算法题目打卡
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
输入 coins = [1, 2, 5], amount = 11
输出:3
解释 11 = 5 + 5 + 1
解答:
class Solution:
def coinChange(self, coins: List[int], amount: int) -> int:
# 设定solution变量
solut = {}
@functools.lru_cache(amount)
def dp(rem) -> int:
if rem < 0: return -1
if rem == 0: return 0
if rem in solut:
return solut[rem]
mini = int(1e9)
for coin in self.coins:
res = dp(rem - coin)
if res >= 0 and res < mini:
mini = res + 1
solut[rem-coin] = mini
return mini if mini < int(1e9) else -1
self.coins = coins
if amount < 1: return 0
return dp(amount)
注意此代码加不加solut字典其实速度和内存消耗都是差不多的,是因为python特殊的修饰器功能,解释如下:
在代码中,solut 字典确实是被用来存储中间结果,以避免重复计算的。然而,也使用了 functools.lru_cache 装饰器,这是 Python 中的一个功能强大的工具,它可以自动缓存函数的结果。
lru_cache 装饰器会创建一个类似于手动创建的 solut 字典的缓存。它会自动保存最近使用的函数调用的结果,并在后续相同参数的调用中直接返回缓存的结果,这样就避免了重复计算。
由于 lru_cache 已经有效地缓存了结果,solut 字典在此代码中实际上是多余的。如果 lru_cache 装饰器已经足够高效地工作了,我们可能不会在运行时观察到加入 solut 字典有任何显著的速度提升,因为 lru_cache 已经在内部做了相同的事情。
如果想验证 solut 字典对性能的影响,可以可以尝试禁用 lru_cache(注释掉 @functools.lru_cache(amount) 这一行),这时应该能看到不使用 solut 字典会导致函数运行得更慢,因为会有很多重复计算。
给你一棵二叉树的根节点 root ,请你判断这棵树是否是一棵 完全二叉树 。
在一棵 完全二叉树 中,除了最后一层外,所有层都被完全填满,并且最后一层中的所有节点都尽可能靠左。最后一层(第 h 层)中可以包含 1 到 2h 个节点。
示例 1:
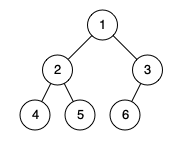
输入:root = [1,2,3,4,5,6]
输出:true
解释:最后一层前的每一层都是满的(即,节点值为 {1} 和 {2,3} 的两层),且最后一层中的所有节点({4,5,6})尽可能靠左。
解答
class Solution:
def isCompleteTree(self, root: Optional[TreeNode]) -> bool:
# 设置初始变量
queue = [root] # 初始条件
end = False # 标记树的尾部
while queue: # 遍历队列
current = queue.pop(0)
if not current: # 队列中出现了None
end = True
else: # 队列中还有树节点
if end: # 左节点出现了空值 所以
return False
# 左右节点入队
queue.append(current.left)
queue.append(current.right)
return True
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
示例 1:
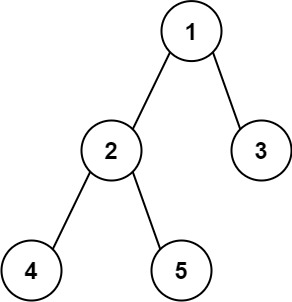
输入:root = [1,2,3,4,5]
输出:3
解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。
使用深度优先遍历的思想来解决:
class Solution:
def diameterOfBinaryTree(self, root: Optional[TreeNode]) -> int:
self.MaxDiameter = 0
def depth(node):
nodeDepth = 0
if not node:# 定义递归的返回条件
return 0
l = depth(node.left)
r = depth(node.right)
if l+r > self.MaxDiameter:
# 找到最远的距离 左子树深度 右子树深度
self.MaxDiameter = l+r
return max(l,r)+1
depth(root)
return self.MaxDiameter
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的
子集
(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
输入: nums = [1,2,3]
输出: [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
方法一: 利用python官方给出的combinations组合函数来输出结果
from itertools import combinations
class Solution:
def subsets(self, data: List[int]) -> List[List[int]]:
subsets = []
for r in range(len(data) + 1):
subsets.extend(combinations(data, r))
return subsets
介绍combinations
itertools.combinations(iterable, r)函数是Python标准库中itertools模块提供的一个函数,用于生成指定长度的组合。它接受两个参数:
iterable:指定要生成组合的可迭代对象,例如列表、元组等。r:指定生成的组合的长度。
combinations函数将返回一个迭代器,其中包含了原始数据中所有长度为r的组合。这些组合是按照原始数据中的顺序产生的。
以下是combinations函数的示例用法:
from itertools import combinations
# 定义原始数据
data = [1, 2, 3, 4]
# 生成长度为2的组合
result = combinations(data, 2)
# 输出所有组合
for comb in result:
print(comb)
在这个示例中,我们定义了一个包含数字 1、2、3 和 4 的列表作为原始数据。然后,我们使用combinations函数生成了长度为 2 的所有可能组合,并通过循环遍历打印了每个组合。
运行上述代码,你将看到输出的所有长度为 2 的组合结果。这些组合是从原始数据中选取的长度为 2 的所有可能组合。
方法二
记原序列中元素的总数为 n。原序列中的每个数字 a i a_i ai的状态可能有两种,即「在子集中」和「不在子集中」。我们用 1 表示「在子集中」,0 表示不在子集中,那么每一个子集可以对应一个长度为 n 的 01 序列,第 i位表示 a i a_i ai 是否在子集中
def subsets(nums):
"""
生成一个集合的所有子集
参数:
nums: 列表,原集合中的所有数字
返回值:
result: 列表的列表,表示原集合的所有子集
"""
n = len(nums) # 集合中元素的总数
result = [] # 存储所有子集的列表
for mask in range(2**n): # 枚举所有可能的状态
subset = [] # 存储当前子集的列表
for i in range(n): # 遍历集合中的每个元素
if mask & (1 << i): # 检查二进制表示中的第i位是否为1
subset.append(nums[i]) # 如果是1,则将对应的元素加入当前子集
result.append(subset) # 将当前子集添加到结果列表中
return result























![使用 Python SimPy 进行离散事件仿真[01]: — 构建基本模型](https://img-blog.csdnimg.cn/direct/c23b7d65ff2342879aabd4e33acfbc1b.png)