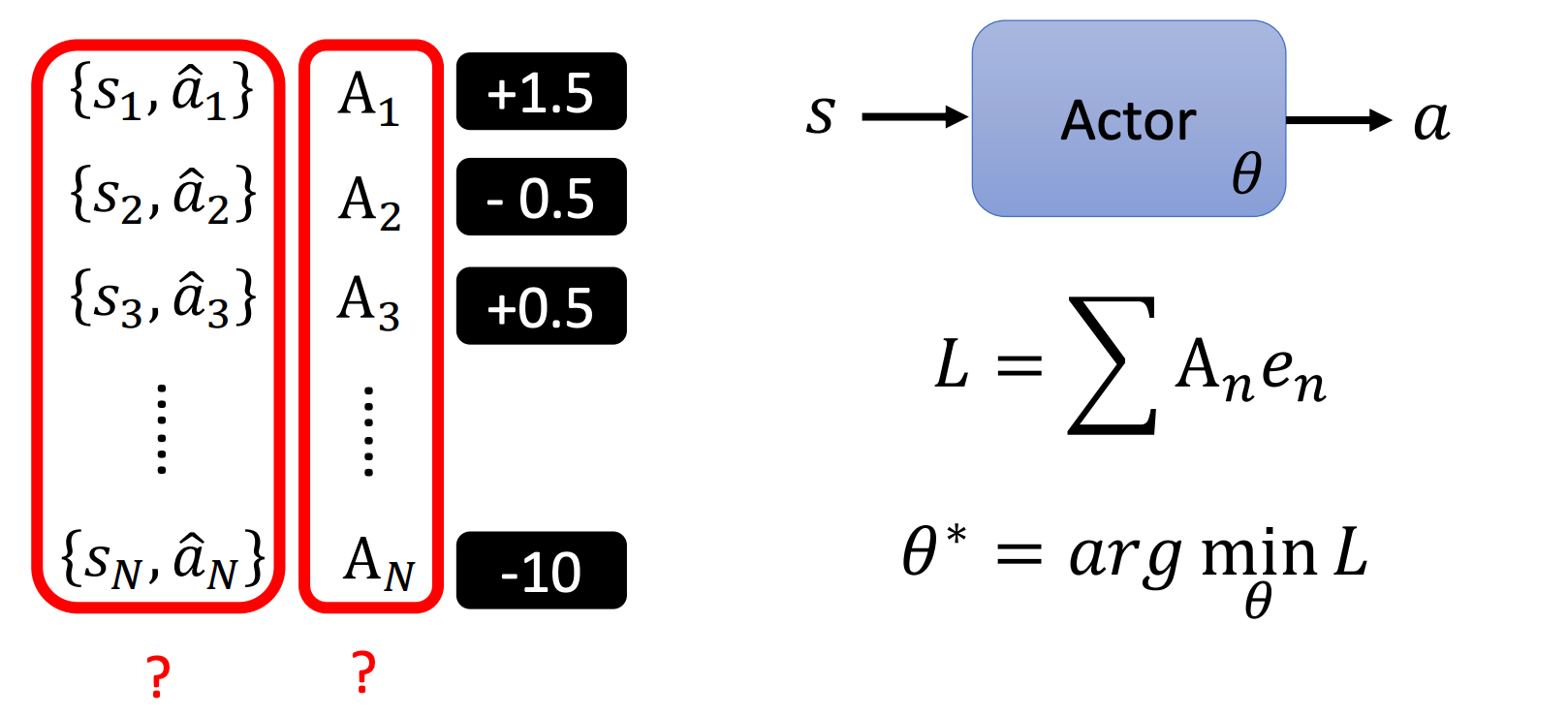
什么是Xorbits Inference
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
主要功能
🌟 模型推理,轻而易举:大语言模型,语音识别模型,多模态模型的部署流程被大大简化。一个命令即可完成模型的部署工作。
⚡️ 前沿模型,应有尽有:框架内置众多中英文的前沿大语言模型,包括 baichuan,chatglm2 等,一键即可体验!内置模型列表还在快速更新中!
🖥 异构硬件,快如闪电:通过 ggml,同时使用你的 GPU 与 CPU 进行推理,降低延迟,提高吞吐!
⚙️ 接口调用,灵活多样:提供多种使用模型的接口,包括 OpenAI 兼容的 RESTful API(包括 Function Calling),RPC,命令行,web UI 等等。方便模型的管理与交互。
🌐 集群计算,分布协同: 支持分布式部署,通过内置的资源调度器,让不同大小的模型按需调度到不同机器,充分使用集群资源。
🔌 开放生态,无缝对接: 与流行的三方库无缝对接,包括 LangChain,LlamaIndex,Dify,以及 Chatbox。
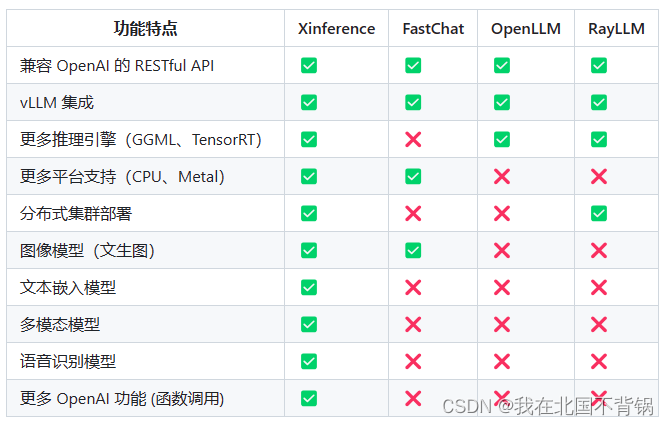
Xorbits Inference相比其他推理框架,支持文本嵌入模型、支持多模态模型、支持函数调用等功能。
内置模型
Xorbits Inference内置大语言模型、嵌入模型、Image Models、音频模型以及重排序模型。
支持众多的模型,内置模型列表可查看:
https://inference.readthedocs.io/zh-cn/latest/models/builtin/llm/index.html
部署
Xinference 在 Linux, Windows, MacOS 上都可以通过 pip 来安装。如果需要使用 Xinference 进行模型推理,可以根据不同的模型指定不同的引擎。
Transformers 引擎
如果是使用Transformers 引擎,PyTorch(transformers) 引擎支持几乎有所的最新模型,这是 Pytorch 模型默认使用的引擎:
pip install "xinference[transformers]"
vLLM 引擎
如果是使用vLLM 引擎,vLLM 是一个支持高并发的高性能大模型推理引擎。当满足以下条件时,Xinference 会自动选择 vllm 作为引擎来达到更高的吞吐量:
模型的格式必须是 PyTorch 或者 GPTQ
量化方式必须是 GPTQ 4 bit 或者 none
运行的操作系统必须是 Linux 且至少有一张支持 CUDA 的显卡
运行的模型必须在 vLLM 引擎的支持列表里
安装 xinference 和 vLLM:
pip install "xinference[vllm]"
GGML 引擎
当使用 GGML 引擎时,建议根据当前使用的硬件手动安装依赖,从而获得最佳的加速效果。
GGML 引擎
pip install xinference
pip install ctransformers
安装llama-cpp-python:
Apple M系列:CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
英伟达显卡:CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
AMD显卡:CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
如果你希望能够推理所有支持的模型,可以用以下命令安装所有需要的依赖:
pip install "xinference[all]"
运行
要启动一个本地的 Xinference 实例,请运行以下命令:
xinference-local --host 0.0.0.0 --port 9997
运行成功后,后续所有的操作都可以在页面上进行。
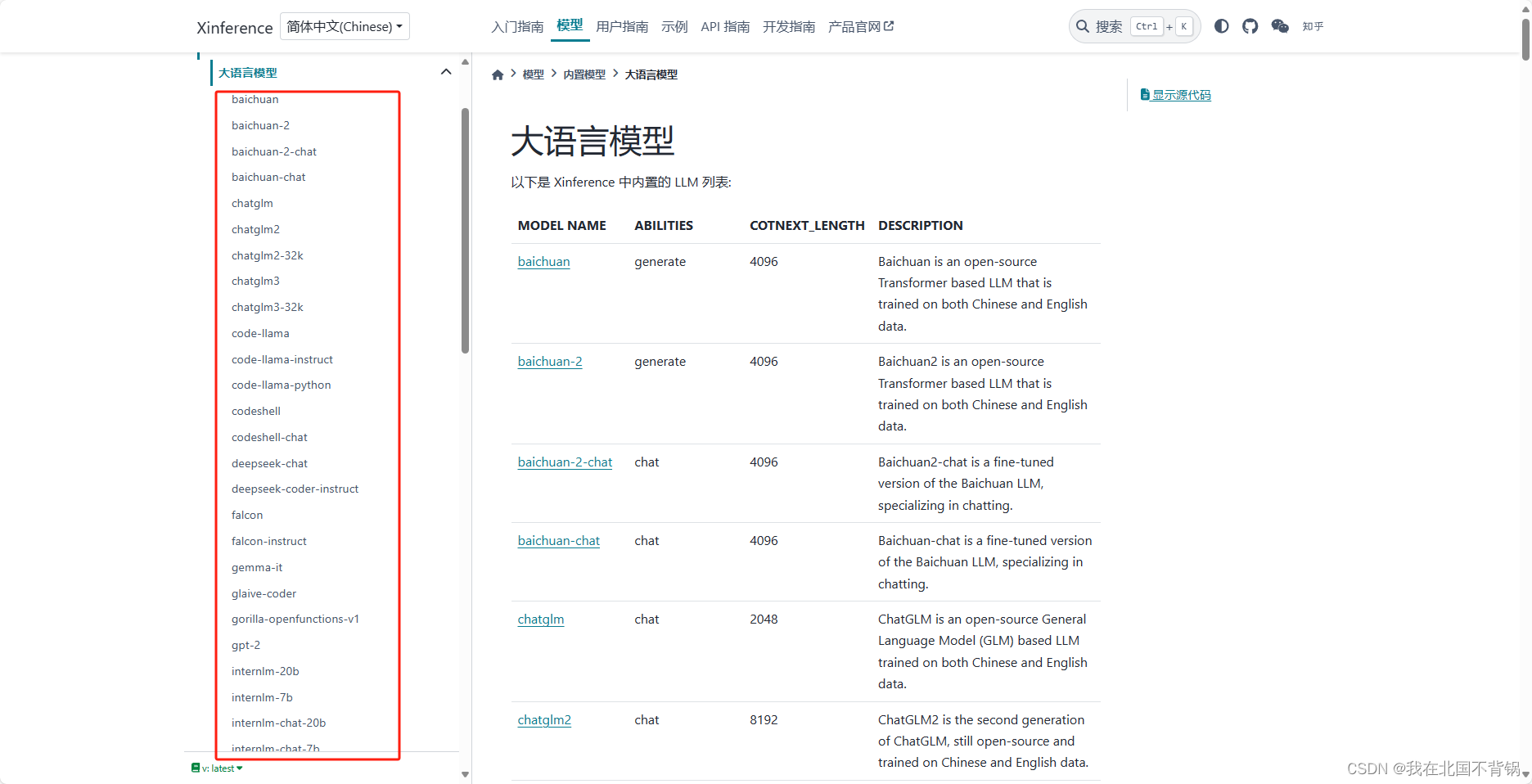
页面左侧列表主要包括3个功能:发行模型(Launch Model)、运行模型(Running Models)、注册模型(Register Model)。
发行模型展示各模型的名称、模型介绍、文本长度、模型类型(chat或者generate或者vl chat)。
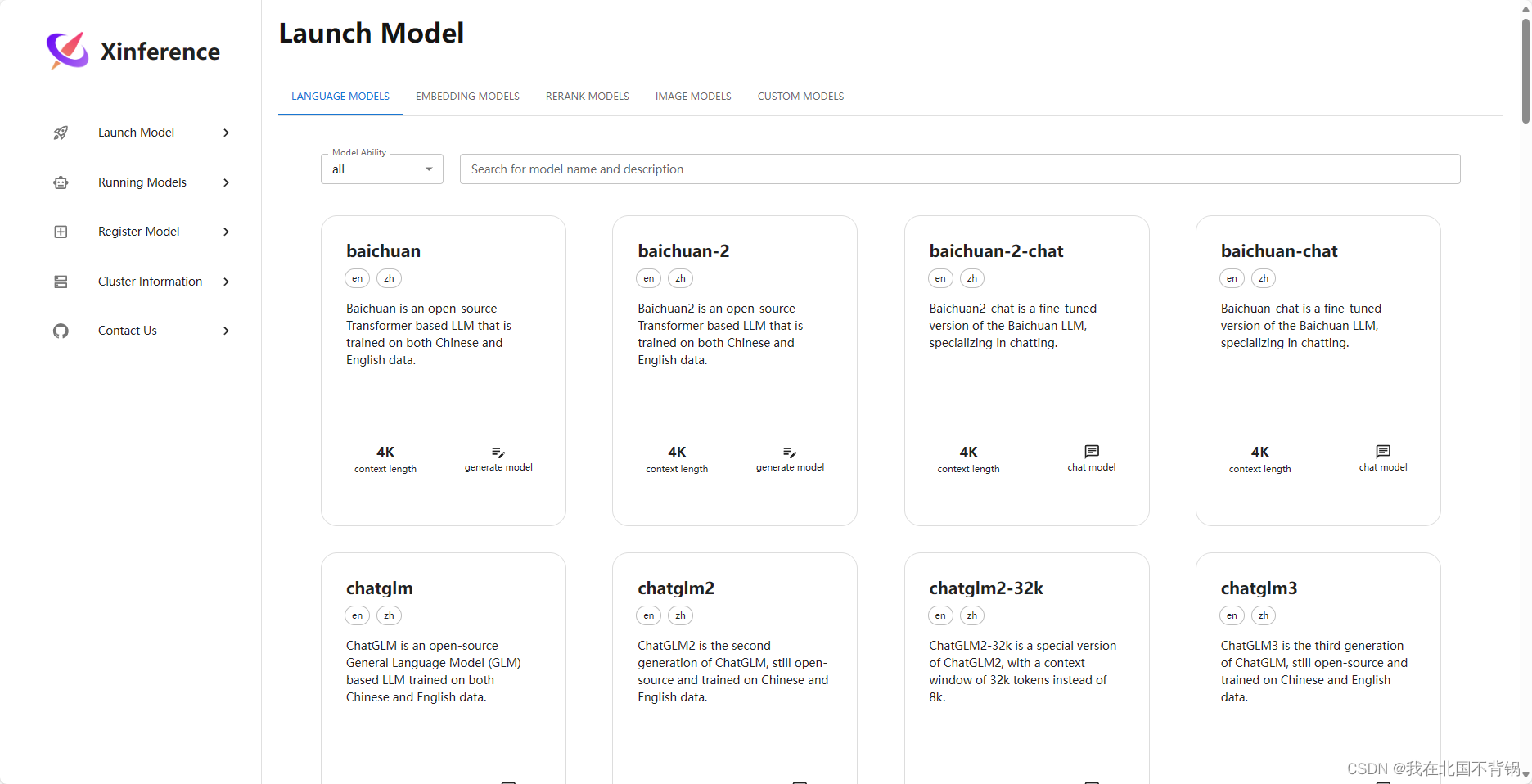
可以根据自己的需求,部署模型:
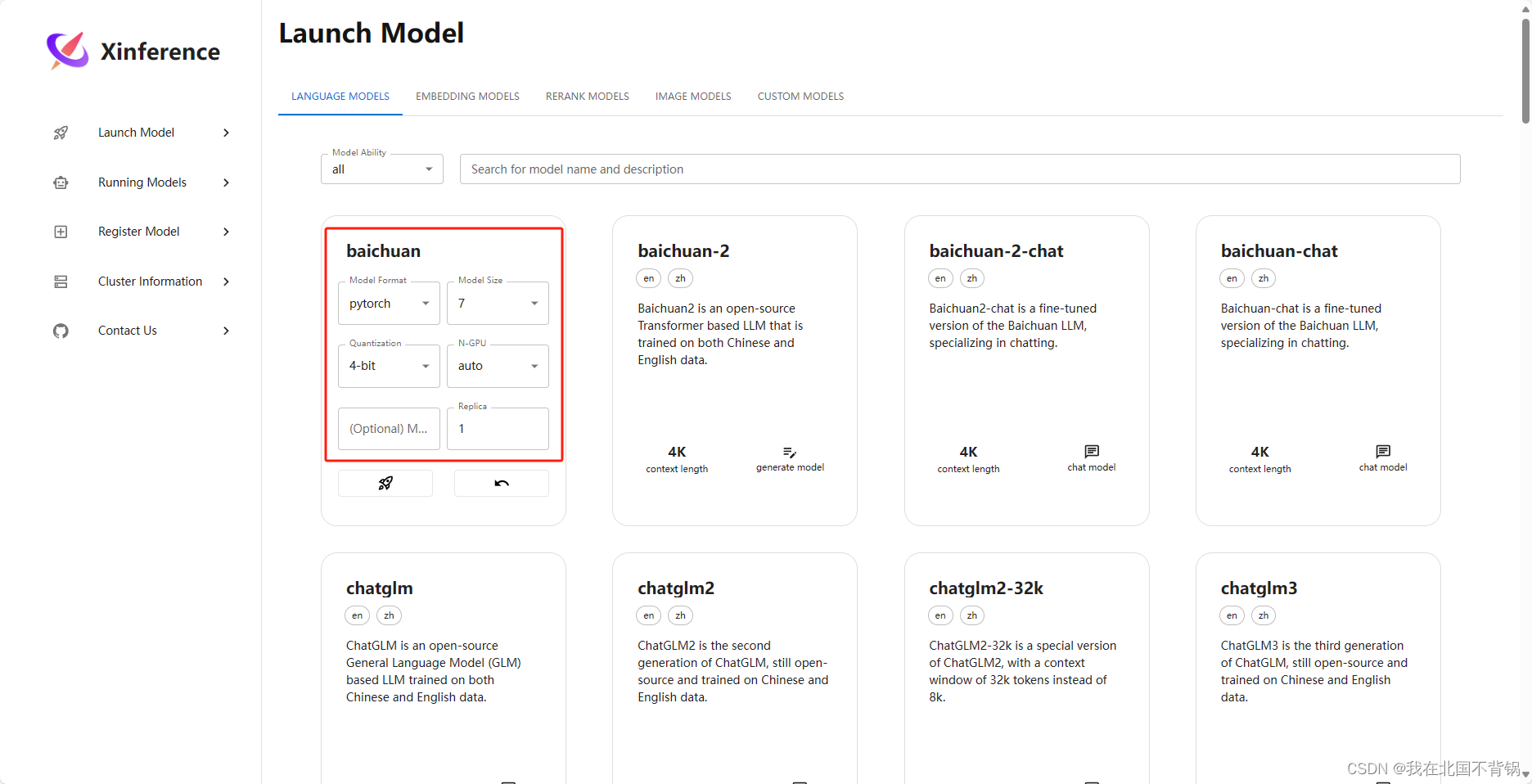
运行模型页面展示正在运行的模型信息,包括模型名称、地址、参数等。
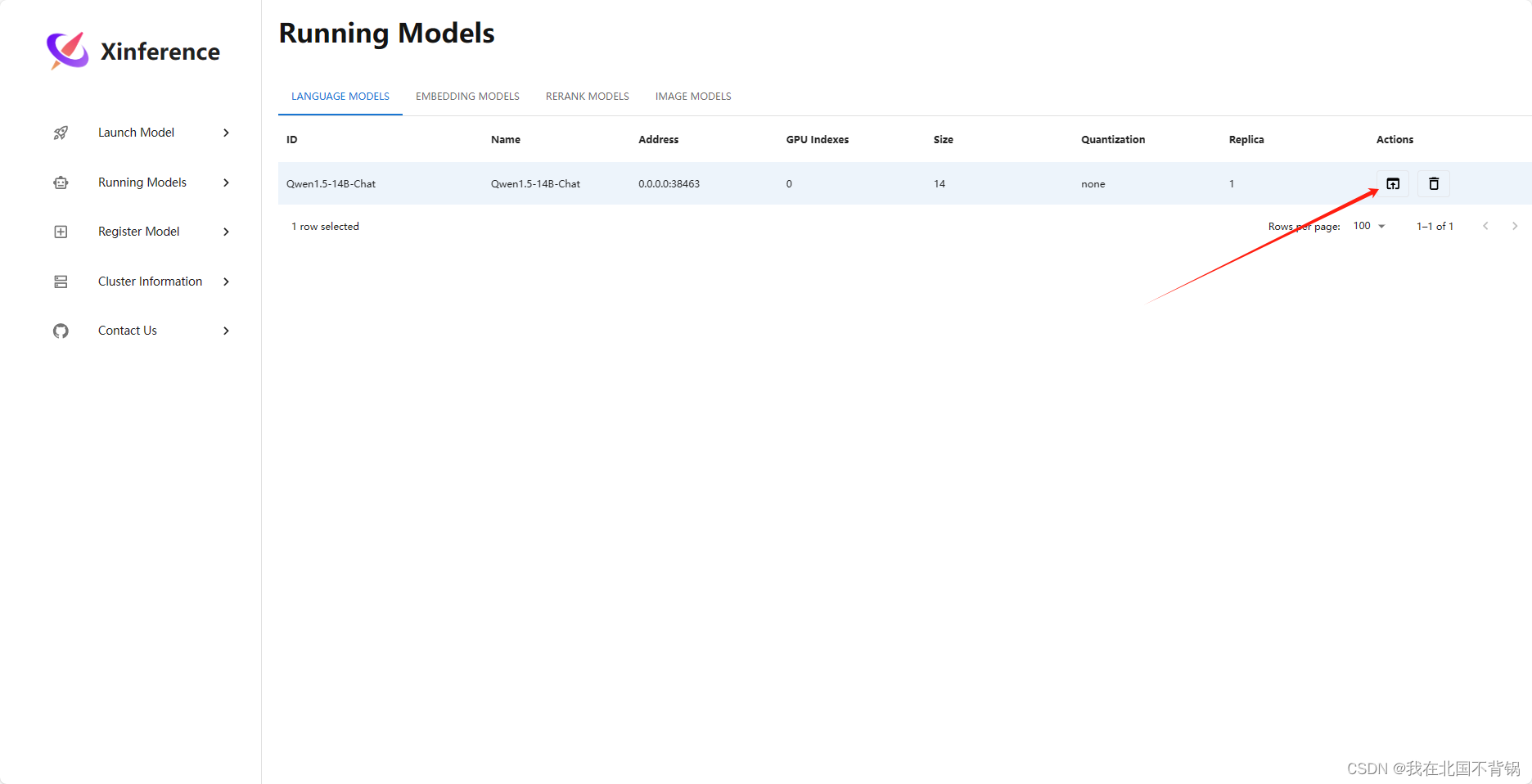
点击箭头所指的按钮,进入内置的问答页面:
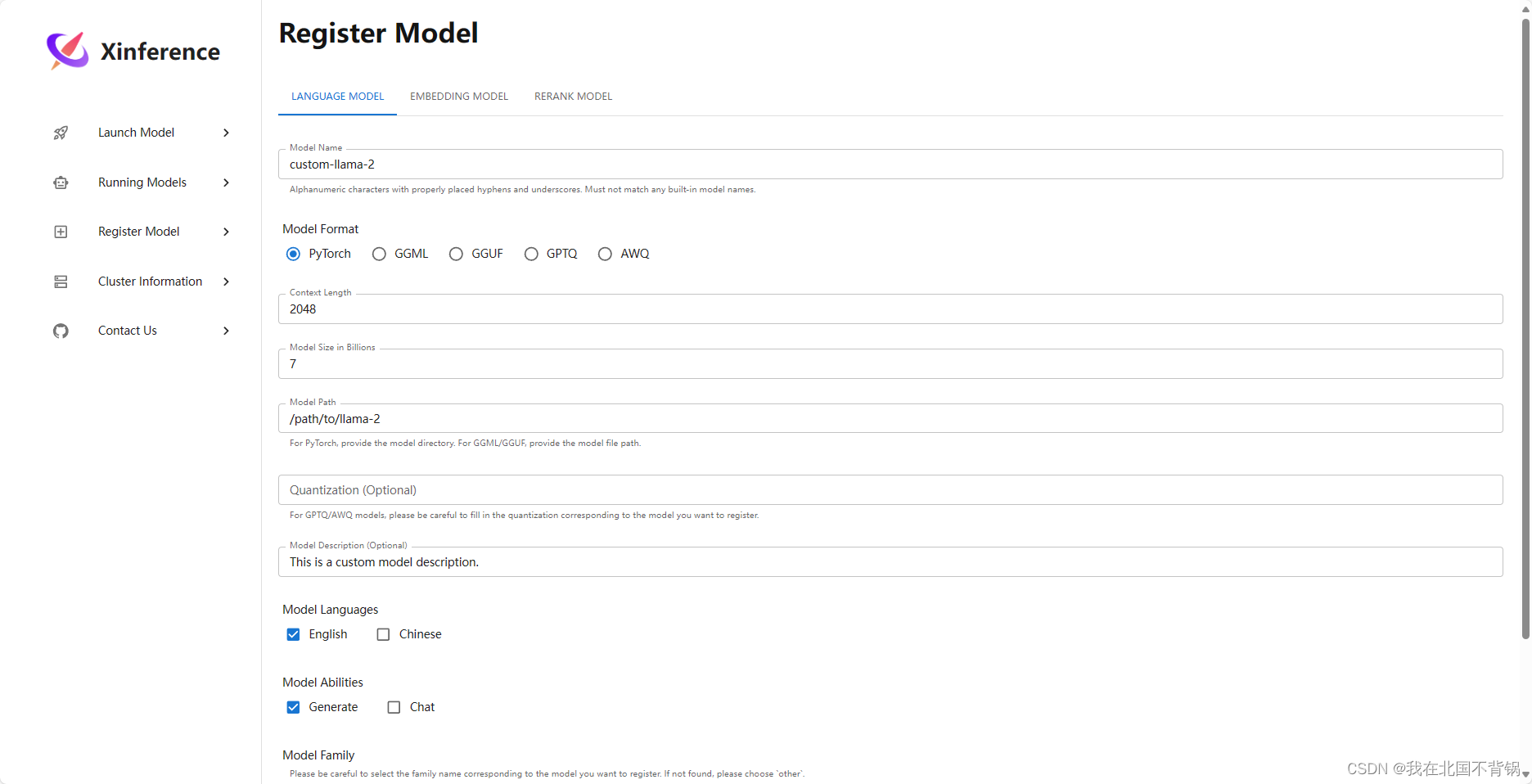
注册模型页面就是可以根据自己的需求注册发布自己的模型: