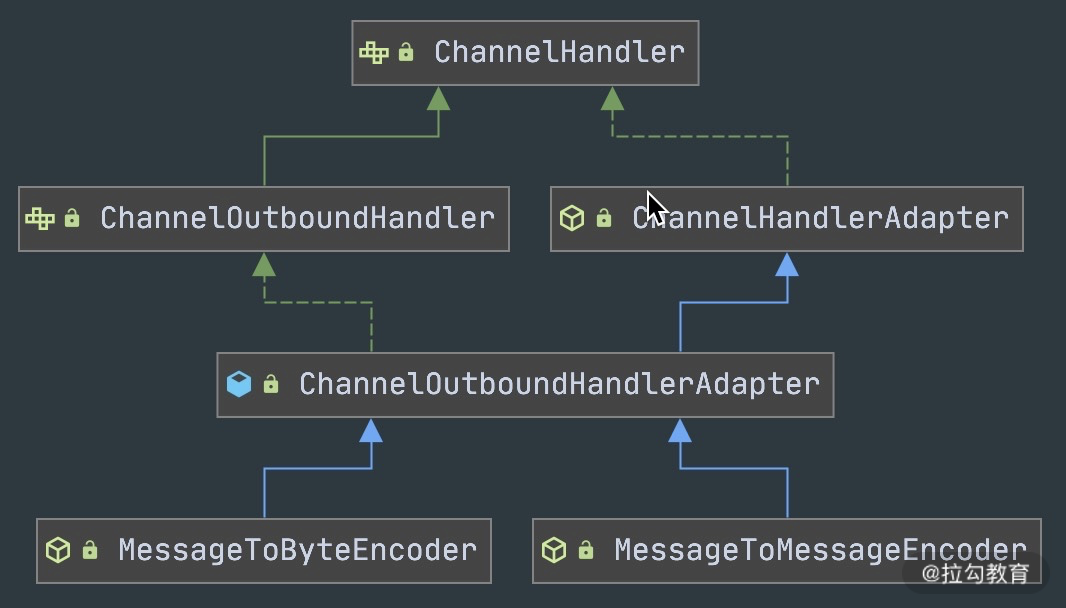
通过抽象编码类的继承图可以看出,编码类是 ChanneOutboundHandler 的抽象类实现,具体操作的是 Outbound 出站数据。
- MessageToByteEncoder
MessageToByteEncoder 用于将对象编码成字节流,MessageToByteEncoder 提供了唯一的 encode 抽象方法,我们只需要实现encode 方法即可完成自定义编码。那么encode() 方法是在什么时候被调用的呢?我们一起看下MessageToByteEncoder 的核心源码片段,如下所示。
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ByteBuf buf = null;
try {
if (acceptOutboundMessage(msg)) { // 1. 消息类型是否匹配
@SuppressWarnings("unchecked")
I cast = (I) msg;
buf = allocateBuffer(ctx, cast, preferDirect); // 2. 分配 ByteBuf 资源
try {
encode(ctx, cast, buf); // 3. 执行 encode 方法完成数据编码
} finally {
ReferenceCountUtil.release(cast);
}
if (buf.isReadable()) {
ctx.write(buf, promise); // 4. 向后传递写事件
} else {
buf.release();
ctx.write(Unpooled.EMPTY_BUFFER, promise);
}
buf = null;
} else {
ctx.write(msg, promise);
}
} catch (EncoderException e) {
throw e;
} catch (Throwable e) {
throw new EncoderException(e);
} finally {
if (buf != null) {
buf.release();
}
}
}
MessageToByteEncoder 重写了 ChanneOutboundHandler 的 write() 方法,其主要逻辑分为以下几个步骤:
- acceptOutboundMessage 判断是否有匹配的消息类型,如果匹配需要执行编码流程,如果不匹配直接继续传递给下一个 ChannelOutboundHandler;
- 分配 ByteBuf 资源,默认使用堆外内存;
- 调用子类实现的 encode 方法完成数据编码,一旦消息被成功编码,会通过调用 ReferenceCountUtil.release(cast) 自动释放;
- 如果 ByteBuf 可读,说明已经成功编码得到数据,然后写入 ChannelHandlerContext 交到下一个节点;如果 ByteBuf 不可读,则释放 ByteBuf 资源,向下传递空的 ByteBuf 对象。
编码器实现非常简单,不需要关注拆包/粘包问题。如下例子,展示了如何将字符串类型的数据写入到 ByteBuf 实例,ByteBuf 实例将传递给 ChannelPipeline 链表中的下一个 ChannelOutboundHandler。
public class StringToByteEncoder extends MessageToByteEncoder<String> {
@Override
protected void encode(ChannelHandlerContext channelHandlerContext, String data, ByteBuf byteBuf) throws Exception {
byteBuf.writeBytes(data.getBytes());
}
}
- MessageToMessageEncoder
MessageToMessageEncoder 与 MessageToByteEncoder 类似,同样只需要实现 encode 方法。与 MessageToByteEncoder 不同的是,MessageToMessageEncoder 是将一种格式的消息转换为另外一种格式的消息。其中第二个 Message 所指的可以是任意一个对象,如果该对象是 ByteBuf 类型,那么基本上和 MessageToByteEncoder 的实现原理是一致的。此外 MessageToByteEncoder 的输出结果是对象列表,编码后的结果属于中间对象,最终仍然会转化成 ByteBuf 进行传输。
MessageToMessageEncoder 常用的实现子类有 StringEncoder、LineEncoder、Base64Encoder 等。以 StringEncoder 为例看下 MessageToMessageEncoder 的用法。源码示例如下:将 CharSequence 类型(String、StringBuilder、StringBuffer 等)转换成 ByteBuf 类型,结合 StringDecoder 可以直接实现 String 类型数据的编解码。
@Override
protected void encode(ChannelHandlerContext ctx, CharSequence msg, List<Object> out) throws Exception {
if (msg.length() == 0) {
return;
}
out.add(ByteBufUtil.encodeString(ctx.alloc(), CharBuffer.wrap(msg), charset));
}
抽象解码类
同样,我们先看下抽象解码类的继承关系图。解码类是 ChanneInboundHandler 的抽象类实现,操作的是 Inbound 入站数据。解码器实现的难度要远大于编码器,因为解码器需要考虑拆包/粘包问题。由于接收方有可能没有接收到完整的消息,所以解码框架需要对入站的数据做缓冲操作,直至获取到完整的消息。

- 抽象解码类 ByteToMessageDecoder。
首先,我们看下 ByteToMessageDecoder 定义的抽象方法:
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter {
protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;
protected void decodeLast(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
if (in.isReadable()) {
decodeRemovalReentryProtection(ctx, in, out);
}
}
}
decode() 是用户必须实现的抽象方法,在该方法在调用时需要传入接收的数据 ByteBuf,及用来添加编码后消息的 List。由于 TCP 粘包问题,ByteBuf 中可能包含多个有效的报文,或者不够一个完整的报文。Netty 会重复回调 decode() 方法,直到没有解码出新的完整报文可以添加到 List 当中,或者 ByteBuf 没有更多可读取的数据为止。如果此时 List 的内容不为空,那么会传递给 ChannelPipeline 中的下一个ChannelInboundHandler。
此外 ByteToMessageDecoder 还定义了 decodeLast() 方法。为什么抽象解码器要比编码器多一个 decodeLast() 方法呢?因为 decodeLast 在 Channel 关闭后会被调用一次,主要用于处理 ByteBuf 最后剩余的字节数据。Netty 中 decodeLast 的默认实现只是简单调用了 decode() 方法。如果有特殊的业务需求,则可以通过重写 decodeLast() 方法扩展自定义逻辑。
ByteToMessageDecoder 还有一个抽象子类是 ReplayingDecoder。它封装了缓冲区的管理,在读取缓冲区数据时,你无须再对字节长度进行检查。因为如果没有足够长度的字节数据,ReplayingDecoder 将终止解码操作。ReplayingDecoder 的性能相比直接使用 ByteToMessageDecoder 要慢,大部分情况下并不推荐使用 ReplayingDecoder。
- 抽象解码类 MessageToMessageDecoder。
MessageToMessageDecoder 与 ByteToMessageDecoder 作用类似,都是将一种消息类型的编码成另外一种消息类型。与 ByteToMessageDecoder 不同的是 MessageToMessageDecoder 并不会对数据报文进行缓存,它主要用作转换消息模型。比较推荐的做法是使用 ByteToMessageDecoder 解析 TCP 协议,解决拆包/粘包问题。解析得到有效的 ByteBuf 数据,然后传递给后续的 MessageToMessageDecoder 做数据对象的转换,具体流程如下图所示。

通信协议实战
在上述通信协议设计的小节内容中,我们提到了协议的基本要素并给出了一个较为通用的协议示例。下面我们通过 Netty 的编辑码框架实现该协议的解码器,加深我们对 Netty 编解码框架的理解。
在实现协议编码器之前,我们首先需要清楚一个问题:如何判断 ByteBuf 是否存在完整的报文?最常用的做法就是通过读取消息长度 dataLength 进行判断。如果 ByteBuf 的可读数据长度小于 dataLength,说明 ByteBuf 还不够获取一个完整的报文。在该协议前面的消息头部分包含了魔数、协议版本号、数据长度等固定字段,共 14 个字节。固定字段长度和数据长度可以作为我们判断消息完整性的依据,具体编码器实现逻辑示例如下:
/*
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
*/
@Override
public final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
// 判断 ByteBuf 可读取字节
if (in.readableBytes() < 14) {
return;
}
in.markReaderIndex(); // 标记 ByteBuf 读指针位置
in.skipBytes(2); // 跳过魔数
in.skipBytes(1); // 跳过协议版本号
byte serializeType = in.readByte();
in.skipBytes(1); // 跳过报文类型
in.skipBytes(1); // 跳过状态字段
in.skipBytes(4); // 跳过保留字段
int dataLength = in.readInt();
if (in.readableBytes() < dataLength) {
in.resetReaderIndex(); // 重置 ByteBuf 读指针位置
return;
}
byte[] data = new byte[dataLength];
in.readBytes(data);
SerializeService serializeService = getSerializeServiceByType(serializeType);
Object obj = serializeService.deserialize(data);
if (obj != null) {
out.add(obj);
}
}
上述实现中所涉及的 ByteBuf API,在本章节就不做详细阐述了。在本专栏第三章我们会深入学习 ByteBuf。
总结
本节课我们学习了协议设计的基本要素,以及如何使用 Netty 实现自定义协议。Netty 提供了一组 ChannelHandler 实现的抽象类,在项目开发中基于这些抽象类实现自定义的编解码器具备较好的可扩展性,最后通过具体示例协议的实战加深对编解码器的理解。你学会了吗?
当然 Netty 在编解码方面所做的工作远不止于此。它还提供了丰富的开箱即用的编解码器,下节课我们便一起探索实用的编解码技巧。
08 开箱即用:Netty 支持哪些常用的解码器?
在前两节课我们介绍了 TCP 拆包/粘包的问题,以及如何使用 Netty 实现自定义协议的编解码。可以看到,网络通信的底层实现,Netty 都已经帮我们封装好了,我们只需要扩展 ChannelHandler 实现自定义的编解码逻辑即可。更加人性化的是,Netty 提供了很多开箱即用的解码器,这些解码器基本覆盖了 TCP 拆包/粘包的通用解决方案。本节课我们将对 Netty 常用的解码器进行讲解,一起探索下它们有哪些用法和技巧。
在本节课开始之前,我们首先回顾一下 TCP 拆包/粘包的主流解决方案。并梳理出 Netty 对应的编码器类。
固定长度解码器 FixedLengthFrameDecoder
固定长度解码器 FixedLengthFrameDecoder 非常简单,直接通过构造函数设置固定长度的大小 frameLength,无论接收方一次获取多大的数据,都会严格按照 frameLength 进行解码。如果累积读取到长度大小为 frameLength 的消息,那么解码器认为已经获取到了一个完整的消息。如果消息长度小于 frameLength,FixedLengthFrameDecoder 解码器会一直等后续数据包的到达,直至获得完整的消息。下面我们通过一个例子感受一下使用 Netty 实现固定长度解码是多么简单。
public class EchoServer {
public void startEchoServer(int port) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new FixedLengthFrameDecoder(10));
ch.pipeline().addLast(new EchoServerHandler());
}
});
ChannelFuture f = b.bind(port).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws Exception {
new EchoServer().startEchoServer(8088);
}
}
@Sharable
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
System.out.println("Receive client : [" + ((ByteBuf) msg).toString(CharsetUtil.UTF_8) + "]");
}
}
在上述服务端的代码中使用了固定 10 字节的解码器,并在解码之后通过 EchoServerHandler 打印结果。我们可以启动服务端,通过 telnet 命令像服务端发送数据,观察代码输出的结果。
客户端输入:
telnet localhost 8088
Trying ::1...
Connected to localhost.
Escape character is '^]'.
1234567890123
456789012
服务端输出:
Receive client : [1234567890]
Receive client : [123
45678]
特殊分隔符解码器 DelimiterBasedFrameDecoder
使用特殊分隔符解码器 DelimiterBasedFrameDecoder 之前我们需要了解以下几个属性的作用。
- delimiters
delimiters 指定特殊分隔符,通过写入 ByteBuf 作为参数传入。delimiters 的类型是 ByteBuf 数组,所以我们可以同时指定多个分隔符,但是最终会选择长度最短的分隔符进行消息拆分。
例如接收方收到的数据为:
+--------------+
| ABC\nDEF\r\n |
+--------------+
如果指定的多个分隔符为 \n 和 \r\n,DelimiterBasedFrameDecoder 会退化成使用 LineBasedFrameDecoder 进行解析,那么会解码出两个消息。
+-----+-----+
| ABC | DEF |
+-----+-----+
如果指定的特定分隔符只有 \r\n,那么只会解码出一个消息:
+----------+
| ABC\nDEF |
+----------+
- maxLength
maxLength 是报文最大长度的限制。如果超过 maxLength 还没有检测到指定分隔符,将会抛出 TooLongFrameException。可以说 maxLength 是对程序在极端情况下的一种保护措施。
- failFast
failFast 与 maxLength 需要搭配使用,通过设置 failFast 可以控制抛出 TooLongFrameException 的时机,可以说 Netty 在细节上考虑得面面俱到。如果 failFast=true,那么在超出 maxLength 会立即抛出 TooLongFrameException,不再继续进行解码。如果 failFast=false,那么会等到解码出一个完整的消息后才会抛出 TooLongFrameException。
- stripDelimiter
stripDelimiter 的作用是判断解码后得到的消息是否去除分隔符。如果 stripDelimiter=false,特定分隔符为 \n,那么上述数据包解码出的结果为:
+-------+---------+
| ABC\n | DEF\r\n |
+-------+---------+
下面我们还是结合代码示例学习 DelimiterBasedFrameDecoder 的用法,依然以固定编码器小节中使用的代码为基础稍做改动,引入特殊分隔符解码器 DelimiterBasedFrameDecoder:
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ByteBuf delimiter = Unpooled.copiedBuffer("&".getBytes());
ch.pipeline().addLast(new DelimiterBasedFrameDecoder(10, true, true, delimiter));
ch.pipeline().addLast(new EchoServerHandler());
}
});
我们依然通过 telnet 模拟客户端发送数据,观察代码输出的结果,可以发现由于 maxLength 设置的只有 10,所以在解析到第三个消息时抛出异常。
客户端输入:
telnet localhost 8088
Trying ::1...
Connected to localhost.
Escape character is '^]'.
hello&world&1234567890ab
服务端输出:
Receive client : [hello]
Receive client : [world]
九月 25, 2020 8:46:01 下午 io.netty.channel.DefaultChannelPipeline onUnhandledInboundException
警告: An exceptionCaught() event was fired, and it reached at the tail of the pipeline. It usually means the last handler in the pipeline did not handle the exception.
io.netty.handler.codec.TooLongFrameException: frame length exceeds 10: 13 - discarded
at io.netty.handler.codec.DelimiterBasedFrameDecoder.fail(DelimiterBasedFrameDecoder.java:302)
at io.netty.handler.codec.DelimiterBasedFrameDecoder.decode(DelimiterBasedFrameDecoder.java:268)
at io.netty.handler.codec.DelimiterBasedFrameDecoder.decode(DelimiterBasedFrameDecoder.java:218)
长度域解码器 LengthFieldBasedFrameDecoder
长度域解码器 LengthFieldBasedFrameDecoder 是解决 TCP 拆包/粘包问题最常用的**解码器。**它基本上可以覆盖大部分基于长度拆包场景,开源消息中间件 RocketMQ 就是使用 LengthFieldBasedFrameDecoder 进行解码的。LengthFieldBasedFrameDecoder 相比 FixedLengthFrameDecoder 和 DelimiterBasedFrameDecoder 要复杂一些,接下来我们就一起学习下这个强大的解码器。
首先我们同样先了解 LengthFieldBasedFrameDecoder 中的几个重要属性,这里我主要把它们分为两个部分:长度域解码器特有属性以及与其他解码器(如特定分隔符解码器)的相似的属性。
- 长度域解码器特有属性。
// 长度字段的偏移量,也就是存放长度数据的起始位置
private final int lengthFieldOffset;
// 长度字段所占用的字节数
private final int lengthFieldLength;
/*
* 消息长度的修正值
*
* 在很多较为复杂一些的协议设计中,长度域不仅仅包含消息的长度,而且包含其他的数据,如版本号、数据类型、数据状态等,那么这时候我们需要使用 lengthAdjustment 进行修正
*
* lengthAdjustment = 包体的长度值 - 长度域的值
*
*/
private final int lengthAdjustment;
// 解码后需要跳过的初始字节数,也就是消息内容字段的起始位置
private final int initialBytesToStrip;
// 长度字段结束的偏移量,lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength
private final int lengthFieldEndOffset;
- 与固定长度解码器和特定分隔符解码器相似的属性。
private final int maxFrameLength; // 报文最大限制长度
private final boolean failFast; // 是否立即抛出 TooLongFrameException,与 maxFrameLength 搭配使用
private boolean discardingTooLongFrame; // 是否处于丢弃模式
private long tooLongFrameLength; // 需要丢弃的字节数
private long bytesToDiscard; // 累计丢弃的字节数
下面我们结合具体的示例来解释下每种参数的组合,其实在 Netty LengthFieldBasedFrameDecoder 源码的注释中已经描述得非常详细,一共给出了 7 个场景示例,理解了这些示例基本上可以真正掌握 LengthFieldBasedFrameDecoder 的参数用法。
示例 1:典型的基于消息长度 + 消息内容的解码。
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000C | "HELLO, WORLD" | | 0x000C | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
上述协议是最基本的格式,报文只包含消息长度 Length 和消息内容 Content 字段,其中 Length 为 16 进制表示,共占用 2 字节,Length 的值 0x000C 代表 Content 占用 12 字节。该协议对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 0,解码后内容依然是 Length + Content,不需要跳过任何初始字节。
示例 2:解码结果需要截断。
BEFORE DECODE (14 bytes) AFTER DECODE (12 bytes)
+--------+----------------+ +----------------+
| Length | Actual Content |----->| Actual Content |
| 0x000C | "HELLO, WORLD" | | "HELLO, WORLD" |
+--------+----------------+ +----------------+
示例 2 和示例 1 的区别在于解码后的结果只包含消息内容,其他的部分是不变的。该协议对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 2,跳过 Length 字段的字节长度,解码后 ByteBuf 中只包含 Content字段。
示例 3:长度字段包含消息长度和消息内容所占的字节。
BEFORE DECODE (14 bytes) AFTER DECODE (14 bytes)
+--------+----------------+ +--------+----------------+
| Length | Actual Content |----->| Length | Actual Content |
| 0x000E | "HELLO, WORLD" | | 0x000E | "HELLO, WORLD" |
+--------+----------------+ +--------+----------------+
与前两个示例不同的是,示例 3 的 Length 字段包含 Length 字段自身的固定长度以及 Content 字段所占用的字节数,Length 的值为 0x000E(2 + 12 = 14 字节),在 Length 字段值(14 字节)的基础上做 lengthAdjustment(-2)的修正,才能得到真实的 Content 字段长度,所以对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = -2,长度字段为 14 字节,需要减 2 才是拆包所需要的长度。
- initialBytesToStrip = 0,解码后内容依然是 Length + Content,不需要跳过任何初始字节。
示例 4:基于长度字段偏移的解码。
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Header 1 | Length | Actual Content |----->| Header 1 | Length | Actual Content |
| 0xCAFE | 0x00000C | "HELLO, WORLD" | | 0xCAFE | 0x00000C | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
示例 4 中 Length 字段不再是报文的起始位置,Length 字段的值为 0x00000C,表示 Content 字段占用 12 字节,该协议对应的解码器参数组合如下:
- lengthFieldOffset = 2,需要跳过 Header 1 所占用的 2 字节,才是 Length 的起始位置。
- lengthFieldLength = 3,协议设计的固定长度。
- lengthAdjustment = 0,Length 字段只包含消息长度,不需要做任何修正。
- initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。
示例 5:长度字段与内容字段不再相邻。
BEFORE DECODE (17 bytes) AFTER DECODE (17 bytes)
+----------+----------+----------------+ +----------+----------+----------------+
| Length | Header 1 | Actual Content |----->| Length | Header 1 | Actual Content |
| 0x00000C | 0xCAFE | "HELLO, WORLD" | | 0x00000C | 0xCAFE | "HELLO, WORLD" |
+----------+----------+----------------+ +----------+----------+----------------+
示例 5 中的 Length 字段之后是 Header 1,Length 与 Content 字段不再相邻。Length 字段所表示的内容略过了 Header 1 字段,所以也需要通过 lengthAdjustment 修正才能得到 Header + Content 的内容。示例 5 所对应的解码器参数组合如下:
- lengthFieldOffset = 0,因为 Length 字段就在报文的开始位置。
- lengthFieldLength = 3,协议设计的固定长度。
- lengthAdjustment = 2,由于 Header + Content 一共占用 2 + 12 = 14 字节,所以 Length 字段值(12 字节)加上 lengthAdjustment(2 字节)才能得到 Header + Content 的内容(14 字节)。
- initialBytesToStrip = 0,解码后内容依然是完整的报文,不需要跳过任何初始字节。
示例 6:基于长度偏移和长度修正的解码。
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
示例 6 中 Length 字段前后分为别 HDR1 和 HDR2 字段,各占用 1 字节,所以既需要做长度字段的偏移,也需要做 lengthAdjustment 修正,具体修正的过程与 示例 5 类似。对应的解码器参数组合如下:
- lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = 1,由于 HDR2 + Content 一共占用 1 + 12 = 13 字节,所以 Length 字段值(12 字节)加上 lengthAdjustment(1)才能得到 HDR2 + Content 的内容(13 字节)。
- initialBytesToStrip = 3,解码后跳过 HDR1 和 Length 字段,共占用 3 字节。
示例 7:长度字段包含除 Content 外的多个其他字段。
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x0010 | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
示例 7 与 示例 6 的区别在于 Length 字段记录了整个报文的长度,包含 Length 自身所占字节、HDR1 、HDR2 以及 Content 字段的长度,解码器需要知道如何进行 lengthAdjustment 调整,才能得到 HDR2 和 Content 的内容。所以我们可以采用如下的解码器参数组合:
- lengthFieldOffset = 1,需要跳过 HDR1 所占用的 1 字节,才是 Length 的起始位置。
- lengthFieldLength = 2,协议设计的固定长度。
- lengthAdjustment = -3,Length 字段值(16 字节)需要减去 HDR1(1 字节) 和 Length 自身所占字节长度(2 字节)才能得到 HDR2 和 Content 的内容(1 + 12 = 13 字节)。
- initialBytesToStrip = 3,解码后跳过 HDR1 和 Length 字段,共占用 3 字节。
以上 7 种示例涵盖了 LengthFieldBasedFrameDecoder 大部分的使用场景,你是否学会了呢?最后留一个小任务,在上一节课程中我们设计了一个较为通用的协议,如下所示。如何使用长度域解码器 LengthFieldBasedFrameDecoder 完成该协议的解码呢?抓紧自己尝试下吧。
+---------------------------------------------------------------+
| 魔数 2byte | 协议版本号 1byte | 序列化算法 1byte | 报文类型 1byte |
+---------------------------------------------------------------+
| 状态 1byte | 保留字段 4byte | 数据长度 4byte |
+---------------------------------------------------------------+
| 数据内容 (长度不定) |
+---------------------------------------------------------------+
总结
本节课我们介绍了三种常用的解码器,从中我们可以体会到 Netty 在设计上的优雅,只需要调整参数就可以轻松实现各种功能。在健壮性上,Netty 也考虑得非常全面,很多边界情况 Netty 都贴心地增加了保护性措施。实现一个健壮的解码器并不容易,很可能因为一次解析错误就会导致解码器一直处理错乱的状态。如果你使用了基于长度编码的二进制协议,那么推荐你使用 LengthFieldBasedFrameDecoder,它已经可以满足实际项目中的大部分场景,基本不需要再自定义实现了。希望朋友们在项目开发中能够学以致用。
09 数据传输:writeAndFlush 处理流程剖析
在前面几节课我们介绍了 Netty 编解码的基础知识,想必你已经掌握了 Netty 实现编解码逻辑的技巧。那么接下来我们如何将编解码后的结果发送出去呢?在 Netty 中实现数据发送非常简单,只需要调用 writeAndFlush 方法即可,这么简单的一行代码究竟 Netty 帮我们完成了哪些事情呢?一起进入我们今天这节课要探讨的主题吧!
Pipeline 事件传播回顾
在介绍 writeAndFlush 的工作原理之前,我们首先回顾下 Pipeline 的事件传播机制,因为他们是息息相关的。根据网络数据的流向,ChannelPipeline 分为入站 ChannelInboundHandler 和出站 ChannelOutboundHandler 两种处理器,如下图所示。

当我们从客户端向服务端发送请求,或者服务端向客户端响应请求结果都属于出站处理器 ChannelOutboundHandler 的行为,所以当我们调用 writeAndFlush 时,数据一定会在 Pipeline 中进行传播。
在这里我首先抛出几个问题,学完本节课后可以用于检验下自己是否真的理解了 writeAndFlush 的原理。
- writeAndFlush 是如何触发事件传播的?数据是怎样写到 Socket 底层的?
- 为什么会有 write 和 flush 两个动作?执行 flush 之前数据是如何存储的?
- writeAndFlush 是同步还是异步?它是线程安全的吗?
writeAndFlush 事件传播分析
为了便于我们分析 writeAndFlush 的事件传播流程,首先我们通过代码模拟一个最简单的数据出站场景,服务端在接收到客户端的请求后,将响应结果编码后写回客户端。
以下是服务端的启动类,分别注册了三个 ChannelHandler:固定长度解码器 FixedLengthFrameDecoder、响应结果编码器 ResponseSampleEncoder、业务逻辑处理器 RequestSampleHandler。
public class EchoServer {
public void startEchoServer(int port) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ch.pipeline().addLast(new FixedLengthFrameDecoder(10));
ch.pipeline().addLast(new ResponseSampleEncoder());
ch.pipeline().addLast(new RequestSampleHandler());
}
});
ChannelFuture f = b.bind(port).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws Exception {
new EchoServer().startEchoServer(8088);
}
}
其中固定长度解码器 FixedLengthFrameDecoder 是 Netty 自带的解码器,在这里就不做赘述了。下面我们分别看下另外两个 ChannelHandler 的具体实现。
响应结果编码器 ResponseSampleEncoder 用于将服务端的处理结果进行编码,具体的实现逻辑如下:
public class ResponseSampleEncoder extends MessageToByteEncoder<ResponseSample> {
@Override
protected void encode(ChannelHandlerContext ctx, ResponseSample msg, ByteBuf out) {
if (msg != null) {
out.writeBytes(msg.getCode().getBytes());
out.writeBytes(msg.getData().getBytes());
out.writeLong(msg.getTimestamp());
}
}
}
RequestSampleHandler 主要负责客户端的数据处理,并通过调用 ctx.channel().writeAndFlush 向客户端返回 ResponseSample 对象,其中包含返回码、响应数据以及时间戳。
public class RequestSampleHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
String data = ((ByteBuf) msg).toString(CharsetUtil.UTF_8);
ResponseSample response = new ResponseSample("OK", data, System.currentTimeMillis());
ctx.channel().writeAndFlush(response);
}
}
通过以上的代码示例我们可以描绘出 Pipeline 的链表结构,如下图所示。

那么当 RequestSampleHandler 调用 writeAndFlush 时,数据是如何在 Pipeline 中传播、处理并向客户端发送的呢?下面我们结合该场景对 writeAndFlush 的处理流程做深入的分析。
既然 writeAndFlush 是特有的出站操作,那么我们猜测它是从 Pipeline 的 Tail 节点开始传播的,然后一直向前传播到 Head 节点。我们跟进去 ctx.channel().writeAndFlush 的源码,如下所示,发现 DefaultChannelPipeline 类中果然是调用的 Tail 节点 writeAndFlush 方法。
@Override
public final ChannelFuture writeAndFlush(Object msg) {
return tail.writeAndFlush(msg);
}
继续跟进 tail.writeAndFlush 的源码,最终会定位到 AbstractChannelHandlerContext 中的 write 方法。该方法是 writeAndFlush 的核心逻辑,具体见以下源码。
private void write(Object msg, boolean flush, ChannelPromise promise) {
// ...... 省略部分非核心代码 ...... // 找到 Pipeline 链表中下一个 Outbound 类型的 ChannelHandler 节点
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
// 判断当前线程是否是 NioEventLoop 中的线程
if (executor.inEventLoop()) {
if (flush) {
// 因为 flush == true,所以流程走到这里
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
final AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
if (!safeExecute(executor, task, promise, m)) {
task.cancel();
}
}
}
首先我们确认下方法的入参,因为我们需要执行 flush 动作,所以 flush == true;write 方法还需要 ChannelPromise 参数,可见写操作是个异步的过程。AbstractChannelHandlerContext 会默认初始化一个 ChannelPromise 完成该异步操作,ChannelPromise 内部持有当前的 Channel 和 EventLoop,此外你可以向 ChannelPromise 中注册回调监听 listener 来获得异步操作的结果。
write 方法的核心逻辑主要分为三个重要步骤,我已经以注释的形式在源码中标注出来。下面我们将结合上文中的 EchoServer 代码示例详细分析 write 方法的执行机制。
第一步,调用 findContextOutbound 方法找到 Pipeline 链表中下一个 Outbound 类型的 ChannelHandler。在我们模拟的场景中下一个 Outbound 节点是 ResponseSampleEncoder。
第二步,通过 inEventLoop 方法判断当前线程的身份标识,如果当前线程和 EventLoop 分配给当前 Channel 的线程是同一个线程的话,那么所提交的任务将被立即执行。否则当前的操作将被封装成一个 Task 放入到 EventLoop 的任务队列,稍后执行。所以 writeAndFlush 是否是线程安全的呢,你心里有答案了吗?
第三步,因为 flush== true,将会直接执行 next.invokeWriteAndFlush(m, promise) 这行代码,我们跟进去源码。发现最终会它会执行下一个 ChannelHandler 节点的 write 方法,那么流程又回到了 到 AbstractChannelHandlerContext 中重复执行 write 方法,继续寻找下一个 Outbound 节点。
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
为什么 ResponseSampleEncoder 中重写的是 encode 方法,而不是 write 方法?encode 方法又是什么时机被执行的呢?这就回到了《Netty 如何实现自定义通信协议》课程中所介绍的 MessageToByteEncoder 源码。因为我们在实现编码器的时候都会继承 MessageToByteEncoder 抽象类,MessageToByteEncoder 重写了 ChanneOutboundHandler 的 write 方法,其中会调用子类实现的 encode 方法完成数据编码,在这里我们不再赘述。
到目前为止,writeAndFlush 的事件传播流程已经分析完毕,可以看出 Netty 的 Pipeline 设计非常精妙,调用 writeAndFlush 时数据是在 Outbound 类型的 ChannelHandler 节点之间进行传播,那么最终数据是如何写到 Socket 底层的呢?我们一起继续向下分析吧。
写 Buffer 队列
通过上述场景示例分析,我们知道数据将会在 Pipeline 中一直寻找 Outbound 节点并向前传播,直到 Head 节点结束,由 Head 节点完成最后的数据发送。所以 Pipeline 中的 Head 节点在完成 writeAndFlush 过程中扮演着重要的角色。我们直接看下 Head 节点的 write 方法源码:
// HeadContext # write
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
unsafe.write(msg, promise);
}
// AbstractChannel # AbstractUnsafe # write
@Override
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
safeSetFailure(promise, newClosedChannelException(initialCloseCause));
ReferenceCountUtil.release(msg);
return;
}
int size;
try {
msg = filterOutboundMessage(msg); // 过滤消息
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
safeSetFailure(promise, t);
ReferenceCountUtil.release(msg);
return;
}
outboundBuffer.addMessage(msg, size, promise); // 向 Buffer 中添加数据
}
可以看出 Head 节点是通过调用 unsafe 对象完成数据写入的,unsafe 对应的是 NioSocketChannelUnsafe 对象实例,最终调用到 AbstractChannel 中的 write 方法,该方法有两个重要的点需要指出:
- filterOutboundMessage 方法会对待写入的 msg 进行过滤,如果 msg 使用的不是 DirectByteBuf,那么它会将 msg 转换成 DirectByteBuf。
- ChannelOutboundBuffer 可以理解为一个缓存结构,从源码最后一行 outboundBuffer.addMessage 可以看出是在向这个缓存中添加数据,所以 ChannelOutboundBuffer 才是理解数据发送的关键。
writeAndFlush 主要分为两个步骤,write 和 flush。通过上面的分析可以看出只调用 write 方法,数据并不会被真正发送出去,而是存储在 ChannelOutboundBuffer 的缓存内。下面我们重点分析一下 ChannelOutboundBuffer 的内部构造,跟进一下 addMessage 的源码:
public void addMessage(Object msg, int size, ChannelPromise promise) {
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
if (tailEntry == null) {
flushedEntry = null;
} else {
Entry tail = tailEntry;
tail.next = entry;
}
tailEntry = entry;
if (unflushedEntry == null) {
unflushedEntry = entry;
}
incrementPendingOutboundBytes(entry.pendingSize, false);
}
ChannelOutboundBuffer 缓存是一个链表结构,每次传入的数据都会被封装成一个 Entry 对象添加到链表中。ChannelOutboundBuffer 包含三个非常重要的指针:第一个被写到缓冲区的节点 flushedEntry、第一个未被写到缓冲区的节点 unflushedEntry和最后一个节点 tailEntry。
在初始状态下这三个指针都指向 NULL,当我们每次调用 write 方法是,都会调用 addMessage 方法改变这三个指针的指向,可以参考下图理解指针的移动过程会更加形象。

第一次调用 write,因为链表里只有一个数据,所以 unflushedEntry 和 tailEntry 指针都指向第一个添加的数据 msg1。flushedEntry 指针在没有触发 flush 动作时会一直指向 NULL。
第二次调用 write,tailEntry 指针会指向新加入的 msg2,unflushedEntry 保持不变。
第 N 次调用 write,tailEntry 指针会不断指向新加入的 msgN,unflushedEntry 依然保持不变,unflushedEntry 和 tailEntry 指针之间的数据都是未写入 Socket 缓冲区的。
以上便是写 Buffer 队列写入数据的实现原理,但是我们不可能一直向缓存中写入数据,所以 addMessage 方法中每次写入数据后都会调用 incrementPendingOutboundBytes 方法判断缓存的水位线,具体源码如下。
private static final int DEFAULT_LOW_WATER_MARK = 32 * 1024;
private static final int DEFAULT_HIGH_WATER_MARK = 64 * 1024;
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
} long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
// 判断缓存大小是否超过高水位线
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
setUnwritable(invokeLater);
}
}
incrementPendingOutboundBytes 的逻辑非常简单,每次添加数据时都会累加数据的字节数,然后判断缓存大小是否超过所设置的高水位线 64KB,如果超过了高水位,那么 Channel 会被设置为不可写状态。直到缓存的数据大小低于低水位线 32KB 以后,Channel 才恢复成可写状态。
有关写数据的逻辑已经分析完了,那么执行 flush 动作缓存又会是什么变化呢?我们接下来一起看下 flush 的工作原理吧。
刷新 Buffer 队列
当执行完 write 写操作之后,invokeFlush0 会触发 flush 动作,与 write 方法类似,flush 方法同样会从 Tail 节点开始传播到 Head 节点,同样我们跟进下 HeadContext 的 flush 源码:
// HeadContext # flush
@Override
public void flush(ChannelHandlerContext ctx) {
unsafe.flush();
}
// AbstractChannel # flush
@Override
public final void flush() {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
if (outboundBuffer == null) {
return;
}
outboundBuffer.addFlush();
flush0();
}
可以看出 flush 的核心逻辑主要分为两个步骤:addFlush 和 flush0,下面我们逐一对它们进行分析。
首先看下 addFlush 方法的源码:
// ChannelOutboundBuffer # addFlush
public void addFlush() {
Entry entry = unflushedEntry;
if (entry != null) {
if (flushedEntry == null) {
flushedEntry = entry;
}
do {
flushed ++;
if (!entry.promise.setUncancellable()) {
int pending = entry.cancel();
// 减去待发送的数据,如果总字节数低于低水位,那么 Channel 将变为可写状态
decrementPendingOutboundBytes(pending, false, true);
}
entry = entry.next;
} while (entry != null);
unflushedEntry = null;
}
}
addFlush 方法同样也会操作 ChannelOutboundBuffer 缓存数据。在执行 addFlush 方法时,缓存中的指针变化又是如何呢?如下图所示,我们在写入流程的基础上继续进行分析。

此时 flushedEntry 指针有所改变,变更为 unflushedEntry 指针所指向的数据,然后 unflushedEntry 指针指向 NULL,flushedEntry 指针指向的数据才会被真正发送到 Socket 缓冲区。
在 addFlush 源码中 decrementPendingOutboundBytes 与之前 addMessage 源码中的 incrementPendingOutboundBytes 是相对应的。decrementPendingOutboundBytes 主要作用是减去待发送的数据字节,如果缓存的大小已经小于低水位,那么 Channel 会恢复为可写状态。
addFlush 的大体流程我们已经介绍完毕,接下来便是第二步负责发送数据的 flush0 方法。同样我们跟进 flush0 的源码,定位出 flush0 的核心调用链路:
// AbstractNioUnsafe # flush0
@Override
protected final void flush0() {
if (!isFlushPending()) {
super.flush0();
}
}
// AbstractNioByteChannel # doWrite
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
int writeSpinCount = config().getWriteSpinCount();
do {
Object msg = in.current();
if (msg == null) {
clearOpWrite();
return;
}
writeSpinCount -= doWriteInternal(in, msg);
} while (writeSpinCount > 0);
incompleteWrite(writeSpinCount < 0);
}
实际 flush0 的调用层次很深,但其实核心的逻辑在于 AbstractNioByteChannel 的 doWrite 方法,该方法负责将数据真正写入到 Socket 缓冲区。doWrite 方法的处理流程主要分为三步:
第一,根据配置获取自旋锁的次数 writeSpinCount。那么你的疑问就来了,这个自旋锁的次数主要是用来干什么的呢?当我们向 Socket 底层写数据的时候,如果每次要写入的数据量很大,是不可能一次将数据写完的,所以只能分批写入。Netty 在不断调用执行写入逻辑的时候,EventLoop 线程可能一直在等待,这样有可能会阻塞其他事件处理。所以这里自旋锁的次数相当于控制一次写入数据的最大的循环执行次数,如果超过所设置的自旋锁次数,那么写操作将会被暂时中断。
第二,根据自旋锁次数重复调用 doWriteInternal 方法发送数据,每成功发送一次数据,自旋锁的次数 writeSpinCount 减 1,当 writeSpinCount 耗尽,那么 doWrite 操作将会被暂时中断。doWriteInternal 的源码涉及 JDK NIO 底层,在这里我们不再深入展开,它的主要作用在于删除缓存中的链表节点以及调用底层 API 发送数据,有兴趣的同学可以自行研究。
第三,调用 incompleteWrite 方法确保数据能够全部发送出去,因为自旋锁次数的限制,可能数据并没有写完,所以需要继续 OP_WRITE 事件;如果数据已经写完,清除 OP_WRITE 事件即可。
至此,整个 writeAndFlush 的工作原理已经全部分析完了,整个过程的调用层次比较深,我整理了 writeAndFlush 的时序图,如下所示,帮助大家梳理 writeAndFlush 的调用流程,加深对上述知识点的理解。

总结
本节课我们深入分析了 writeAndFlush 的处理流程,可以总结以下三点:
- writeAndFlush 属于出站操作,它是从 Pipeline 的 Tail 节点开始进行事件传播,一直向前传播到 Head 节点。不管在 write 还是 flush 过程,Head 节点都中扮演着重要的角色。
- write 方法并没有将数据写入 Socket 缓冲区,只是将数据写入到 ChannelOutboundBuffer 缓存中,ChannelOutboundBuffer 缓存内部是由单向链表实现的。
- flush 方法才最终将数据写入到 Socket 缓冲区。
最后,留一个小的思考题,Channel 和 ChannelHandlerContext 都有 writeAndFlush 方法,它们之间有什么区别呢?
10 双刃剑:合理管理 Netty 堆外内存
本节课我们将进入 Netty 内存管理的课程学习,在此之前,我们需要了解 Java 堆外内存的基本知识,因为当你在使用 Netty 时,需要时刻与堆外内存打交道。我们经常看到各类堆外内存泄漏的排查案例,堆外内存使用不当会使得应用出错、崩溃的概率变大,所以在使用堆外内存时一定要慎重,本节课我将带你一起认识堆外内存,并探讨如何更好地使用它。
为什么需要堆外内存
在 Java 中对象都是在堆内分配的,通常我们说的JVM 内存也就指的堆内内存,堆内内存完全被JVM 虚拟机所管理,JVM 有自己的垃圾回收算法,对于使用者来说不必关心对象的内存如何回收。
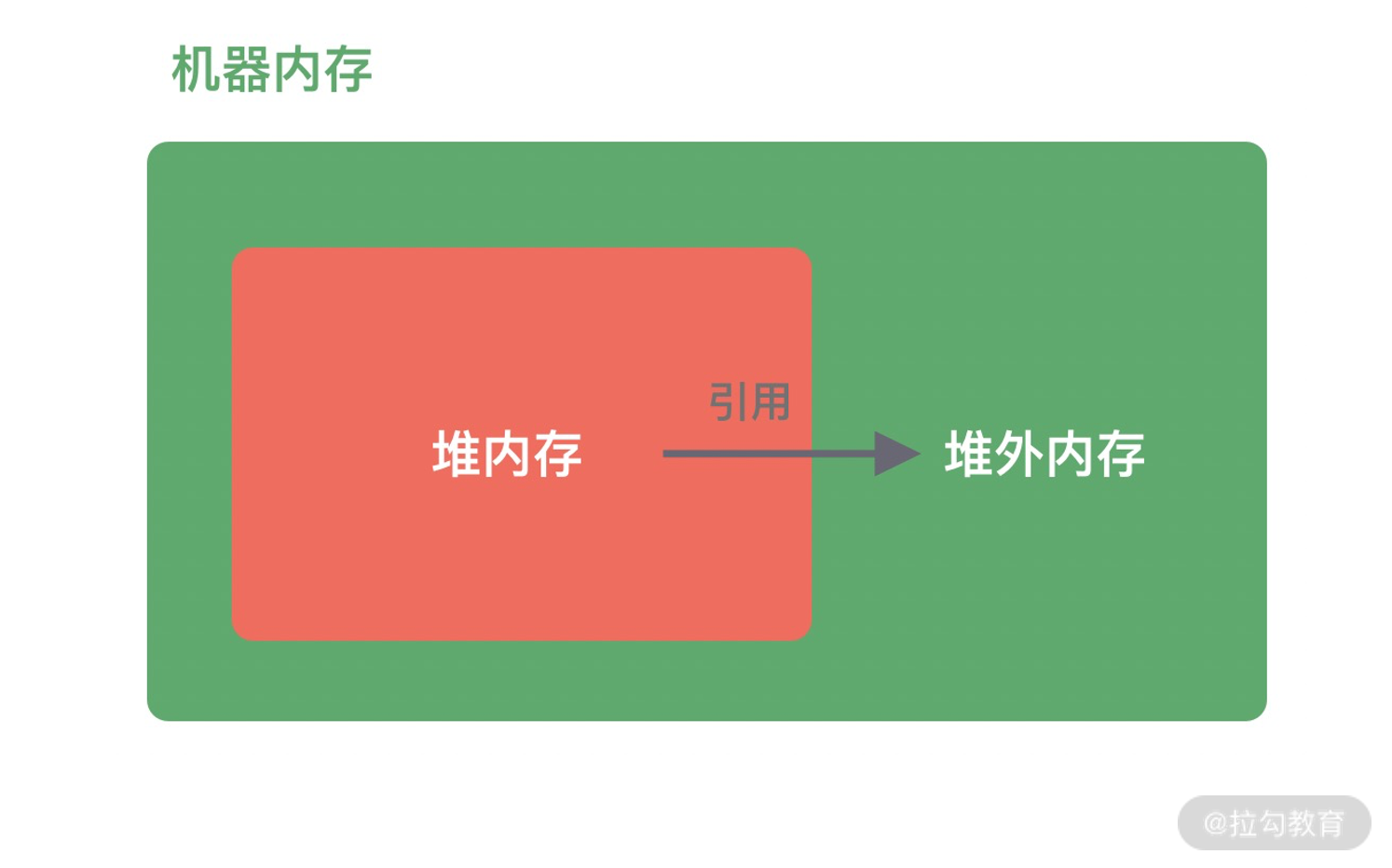
堆外内存与堆内内存相对应,对于整个机器内存而言,除堆内内存以外部分即为堆外内存,如下图所示。堆外内存不受 JVM 虚拟机管理,直接由操作系统管理。
堆外内存和堆内内存各有利弊,这里我针对其中重要的几点进行说明。
- 堆内内存由 JVM GC 自动回收内存,降低了 Java 用户的使用心智,但是 GC 是需要时间开销成本的,堆外内存由于不受 JVM 管理,所以在一定程度上可以降低 GC 对应用运行时带来的影响。
- 堆外内存需要手动释放,这一点跟 C/C++ 很像,稍有不慎就会造成应用程序内存泄漏,当出现内存泄漏问题时排查起来会相对困难。
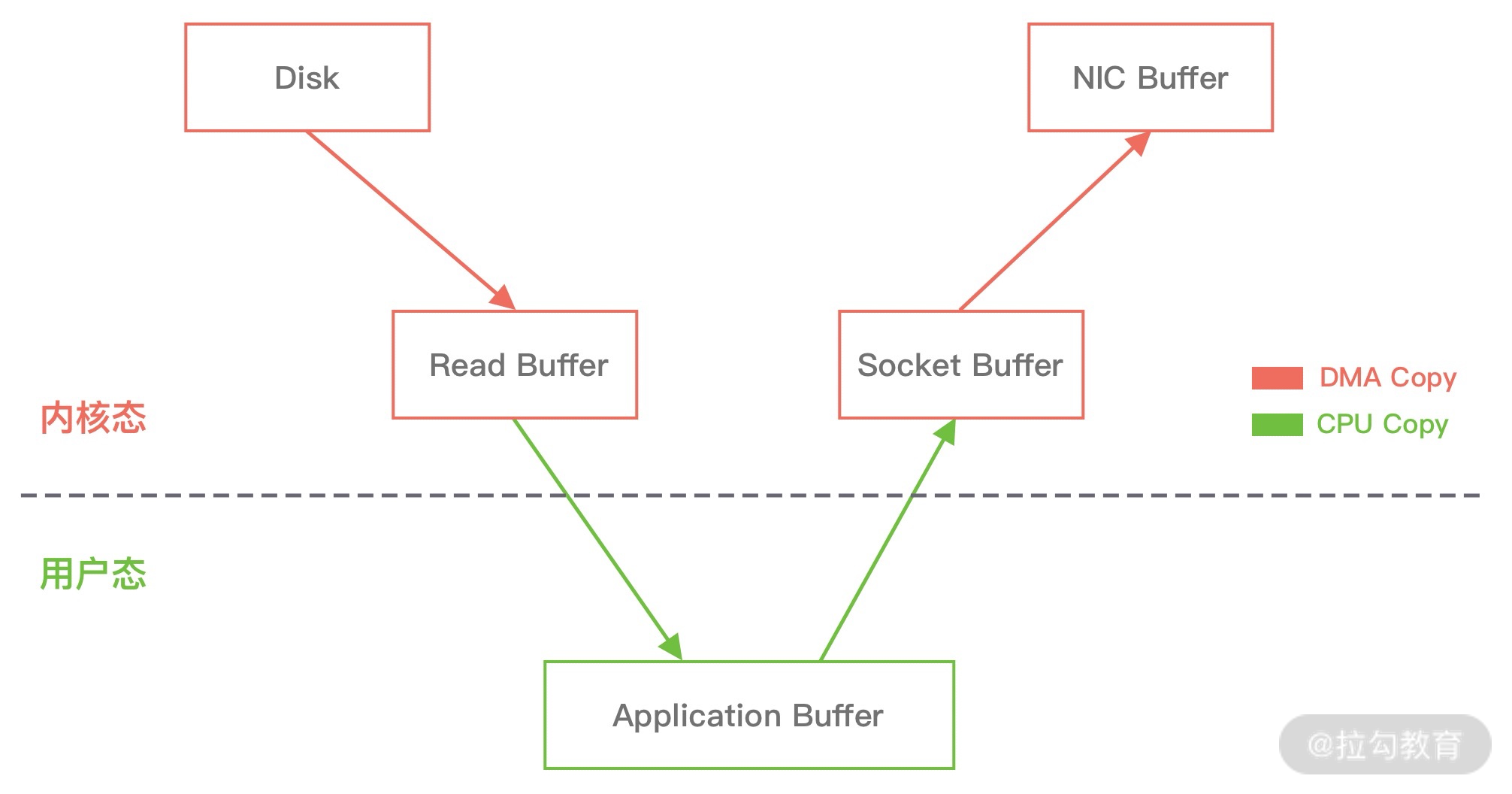
- 当进行网络 I/O 操作、文件读写时,堆内内存都需要转换为堆外内存,然后再与底层设备进行交互,这一点在介绍 writeAndFlush 的工作原理中也有提到,所以直接使用堆外内存可以减少一次内存拷贝。
- 堆外内存可以实现进程之间、JVM 多实例之间的数据共享。
由此可以看出,如果你想实现高效的 I/O 操作、缓存常用的对象、降低 JVM GC 压力,堆外内存是一个非常不错的选择。
堆外内存的分配
Java 中堆外内存的分配方式有两种:ByteBuffer#allocateDirect和Unsafe#allocateMemory。
首先我们介绍下 Java NIO 包中的 ByteBuffer 类的分配方式,使用方式如下:
// 分配 10M 堆外内存
ByteBuffer buffer = ByteBuffer.allocateDirect(10 * 1024 * 1024);
跟进 ByteBuffer.allocateDirect 源码,发现其中直接调用的 DirectByteBuffer 构造函数:
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
如下图所示,描述了 DirectByteBuffer 的内存引用情况,方便你更好地理解上述源码的初始化过程。在堆内存放的 DirectByteBuffer 对象并不大,仅仅包含堆外内存的地址、大小等属性,同时还会创建对应的 Cleaner 对象,通过 ByteBuffer 分配的堆外内存不需要手动回收,它可以被 JVM 自动回收。当堆内的 DirectByteBuffer 对象被 GC 回收时,Cleaner 就会用于回收对应的堆外内存。

从 DirectByteBuffer 的构造函数中可以看出,真正分配堆外内存的逻辑还是通过 unsafe.allocateMemory(size),接下来我们一起认识下 Unsafe 这个神秘的工具类。
Unsafe 是一个非常不安全的类,它用于执行内存访问、分配、修改等敏感操作,可以越过 JVM 限制的枷锁。Unsafe 最初并不是为开发者设计的,使用它时虽然可以获取对底层资源的控制权,但也失去了安全性的保证,所以使用 Unsafe 一定要慎重。Netty 中依赖了 Unsafe 工具类,是因为 Netty 需要与底层 Socket 进行交互,Unsafe 在提升 Netty 的性能方面起到了一定的帮助。
在 Java 中是不能直接使用 Unsafe 的,但是我们可以通过反射获取 Unsafe 实例,使用方式如下所示。
private static Unsafe unsafe = null;
static {
try {
Field getUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
getUnsafe.setAccessible(true);
unsafe = (Unsafe) getUnsafe.get(null);
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
获得 Unsafe 实例后,我们可以通过 allocateMemory 方法分配堆外内存,allocateMemory 方法返回的是内存地址,使用方法如下所示:
// 分配 10M 堆外内存
long address = unsafe.allocateMemory(10 * 1024 * 1024);
与 DirectByteBuffer 不同的是,Unsafe#allocateMemory 所分配的内存必须自己手动释放,否则会造成内存泄漏,这也是 Unsafe 不安全的体现。Unsafe 同样提供了内存释放的操作:
unsafe.freeMemory(address);
到目前为止,我们了解了堆外内存分配的两种方式,对于 Java 开发者而言,常用的是 ByteBuffer.allocateDirect 分配方式,我们平时常说的堆外内存泄漏都与该分配方式有关,接下来我们一起看看使用 ByteBuffer 分配的堆外内存如何被 JVM 回收,这对我们排查堆外内存泄漏问题有较大的帮助。
堆外内存的回收
我们试想这么一种场景,因为 DirectByteBuffer 对象有可能长时间存在于堆内内存,所以它很可能晋升到 JVM 的老年代,所以这时候 DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理。如果长时间没有 Old GC 或者 Full GC 执行,那么堆外内存即使不再使用,也会一直在占用内存不释放,很容易将机器的物理内存耗尽,这是相当危险的。
那么在使用 DirectByteBuffer 时我们如何避免物理内存被耗尽呢?因为 JVM 并不知道堆外内存是不是已经不足了,所以我们最好通过 JVM 参数 -XX:MaxDirectMemorySize 指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收,如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常。
此外在 ByteBuffer.allocateDirect 分配的过程中,如果没有足够的空间分配堆外内存,在 Bits.reserveMemory 方法中也会主动调用 System.gc() 强制执行 Full GC,但是在生产环境一般都是设置了 -XX:+DisableExplicitGC,System.gc() 是不起作用的,所以依赖 System.gc() 并不是一个好办法。
通过前面堆外内存分配方式的介绍,我们知道 DirectByteBuffer 在初始化时会创建一个 Cleaner 对象,它会负责堆外内存的回收工作,那么 Cleaner 是如何与 GC 关联起来的呢?
Java 对象有四种引用方式:强引用 StrongReference、软引用 SoftReference、弱引用 WeakReference 和虚引用 PhantomReference。其中 PhantomReference 是最不常用的一种引用方式,Cleaner 就属于 PhantomReference 的子类,如以下源码所示,PhantomReference 不能被单独使用,需要与引用队列 ReferenceQueue 联合使用。
public class Cleaner extends java.lang.ref.PhantomReference<java.lang.Object> {
private static final java.lang.ref.ReferenceQueue<java.lang.Object> dummyQueue;
private static sun.misc.Cleaner first;
private sun.misc.Cleaner next;
private sun.misc.Cleaner prev;
private final java.lang.Runnable thunk;
public void clean() {}
}
首先我们看下,当初始化堆外内存时,内存中的对象引用情况如下图所示,first 是 Cleaner 类中的静态变量,Cleaner 对象在初始化时会加入 Cleaner 链表中。DirectByteBuffer 对象包含堆外内存的地址、大小以及 Cleaner 对象的引用,ReferenceQueue 用于保存需要回收的 Cleaner 对象。

当发生 GC 时,DirectByteBuffer 对象被回收,内存中的对象引用情况发生了如下变化:
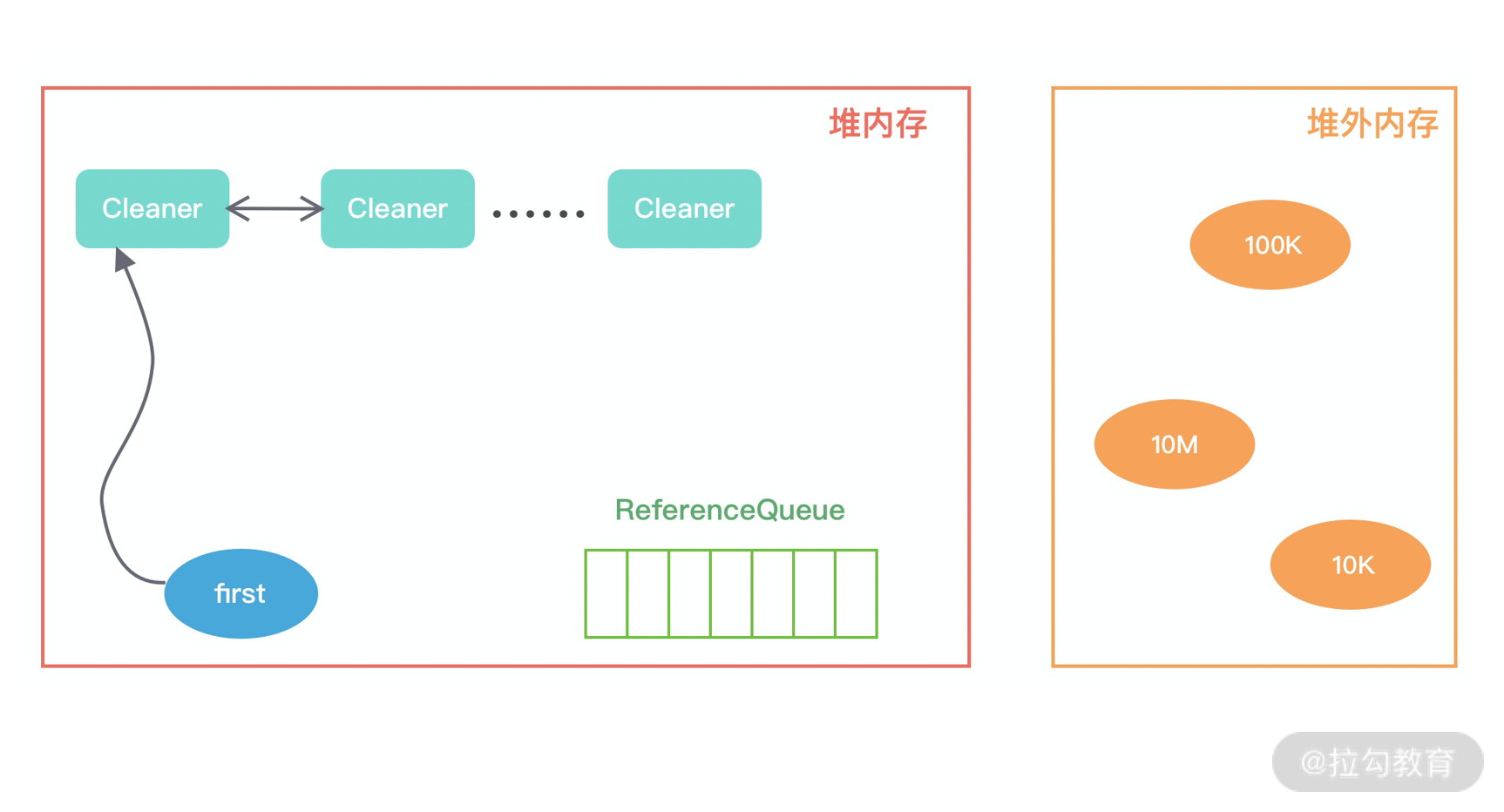
此时 Cleaner 对象不再有任何引用关系,在下一次 GC 时,该 Cleaner 对象将被添加到 ReferenceQueue 中,并执行 clean() 方法。clean() 方法主要做两件事情:
- 将 Cleaner 对象从 Cleaner 链表中移除;
- 调用 unsafe.freeMemory 方法清理堆外内存。
至此,堆外内存的回收已经介绍完了,下次再排查内存泄漏问题的时候先回顾下这些最基本的知识,做到心中有数。
总结
堆外内存是一把双刃剑,在网络 I/O、文件读写、分布式缓存等领域使用堆外内存都更加简单、高效,此外使用堆外内存不受 JVM 约束,可以避免 JVM GC 的压力,降低对业务应用的影响。当然天下没有免费的午餐,堆外内存也不能滥用,使用堆外内存你就需要关注内存回收问题,虽然 JVM 在一定程度上帮助我们实现了堆外内存的自动回收,但我们仍然需要培养类似 C/C++ 的分配/回收的意识,出现内存泄漏问题能够知道如何分析和处理。