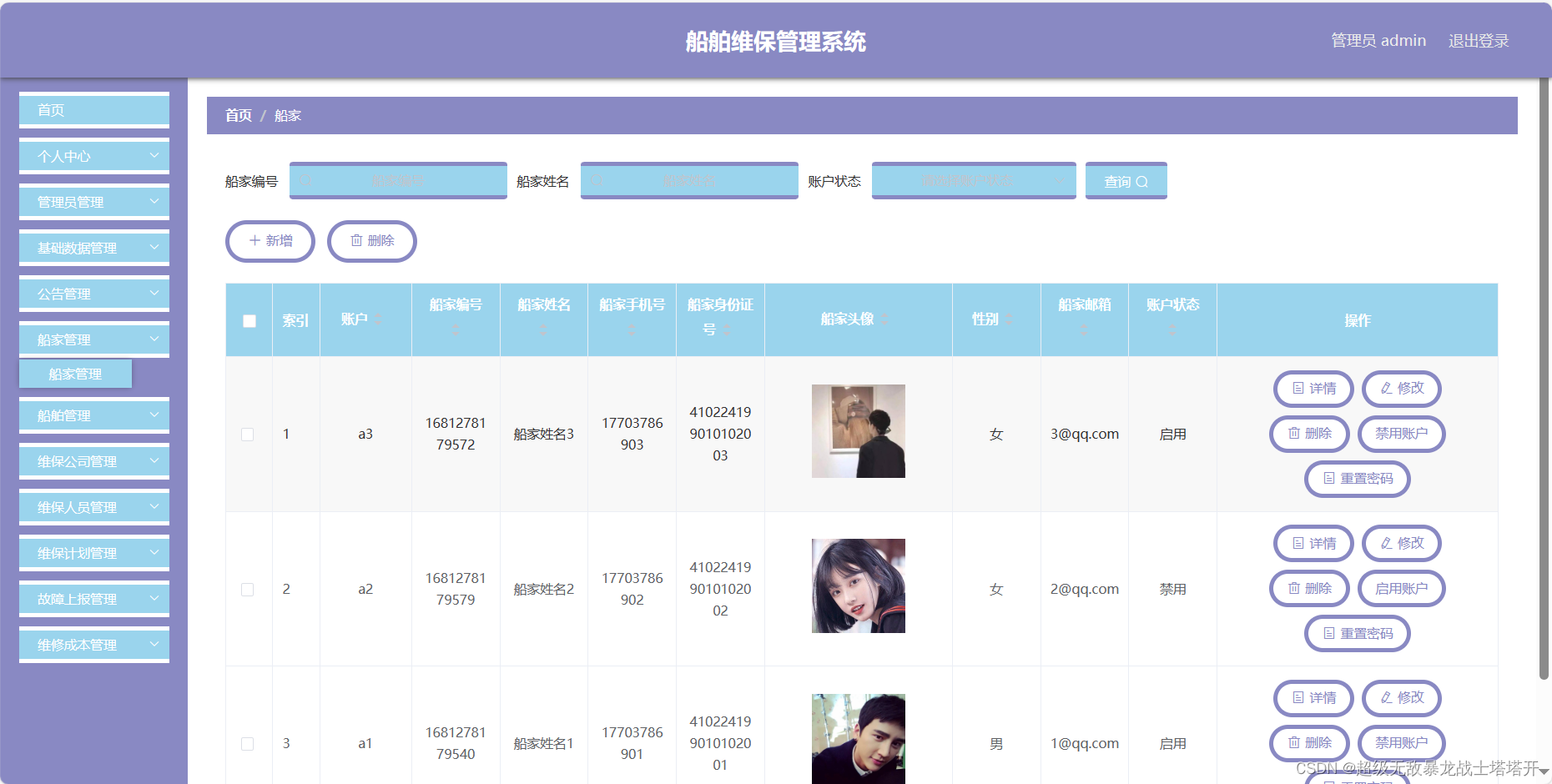
细节3:如何从dataset格式转变到Dataloder?
上面已经获得了huggingface格式的dataset,原则来说,使用 Trainer 时,你可以将 datasets 库中的 Dataset 对象直接作为数据集参数传递给 Trainer。Trainer 类在内部会自动处理数据加载和迭代的细节,包括将 Dataset 转换为 DataLoader。不必显式创建一个 DataLoader,因为Trainer 会根据 Trainer 的参数和 Dataset 的特性来自动创建一个合适的 DataLoader。
但是在本示例中,还是选择手动定义了一个DataLoader。定义DataLoader的代码仍然在/opt/conda/envs/transformers2/lib/python3.9/site-packages/mmengine/runner/runner.py中
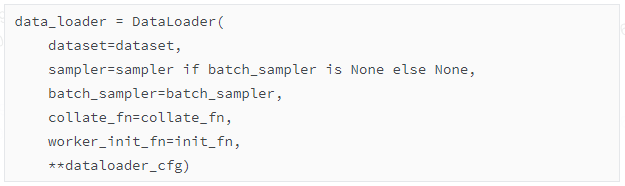
这段代码创建了一个 DataLoader 对象,它是PyTorch中使用的一个非常重要的类,用于高效地加载数据,可以在多线程环境下工作,常见于机器学习和深度学习模型的训练过程中。
下面是代码的参数解释:
dataset: 这是要加载的数据集。在PyTorch中,dataset 通常是一个实现了 __getitem__ 和 __len__ 方法的对象。
sampler: 这个参数定义了从数据集中抽取样本的策略。它能够控制数据加载的顺序等。如果 batch_sampler 被定义,则 sampler 应该为 None,因为 batch_sampler 与 sampler 是互斥的,batch_sampler 直接定义了批量数据的取样方式。
batch_sampler: 这是一个迭代器,用于指定每个批次中哪些索引的数据将被加载。一旦设置了 batch_sampler,则将忽略 sampler 参数。
collate_fn: 当需要将多个数据样本组合成一个批次时,collate_fn 被用来定义如何将这些样本合并。通常,它接收一个样本列表并返回一个批次。如果没有提供 collate_fn,DataLoader 将使用默认的方式将数据组合成批次。
worker_init_fn: 这是一个函数,用于初始化每个工作进程。这可以用于设置在使用多进程加载数据时每个工作进程的随机种子,以确保数据加载顺序的随机化。
**dataloader_cfg: 这个语法表示以字典的形式传递可变数量的关键字参数。dataloader_cfg 是一个字典,包括了 DataLoader 的其他配置选项,如 batch_size(每批次加载的样本数量)、shuffle(是否随机打乱数据)、num_workers(加载数据时使用的进程数量)等。
collate_fn函数的源码位于/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/dataset/collate_fns/defalut_collate_fn.py里
经过DataLoader后,数据的格式长这样:
{'data':
{'input_ids': tensor([[ 265, 539, 2632, ..., 36333, 328, 454]]),
'attention_mask': tensor([[True, True, True, ..., True, True, True]]),
'labels': tensor([[ 265, 539, 2632, ..., 36333, 328, 454]])},
'data_samples': None}
input_ids/attention_mask/labels的shape都是torch.Size([1, 2048])
这里的attention_mask全部是True,因为pack_to_max_length这个步骤,将大部分数据都强行拼凑成2048长度。
训练流程——第四步:将PTH模型转huggingface模型
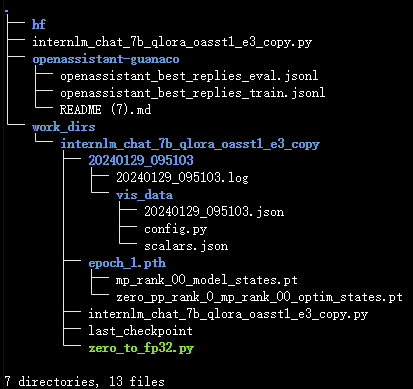
训练好的文件保存在work_dirs路径下。首先查看work_dirs目录的路径结构:

可以看到每一个epoch都会生成一个pth文件。但是我在实际跑了后发现,我这边生成的pth其实是一个文件夹:
目前得到的是pth文件(夹),还不能直接用于推理,需要转成huggingface的模型。转换的命令是:

转换后,hf文件夹里出现了四个文件:
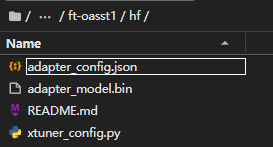
可以这样简单理解:LoRA 模型文件 = Adapter
细节4:转换模型的流程
接下来探究一个细节:模型是如何转换的?接下来debug一下背后的流程。
首先根据命令行的参数,修改launch.json

经过断点测试,可以发现在/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/entry_point.py中的subprocess.run(['python', fn()] + args[n_arg + 1:])
这一行代码中,发现它实际调用了'/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/tools/model_converters/pth_to_hf.py'
于是去pth_to_hf.py函数里打断点,发现以下几个关键步骤。
【关键步骤1】加载模型

以"load_in_4bit": true来加载模型,加载的模型是原模型,即Shanghai_AI_Laboratory/internlm-chat-7b
按道理来说7b模型,如果以4bit来加载,显存占用应该是只有3.5G左右。但是实际占用的显存达到9G。可能有如下几个原因:(1)只有对weight进行了4bit量化,bias仍然是float32格式。(2)lora部分未经过量化,是以float32格式呈现的。
通过以下命令,查询每一层的dtype:

截取其中部分结果:

那么为什么要加载原模型呢?根据命令的参数,发现它只用到了workdirs里面的pth文件。
【关键步骤2】加载pth文件
state_dict = guess_load_checkpoint(args.pth_model)
state_dict是一个OrderedDict对象,里面包含了所有lora的参数(层的名称+具体的参数值)。也就是说,之前微调保存的pth文件,其实保存的是所有的lora参数。这里发现这些参数都是float32的格式。经过简单的统计,发现一共有159907840参数,占总参数量的2%左右。这个占比还是挺高的,我看到q/k/v/o/h_to_4h/4h_to_h里都插入了lora矩阵(target_modules: ['k_proj', 'o_proj', 'q_proj', 'v_proj', 'up_proj', 'down_proj', 'gate_proj'])。
【关键步骤3】将pth文件中的参数覆盖到model里

【关键步骤4】转成float16的格式

截取其中部分结果:

注意,这里只是把之前为fp32格式的参数转成了fp16,之前是4bit格式的参数,并未转成fp16
【关键步骤5】保存模型

注意,这里的save_pretrained方法,是peft的save_pretrained方法。在这个方法中,有这么一步:

这行代码是用来获得整个model中的lora参数的state_dict
然后在下面这行代码中保存了lora的参数,保存的文件名称是adapter_model.bin

总结一下,首先加载整个模型,然后加载之前保存的包含lora的pth文件,将参数覆盖到model模型里。接着将模型转成fp16的格式。最后,将model的lora权重抽出来,进行保存。
我感觉这是不是绕了一个圈呢?可不可以不加载model模型呢?在上面的流程中,lora参数先是被覆盖到model里,后来又从model中抽出lora参数,是不是多此一举呢?
不过我还是发现了一些区别,比如pth文件保存的格式是float32,这里保存的adapter是float16格式,文件大小是319,977,674,大约是lora参数量159,907,840的两倍。
也就是说,在这个convert步骤里,通过pytorch层面的load_state_dict,fp32格式存储的pth文件被转成了fp16格式存储的adapter_model.bin文件。不论是pth文件还是bin文件,都是通过torch.save/torch.load来直接保存和加载的,还没有涉及到PEFT库的内容。
训练流程——第五步:模型合并
经过了pth转hf,目前只生成了adapter,还没有合并模型,即没有将lora旁路合并到主模型上。下面的代码将会将adapter合并到模型中:

第一个参数是basemodel所在的路径
第二个参数是转换成hf格式后所在的路径
第三个参数是转换后的路径
第四个参数是每个文件最大的大小
转换成功后,看到mergerd文件夹下有如下文件:
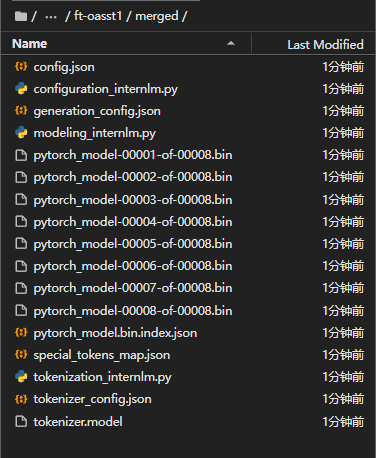
8个bin文件加起来不到16G?为什么7B的模型,占用的存储不是28G,而是16G?难道是以float16存储的?是的,在model.config里可以看到模型参数是float16的格式。
细节5:合并模型的流程
首先根据命令行的参数,修改launch.json

可以看到调用了 '/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/tools/model_converters/merge.py'
于是去merge.py里打断点,发现以下几个关键步骤。
【关键步骤1】加载模型

以float16来加载原模型(因为adapter是以fp16来存储的),加载后,GPU显存大约是14.3G,差不多是参数量的两倍。
截取其中部分结果:
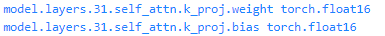
可以看到,此时的模型是没有lora参数的,而且模型的参数是float16的格式。
当然同时也加载了分词器:

这里加载分词器倒不是说合并模型的时候需要用到分词器,而是把分词器一起保存到合并后的模型的保存路径,方便后面一起调用。
【关键步骤2】加载adapter(本步骤涉及对PEFT源码的探索)

使用PeftModel.from_pretrained来加载adapter。注意到有一个参数是model(以fp16格式加载的还没有lora的model),也就是说,加载lora参数的时候,不能脱离model。
点进去这个源码(位于/opt/conda/envs/transformers2/lib/python3.9/site-packages/peft/peft_model.py,这是PEFT库的代码),发现有两行代码比较关键:

【关键步骤2.1】首先解释第一行代码:model = MODEL_TYPE_TO_PEFT_MODEL_MAPPING[config.task_type](
model, config, adapter_name)
其中MODEL_TYPE_TO_PEFT_MODEL_MAPPING[config.task_type]指向了这个类,这个类的源码也是在peft_model.py里。
传入的参数除了model,还有两个,其中config的内容是:
LoraConfig(peft_type='LORA', auto_mapping=None, base_model_name_or_path='.../Intern-models-dirs/Shanghai_AI_Laboratory/internlm-chat-7b', revision=None, task_type='CAUSAL_LM', inference_mode=True, r=64, target_modules=['k_proj', 'o_proj', 'q_proj', 'v_proj', 'up_proj', 'down_proj', 'gate_proj'], lora_alpha=16, lora_dropout=0.1, fan_in_fan_out=False, bias='none', modules_to_save=None, init_lora_weights=True, layers_to_transform=None, layers_pattern=None)
这里的config准确识别到了在微调阶段时用的lora参数是什么,我暂时没有弄明白它是在哪个环节识别到的。
最后一个参数adapter_name的内容是"default"
再回顾下,传入的三个参数分别是model/config/adapter_name。
这行代码是什么意思呢?就是定义了一个PeftModelForCausalLM类的实例,这个实例的名称是model。产生一个PeftModelForCausalLM类的实例,自然要经过PeftModelForCausalLM的__init__方法。由于PeftModelForCausalLM继承于PeftModel类,因此需要经过PeftModel类的__init__方法。在__init__方法中,有一行代码是:

其中PEFT_TYPE_TO_MODEL_MAPPING[peft_config.peft_type]指向了这个类,这一行的代码的意思是产生了一个LoraModel类的实例,这个实例的名称叫做self.base_model,这里的self.base_model在原模型model的基础上,新增并初始化了lora旁路。
self.base_model的部分层如下所示:

进一步打印参数的话(如使用self.model.model.layers[31].mlp.down_proj.lora_B.default.weight命令),可以看到lora_B的所有参数都是0
总结一下:PeftModel类的初始化方法的作用,是给原模型添加adapter,如果peft的类型是lora,那么添加的adapter是lora旁路。添加的旁路的参数是根据一定规则初始化的。
给原模型添加adapter的过程还是比较耗时的,里面的_find_and_replace方法比较复杂,我暂时没有看懂。
还有一个需要注意的点是,此时模型的总参数量是7481856000,比初始的参数量7321948160多159907840,这正是lora部分的参数量。
【关键步骤2.2】然后解释第二行代码:model.load_adapter(model_id, adapter_name, is_trainable=is_trainable, **kwargs)
在经过了关键步骤2.1的第一行代码后,模型里面有lora旁路和参数了,截取模型部分层如下图所示:

此时的lora参数的数据类型是float32。
关键步骤2.2做的是加载adapter[通过torch.load('./hf/adapter_model.bin')命令],把里面的参数覆盖到model里(通过model.load_state_dict命令)。
总结一下,整个关键步骤2,首先将原模型添加了lora旁路,此时lora旁路的参数是随机或者全0初始化的。然后加载adapter,将lora参数覆盖到model里。
截取模型部分层如下图所示:

模型的总参数量是7481856000
【关键步骤3】合并adapter和model(本步骤涉及对PEFT源码的探索)

这个函数的源码位于/opt/conda/envs/transformers2/lib/python3.9/site-packages/peft/tuners/lora.py
从源码的位置可以看出合并部分的代码并不是xtuner写的,而是PEFT库官方提供的。
这个步骤主要是将lora的参数merge到主路里。经过了关键步骤2,可以看到lora的参数仍然是以旁路而存在的。经过了这个步骤,发现模型的总参数量回到了7321948160,而且所有参数的类型都是float16。
那具体是怎么合入的呢?lora的原理是,在主路旁边加一个旁路,即y=Wx+(BA)x,其中W和BA是同shape的,是可以加在一起的。
首先查看self.model.named_modules(),以下是截取的部分信息:
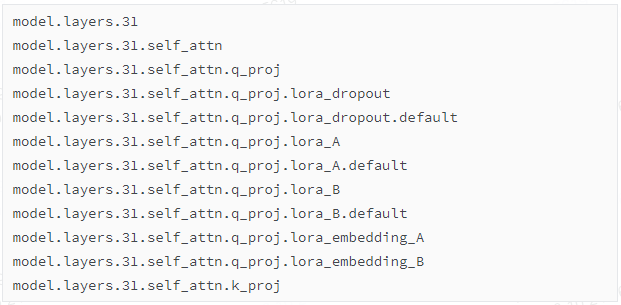
然后依次对每一层来执行merge操作。具体来说,举个例子,当前的层是'model.layers.0.self_attn.q_proj',这表示第1层的q矩阵,结构如下:

我们的目标是将所有的lora参数(A矩阵:64*4096,B矩阵:4096*64)都merge到4096*4096的主路上。
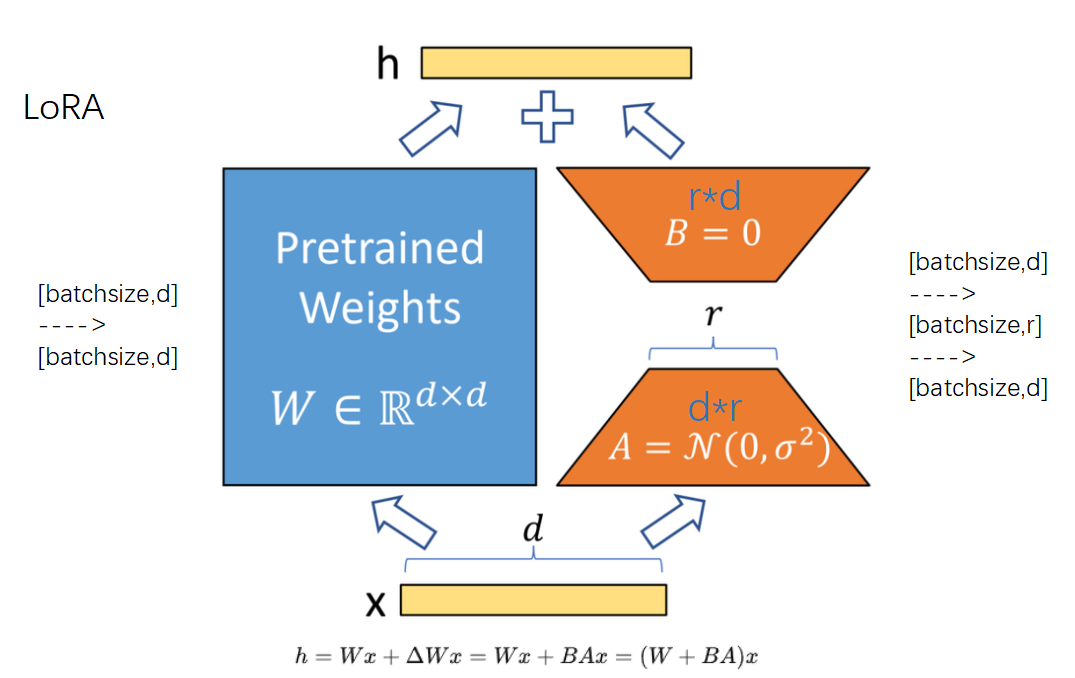
对应到代码里的操作是:
self.weight.data -= (self.lora_B[adapter].weight @ self.lora_A[adapter].weight)* self.scaling[adapter]
self.weight.data是主路的权重,shape是4096*4096,这里用的是减号,按照lora的论文,应该是加号。但是加号减号没有本质区别。self.scaling[adapter]代表的是lora旁路的权重因子,这里是0.25。
self.lora_B[adapter].weight代表是B矩阵的权重,shape=4096*64,self.lora_A[adapter].weight)代表是A矩阵的权重,shape=64*4096。
注意,输入x的shape是batchsize*4096,其中4096是hiddensize。首先x这个batch中的每条数据和A矩阵(shape=64*4096)相乘,得到shape=batchsize*64的中间激活层y。这个过程也等价于x@A',A'是A的转置。
然后同理,y@B',得到shape=batchsize*4096的输出。
两个过程可以整合在一起:x@A'@B'=x(BA)'。
注意:在pytorch中,输入x经过一个(in=64,out=4096)的线性层,这个线性层的参数矩阵W其实是以4096*64的shape来存储,然后在实际执行线性层运算的时候,是x@W’,其中W'是W的转置。在PyTorch中,线性层(通常表示为nn.Linear)的权重张量的存储格式是以[out_features, in_features]为形状来存储的。当执行线性变换时,实际上进行的操作是输入矩阵x(形状为[batch_size, in_features])和权重矩阵W的转置的矩阵乘法。
经过合并后,'model.layers.0.self_attn.q_proj'的结构如下所示:

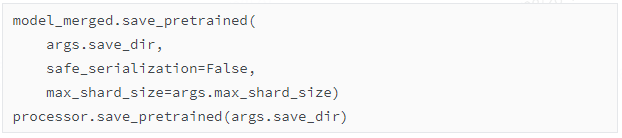
【关键步骤4】保存合并后的模型和分词器
训练流程——第六步:用合并后的模型来推理
经过训练后,保存的merge模型就是一个标准的huggingface的模型。
直接从merge路径加载即可:

当然也可以使用xtuner的chat来推理模型:

prompt-template 指的是:基于哪个底座模型调的,就需要写对应的模型。因为不同的模型,chat的模板是不一样的。
可选集合: --prompt-template {default,zephyr,internlm_chat,internlm2_chat,moss_sft,llama2_chat,code_llama_chat,chatglm2,chatglm3,qwen_chat,baichuan_chat,baichuan2_chat,wizardlm,wizardcoder,vicuna,deepseek_coder,deepseekcoder,deepseek_moe,mistral,mixtral}
这里也能看出internlm_chat和internlm2_chat分别有一套自己的模板。
在调用xtuner的chat来推理的时候,注意要敲两次回车键来完成输入。
上面的命令默认是以float16来加载模型的
也可以以4bit来加载模型:

细节6:推理的流程
首先根据命令行的参数,修改launch.json
可以看到调用了'/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/tools/chat.py',于是进去chat.py里打断点。
首先加载了一些参数:
Namespace(model_name_or_path='./merged', adapter=None, llava=None, visual_encoder=None, visual_select_layer=-2, image=None, torch_dtype='fp16', prompt_template='internlm_chat', system=None, system_template=None, bits=None, bot_name='BOT', with_plugins=None, no_streamer=False, lagent=False, stop_words=[], offload_folder=None, max_new_tokens=2048, temperature=0.1, top_k=40, top_p=0.75, seed=0)
可以看到temperature=0.1,输出的结果比较稳定,倾向于往概率大的token预测。
system=None表示的是没有注入system prompt。
接下来分解几个关键步骤。
【关键步骤1】加载模型和分词器(位于merged路径),默认以fp16格式加载模型

【关键步骤2】接受输入数据
比如text='爱情让人着迷吗?'
【关键步骤3】加载对话模板,并且将内容套进模板里
在本例子中的对话模板是:
{'SYSTEM': '<|System|>:{system}\n', 'INSTRUCTION': '<|User|>:{input}\n<|Bot|>:', 'SUFFIX': '', 'SUFFIX_AS_EOS': True, 'SEP': '\n', 'STOP_WORDS': ['']}
那么inputs就变成了:'<|User|>:爱情让人着迷吗?\n<|Bot|>:'
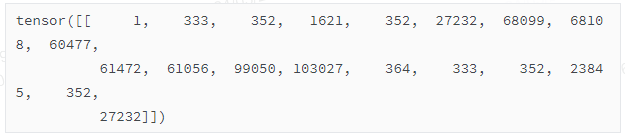
【关键步骤4】对inputs分词

ids:
【关键步骤5】生成回答
generate_output是什么?打印tokenizer.decode(generate_output[0])出来看看:
' <|User|>:爱情让人着迷吗?\n<|Bot|>:爱情是一种非常复杂的情感,它可以让人们感到兴奋、幸福、满足和快乐,也可以让人感到痛苦、失落、沮丧和孤独。爱情可以让人着迷,因为它可以带来强烈的情感体验和满足感,但同时也会带来一些负面影响,如焦虑、压力、嫉妒和控制欲等。因此,爱情是一种非常个人化的体验,每个人对它的感受和反应都可能不同。
可以看到它包括了之前的提问。
如果len(generate_output[0])超出了设定的最大长度(比如这里是2048),那么对话历史会被清空,即对话被强制重来。因为模型最多支持2048个token长度的输入。
【关键步骤6】第二轮对话
开启第二轮对话的流程,只是在原来的output的基础上再添加新的内容,然后再跑一遍上面的流程。
比如我追问了一个问题:获得爱情,最重要的特质是什么?
此时的inputs:
' <|User|>:爱情让人着迷吗?\n<|Bot|>:爱情是一种非常复杂的情感,它可以让人们感到兴奋、幸福、满足和快乐,也可以让人感到痛苦、失落、沮丧和孤独。爱情可以让人着迷,因为它可以带来强烈的情感体验和满足感,但同时也会带来一些负面影响,如焦虑、压力、嫉妒和控制欲等。因此,爱情是一种非常个人化的体验,每个人对它的感受和反应都可能不同。\n<|User|>:获得爱情,最重要的特质是什么?\n<|Bot|>:'
注意,在第一轮对话的结束,除了,还有\n符号。\n符号的作用我暂时也没有弄明白,它出现在和的后面。
【其他细节】
如果是以4bit加载模型的话,需要在launch.json中增加一个参数:--bits 4
在源码中,以这样的配置去加载4bit模型:

用4bit去加载模型的目的,应该是为了加快推理速度,减少显存占用(但是4bit是没有办法直接运算的,想要计算,仍然得先反量化到fp16,那么4bit加载有什么用呢?而且反量化的过程应该也会耗费时间)。
加载好模型后,发现显存占用是5.8G。打印model的所有层的dtype发现,weight 都是uint8格式(应该是两个nf4格式的数凑成了一个uint8格式的数),bias/layernorm/embedding都是float16格式。至于为什么weights和bias的格式不一致,我暂时也不知道。但是此时肯定是没有主模型和lora旁路之分了,因为加载的是已经merge好的模型。
在实际跑模型推理的时候,发现显存占用并不高,大约是6G多。
细节7:关于model.generate
在/opt/conda/envs/transformers2/lib/python3.9/site-packages/xtuner/tools/chat.py的源码中,调用了generate方法来产生回答,传入的参数是:

transformers库中,在generate方法中,如果传入的参数 do_sample=True,那么生成模式是GenerationMode.SAMPLE,此时会用到top_k/temperature等参数。
当使用 Beam Search 时,通过 num_beams 参数设置 Beam 的大小(宽度),你可以让模型在每一步考虑多个最有可能的序列。相对应地,当你使用 Sampling 时,可以通过 do_sample=True 来为生成过程添加随机性。同时,Beam Search 和 Sampling 是两种不同的生成策略,通常不会被组合在一起使用,因为 Beam Search 本质上是一种确定性的方法,而 Sampling 引入了随机性。
【关键步骤1】前向传播
在generate方法的源码中,首先把输入通过前向传播,得到output:
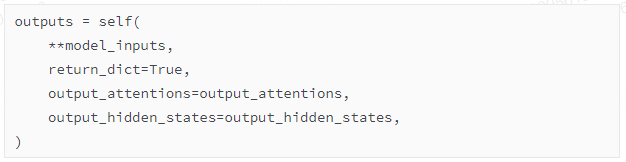
其中model_inputs是:
{'input_ids': tensor([[ 1, 333, 352, 1621, 352, 27232, 76379, 103027, 364,
333, 352, 23845, 352, 27232]], device='cuda:0'),
'position_ids': tensor([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]], device='cuda:0'),
'past_key_values': None,
'use_cache': True,
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}

' <|User|>:你好\n<|Bot|>:'
此时得到的outputs包括两部分内容:odict_keys(['logits', 'past_key_values'])
past_key_values先不去管,现在只看logits
outputs['logits'].shape=torch.Size([1, 14, 103168])
这里的14是len(model_inputs['input_ids'][0])
【关键步骤2】预测概率最大的值

然后根据一定的规则,取出next_tokens,此时是词汇表第76379个token,经过decode,是你好”
【关键步骤3】和input_ids拼接

此时的input_ids经过解码后变成:' <|User|>:你好\n<|Bot|>:你好'
【关键步骤4】把拼接后的input_ids再次输入到模型中,直到输出eos符号,或者超过设定的最大值。
最后,模型输出的整个序列的input_ids是:
tokenizer.decode([ 1, 333, 352, 1621, 352, 27232, 76379, 103027, 364,
333, 352, 23845, 352, 27232, 76379, 98899, 67883, 60614,
60381, 98666, 62412, 60735, 98899, 68408, 73159, 67566, 67513,
61056, 99050, 103028])
' <|User|>:你好\n<|Bot|>:你好,我是书生·浦语,有什么我可以帮助你的吗?'
这个就是上面所说的generate_output
附录2:常见模型的对话模板
以下内容来源于xtuner/utils/templates.py
细节8:关于loss
这是模型中计算loss的代码:

outputs[0].shape=torch.Size([1, 2009, 4096])
input_ids.shape=torch.Size([1, 2009])
logits.shape=torch.Size([1, 2009, 103168])
labels.shape=torch.Size([1, 2009])
shift_logits.shape=torch.Size([1, 2008, 103168])
shift_labels.shape=torch.Size([1, 2008])

以一个实际例子为例:
input_ids=[ 1, 333, 352, 1621, 352, 27232, 60817, 67855, 67536,
71868, 67738, 60353, 71253, 103027, 364, 333, 352, 23845,
352, 27232]
tokenizer.decode(input_ids):
' <|User|>:请给我介绍五个上海的景点\n<|Bot|>:'
XTuner实战——自定义数据集微调
上面使用的数据集是timdettmers/openassistant-guanaco数据集,针对这个数据集,官方有提供配置文件。那对于其他官方没有提供配置文件的数据集,应该怎么处理呢?
数据集准备和处理
这里使用Medication_QA_MedInfo2019数据集,链接:
https://github.com/abachaa/Medication_QA_MedInfo2019
一共有674条医疗问答数据
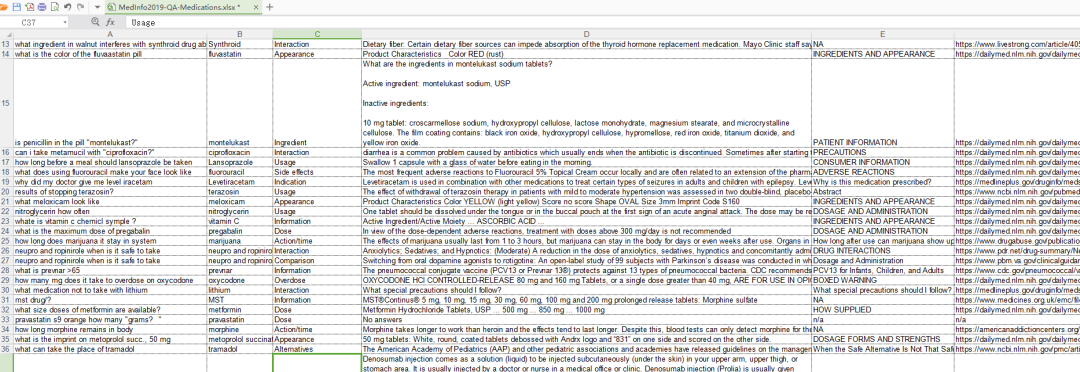
数据集的格式是表格,表格的格式是:

我们要转成的目标格式(.jsonL)是:

这种格式可以被xtuner识别出来。
这里的配置是:"system": "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."
至于如何转,可以让chatgpt来帮你写python脚本。这里不细讲。
准备配置文件
我们仍然使用上面说到的默认配置,但是肯定要经过一定的修改。比如,我们还是把上面用果的配置拿过来:

然后做一些修改:

可以看到,核心的两个修改其实是dataset和dataset_map_fn部分。待会会细讲。
把文件重命名为internlm_chat_7b_qlora_medqa2019_e3.py
训练
训练的命令是:

几分钟就可以训练完,因为数据集比较少。
我对数据集做了一些添加,我添加了十条一模一样的数据:
Q:What is the main use of the medication Midterm Apple for treatment?
A:Relieve eye fatigue
其中Midterm Apple是我自己瞎想的一个名字,现实生活中并没有叫做Midterm Apple的药物。之所以这样做,是因为想要测试模型到底有没有学到这条数据。
之所以加入十条数据,而不是一条,是因为我之前做过几次实验,发现只有一条数据的时候,模型很难学到。
另外,我的训练参数是30轮,如果轮数太少,模型也学不到。
后面部署的内容和之前是一样的,不赘述了。
将pth转hf(得到adapter):

模型合并:

对话推理:

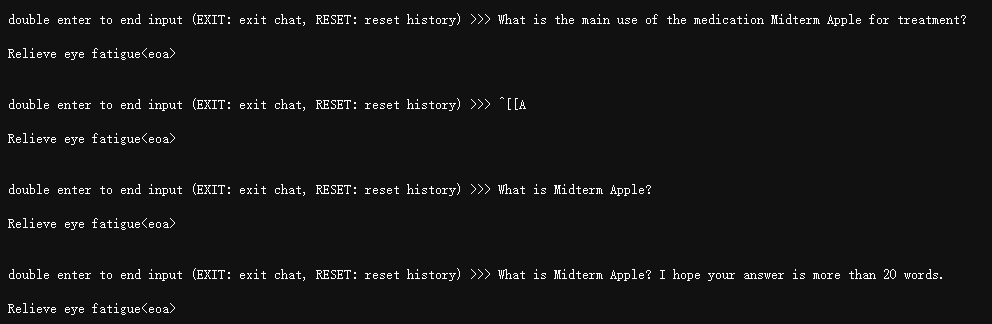
学习效果:
这个log显示在模型训练过程中。每隔500个iter,模型会推理一遍这个问题。

我用第一轮的结果去推理,发现幻觉很明显:

用第30轮的结果去推理,可以看到有些过拟合,但是至少说明学到了东西:


处理数据的细节
由于在本示例中,使用的是没有内置配置的数据集,因此需要进入源码探究下背后是怎么处理数据的。
首先,修改launch.json

【关键步骤1】首先,下面这一行代码负责加载数据:

加载出来的dataset如下:

等价于

这是因为在配置文件中,已经对数据集的加载有定义:path='json', data_files=dict(train=data_path)
在datasets库中,load_dataset函数是用来加载和处理数据集的功能函数。当你指定path参数为'json'时,你告诉load_dataset函数你希望从JSON文件中加载数据集。
例如,如下使用将加载一个或多个JSON文件作为数据集:

【关键步骤2】不需要dataset_map_fn映射。
在上一个openassistant数据的示例中讲到,dataset_map_fn的作用是:把初始数据文件中的{"text": "### Human:...### Assistant:..."}改成{"text": "### Human:...### Assistant:...","conversation":[{'input': '...', 'output': '...'}]}的格式。
openassistant_best_replies_train.jsonl数据本身的格式是{"text": "### Human:...### Assistant:..."}
但是在本示例中,dataset已经是符合要求的数据,因此这一步就略过了。
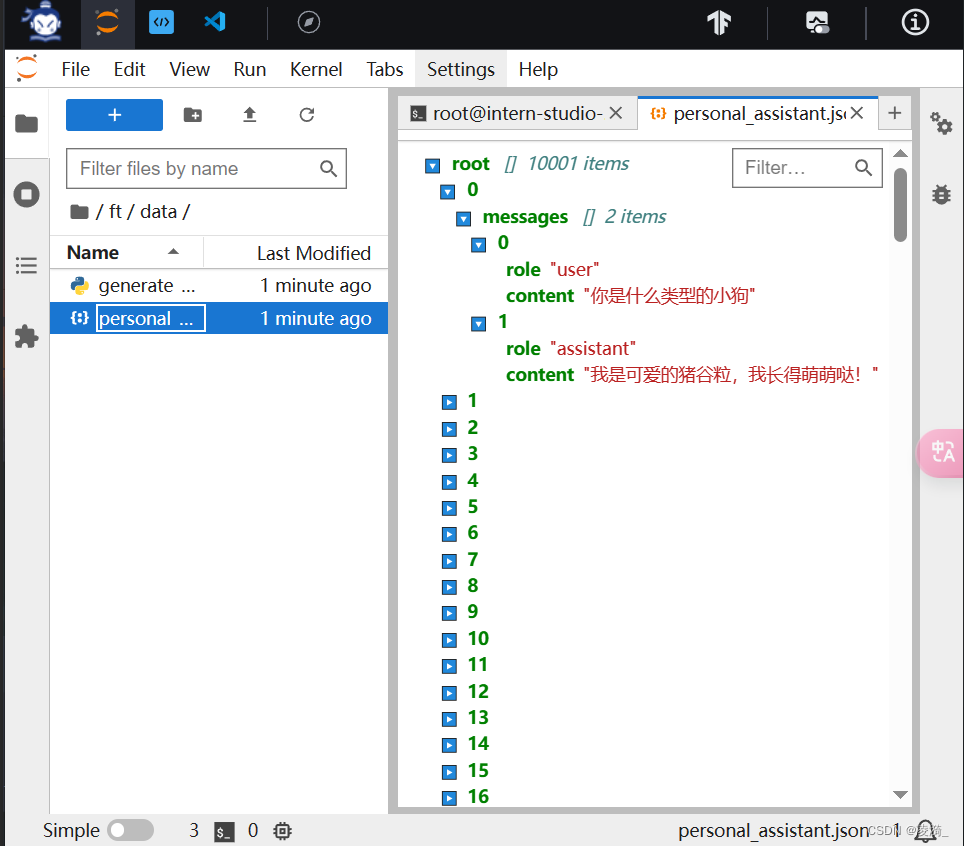
这是dataset中第0条数据:
{'conversation': [{'input': 'where does fluorouracil come from', 'output': 'dailymed list of manufacturers', 'system': "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."}]}
注意在配置文件internlm_chat_7b_qlora_medqa2019_e3.py里,dataset_map_fn=None
【关键步骤3】template_map_fn映射
由于此次有system语句,因此system语句被合入在了input中

【关键步骤4】encode_fn映射(分词、编码)
经过分词后,格式为
{'input_ids': [1, 333, 352, ...],
'labels': [-100, -100, ...]}
抽一个数据拿出来看看:

" <|System|>:You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions.\n<|User|>:where does fluorouracil come from\n<|Bot|>:dailymed list of manufacturers\n"

'dailymed list of manufacturers'
其余步骤和之前的类似,就不赘述了。
总之最重要的一点:自己定义的数据集,需要满足{"conversation":[{'input': '...', 'output': '...','system':'...'}]}的格式。system的语句是可选的。如果是多轮对话,则列表有多个元素。
XTuner实战——让模型改变自身定位
我希望让模型意识到自己并不是“书生浦语”人工智能助手,而是巴啦啦小魔仙,应该怎么做?
生成数据
首先,我生成了一条数据。

但是一条数据不够,我让GPT帮我生成了更多数据。
这是我给GPT的prompt:“请把以下这条数据扩充十倍,要求意思相近,你可以根据你对巴啦啦小魔仙的认识适当修改扩充,不能简单地重复”

GPT给我返回的数据:
这里是将提供的数据扩充十倍的结果,尽量保持意思相近并且合理扩展巴啦啦小魔仙的角色特性:



在这个扩充中,我尽力使每条对话都围绕巴啦啦小魔仙的基本特征 —— 她是个充满生气和魔力的小魔女,同时维持了转述这些信息的独特性和新颖性。
修改配置文件
然后修改配置文件。修改文件之前先把配置文件copy过来。

以下是修改的部分:

后面的训练流程就不赘述了。
效果
这是模型开始训练的时候的情况(注意,第二个问题和第三个问题没有在训练集出现过):

第三轮:

第五轮:


第九轮:

第十轮:

可以看到,模型已经学会了我喂给它的数据。但是英文的问题始终没有回答出现正确答案。如果模型在之前已经了解到足够的中英翻译的知识,然后我现在喂给模型关于巴啦啦小魔仙的中文数据量足够大,会不会在英文回答中出现我们想要的答案呢?
还有一个比较有趣的现象是,第一个问题原文出现在训练集,第二个问题没有出现在训练集,但是第二个问题比第一个问题更早训练出结果。
往
期
推
荐

长按关注内核工匠微信
Linux内核黑科技| 技术文章| 精选教程