使用LDA模型和Spark进行文本主题分析
本篇博客介绍了如何使用LDA(潜在狄利克雷分配)模型和Spark进行文本主题分析。我们的目标是从大量的用户评论中提取出主题。
1. 环境设置
首先,我们需要导入所需的库,包括jieba(用于中文分词),gensim(用于创建LDA模型),nltk(用于下载和使用停用词),json(用于处理json格式的数据),snownlp(用于情感分析),以及pyspark(用于处理大规模数据)。这里建议使用anaconda建立虚拟环境去运行。
然后,我们创建一个SparkSession并连接到远程的Spark服务器。
spark = SparkSession.builder.appName("RemoteSparkConnection").master("yarn").\
config("spark.pyspark.python", "/opt/apps/anaconda3/envs/myspark/bin/python") \
.config("spark.sql.warehouse.dir", "/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node01:9083") \
.config("spark.sql.parquet.writeLegacyFormat", "true") \
.enableHiveSupport() \
.getOrCreate()
在这篇博客中,我们将详细介绍如何使用SparkSession建立一个远程的Spark连接。以下是我们将要讲解的代码:
spark = SparkSession.builder.appName("RemoteSparkConnection").master("yarn").\
config("spark.pyspark.python", "/opt/apps/anaconda3/envs/myspark/bin/python") \
.config("spark.sql.warehouse.dir", "/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node01:9083") \
.config("spark.sql.parquet.writeLegacyFormat", "true") \
.enableHiveSupport() \
.getOrCreate()
首先,我们使用SparkSession.builder来创建一个SparkSession的构建器。这个构建器可以让我们配置SparkSession的参数。
然后,我们使用appName("RemoteSparkConnection")来设置应用程序的名称。这个名称将会显示在Spark集群管理器的用户界面上。
接着,我们使用master("yarn")来设置集群管理器。在这个例子中,我们使用的是YARN。
接下来,我们使用config方法来设置一些配置参数。例如,我们设置了Python环境的路径、Spark SQL的仓库目录、Hive元数据存储的URI以及Parquet文件的写入格式。
然后,我们使用enableHiveSupport方法来启用Hive的支持。这样,我们就可以使用Hive的功能,例如HiveQL和Hive UDF。
最后,我们使用getOrCreate方法来获取或创建一个SparkSession。如果已经存在一个符合我们配置的SparkSession,那么就返回这个SparkSession;否则,就创建一个新的SparkSession。
通过以上步骤,我们就成功地建立了一个远程的Spark连接。在后续的数据处理任务中,我们可以使用这个SparkSession来读取和写入数据,执行SQL查询,以及运行机器学习算法。
2. 文本预处理
我们定义了一个名为Thematic_focus的函数,用于对文本进行预处理。这个函数包括以下几个步骤:
- 中文分词:使用
jieba库进行分词。 - 删除停用词:使用
nltk库中的停用词列表删除停用词。 - 删除标点符号:使用Python的
string库删除所有的标点符号。
def Thematic_focus(text):
# 下载中文停用词列表
# 中文文本分词
def tokenize(text):
return list(jieba.cut(text))
# 删除中文停用词
def delete_stopwords(tokens):
# 分词
words = tokens # 假设你已经有分好词的文本,如果没有,你可以使用jieba等工具进行分词
# 加载中文停用词
stop_words = set(stopwords.words('chinese'))
# 去除停用词
filtered_words = [word for word in words if word not in stop_words]
# 重建文本
filtered_text = ' '.join(filtered_words)
return filtered_text
def remove_punctuation(input_string):
import string
# 制作一个映射表,其中所有的标点符号都被映射为None
all_punctuation = string.punctuation + "!?。。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏.\t \n很好是去"
translator = str.maketrans('', '', all_punctuation)
# 使用映射表来移除所有的标点符号
no_punct = input_string.translate(translator)
return no_punct
3. 主题分析
tokens = tokenize(text)
# 删除停用词
text = delete_stopwords(tokens)
# 祛除标点符号
text = remove_punctuation(text)
# 重新分词
tokens = tokenize(text)
# 创建字典和文档-词频矩阵
dictionary = corpora.Dictionary([tokens])
corpus = [dictionary.doc2bow(tokens)]
# 运行LDA模型
lda_model = models.LdaModel(corpus, num_topics=1, id2word=dictionary, passes=50)
# 提取主题
topics = lda_model.show_topics(num_words=8)
# 输出主题
for topic in topics:
print(topic)
在完成文本预处理后,我们使用gensim库中的corpora和models模块创建LDA模型,并对预处理后的文本进行主题分析。
我们首先创建一个字典和一个文档-词频矩阵,然后使用这些数据训练LDA模型。我们设置主题数量为1,并进行50次迭代。
最后,我们使用LDA模型提取出主题,并打印出每个主题的前8个词。
4. 应用
def qvna():
df=spark.table("cjw_data.qvna")
def calculate_Thematic(commentlist):
try:
jsonstr = str(commentlist)
python_obj = json.loads(jsonstr, strict=False)
except:
return None
contentstring = ""
for item in python_obj:
for i in item:
if (i["content"] != "用户未点评,系统默认好评。"):
contentstring+=i["content"]
print(contentstring)
try:
Thematic_focus(contentstring)
except:
return None
row = df.take(100)
for i in row:
print(calculate_Thematic(i[-1]))
我们定义了一个名为qvna的函数,用于从Spark表中读取数据,并对每一条评论进行主题分析。我们首先将评论列表从json格式转换为Python对象,然后将所有的评论合并成一个字符串,最后使用Thematic_focus函数对这个字符串进行主题分析。
我们使用take函数从表中取出前100条记录,并对每一条记录的评论进行主题分析。
完整代码
# Author: 冷月半明
# Date: 2023/12/20
# Description: This script does XYZ.
import jieba
from gensim import corpora, models
import nltk
from nltk.corpus import stopwords
import json
import time
from snownlp import SnowNLP
from pyspark.sql.functions import udf
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
nltk.download('stopwords')
# 创建SparkSession并连接到远程Spark服务器
spark = SparkSession.builder.appName("RemoteSparkConnection").master("yarn").\
config("spark.pyspark.python", "/opt/apps/anaconda3/envs/myspark/bin/python") \
.config("spark.sql.warehouse.dir", "/hive/warehouse") \
.config("hive.metastore.uris", "thrift://node01:9083") \
.config("spark.sql.parquet.writeLegacyFormat", "true") \
.enableHiveSupport() \
.getOrCreate()
print("链接成功")
def Thematic_focus(text):
# 下载中文停用词列表
# 中文文本分词
def tokenize(text):
return list(jieba.cut(text))
# 删除中文停用词
def delete_stopwords(tokens):
# 分词
words = tokens # 假设你已经有分好词的文本,如果没有,你可以使用jieba等工具进行分词
# 加载中文停用词
stop_words = set(stopwords.words('chinese'))
# 去除停用词
filtered_words = [word for word in words if word not in stop_words]
# 重建文本
filtered_text = ' '.join(filtered_words)
return filtered_text
def remove_punctuation(input_string):
import string
# 制作一个映射表,其中所有的标点符号都被映射为None
all_punctuation = string.punctuation + "!?。。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏.\t \n很好是去"
translator = str.maketrans('', '', all_punctuation)
# 使用映射表来移除所有的标点符号
no_punct = input_string.translate(translator)
return no_punct
tokens = tokenize(text)
# 删除停用词
text = delete_stopwords(tokens)
# 祛除标点符号
text = remove_punctuation(text)
# 重新分词
tokens = tokenize(text)
# 创建字典和文档-词频矩阵
dictionary = corpora.Dictionary([tokens])
corpus = [dictionary.doc2bow(tokens)]
# 运行LDA模型
lda_model = models.LdaModel(corpus, num_topics=1, id2word=dictionary, passes=50)
# 提取主题
topics = lda_model.show_topics(num_words=8)
# 输出主题
for topic in topics:
print(topic)
def qvna():
df=spark.table("cjw_data.qvna")
def calculate_Thematic(commentlist):
try:
jsonstr = str(commentlist)
python_obj = json.loads(jsonstr, strict=False)
except:
return None
contentstring = ""
for item in python_obj:
for i in item:
if (i["content"] != "用户未点评,系统默认好评。"):
contentstring+=i["content"]
print(contentstring)
try:
Thematic_focus(contentstring)
except:
return None
row = df.take(100)
for i in row:
print(calculate_Thematic(i[-1]))
def job():
qvna()
job()
运行截图:
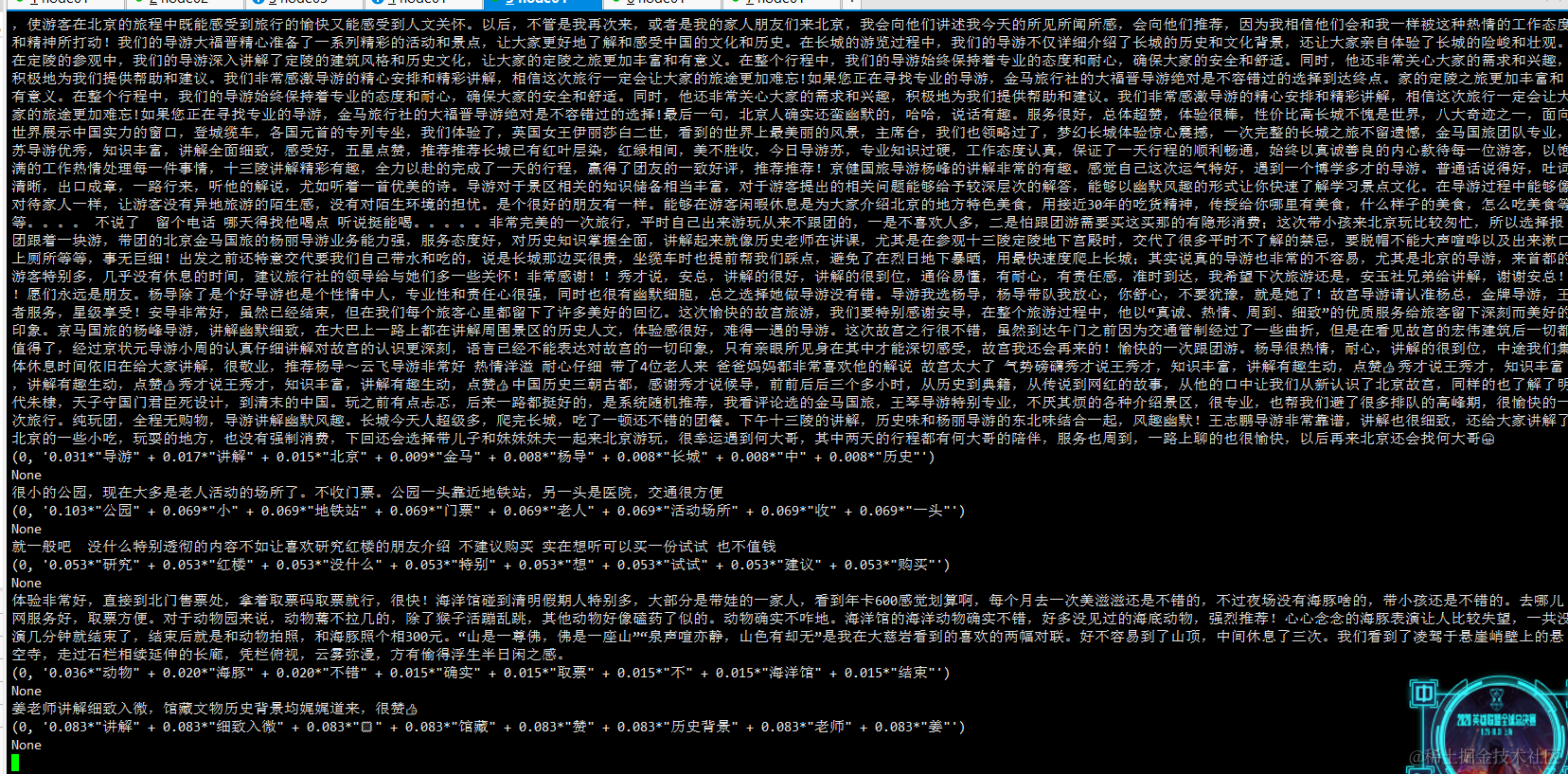
需注意的是若需分析的文本较短,该模型可能不会展现出预期的结果,这时有以下几个解决方案:
- 预处理:对于较短的文本,可以尝试将它们与相邻的文本合并,以形成更长的文本。这样可以提供更多的上下文信息,有助于LDA模型更好地提取主题。
- 调整模型参数:LDA模型的主要参数包括主题数(
num_topics)和迭代次数(passes)。对于较短的文本,可以尝试减少主题数和增加迭代次数,以提高模型的性能。 - 使用其他模型:如果LDA模型在处理较短文本时效果不佳,可以考虑使用其他的主题模型,如NMF(非负矩阵分解)或LSA(潜在语义分析)。
- 特征选择:在进行主题提取之前,可以通过TF-IDF等方法进行特征选择,以减少噪声并提高模型的性能。