概述
| Id | Operation | Name | Rows | Bytes | TempSpc | Cost (%CPU) | Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10000 | 120000| 0 | 20000 (100)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 120 | | 20000 (100)| |
| 2 | INDEX FAST FULL SCAN | IDX_Employee_LastName | 10000 | 120000| 0 | 10000 (10)| |
解释:
| Id | - 表示执行计划的步骤编号,从0开始,按执行顺序递增。
| Operation | - 描述数据库执行的具体操作类型,如:SELECT STATEMENT、SORT AGGREGATE、INDEX FULL SCAN等。
| Name | - 操作所涉及的对象名称,如索引名、表名等。
| Rows | - 预估的执行此操作将读取或产生的行数,是Oracle优化器根据统计信息做出的估算。
| Bytes | - 预估处理的字节数,反映了操作所需处理的数据量。
| TempSpc | - 指定此步骤是否会使用临时段(临时空间),如果是,显示所需的临时空间大小(单位通常是KB)。
| Cost (%CPU)| - 执行此步骤的总成本估计,包括CPU成本和I/O成本,用于衡量不同执行计划的相对代价。
| Time | - 预测的执行时间,但通常在实际运行中会有差异,主要用于优化器决策。
举例说明:
第一行表示整个SQL语句(SELECT STATEMENT),预估处理10000行数据,总共120000字节,总成本是20000(其中100%是CPU成本),预计耗时1秒。
第二行是一个排序聚合操作(SORT AGGREGATE),生成1行结果,共120字节。
第三行是一个索引快速全扫描(INDEX FAST FULL SCAN),同样处理10000行数据,总成本较低,使用索引IDX_Employee_LastName进行扫描,不需要临时空间。使用方式
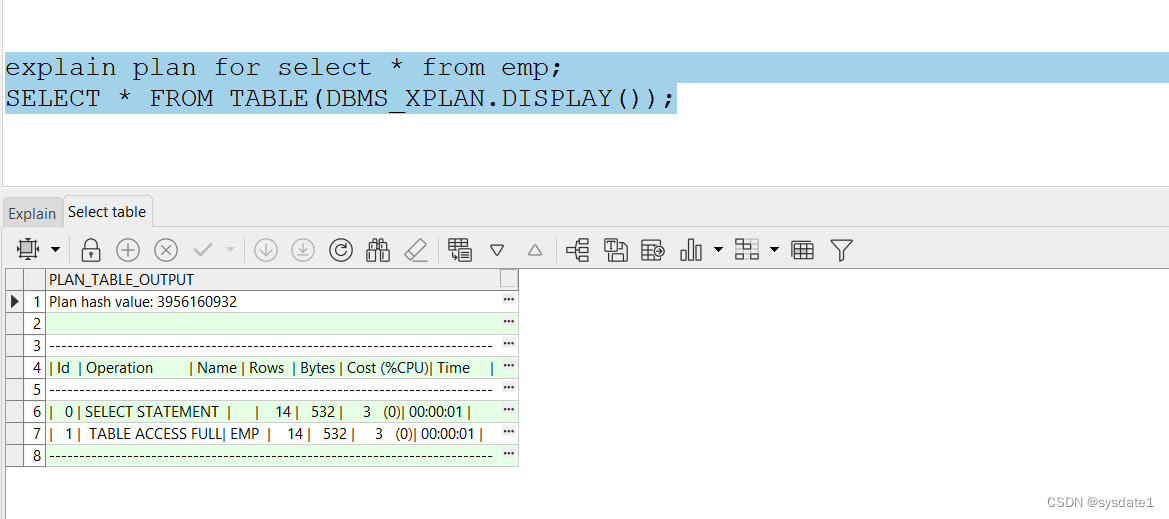
EXPLAIN PLAN FOR 查询语句
ID(每个流程的唯一标识):
ID(Id)列代表了执行计划中不同操作步骤的唯一标识符。
即:每个流程的唯一标识Operation(具体操作,执行顺序):
“Operation”列展示了数据库为了执行SQL语句而采取的不同操作步骤。这些操作涵盖了从数据源访问、过滤、排序、连接、聚合等多种数据库内部处理行为
1:执行的操作
2:执行的顺序(缩进越多,越先执行)
同一级的动作执行时遵循最上最右先执行的原则可能会出现操作明细
1. SELECT STATEMENT:
-
- 整个查询的起点,标识SQL语句的整体执行计划。
2. 全表扫描:TABLE ACCESS FULL:
-
- 全表扫描,即对整个表的所有数据进行线性读取,没有利用任何索引。
3. 索引扫描:INDEX SCAN:
-
- 索引扫描,包括但不限于:
-
-
- INDEX RANGE SCAN: 根据索引范围条件检索数据。
- INDEX UNIQUE SCAN: 当唯一索引被用来直接定位一行数据时。
- INDEX FAST FULL SCAN: 对索引进行类似全表扫描的操作,但比全表扫描可能更快,因为它可能避免了额外的排序和行链接操作。
-
4. 排序:SORT:
-
- 排序操作,例如:
-
-
- SORT ORDER BY
- SORT GROUP BY: 对数据进行分组前的排序。
- SORT AGGREGATE: 聚合操作,如SUM、COUNT、AVG等,可能伴随排序。
-
5. 表连接方式:JOIN:
-
- 表连接操作,例如:
a. 嵌套循环连接:小表连大表:NESTED LOOPS JOIN: 最常见的连接类型之一。
工作原理: 嵌套循环连接是最基础的连接方法,它的工作原理类似于嵌套循环,外层循环逐行遍历一个表,内层循环则针对每一行去另一个表中查找匹配的记录。其性能很大程度上依赖于内外表的大小以及索引的有效性。
性能特点:
当外表较小或者内外表之间有很好的索引关联时(如外表通过主键连接内表的唯一索引),嵌套循环连接效率非常高。
若外表庞大而内表没有合适的索引,或者连接条件没有利用到索引,这种连接方式可能会很慢,因为它可能需要进行大量的索引查找或全表扫描。b. 合并连接(内存不足用这个):排序好的表进行连接:MERGE JOIN: ,适用于已经排序或者部分排序的数据。
工作原理: 合并连接要求两个表都已经排序好(或者可以利用现有索引达到排序效果),然后将两个排序好的数据流进行合并,匹配相同的键值来进行连接。合并连接可以有效地利用索引和排序,无需额外的临时空间。
性能特点:
● 当两个表都很大,但都已排序或可以利用索引进行有效的排序时,合并连接效率很高。
● 如果数据量巨大,内存不足以一次性装入所有数据,但有足够的磁盘空间和合理的I/O速度,合并连接可以通过多轮排序和合并逐步完成,性能较好。c. HASH JOIN: 使用哈希算法来匹配两表之间的记录。
6. 哈希连接(HASH JOIN)
工作原理: 哈希连接首先将一方表构建哈希表,然后扫描另一方表,对每一行计算哈希值并查找哈希表,通过哈希索引快速找到匹配项。哈希连接需要足够的内存来存储哈希表。
性能特点:
● 当两个表都非常大,并且内存充足时,哈希连接通常比嵌套循环连接更快,因为它避免了大量索引查找操作。
● 如果内存不足,哈希连接可能需要溢出到磁盘,这会显著降低性能,但即使如此,有时仍可能比其他连接方式更快,尤其是在大规模数据处理中。
总结起来,选择哪种连接方式最为高效,通常取决于表的大小、索引的存在和有效性、内存资源、磁盘I/O能力等因素。在实际应用中,Oracle数据库的优化器会根据统计信息和成本模型自动选择最优的连接方式。在特定场景下,也可能需要通过手工hints等方式指导优化器选择合适的连接方法。7. 过滤:FILTER:
-
- 过滤操作,应用于WHERE子句中的条件筛选。
8. INDEX SKIP SCAN:
-
- 索引跳跃扫描,仅读取索引的一部分来满足查询需求。
9. 分区操作:PARTITION RANGE ALL / SINGLE / ITERATOR:
-
- 分区表相关的扫描操作,针对分区表中的特定分区或所有分区。
10. 视图操作:VIEW:
-
- 视图操作,数据库处理视图逻辑的方式。
11. rowID查询:TABLE ACCESS BY INDEX ROWID:
-
- 通过索引获取行地址(ROWID),随后进行单行的表访问。
每一个“Operation”都是SQL执行流程中的一个阶段,Oracle优化器会选择成本最低的执行路径来执行SQL语句,从而尽可能提高查询效率。通过分析执行计划中的Operation序列,可以深入了解数据库是如何实际处理SQL查询请求的,并据此进行性能优化。
备注:表的访问方式
● 全表扫描table access full
- Oracle 会读取表中所有的行,并检查每一行是否满足 where 限制条件
- 全表扫描时可以使用多块读(一次 I/O 读取多块数据块)操作,提升吞吐量
● rowid 扫描table access by rowid(单行存取他最快)
- rowid:伪列,Oracle 自带的,不会存储 rowid 的值,不能被增、删、改
- 一旦一行数据插入后,则其对应的 rowid 在该行的生命周期内是唯一的,即使发生行迁移,该行的 rowid 值也不变
简述:查询时,先找索引树,根据索引树存储的rowid信息,拿到rowid对应的行。
rowid简述:行的唯一ID。(还包含有关数据在数据库物理存储结构中的具体位置信息。)
● 索引扫描table access by index scan
索引唯一扫描:index unique scan(主键唯一索引专用,只返回一条数据)
- 每次至多返回一条记录
- 有下列两种情况(当查询字段有下列约束时)
-
- unique (唯一索引)
- primary key (主键ID)
索引范围扫描:index range scan(携带范围条件会用他)
- 每次至少返回一条记录
- 一般有下列三种情况
-
- 在唯一索引列上使用了范围操作符(如:> < >= <= between)
- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
- 对非唯一索引列上进行的任何查询
索引全表扫描:index full scan
扫描索引并排序返回
索引快速扫描:index fast full scan
扫描索引 不 排序返回
索引跳跃扫描(组合索引专用):index skip scan
- 必须是 组合索引
- 除了前导列(索引中第一列)外的其他列作为条件
说明了:MYSQL不允许打破的规则被ORACAL打破了 (本人的理解)
ABC为联合索引,
MYSQL:可用:A,AB,ABC
ORACAL:A,AB,ABC,AC,BC
NAME(每个步骤涉及的表名,索引名等)
"Name"列通常表示的是执行计划中涉及的具体数据库对象,例如表名、索引名、视图名或者是其他类型的数据库对象,如分区、物化视图等。每个操作步骤(Operation)都会关联到一个或多个数据库对象,"Name"列就用来展示这些操作所作用的具体对象。| Id | Operation | Name |
-------------------------------------------------
| 1 | TABLE ACCESS FULL | Customers |
| 2 | INDEX RANGE SCAN | PK_Products |
| 3 | SORT JOIN | |
| 4 | TABLE ACCESS BY INDEX ROWID| Orders |- 在第一个操作步骤中,"Name"是"Customers",表示执行了一个全表扫描操作在"Customers"表上。
- 第二个步骤使用了名为"PK_Products"的索引进行了索引范围扫描。
- 第四个步骤使用索引行ID访问了"Orders"表,这里的"Name"为空是因为该步骤是通过前面的索引扫描间接访问的。
通过分析执行计划中的"Name"列,我们可以清楚地了解到数据库执行SQL语句时访问的具体数据来源,这对于性能调优和理解查询执行过程至关重要。
Rows(操作预计涉及的行数)
K是千
M是万
Bytes(预计处理的数据量)
TempSpc(临时表)
存在此行,说明使用临时表,展示的是临时表占用的内存。
不存在此行,说明未使用临时表
Cost (%CPU) (预计CPU使用情况)
Cost (%CPU)列表示Oracle优化器对执行某个操作预计耗费的CPU成本的度量。这个成本不仅包括CPU时间,还包括内存和I/O操作的成本,但通常以CPU时间作为主要参考基准。Cost (%CPU)列的值是一个相对成本,用于比较不同执行计划的成本,从而帮助优化器选择成本最低的执行计划。
| Id | Operation | Name | Rows | Bytes | Cost (%CPU) |
----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000 | 8000 | 10000 (1) |
| 1 | SORT AGGREGATE | | 1 | 12 | 1000 (1) |
| 2 | TABLE ACCESS FULL| Employees | 1000 | 8000 | 1000 (1) |在这个例子中:
- Id 为 2 的 TABLE ACCESS FULL 操作预计的总成本是 1000 (1),这意味着Oracle估计执行全表扫描 Employees 表大概会花费相当于1000个CPU单位的工作量,其中 (1) 表示大致的CPU成本占比为100%。
- Id 为 1 的 SORT AGGREGATE 操作预计的成本是 1000 (1),这表示排序和聚合操作大约需要1000个CPU单位的工作量。
- Id 为 0 的 SELECT STATEMENT 总体成本是 10000 (1),这是整个查询的预计总成本,包括子操作的成本。
优化器会综合考虑Cost (%CPU)以及其他因素(如Rows、Bytes、TempSpc等)来确定最佳执行计划,旨在选择成本最低且能最快得到查询结果的方案。但要注意,实际运行时的成本可能会与预估成本有所出入,因为预估是基于当前的统计信息和Oracle的优化算法得出的。