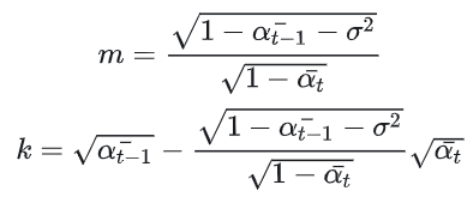背景
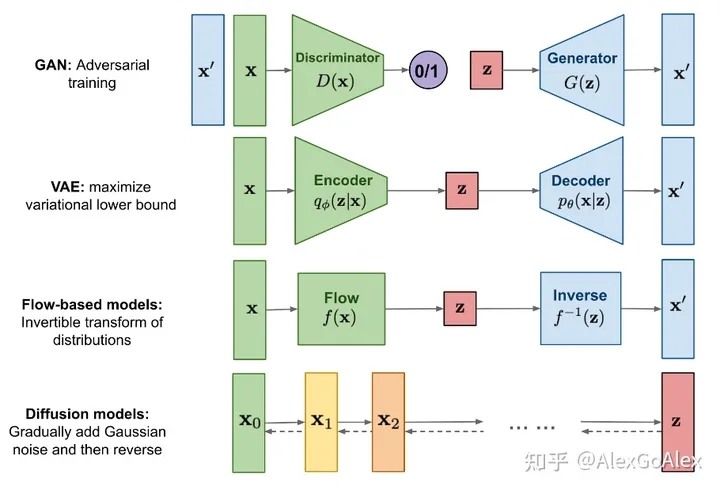
传统的图像生成模型有GAN,VAE等,但是存在模式坍缩,即生成图片缺乏多样性,这是因为模型本身结构导致的。而扩散模型拥有训练稳定,保持图像多样性等特点,逐渐成为现在AIGC领域的主流。
扩散模型
正如其名,该方法是从自然界的扩散现象(热力学第二定律、熵增)得到启发,认为任意我们想要的图片可以由随机噪声经过一系列采样步骤后得到,把对这个过程进行定义和建模就称为扩散模型。虽然原始论文涉及到的知识包括随机分布,马尔科夫链等,而且推导过程极其复杂,但本文不会深入去推导相关的公式,而是把重心放在思考这个过程以及对其中发现的一些问题进行探讨。
前向过程
前向过程其实就是一些假设。给定一张原始的图片,不断地往这张图片加正态分布的噪声,最终这张图片会变成正态分布噪声。
- 为什么老有这个正态分布出现?其他分布不行吗?
统计学上有个中心极限定理,在特定条件下,大量统计独立的随机变量的和的分布趋于正态分布。依据这一定理的结论,其它概率分布能够用正态分布作为近似。这就降低了很多随机过程的计算难度。
- 那这个前向过程的作用是啥呢?
如果在假设的条件下,能够得到最终的噪声图片,那么反过来从噪声中也能得到想要的“原始图片”,即我就能从随机噪声生成任意图片,这里就与GAN是一样的。这就是下面的反向过程推导了。
- 噪声是怎么加的?
前向过程加噪声是先小后大,因为一开始图片质量很高,加很小的噪声就发生很大的变化,而越后面的图片含有噪声越多,失真越严重,必须加更大的噪声才能引起较大变化。如果玩过文生图的话就能发现,选择了一定的采样步数后,前几步图片变化非常大,从模糊的噪声逐渐出现轮廓,后面几步基本不变,只是一些细节发生了变化。
- 前向过程的最终结论
前向推导出加噪声过程可由 x 0 x_0 x0直接得到,那在训练过程就不必保存中间的过程变量,不需要一步步迭代,节省中间变量占用的内存。相当于前向过程是一个公式,时间复杂度是 O ( 1 ) O(1) O(1),整个模型的时间复杂度只取决于反向过程。
反向过程
反向过程其实就是在前面定义的基础上,本来想直接求解 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt)的。但是发现走不通,这样是完全求不出来的。而 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t,x_0) q(xt−1∣xt,x0)这个是有办法求解的(经过贝叶斯公式一系列变换),但是这样需要假设我们知道 x 0 x_0 x0的情况才行。因此需要加上 x 0 x_0 x0,然后我们用来进行训练一个模型,拟合训练数据的分布之后,就可以预测出 q ( x t − 1 ∣ x t ) q(x_{t-1}|x_t) q(xt−1∣xt),即对任意噪声图片的任意时刻,我都能预测出前一时刻该图片的样子,不管准不准。问题建模成 p θ ( x t − 1 ∣ x t ) p_\theta(x_{t-1}|x_t) pθ(xt−1∣xt)来求解, θ \theta θ就是求解的参数,实际上就是代表模型对 x 0 x_0 x0的预测能力。
训练与采样

算法2的采样中, ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)表示的即是模型预测出来 t t t时候加上的噪声,结合如下代码更容易理解。
betas = torch.linspace(start=0.0001, end=0.02, steps=1000)
alphas = 1 - betas
alphas_cum = torch.cumprod(alphas, 0)
alphas_cum_s = torch.sqrt(alphas_cum)
alphas_cum_sm = torch.sqrt(1 - alphas_cum)
# 扩散损失计算
def diffusion_loss(model, x0, t, noise):
# 根据公式计算 xt
xt = alphas_cum_s[t] * x0 + alphas_cum_sm[t] * noise
# 模型预测噪声
predicted_noise = model(xt, t)
# 计算Loss
return mse_loss(predicted_noise, noise)
# 训练过程
for i in len(data_loader):
# 从数据集读取一个 batch 的真实图片
x0 = next(data_loader)
# 采样时间步
t = torch.randint(0, 1000, (batch_size,))
# 生成高斯噪声
noise = torch.randn_like(x_0)
loss = diffusion_loss(model, x0, t, noise)
optimizer.zero_grad()
loss.backward()
optimizer.step()