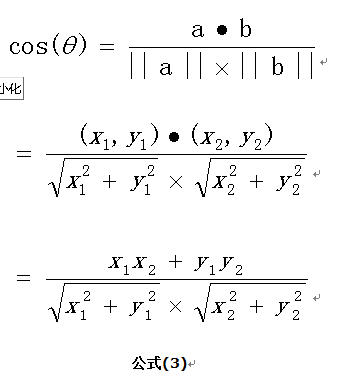一、基础知识扫盲
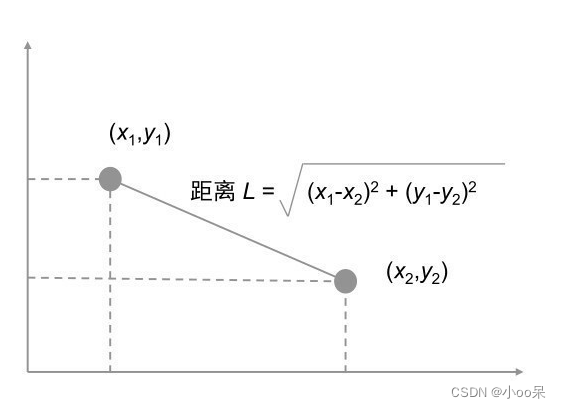
(1)欧式距离
想象你在一个平坦的公园里,看到两个孩子分别在不同的游乐设施上玩耍。你想知道他们之间有多远。直觉的方法就是拉直测量绳,量一下他们直线距离有多远。在数学中,这就是所谓的欧式距离,也就是两点间直线的最短距离。在多维空间中,欧式距离考虑了每个维度的差异,使用勾股定理进行计算。
欧式距离是定义在欧式空间中的两点之间的距离,考虑了向量各维度数值上的差异。对于两个点和
,如果它们在二维空间中的坐标分别是
和
,那么它们之间的欧式距离
可以通过下面的公式计算:
推广到在多维空间(n维)中的公式如下:
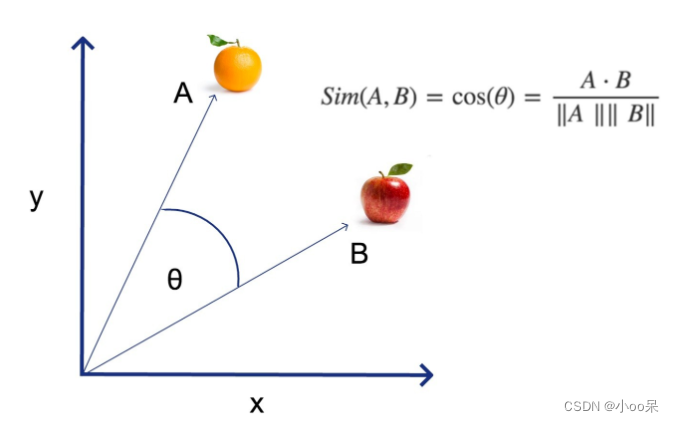
(2)余弦相似度
假设这两个孩子代表了两个人的兴趣向量,他们玩耍的方向代表了他们各自兴趣的方向。即使他们不同的公园玩耍(这意味着他们的欧式距离很远),但他们玩耍的方向可能非常相似。余弦相似度就是用来衡量这两个方向的相似程度,它通过计算夹角的余弦值来忽略兴趣强度的差异,专注于兴趣方向的相似程度。如果夹角接近0度,他们的兴趣非常相似。
余弦相似度是一种衡量两个非零向量在方向上的相似程度的方法,而非它们的长度或规模。它通过计算两个向量的点积除以它们各自的模长乘积来得出。取值范围[-1,1]。对于两个向量和
,它们的余弦相似度
可以用它们的点积和各自范数(或叫向量模长)的乘积来计算:
(3)余弦距离
余弦距离也是用来反映两个向量间的相似性,只是它将相似度转换为了一个距离的概念,值越小代表相似度越高。它是由1减去余弦相似度得到的。如果两个向量完全相同,它们的余弦相似度是1,而余弦距离就是0,代表之间没有距离,完全一致;而如果两个向量完全不同,它们的余弦相似度是0,余弦距离是1,意味着他们完全相反。取值范围[0,2]。
二、为什么要用余弦相似度而不是欧式距离?
(1)举例说明
假设我有三本书A、B和C。现在我们想衡量这三本书的相似程度,为了做到这点,我们需要构建一个特性集合来表示每本书。假设我们已经有了一些用户的书籍评分数据,我们可以基于这些评分来构建特征向量。
又假设我们有五个用户,他们对三本书的评分如下(评分范围从0到5)这五个用户的评分构成了三本书的特征向量:
书A的特征向量: A = [5, 4, 3, 0, 1]
书B的特征向量: B = [3, 0, 4, 2, 0]
书C的特征向量: C = [0, 1, 0, 5, 4]
| 用户 | 书A | 书B | 书C |
|---|---|---|---|
| 1 | 5 | 3 | 0 |
| 2 | 4 | 0 | 1 |
| 3 | 3 | 4 | 0 |
| 4 | 0 | 2 | 5 |
| 5 | 1 | 0 | 4 |
接下来,我们可以使用余弦相似度来衡量这三本书之间的相似度,因为:
- 假设我们用欧式距离来衡量相似度,由于评分数据可能存在较大的尺度差异,会导致欧式距离很大,且我们更关心的是用户对书籍的喜好倾向(即评分方向)而不是评分的绝对值大小。
- 欧式距离还有一个问题:它对评分的绝对值非常敏感,也就是说,哪怕两个书籍被相同的群体阅读,但因为评分的量度不同(一个群体的评分普遍高于另一个群体),使用欧式距离可能会导致得出它们不相似的结论。
- 余弦相似度可以很好地处理这样的特征向量,它关注的是用户对书籍喜好评分上的趋势更为接近,而不考虑每本书被多少人评价过。
(2)欧式距离与余弦相似度的区别
- 欧式距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
- 当一对文本相似度的长度差距很大、但内容很相近时,如果使用词频统计或词向量作为特征,他们在特征空间中的欧式距离通常很大;而如果使用余弦相似度的话,他们之间的夹角可能很小,因而相似度很高
- 在文本、图像、视频领域,研究的对象特征维度往往很高,余弦相似度可以在高维情况下依旧保持“相同为1,正交为0,相反为-1”的性质,而欧式距离的数值则受到维度的影响范围不定,含义也比较模糊
三、余弦相似度一般会用在哪儿?
(1)文本相似性比较
在文本挖掘和自然语言处理中,余弦相似度被用来衡量两份文档在主题或内容上的相似程度。通过比较文档中词汇的频率表现为向量,可以找出含有相似主题的文档。
(2)推荐系统
用户行为数据也可以被转化为向量形式,比如用户的购买历史记录或者对电影、音乐、商品的评分可以形成用户兴趣向量。在这种情况下,计算用户向量和其他用户或商品向量的余弦相似度,可以帮助找到兴趣相似的用户或推荐最匹配的商品。
(3)社交网络分析
在社交网络中,用户的属性和活动可以表示为特征向量,如用户的喜好、朋友关系、发帖内容等。计算用户之间的余弦相似度可以发现具有相似兴趣爱好的用户群体或潜在的朋友关系。
(4)机器翻译和语义分析
在机器翻译中,源语言和目标语言的短语或句子对经过编码后,计算它们之间的余弦相似度有助于评估翻译结果的质量,尤其是在无监督或半监督的学习环境中。通过词嵌入技术,每个单词或短语都可以被转换为一个稠密向量,这些向量的位置隐含了它们在语义空间中的关系。当两个短语或句子被编码为向量后,就可以使用余弦相似度来衡量它们在高维空间中的语义相似性,即它们所指代的意义有多接近。